【论文阅读笔记】Detecting Camouflaged Object in Frequency Domain
1.论文介绍
Detecting Camouflaged Object in Frequency Domain
基于频域的视频目标检测
2022年发表于CVPR
[Paper] [Code]
2.摘要
隐藏目标检测(COD)旨在识别完美嵌入其环境中的目标,在医学,艺术和农业等领域有各种下游应用。然而,以人眼的感知能力来识别遮挡的物体是一项极具挑战性的任务。因此,我们主张COD任务的目标不仅仅是在单个RGB域中模仿人类的视觉能力,而是超越人类的生物视觉。然后,我们引入频域作为一个额外的线索,以更好地检测从背景中隐藏的对象。为了更好地将频率线索纳入CNN模型,我们提出了一个具有两个特殊组件的强大网络。我们首先设计了一个新的频率增强模块(FEM),在频域中挖掘隐藏对象的线索。它包含离线离散余弦变换,然后是可学习的增强。然后,我们使用一个特征对齐融合的特征,从RGB域和频域。此外,为了进一步充分利用频率信息,我们提出了高阶关系模块(HOR)来处理丰富的融合特征。在三个广泛使用的COD数据集上的综合实验表明,该方法明显优于其他国家的最先进的方法的大幅度。
Keywords: 频域、频率增强、隐藏目标检测
3.Introduction
以前的尝试:纹理增强模块、注意力机制来引导模型关注隐藏区域、额外边缘信息、新的监督数据、将分割的对象视为两个阶段。
以前的SOTA COD方法都有一个共同的特点:它们只是通过复杂的技术来增强图像的RGB域信息。然而,根据生物学和心理学的研究动物捕食往往利用感知过滤器分离目标猎物与背景,动物比人类在处理视觉场景时有更多的波段,这使得人类视觉系统(HVS)很难发现隐藏的对象。本文提出COD任务的目标不仅仅是模仿人类在单一RGB域的视觉能力,而是超越人类的生物视觉。因此,为了更好地从背景中检测隐藏的对象,需要图像中的一些其他线索(例如,频域中的线索)。
隐藏对象检测(COD)任务是检测与其周围环境融合的隐藏对象。之前的工作:①首先粗略地搜索隐藏的对象,然后执行分割。②将实例分割和对抗性攻击用于COD的方法。③提出了一种基于图的模型,通过对多级关系的综合推理,同时执行隐藏对象检测和隐藏对象感知边缘提取。④考虑了隐藏对象和背景之间的细微纹理差异。
频域中的压缩表示包含用于图像理解任务的丰富模式。之前已经有从频域提取特征以分类图像和将空间域CNN模型转换到频域的算法。还有为了避免复杂的模型转换过程,使用SE-Block来选择频率信道。有人提出频道注意网络。尽管以前的方法在频域上取得了成就,但如何建模频域和RGB域之间的相互作用关系以进行密集预测几乎没有探索。
设计了频率增强模块,将频域感知线索引入CNN模型;特征对齐融合RGB信息与频域信息;设计了频率损失,直接限制在频率和引导网络更专注于频率信号;为了区分真实的隐藏对象,提出了高阶关系模块(由于目标和噪声对象总是共享相似的结构信息,低阶关系不足以获得区分特征)。
