【论文解读】Kvazaar 2.0: Fast and Efficient Open-Source HEVC Inter Encoder
时间:2020
级别:SCI
机构:Tampere University
摘要:高效视频编码(HEVC)是当前多媒体应用中经济的视频传输和存储的关键,但解决其固有的计算复杂性需要强大的视频编解码器实现。本文介绍了Kvazaar 2.0 HEVC编码器,它是我们学术开源软件(github.com/ultravideo/kvazaar)的新版本。Kvazaar 2.0引入了新的帧间编码功能,该功能建立在先进的率失真优化(RDO)方案之上,并通过多种提前终止机制、simd优化的编码工具和并行化策略来加速。实验结果表明,在Intel Xeon E5-2699 v4 22核处理器上,Kvazaar的编码速度是HEVC参考软件HM的125倍,而平均编码代价仅为2.4%。在固定 QP 模式下,实验结果表明,保持同样的客观视觉质量下,Kvazaar的编码速度是x265的3倍,平均码率比x265低10.7%。这些结果表明,Kvazaar已经成为实际高效视频编码领域领先的开源HEVC编码器之一。
介绍:据思科称,从2017年开始全球IP视频流量将增加四倍,到2022年,将占所有IP流量的82%。这爆炸式增长主要是由先进技术的扩散驱动的多媒体设备、无处不在的连接和流行视频具有沉浸式用户体验的应用程序。
高效视频编码(High Efficiency video coding, HEVC/H.265)是针对当前视频传输和存储日益增长的问题而制定的最新视频编码标准。与之前的高级视频编码(AVC/H.264)标准相比,在相同的目标视觉质量下,编码效率提高了近40%,但复杂度开销增加了约40%。因此,在世界范围内促进HEVC的部署需要开放和强大的实现,这些实现能够解决HEVC的复杂性,并获得吸引人的编码速度、编码效率和功率预算。
目前,有几个值得注意的开源软件HEVC编码器,其中仅HEVC参考软件模型(HM) , x265和Kvazaar 积极开展学术研究与发展。HM支持所有规范的HEVC编码工具是能够达到最好的,然而其巨大的计算复杂性限制了其应用仅限于研究。x265可能是最好的,被用作我们工作的主要参考。
Kvazaar是一个学术开源HEVC软件编码器,由我们在坦佩雷大学的Ultra Video小组开发。它可以在GitHub上在线下载:https://github.com/ultravideo/kvazaar 。在GNU LGPLv2.1许可证下。我们之前的工作已经彻底考虑了第一代Kvazaar版本,该版本被证明是HEVC帧内编码的学术领先者。介绍了Kvazaar的第二代实现,即Kvazaar 2.0,它针对HEVC的帧间编码进行了优化。
