Spark四:Spark Streaming和Structured Streaming
简介
Spark Streaming整体流程和DStream介绍
Structured Streaming发展历史和Dataflow模型介绍
Spark Streaming 是一个基于 Spark Core 之上的实时计算框架,从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

Spark Streaming的特点
- 易用:可以像编写离线批处理一样编写流式程序,支持java/scala/python
- 容错:在没有额外代码和配置的情况下可以恢复丢失的工作
- 易整合到Spark体系:流式处理与批处理和交互式查询相结合
学习资料:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ
一、Spark Streaming整体流程
Spark Streaming中,会有一个接收器组件Receiver,作为一个长期运行的task跑在一个Executor上。Recevier接受外部的数据流形成input DStream。
Dstream。
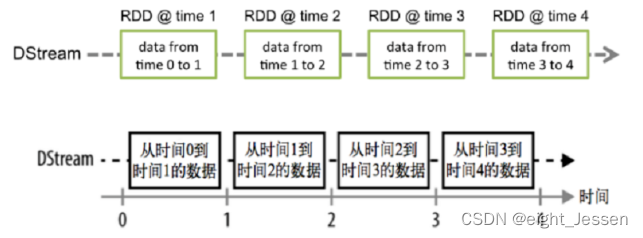
DStream会被按照时间间隔划分成一批一批的RDD,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
对DStream进行操作就是对RDD进行操作,计算处理的结果可以传给外部系统。
整体流程如下:

二、数据抽象
Spark Streaming的基础抽象是DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种 Spark 算子操作后的结果数据流。
可以从多个角度理解DStream:
-
DStream本质上就是一系列时间上连续的RDD
-
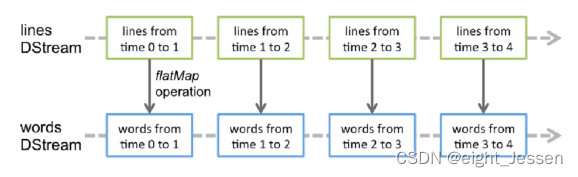
对DStream的数据进行操作也是按照RDD为单位进行的
-
容错性,底层RDD之间存在依赖关系,DStream直接也有依赖关系,RDD有容错性,DStream也具有容错性
-
准实时性/近实时性
Spark Streaming将流式计算分解成多个Spark Job,对于每一时间段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程
Spark Streaming虽然能够满足流式实时计算场景,但是对实时性要求非常高的如高频实时交易场景则不太合适。
DStream可以理解为对RDD的封装,对DStream进行操作,就是对RDD进行操作。
三、DStream相关操作
DStream上的操作与RDD相似,分为一下靓装:
- Transformations(转换)
- Output Operations(输出)/Action
3.1 Transformations
- 无状态转换:即每个批次的处理不依赖与之前批次的数据
| Transformation | 含义 |
|---|---|
| map(func) | 对 DStream 中的各个元素进行 func 函数操作,然后返回一个新的 DStream |
| flatMap(func) | 与 map 方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数 func 返回值为 true 的 DStream 元素并返回一个新的 DStream |
| union(otherStream) | 将源 DStream 和输入参数为 otherDStream 的元素合并,并返回一个新的 DStream |
| reduceByKey(func, [numTasks]) | 利用 func 函数对源 DStream 中的 key 进行聚合操作,然后返回新的(K,V)对构成的 DStream |
| join(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的 DStream,返回一个新的(K,(V,W)类型的 DStream |
| transform(func) | 通过 RDD-to-RDD 函数作用于 DStream 中的各个 RDD,可以是任意的 RDD 操作,从而返回一个新的 RDD |
- 有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果,包括基于追踪状态变化的转换(updateStateByKey)和滑动窗口的转换:
UpdateStateByKey(func)
Window Operations 窗口操作
3.2 Output/Action
可以将 DStream 的数据输出到外部的数据库或文件系统。
当某个 Output Operations 被调用时,spark streaming 程序才会开始真正的计算过程(与 RDD 的 Action 类似)。
| Output Operation | 含义 |
|---|---|
| print() | 打印到控制台 |
| saveAsTextFiles(prefix, [suffix]) | 保存流的内容为文本文件,文件名为"prefix-TIME_IN_MS[.suffix]" |
| saveAsObjectFiles(prefix,[suffix]) | 保存流的内容为 SequenceFile,文件名为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsHadoopFiles(prefix,[suffix]) | 保存流的内容为 hadoop 文件,文件名为"prefix-TIME_IN_MS[.suffix]" |
| foreachRDD(func) | 对 Dstream 里面的每个 RDD 执行 func |
四、Spark Streaming完成实时需求举例
4.1 WordCount
计算每个单词出现次数
4.2 updataStateByKey
累加更新每个单词出现次数
使用 updateStateByKey(func)来更新状态
4.3 reduceByKeyAndWindow
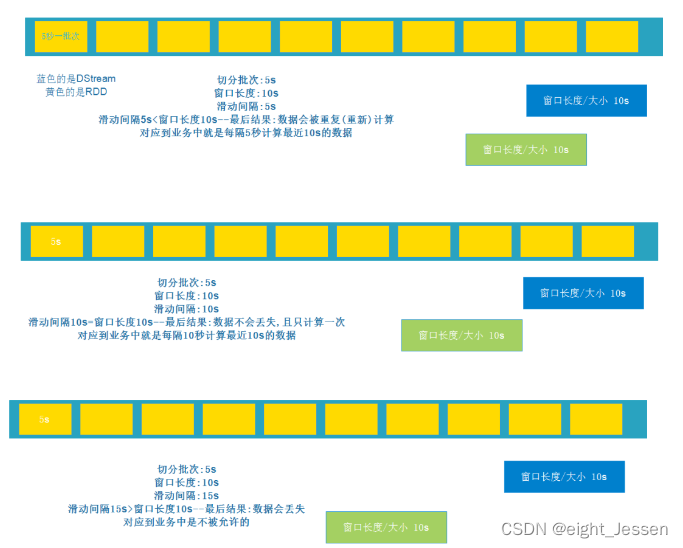
需要对指定时间范围的数据进行统计
窗口长度>滑动时间:数据会被重复计算 开发中会使用
窗口长度=滑动时间:数据不会丢失也不会重复计算 开发中会使用
窗口长度<滑动时间:数据丢失
五、Structured Streaming历史
Spark Streaming使用micro-batch(微批处理)的方式,面对复杂的流式处理场景捉襟见肘,处理延时较高,无法支持基于event_time的时间窗口做聚合逻辑。
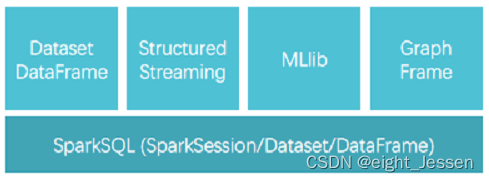
Structure Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎
5.1 API
Spark Streaming采用的抽象数据是RDD