4.网络结构详解
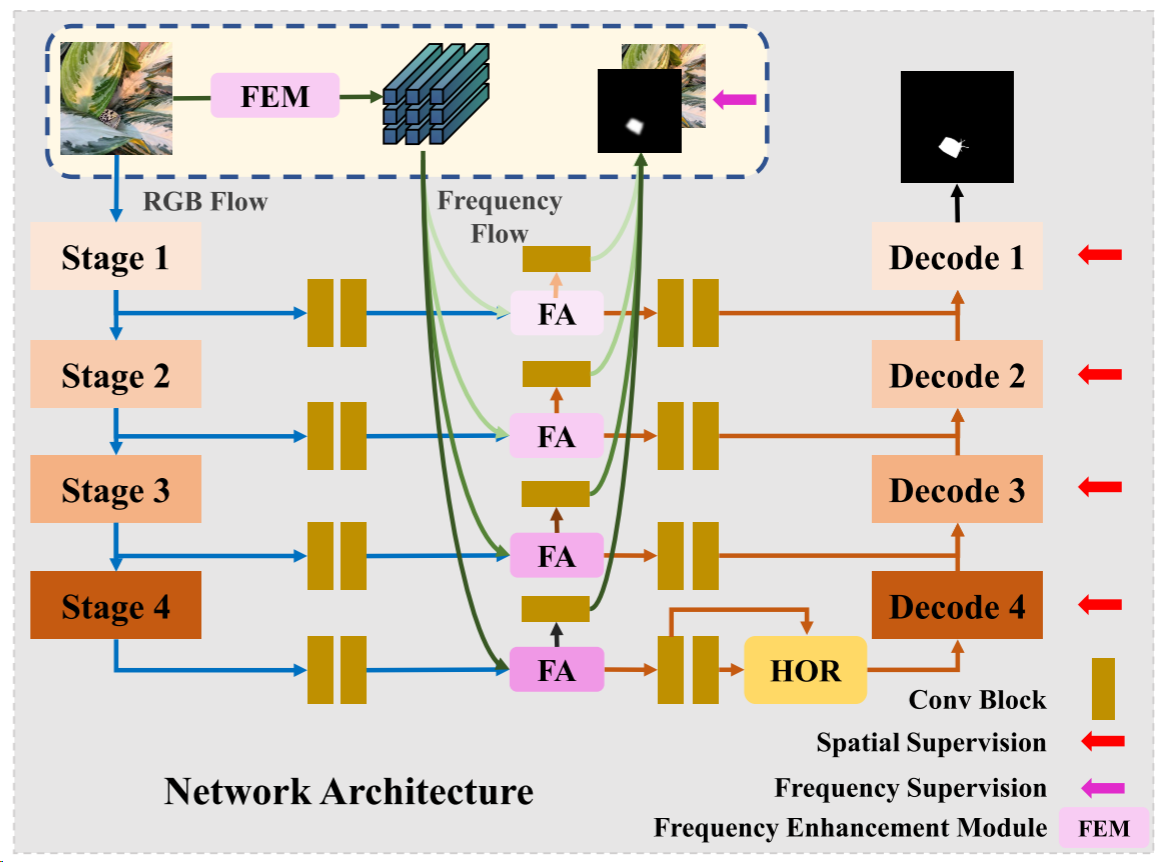
上图是本文的网络结构图,主干采用Res2Net和ResNet50进行特征提取。首先RGB输入被转换到频域并由频率增强模块(FEM)增强。RGB和频率输入分别以RGB流和频率流的形式送入网络。特征对齐(FA)是用来融合这些功能,从RGB和频域。为了在特征中发现更多细微的差异以区分被隐藏的对象,在主网络中构建了高阶关系模块(HOR)。令
x
r
g
b
∈
R
H
×
W
×
3
x_{rgb} ∈ R^{H×W×3}
xrgb?∈RH×W×3表示RGB输入,其中H,W是图像的高度和宽度。并且来自骨干的每一层的最后一个残差块的特征图可以被认为是{X1,X2,X3,X4}。那么所有这些特征图在跳过连接中被处理并且以自底向上的方式被解码。每个解码块由两个卷积层组成,后面是BN和ReLU。
FEM频率增强模块
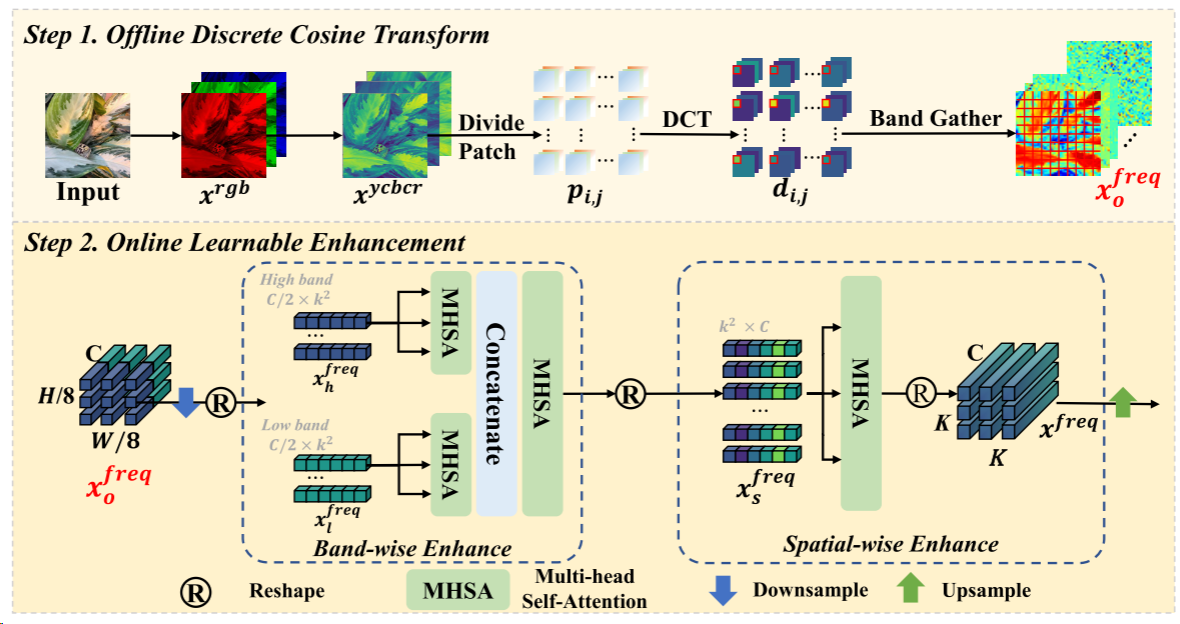
FEM把RGB输入转换到频域并进行频率增强。FEM包含两个步骤:离线DCT(离散余弦变换)过程和神经网络在线增强。
离线离散余弦变换。也就是上图中的step1。首先处理输入的RGB图像,将 x r g b x^{rgb} xrgb变换到 Y C b C r YCbCr YCbCr空间(表示为 x y c b c r x^{ycbcr} xycbcr ∈ R H × W × 3 R^{H×W×3} RH×W×3)。然后,将 x y c b c r x^{ycbcr} xycbcr划分为一组8×8块(在图像的滑动窗口上密集地进行DCT是JPEG压缩等频率处理的常见操作),可以得到{ p i , j c p^c_{ i,j} pi,jc?| 1 ≤ i,j ≤ H 8 \frac{H}{8} 8H? }, p i , j c p^c_{ i,j} pi,jc? ∈ R 8 × 8 R^{8×8} R8×8表示某个颜色通道的补丁。每片图像经离散余弦变换(DCT)处理后得到频谱 d i , j c d^c_{ i,j} di,jc? ∈ R 8 × 8 R^{8×8} R8×8,其中每个值对应于某一频带的强度。为了将相同频率的所有分量分组到一个通道中,展开频谱并重新整形它们以形成新的输入(把三维变成一维),遵循补丁索引: x o f r e q = x i , j f r e q = f l a t t e n ( d i , j ) x^{freq}_o = x^{freq}_{i,j} = flatten(d_{i,j}) xofreq?=xi,jfreq?=flatten(di,j?),其中 x o f r e q x^{freq}_o xofreq? ∈ R H 8 × W 8 × 192 R^{\frac{H}{8} ×\frac{W}{8}×192} R8H?×8W?×192, d i , j d_{i,j} di,j? ∈ R 8 × 8 × 3 R^{8×8×3} R8×8×3表示所有 d i , j c d^c_{i,j} di,jc?的级联。通过这种方式,重新排列的信号,在一个补丁的锯齿状秩序和每个通道的 x o f r e q x^{freq}_o xofreq?属于一个频带。因此,原始颜色输入被变换到频域。