Kvazaar 2.0 HEVC Encoder:
图 1 展现 kvazaar2.0 总体框架,支持 main profile、10 种 preset、8bit 420.
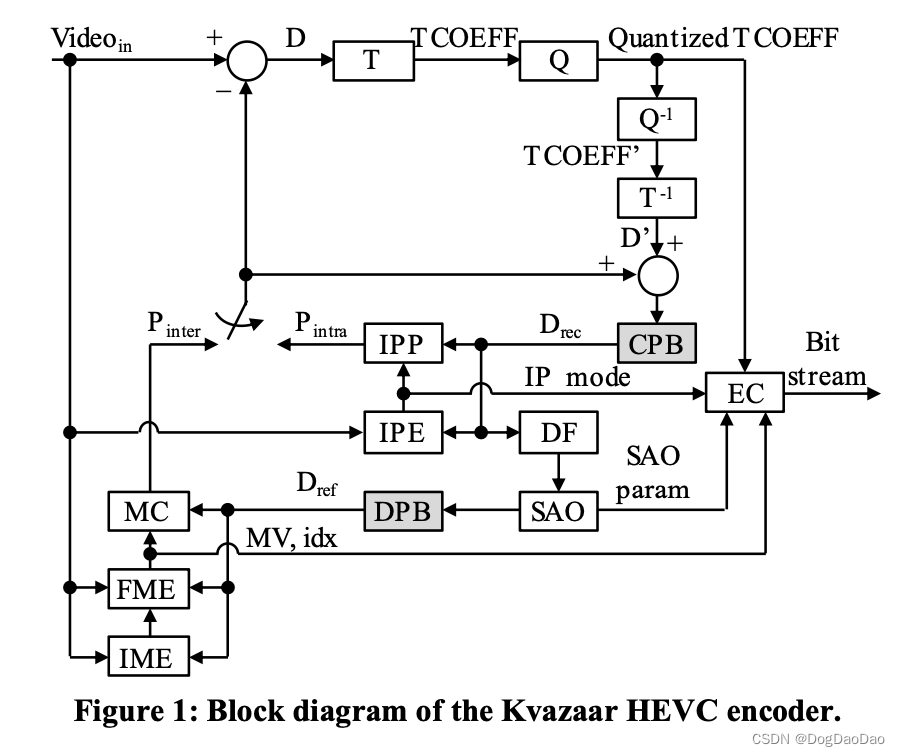
表1列出了Kvazaar中可用的所有基本编码参数和本工作中基准测试的参数子集。

RDO:
Kvazaar支持多阶段率失真优化(RDO)方案,具有近似(快速)和精确(复杂)RDO阶段。这些阶段在确定块结构和模式参数之前,通过比较每个探索过的候选编码的RD成本,使总体编码成本最小化。
近似RDO阶段根据和来比较成本绝对变换差(SATD)的亮度通道和编码模式的相关位。通常,这个阶段用于探索许多不同的选择,只有最好的才能进入精确的RDO阶段。
精确的RDO级同时考虑了亮度和色度失真以及剩余四叉树位。采用差分平方和(SSD)作为失真度量,对图像进行重构成本计算和比较前预测的块划分。
编码树结构:
Kvazaar实现了一种完整的HEVC四叉树编码结构其中每个输入帧被分割成大小相等的正方形称为编码树单元(CTUs)的块。在Kvazaar,一个CTU尺寸是64 × 64像素。在4:2:0颜色格式中,一个CTU包含 一个亮度块,两个色度块,以及相关的语法元素。
CTU被递归地划分为四个大小相等的单元平方编码单元(CUs)直到最大层次深度到达四叉树的顶点。指定亮度块的大小如2N×2N和4:2:0颜色格式限制了色度的大小块到N×N,其中N∈{32,16,8,4}。这四叉树在z-扫描中采用深度优先搜索策略确定分解扫描顺序。在搜索过程中,将准确的RD成本分配给所有被评估的CUs,并在其产生的RD代价低于不拆分方案时做出拆分决策。
通过以下两种提前终止机制降低了递归搜索的复杂度:1)当计算出的子CU的累计代价超过父CU的累计代价时,由于剩余子CU的计算已经不再影响拆分决策,可以跳过对四叉树中子CU的进一步搜索;2)在找到一个没有非零系数的CU后,可以停止对进一步划分CU的递归搜索,因为继续搜索不太可能带来任何显著的RD改进。后一种机制源自参考文章 20。
预测模式决策:
CU可以进一步分割成矩形的 PU,kvazaar 支持的PU 的位置模式有方形模式2Nx2N、NxN;SMP 模式有2N×N 和 N×2N;AMP 模式 2N×nU, 2N×nD, nL×2N, 和 nR×2N;帧内只有NxN;skip 模式 2Nx2N。
