代码随想录算法训练营第20天 | 654.最大二叉树 617.合并二叉树 700.二叉搜索树中的搜索 98.验证二叉搜索树
目录
654.最大二叉树
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
- 二叉树的根是数组中的最大元素。
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
示例 :

提示:
给定的数组的大小在 [1, 1000] 之间。
💡解题思路
最大二叉树的构建过程如下:

构造树一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
- 确定递归函数的参数和返回值
参数传入的是存放元素的数组,返回该数组构造的二叉树的头结点,返回类型是指向节点的指针。
代码如下:
TreeNode* constructMaximumBinaryTree(vector<int>& nums)
- 确定终止条件
题目中说了输入的数组大小一定是大于等于1的,所以我们不用考虑小于1的情况,那么当递归遍历的时候,如果传入的数组大小为1,说明遍历到了叶子节点了。
那么应该定义一个新的节点,并把这个数组的数值赋给新的节点,然后返回这个节点。 这表示一个数组大小是1的时候,构造了一个新的节点,并返回。
代码如下:
TreeNode* node = new TreeNode(0);
if (nums.size() == 1) {
node->val = nums[0];
return node;
}
- 确定单层递归的逻辑
这里有三步工作
- 先要找到数组中最大的值和对应的下标, 最大的值构造根节点,下标用来下一步分割数组。
代码如下:
int maxValue = 0;
int maxValueIndex = 0;
for (int i = 0; i < nums.size(); i++) {
if (nums[i] > maxValue) {
maxValue = nums[i];
maxValueIndex = i;
}
}
TreeNode* node = new TreeNode(0);
node->val = maxValue;
- 最大值所在的下标左区间 构造左子树
这里要判断maxValueIndex?>?0,因为要保证左区间至少有一个数值。
代码如下:
if (maxValueIndex > 0) {
vector<int> newVec(nums.begin(), nums.begin() + maxValueIndex);
node->left = constructMaximumBinaryTree(newVec);
}
- 最大值所在的下标右区间 构造右子树
判断maxValueIndex?<?(nums.size()?-?1),确保右区间至少有一个数值。
代码如下:
if (maxValueIndex < (nums.size() - 1)) {
vector<int> newVec(nums.begin() + maxValueIndex + 1, nums.end());
node->right = constructMaximumBinaryTree(newVec);
}
💻实现代码
class Solution {
public TreeNode constructMaximumBinaryTree(int[] nums) {
return constructMaximumBinaryTree1(nums,0,nums.length);
}
public TreeNode constructMaximumBinaryTree1(int[] nums,int left,int right){
if(right-left<1){
return null;
}if(right-left==1){
return new TreeNode(nums[left]);
}
int maxIndex=left;
int maxValue=nums[left];
for(int i=left+1;i<right;i++){
if(nums[i]>maxValue){
maxValue=nums[i];
maxIndex=i;
}
}
TreeNode cur=new TreeNode(maxValue);
cur.left=constructMaximumBinaryTree1(nums,left,maxIndex);
cur.right=constructMaximumBinaryTree1(nums,maxIndex+1,right);
return cur;
}
}617.合并二叉树
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为?NULL 的节点将直接作为新二叉树的节点。
示例?1:

注意: 合并必须从两个树的根节点开始。
💡解题思路
相信这道题目很多同学疑惑的点是如何同时遍历两个二叉树呢?
其实和遍历一个树逻辑是一样的,只不过传入两个树的节点,同时操作。
递归
二叉树使用递归,就要想使用前中后哪种遍历方式?
本题使用哪种遍历都是可以的!
我们下面以前序遍历为例。
动画如下:
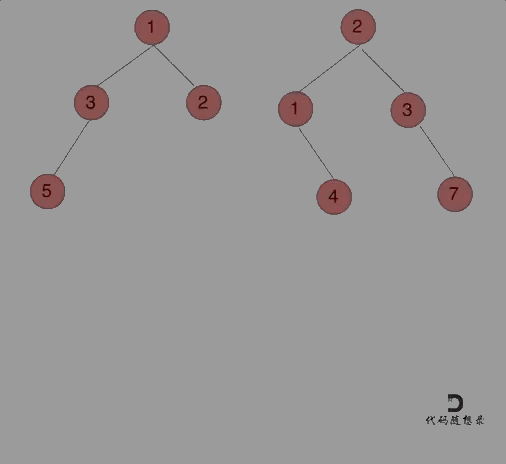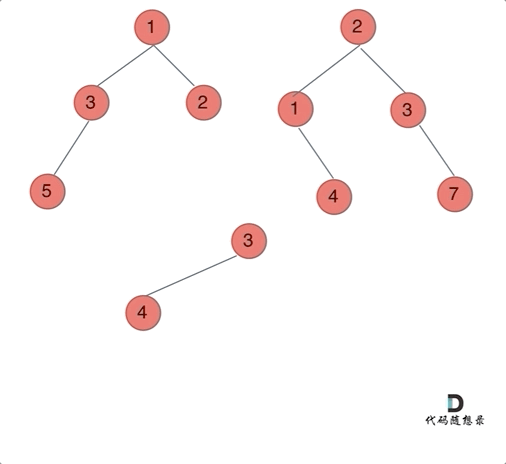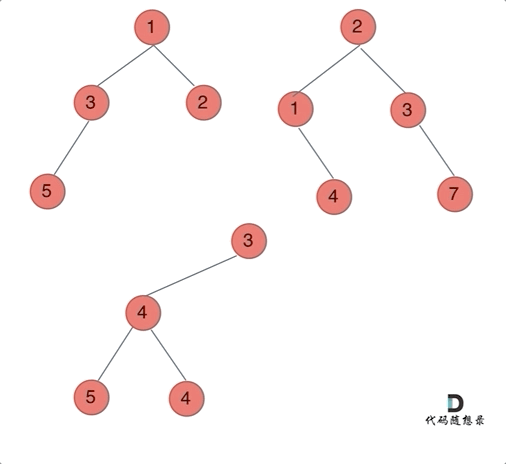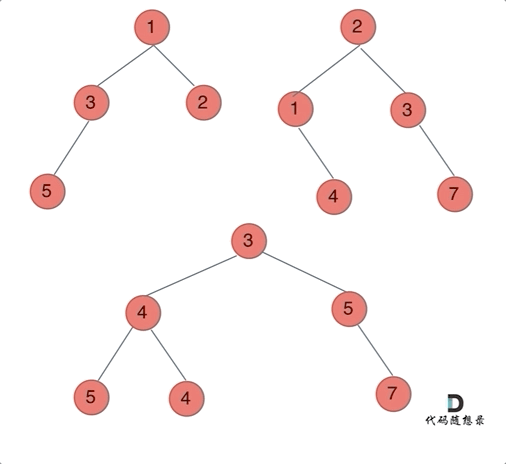
那么我们来按照递归三部曲来解决:
- 确定递归函数的参数和返回值:
首先要合入两个二叉树,那么参数至少是要传入两个二叉树的根节点,返回值就是合并之后二叉树的根节点。
代码如下:
TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {
- 确定终止条件:
因为是传入了两个树,那么就有两个树遍历的节点t1 和 t2,如果t1 == NULL 了,两个树合并就应该是 t2 了(如果t2也为NULL也无所谓,合并之后就是NULL)。
反过来如果t2 == NULL,那么两个数合并就是t1(如果t1也为NULL也无所谓,合并之后就是NULL)。
代码如下:
if (t1 == NULL) return t2; // 如果t1为空,合并之后就应该是t2
if (t2 == NULL) return t1; // 如果t2为空,合并之后就应该是t1
- 确定单层递归的逻辑:
单层递归的逻辑就比较好写了,这里我们重复利用一下t1这个树,t1就是合并之后树的根节点(就是修改了原来树的结构)。
那么单层递归中,就要把两棵树的元素加到一起。
t1->val += t2->val;
接下来t1 的左子树是:合并 t1左子树 t2左子树之后的左子树。
t1 的右子树:是 合并 t1右子树 t2右子树之后的右子树。
最终t1就是合并之后的根节点。
代码如下:
t1->left = mergeTrees(t1->left, t2->left);
t1->right = mergeTrees(t1->right, t2->right);
return t1;
💻实现代码
class Solution {
// 递归
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) return root2;
if (root2 == null) return root1;
root1.val += root2.val;
root1.left = mergeTrees(root1.left,root2.left);
root1.right = mergeTrees(root1.right,root2.right);
return root1;
}
}
class Solution {
// 使用栈迭代
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) {
return root2;
}
if (root2 == null) {
return root1;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root2);
stack.push(root1);
while (!stack.isEmpty()) {
TreeNode node1 = stack.pop();
TreeNode node2 = stack.pop();
node1.val += node2.val;
if (node2.right != null && node1.right != null) {
stack.push(node2.right);
stack.push(node1.right);
} else {
if (node1.right == null) {
node1.right = node2.right;
}
}
if (node2.left != null && node1.left != null) {
stack.push(node2.left);
stack.push(node1.left);
} else {
if (node1.left == null) {
node1.left = node2.left;
}
}
}
return root1;
}
}
class Solution {
// 使用队列迭代
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) return root2;
if (root2 ==null) return root1;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root1);
queue.offer(root2);
while (!queue.isEmpty()) {
TreeNode node1 = queue.poll();
TreeNode node2 = queue.poll();
// 此时两个节点一定不为空,val相加
node1.val = node1.val + node2.val;
// 如果两棵树左节点都不为空,加入队列
if (node1.left != null && node2.left != null) {
queue.offer(node1.left);
queue.offer(node2.left);
}
// 如果两棵树右节点都不为空,加入队列
if (node1.right != null && node2.right != null) {
queue.offer(node1.right);
queue.offer(node2.right);
}
// 若node1的左节点为空,直接赋值
if (node1.left == null && node2.left != null) {
node1.left = node2.left;
}
// 若node1的右节点为空,直接赋值
if (node1.right == null && node2.right != null) {
node1.right = node2.right;
}
}
return root1;
}
}
700.二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
例如,