索引中各值的含义: x o f r e q x^{freq}_o xofreq?是三维数组,是频谱展开的最终结果。对于原始图像的每个8x8块,我们会得到一个大小为 192 的频谱展开结果。 x i , j f r e q x^{freq}_{i,j} xi,jfreq?表示图像中位置为(i,j)的8x8块,经过频谱展开后的结果。 f l a t t e n ( d i , j ) flatten(d_{i,j}) flatten(di,j?)表示图像中位置为(i,j)的8x8块的频谱,经过频谱展开成一维数组。
RGB与YCbCr都是颜色空间。
分离亮度和色度信息:YCbCr颜色空间将亮度信息(Y)与色度信息(Cb和Cr)分离开来。亮度表示图像的明亮度,而色度表示图像的颜色信息。这种分离使得在压缩和处理图像时更加方便,因为在某些情况下,我们可能更关心亮度而不是具体的颜色信息。
人眼感知: YCbCr 颜色空间更符合人眼的感知。人眼对亮度更为敏感,而对颜色的感知相对较弱。通过将图像分成亮度和色度,可以更好地利用有限的数据量来表示图像,尤其在视频压缩等应用中。
压缩和传输效率: 在许多应用中,如视频压缩、广播和存储,YCbCr 被广泛用于提高效率。由于人眼对亮度更敏感,可以对亮度信号进行更高的采样率,而对色度信号进行较低的采样率,从而减小数据量,提高压缩效率。
色彩子样: 在YCbCr中,色度信息被表示为差异信号(Cb和Cr),这种表示方式有助于色彩子样,即降低色彩信息的采样率,以减小数据量。
总的来说,RGB颜色空间更适合直观地表示颜色,而YCbCr颜色空间则更适合处理和传输图像,尤其是在需要考虑带宽和存储空间的情况下。
在线学习增强。即上图中的Step2。其中图像被映射到频域并由可学习模块增强,以发现隐藏在频率空间中的伪装对象的线索。在实际应用中,图像中的物体种类繁多,背景复杂,固定的离线DCT算法可能无法很好地处理这些问题。因此还需要一个适应性学习过程来适应复杂的场景。由于信息在JPEG压缩等预处理过程中会丢失。所以需要加强频率信号;因此,引入在线学习增强,以增加信号的适应性。从单个补丁内和补丁之间构建增强模块。
参考论文[Image Enhancement Using a Contrast Measure in the Compressed Domain],对压缩域进行直接增强,通过对DCT系数的处理来增强图像。基于对比度度量实现的,对比度度量定义为DCT矩阵的频带中的高频和低频内容的比率。
下面是论文里的内容:Image Enhancement Using a Contrast Measure in the Compressed Domain