帧间预测:
在帧间预测阶段,合并模式的运动参数隐式地继承相邻PUs的运动参数。合并列表构建候选亮度块,并使用所有可用的候选亮度块生成相应的亮度预测块。每个合并候选都要经历近似的RDO过程,以找到最佳的合并模式参数。
在合并候选后尝试早期跳过模式决策分析。如果最好的合并候选节点残差为零,则选择跳过模式,即提前跳过进行模式决策,在这个深度的任何其他模式不再执行搜索。
之后是 AMVP 过程。AMVP模式选取由运动估计获得的,先整数ME,再分数 ME。在对基于运动划分的所有pu进行参数化后,计算各帧间CU的精确RD代价。
帧内预测:
帧内预测阶段分为帧内图像估计(IPE)和帧内图像预测(IPP)。IPE 支持 35 种模式,IPE将最佳模式输出给IPP进行帧内计算对当前PU的预测。
变换和量化:
预测阶段结束后,变换阶段 T 将预测残差 D从空间域转换到变换域系数TCOEFFs。Kvazaar支持转换单位(TUs)的大小32×32, 16×16, 8×8。它实现帧内4×4亮度块编码用整数离散正弦变换(DST) ,其余分块用整数离散余弦变换(DCT)。
量化(Q)阶段将TCOEFFs映射为量化的TCOEFFs。kvazaar 也实现了RDOQ 技术。
解码步骤与之相反。此外,为了提高变换和量化效率,应用了transform skip和sign bit hiding编码工具。
环路滤波:
Kvazaar实现了两个顺序的环路滤波器,即 DF(Deblocking Filter) 和 SAO(Sample-Adaptive Offset)。
熵编码:
熵编码(Entropy Coding, EC)通过上下文自适应的二进制算术编码(Context-Adaptive Binary Arithmetic Coding, CABAC)对量化TCOEFFs、IP模式、MV、idx、SAO参数等二进制语法元素进行压缩。Kvazaar支持两种编码代价估算方法。第一种方法对TCOEFFs和相关元素执行CABAC。第二种是HM中基于表的估计。根据当前上下文状态估计分数比特。为了在可接受的RD损失下限制编码时间,Kvazaar在实际的比特流中主要在CTU级别更新上下文的一代。
并行计算:
除了 slice和 tile 机制,kvazaar 还增加了 WPP(Wavefront Parallel Processing)、OWF(Overlapped Wavefront)。