在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。
💡解题思路
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
递归法
- 确定递归函数的参数和返回值
递归函数的参数传入的就是根节点和要搜索的数值,返回的就是以这个搜索数值所在的节点。
代码如下:
TreeNode* searchBST(TreeNode* root, int val)
- 确定终止条件
如果root为空,或者找到这个数值了,就返回root节点。
if (root == NULL || root->val == val) return root;
- 确定单层递归的逻辑
看看二叉搜索树的单层递归逻辑有何不同。
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果root->val?>?val,搜索左子树,如果root->val?<?val,就搜索右子树,最后如果都没有搜索到,就返回NULL。
代码如下:
TreeNode* result = NULL;
if (root->val > val) result = searchBST(root->left, val);
if (root->val < val) result = searchBST(root->right, val);
return result;
迭代法
对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图:
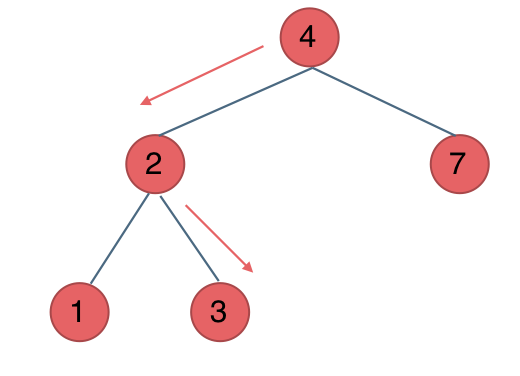
💻实现代码
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if(root==null||root.val==val){
return root;
}if(root.val>val){
return searchBST(root.left,val);
}else{
return searchBST(root.right,val);
}
}
}98.验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。

💡解题思路
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
# 递归法
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
然后只要比较一下,这个数组是否是有序的,注意二叉搜索树中不能有重复元素。
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
这道题目比较容易陷入两个陷阱:
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root->val > root->left->val && root->val < root->right->val) {
return true;
} else {
return false;
}
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case:
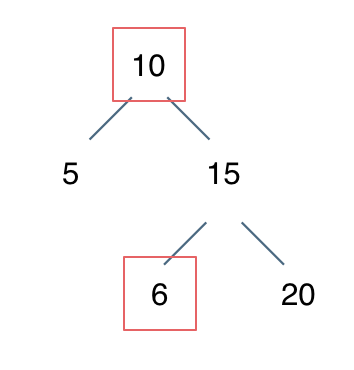
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值。
递归三部曲:
- 确定递归函数,返回值以及参数
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
代码如下:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root)
- 确定终止条件
如果是空节点 是不是二叉搜索树呢?
是的,二叉搜索树也可以为空!
代码如下:
if (root == NULL) return true;
- 确定单层递归的逻辑
中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
代码如下:
bool left = isValidBST(root->left); // 左
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val; // 中
else return false;
bool right = isValidBST(root->right); // 右
return left && right;
💻实现代码
class Solution {
// 递归
TreeNode max;
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
// 左
boolean left = isValidBST(root.left);
if (!left) {
return false;
}
// 中
if (max != null && root.val <= max.val) {
return false;
}
max = root;
// 右
boolean right = isValidBST(root.right);
return right;
}
}
class Solution {
// 迭代
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode pre = null;
while (root != null || !stack.isEmpty()) {
while (root != null) {
stack.push(root);
root = root.left;// 左
}
// 中,处理
TreeNode pop = stack.pop();
if (pre != null && pop.val <= pre.val) {
return false;
}
pre = pop;
root = pop.right;// 右
}
return true;
}
}
// 简洁实现·递归解法
class Solution {
public boolean isValidBST(TreeNode root) {
return validBST(Long.MIN_VALUE, Long.MAX_VALUE, root);
}
boolean validBST(long lower, long upper, TreeNode root) {
if (root == null) return true;
if (root.val <= lower || root.val >= upper) return false;
return validBST(lower, root.val, root.left) && validBST(root.val, upper, root.right);
}
}
// 简洁实现·中序遍历
class Solution {
private long prev = Long.MIN_VALUE;
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
if (!isValidBST(root.left)) {
return false;
}
if (root.val <= prev) { // 不满足二叉搜索树条件
return false;
}
prev = root.val;
return isValidBST(root.right);
}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深入理解虚拟DOM:原理、优势与实践
- 【若依】前后端分离框架部署
- 《系统架构设计师教程(第2版)》第4章-信息安全技术基础知识-01-信息安全基础知识
- LM324N引脚说明、参数解读、应用电路图说明分享
- “modem帮”知识星球介绍
- 成都直播产业园来了!首个直播数字经济产业园落地成都
- Java代码审计&Mybatis注入&文件上传&下载&读取(非常详细!!)
- Netty开篇——NIO章中(四)
- 使用WAF防御网络上的隐蔽威胁之扫描器
- 大语言模型LLM微调技术:P-Tuning