JPEG图像压缩由编码器解码器构成。编码器中,图像被分成不重叠的8*8的块,然后对每个8 × 8块计算二维DCT。一旦获得DCT系数,就使用指定的量化表对它们进行量化。DCT系数的量化是一个有损过程,在这一步中,许多小系数(通常是高频)被量化为零。DCT矩阵的Z字形扫描之后的熵编码利用该属性来降低编码系数所需的比特率。在解码器中,压缩图像被解码,然后通过逐点乘以量化表和逆DCT变换进行解量化。设 x i , j {x_{i,j}} xi,j? 为原始图像中的一个8 × 8块,其DCT变换为 d k , l {d_{k,l}} dk,l?。2-DCT变换表示为
k,l ∈{0~7},
DCT逆变换为(3):
从上式中,可以看到每个 d k , l d_{k,l} dk,l? 表示对应于第kl个波形的贡献,并且输出DCT块中的系数 d k , l d_{k,l} dk,l? 分别按照水平和垂直空间维度中增加的空间频率的顺序从左到右和从上到下排列。DCT系数的空间频率特性提供了一种自然的方式来定义DCT域中的对比度度量。因此,可以将对比度度量定义为DCT矩阵的频带中的高频和低频内容的比率。
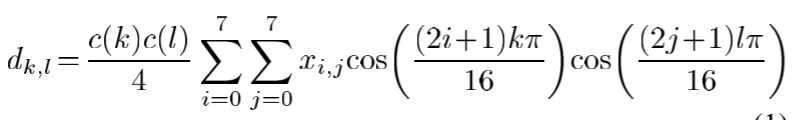
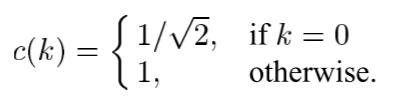
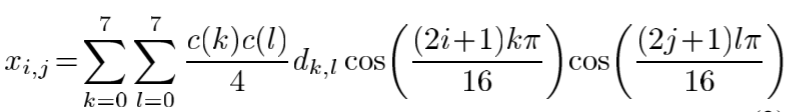
频带的划分:8*8的块组成的二维DCT输出矩阵,可以把系数沿右上左下的对角可划分成15个频带,第n频带由具有的系数 n = k + l n=k+l n=k+l组成。定义的频带给出了近似于圆的菱形,因此选择近似相等的径向频率。因此,使用(3)通过仅保留一个频带而生成的图像块可以被认为是原始图像块的带通版本。随着频带数的增加,带通图像块的频率内容对应于更高的频率,因此,创建了原始的多尺度结构。我们的局部对比度度量定义在每个波段上,波段数大于0。第n波段的对比度定义为:
频谱带上的平均振幅:(5)
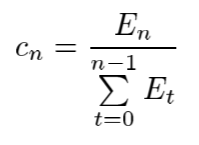
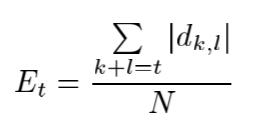
令原始块的对比度为 C = ( c 1 , c 2 . . . ) C=(c_1,c_2...) C=(c1?,c2?...),其中 c n c_n cn?是对应于 E n E_n En?的特定频带处的对比度,并且令增强块的对比度表示为 C  ̄ = ( c  ̄ 1 , c  ̄ 2 . . . ) \overline{C}=(\overline{c}_1,\overline{c}_2...) C=(c1?,c2?...)。例如,如果希望针对所有频率均匀地增强对比度,则 c  ̄ n = λ c n \overline{c}_n=λc_n cn?=λcn?