Structured Streaming采用的抽象数据是Dataset/DataFrame
5.2 核心思想
将实时到达的数据看作是一个不断追加的 unbound table 无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中。
用户可以用静态结构化数据的批处理查询方式进行流计算,如可以使用 SQL 对到来的每一行数据进行实时查询处理。
5.3 应用场景(结构化的实时数据)
将数据源映射为类似于关系数据库中的表,然后将经过计算得到的结果映射为另一张表,完全以结构化的方式去操作流式数据,这种编程模型非常有利于处理分析结构化的实时数据;
5.4 Structured Streaming实战
5.4.1 读取Socket数据
5.4.2 读取目录下文本数据
5.4.3 计算操作
5.4.4 输出
- 计算结果可以输出到多种设备并进行如下设定
- output mode:以哪种方式将 result table 的数据写入 sink,即是全部输出 complete 还是只输出新增数据;
- output mode:以哪种方式将 result table 的数据写入 sink,即是全部输出 complete 还是只输出新增数据;
- query name:指定查询的标识。类似 tempview 的名字;
- trigger interval:触发间隔,如果不指定,默认会尽可能快速地处理数据;
- checkpointLocation: 一般是 hdfs 上的目录。注意:Socket 不支持数据恢复,如果设置了,第二次启动会报错,Kafka 支持。
- 三种输出模式
- Append mode:默认模式,新增的行才输出,每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持那些添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询 select,where,map,flatMap,filter,join 等会支持追加模式。不支持聚合
- Complete mode:所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
- Update mode:更新的行才输出,每次更新结果集时,仅将被更新的结果行输出到接收器(自 Spark 2.1.1 起可用),不支持排序
- Output sink
file sink:Update mode:更新的行才输出,每次更新结果集时,仅将被更新的结果行输出到接收器(自 Spark 2.1.1 起可用),不支持排序
writeStream .format("parquet") // can be "orc", "json", "csv", etc. .option("path", "path/to/destination/dir") .start()Kafka sink:将输出存储到 Kafka 中的一个或多个 topics 中
writeStream.format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("topic", "updates") .start()Foreach sink:对输出中的记录运行任意计算
Console sink:将输出打印到控制台
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- IBM DS5020硬盘状态Impending failure(reported by controller)
- 修改mysql密码策略,可以修改 成简单密码
- Mac brew install youtube-dl 【 youtube 下载工具:youtube-dl 安装】
- 2024关于洋垃圾服务器避坑指南(一)
- OpenHarmony之编译构建使用指导
- python使用ctypes访问Windows原生API
- 浏览器插件:Web Scraper 基本用法和抓取页面内容(无需写代码,即可爬取数据)
- Python基础(五、掌握for循环、range、break和continue用法,猜数游戏)
- pyqt5 手动释放QPushButton的内存
- SpringBoot的web开发