在数据层,最耗时的编码工具,如SAD、SATD、SSD、插值滤波器、IPP和变换,都是使用Intel intrinsic或x86-64汇编语言进行优化的。Kvazaar包含了一种针对SIMD优化函数的动态调度机制,即根据所支持的指令集自动选择最优的SIMD优化CPU。支持对SSE2, SSE4.1, AVX和AVX2的优化,但大多数是AVX2。
率失真复杂度分析
在本次实验中,编码参数设置如表 2。

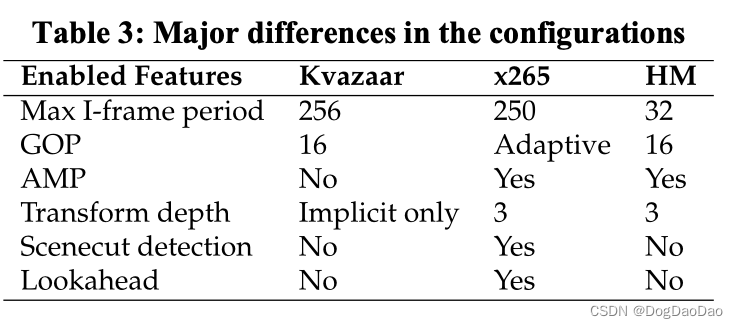
三者的编码参数整体趋于相同,但也有一些不同点,如表 3。
实验设置:
实验设置如表 4,支持AVX2指令集的SIMD扩展。执行从A类到E类的所有18个 8 bit 的HEVC公共测试序列。它们在帧、帧速率和空间分辨率都有所不同。QP 设置 22、27、32、37,以PSNR 为评价标准,采用恒定 QP 编码方案。

实验结果:
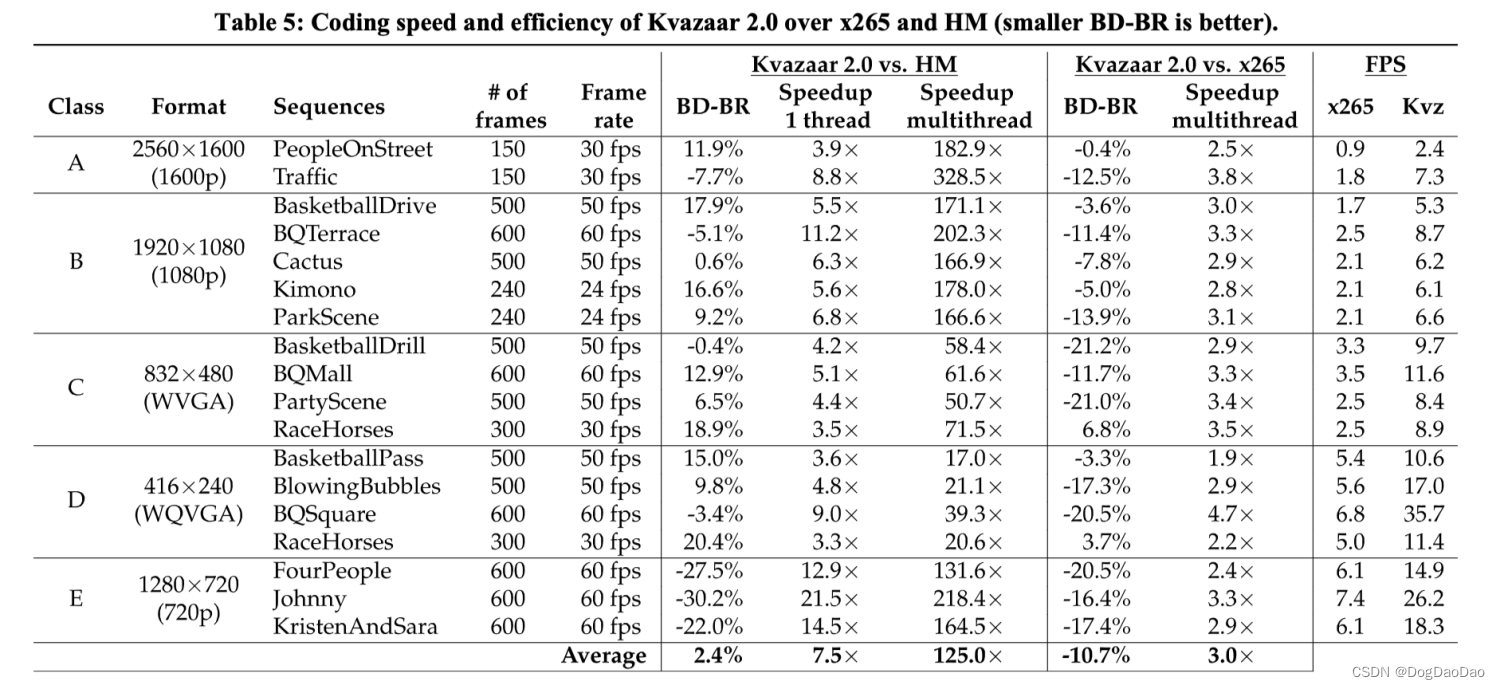
表5报告了Kvazaar v2.0.0相对于HM16.20和x265 v3.2 RC1的RD特性和编码速度。
结论:
在QP编码方式下,提出并行实现 Kvazaar的速度是x265各自非常慢的预设速度的3倍编码器BD-BR平均提升-10.7%。Kvazaar的第一代实现已经被证明是HEVC帧内编码和这项工作结果的领跑者。此次实验结果证明Kvazaar 2.0是目前所有实用开源HEVC编码器的领先解决方案之一。
由于Kvazaar 2.0,整个多媒体社区以后可以在各种多媒体应用中部署一个学术性的、尖端的HEVC间编码替代方案。Kvazaar已经得到了流行的FFmpeg和Libav多媒体框架的支持,这些框架便于Kvazaar与其他多媒体处理工具的部署。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- simulink代码生成(二)——ADC采样模块
- SOLIDWORKS PDM—邮件信息系统
- Java编程练习之this关键字(2)
- 哪里能申请OV通配符证书
- 第6章 服务枚举
- 【华为OD机试真题2023C&D卷 JAVA&JS】精准核酸检测
- 安防视频云平台/可视化监控云平台ARM版EasyCVR无法下载录像文件,如何解决?
- 【Spring 篇】基于XML的Spring事务控制详解
- 2023.12.21力扣每日一题
- 【leetcode100-038/039/040/041】【二叉树】翻转/对称/直径/层序遍历