即 E  ̄ n = λ H n E n , n ≥ 1 \overline{E}_n=λH_nE_n,n≥1 En?=λHn?En?,n≥1(9),其中 H n = ∑ t = 0 n ? 1 E  ̄ t ∑ t = 0 n ? 1 E t H_n=\frac{\sum^{n-1}_{t=0}{\overline{E}_t}}{\sum^{n-1}_{t=0}{E_t}} Hn?=∑t=0n?1?Et?∑t=0n?1?Et??(10);增强的DCT系数 d  ̄ k , l \overline{d}_{k,l} dk,l?: d  ̄ k , l = λ H k + l d k , l , k + l ≥ 1 \overline{d}_{k,l}=λH_{k+l}d_{k,l}, k+l≥1 dk,l?=λHk+l?dk,l?,k+l≥1(11)
整个算法流程如下:
其实就是:1.先初始化;2.n++,计算 H n H_n Hn?;3.计算 d k , l d_{k,l} dk,l?;4.如果n<14,计算 E  ̄ n \overline{E}_n En?和 E n E_{n} En?,否则算法完成;5.跳到第二步。
(不懂为什么不是n≤14)

首先按照上述方法增强局部频带中的系数。然后对信号进行下采样并将其划分为两部分,低频信号 x l f r e q x^{freq}_{l} xlfreq? 和高信号 x h f r e q x^{freq}_{h} xhfreq? ∈ R 96 × k 2 R^{96×k^2} R96×k2,其中k表示大小。为了增强相应频带中的信号,我们将它们分别馈送到两个多头自注意(MHSA)[Attention is all you need]中,并将它们的输出连接起来以恢复原始形状。然后,再用一个MHSA调和所有不同的频带,并且新形成的信号表示 x f f r e q x^{freq}_{f} xffreq?。MHSA能够捕获输入特征中每个项目之间的丰富相关性。在这一点上,图像的不同频谱完全相互作用。对于DCT,图像块是相互独立的,上述过程只增强了单个图像块。为了帮助网络识别被隐藏对象的位置,还需要在补丁之间建立连接。因此,首先将 x f f r e q x^{freq}_{f} xffreq? 整形为 x s f r e q x^{freq}_{s} xsfreq? ∈ R k 2 × C R^{k^2 ×C} Rk2×C。然后,使用MHSA建模所有补丁之间的关系。最后,上采样并得到增强的频率信号 x f r e q x^{freq} xfreq。 x r g b x^{rgb} xrgb 和 x f r e q x^{freq} xfreq 都被输入网络。
要素对齐
构建FA模块来融合RGB域和频域的特征,如下图所示,特征对齐是一个相互加强的过程。
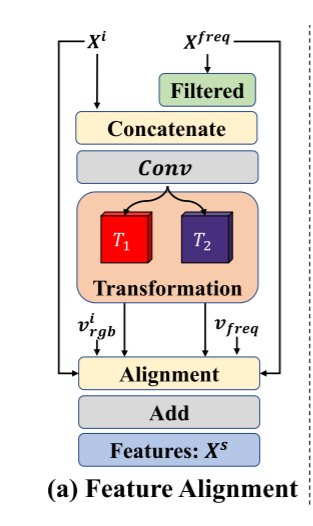
频域信息对隐藏物体更有优势,RGB域信息具有更大的感受野可以补偿频率特征。由于前面的处理确保了
x
r
g
b
x^{rgb}
xrgb和
x
f
r
e
q
x^{freq}
xfreq在空间上对齐,因此在这部分中只将频域与RGB域对齐。
由于CNN对低频信息更敏感,所以先用滤波器处理
x
f
r
e
q
x^{freq}
xfreq:二进制基滤波器
f
b
a
s
e
f_{base}
fbase?覆盖高频段,添加三个可学习的滤波器
f
i
i
=
1
3
{{f_i}^3_{i=1}}
fi?i=13?处理Y、Cb、Cr空间。滤波是频率响应和组合滤波器
f
b
a
s
e
+
σ
(
f
i
)
f_{base} + σ(fi)
fbase?+σ(fi)之间的点积,其中
σ
(
y
)
=
1
?
e
x
p
(
?
y
)
1
+
e
x
p
(
?
y
)
σ(y)= \frac{1?exp(?y)}{1+exp(?y)}
σ(y)=1+exp(?y)1?exp(?y)?。对于输入频域特征
x
f
r
e
q
x^{freq}
xfreq,网络可以通过下式自动聚焦于最重要的频谱:
X
i
f
r
e
q
=
x
i
f
r
e
q
?
[
f
b
a
s
e
+
σ
(
f
i
)
]
X^{freq}_i = x^{freq}_i\bigodot[f_{base} + σ(f_i)]
Xifreq?=xifreq??[fbase?+σ(fi?)],其中
?
\bigodot
?是逐元素乘积。最后,将它们重新组合在一起:
X
f
r
e
q
=
C
o
n
c
a
t
(
[
X
1
f
r
e
q
,
X
2
f
r
e
q
,
X
3
f
r
e
q
]
)
X^{freq} = Concat([X^{freq}_1,X^{freq}_2,X^{freq }_3])
Xfreq=Concat([X1freq?,X2freq?,X3freq?])。
然后,分别从空间域和频率域计算两种信号的变换。由于
X
i
X_i
Xi?具有不同的大小,因此需要将
X
f
r
e
q
X^{freq}
Xfreq缩放到其相应的大小。连接
X
i
X_i
Xi?和
X
f
r
e
q
X^{freq}
Xfreq,然后将其馈送到具有4n个输出通道的Conv层,其输出为T。我们将
T
j
∈
R
H
×
W
×
n
(
j
=
1
,
2
,
3
,
4
)
T_j ∈ R^{H×W×n}(j = 1,2,3,4)
Tj?∈RH×W×n(j=1,2,3,4)从第三维中取出,并将它们整形为
H
W
×
n
HW × n
HW×n。因此,获得RGB域融合矩阵
T
1
∈
R
H
W
×
H
W
T_1 ∈ R^{HW×HW}
T1?∈RHW×HW 和频域的融合矩阵
T
2
T_2
T2?。
T
1
=
T
1
(
T
2
)
T
,
T
2
=
T
3
(
T
4
)
T
T_1 = T_1(T_2)^T,T_2 = T_3(T_4)^T
T1?=T1?(T2?)T,T2?=T3?(T4?)T。其次,对齐特征图。乘以变换和学习向量
v
∈
R
1
×
C
v ∈ R^{1×C}
v∈R1×C以调整每个通道的强度,每个通道的对齐特征:
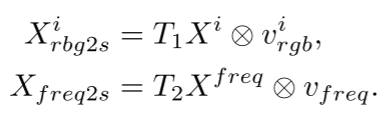
最后,可以通过添加两个域特征来获得融合特征:
X
s
i
=
X
r
b
g
2
s
i
+
X
f
r
e
q
2
s
X^i_s = X^i_{rbg2s} + X_{freq 2s}
Xsi?=Xrbg2si?+Xfreq2s?。通过这种方式,可以利用区分频率信息来找到隐藏的对象,同时保持CNN线索,以确保对象的完整性和细节。\
频率预测损失:
引入了一种新的损失来约束网络:除了直接在RGB域中计算损耗外,还在频域中提供网络的监督。给定输入RGB图像x、对应的真实掩码M和预测掩码Y,定义损失:
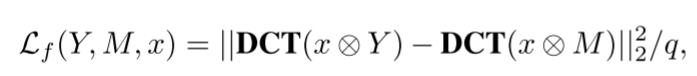
其中,q是量化表,并且
?
\otimes
?表示元素级乘积。特别地,Y和M将首先被复制并扩展到与x相同的大小。
高阶频道选择
为了更好地区分被标记的物体和其他未被标记的物体,需要深入挖掘
X
s
i
X^i_s
Xsi?中不同像素之间的关系。具体地说,真正的干扰和干扰对象可以从背景中分离出来,与频域信息的帮助。然而,真正的干扰对象和干扰对象通常具有极其相似的结构信息,并且频域线索很难区分细微的差异。一种直观的方法是引入注意机制(例如常用的自我注意模块[Non-local neural networks])来探索特征
X
s
i
X^i_s
Xsi?内不同像素的关系,这可能有助于区分细微的差异。然而,常用的注意机制只能捕捉到低层次的关系,不足以发现这种细微的差异。因此,本文提出了一个高阶关系模块(HOR)来解决这个问题,以充分利用频率信号中的信息,如下图所示。
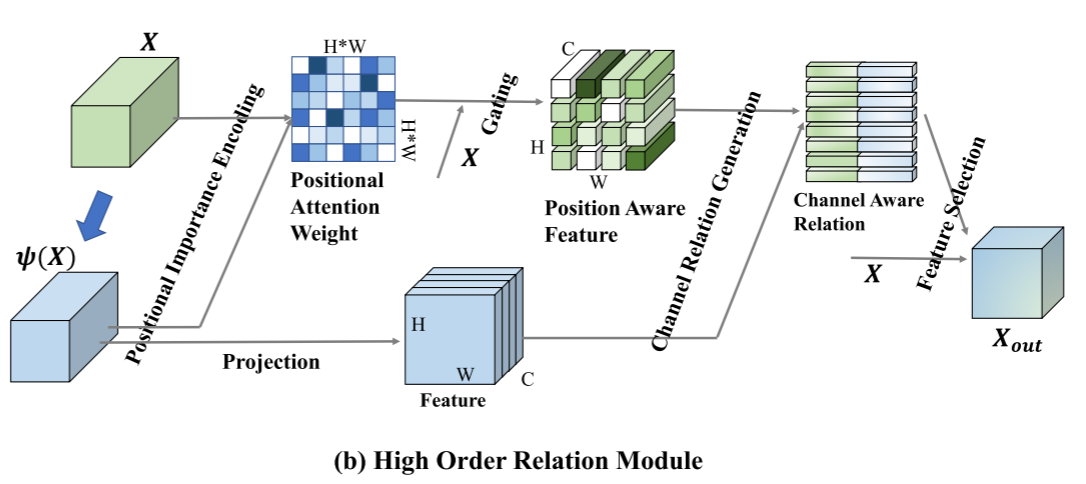
通过采用位置感知的门控操作来构造结构关系,从而为进一步的信道交互和判别谱选择提供高阶空间增强。设
X
∈
R
C
×
H
×
W
X ∈ R^{C×H×W}
X∈RC×H×W表示输入特征,首先将其整形为
C
×
H
W
C×HW
C×HW。由于频率响应来自局部区域,因此需要对具有位置重要性的原始特征进行编码,以将被捕获的对象与其他对象区分开。位置注意力权重可以表示为:
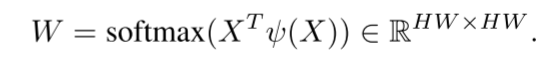
ψ(X)表示比X更后面的层,具有更大的感受野。因此,W用作注意力权重以找到跨不同层的RGB和频率响应相关性。然后,位置权重加强原始特征,并随后通过自适应选通操作来选择出现不同样本时最有用的特征:
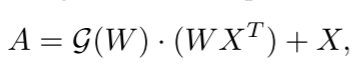
其中
g
(
W
)
∈
R
H
W
g(W)∈ R^{HW}
g(W)∈RHW表示由FC层生成的选通权重,并且它可以被认为是函数
G
:
R
H
W
→
R
1
G:R^{HW} → R^1
G:RHW→R1。门控操作是基于空间感知生成的,以形成位置感知特征。
在获得位置增强特征A之后,可以通过类似的操作来构建信道感知关系矩阵:
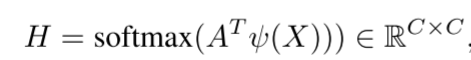
其中C表示位置感知特征的通道维度。通道感知关系中的每个张量具有对应于原始特征通道和频谱的语义和频率映射的相同C维。最后,将该关系矩阵应用于X,得到有利于伪装目标的选择信息
X
o
u
t
=
r
e
s
h
a
p
e
(
H
X
)
∈
R
H
×
W
×
C
X_{out} = reshape(HX)∈ R^{H×W×C}
Xout?=reshape(HX)∈RH×W×C。然后将特征Xout馈送到解码过程中。
监督损失
如网络整体结构图中可见,令{D1,D2,D3,D4}表示从解码块的每一级提取的特征。在网络中的不同分辨率下进行四次预测{Pi}4 i=1,并且在每次FA之后从卷积层进行{Yi}4 i=1。每个Pi和Yi首先被重新缩放到输入图像大小。通过频率感知损失Lf在频域中监督网络。还在通用RGB域中提供监督,以确保细节。将联合收割机的加权BCE损失率和加权IoU损失率结合起来,以更多地关注牵引区域。损失函数定义为:
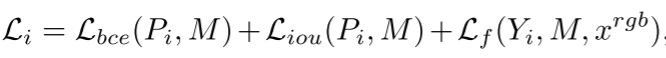
其中M表示真值标签,i表示网络的第i级。最后,总损失函数为:
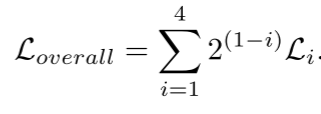
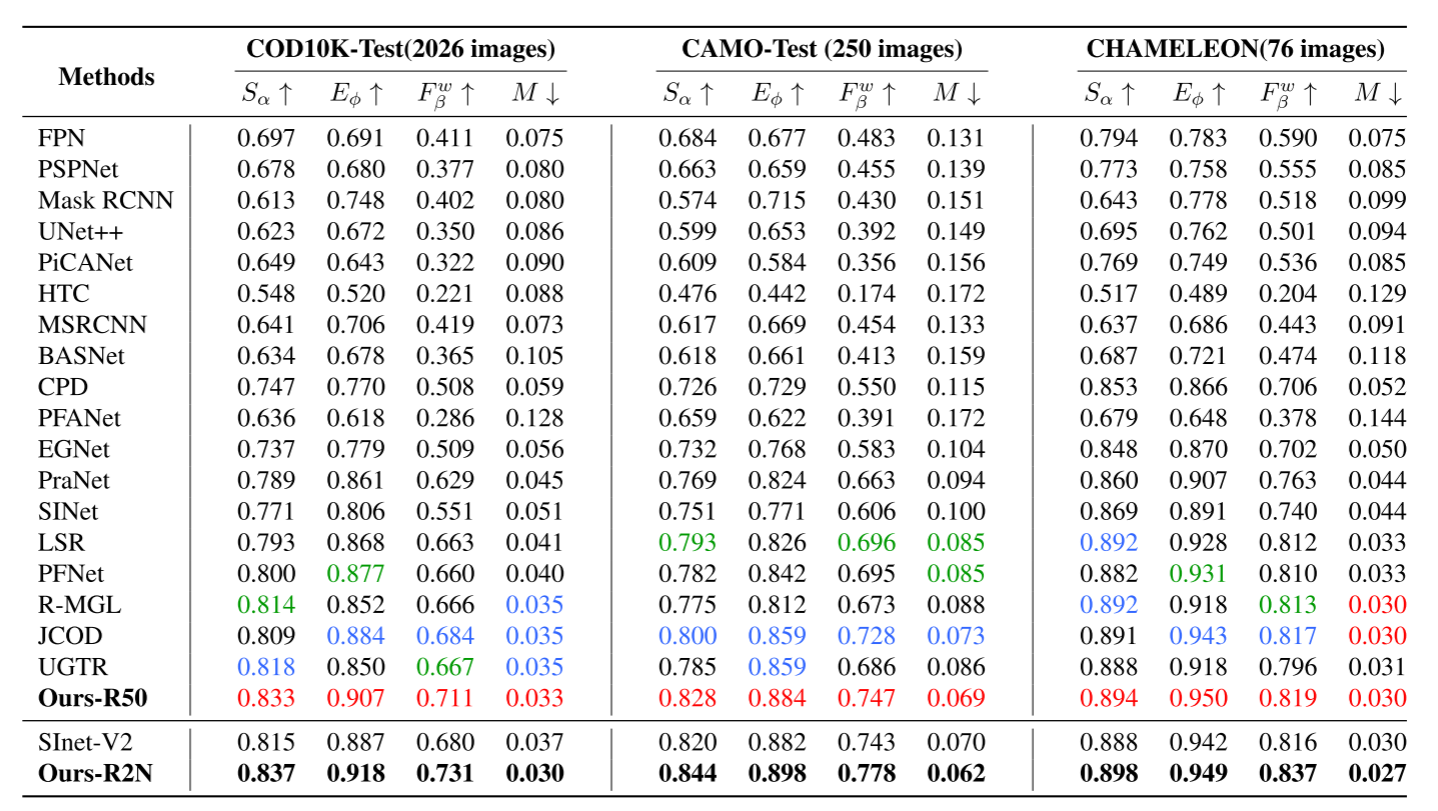
5. 结果

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 码农维权——你知道法院开庭是怎么样吗?
- SAP_ABAP_选择屏幕的DIV布局功能实现步骤 && SAP资产负债表的实现步骤
- java的main方法是什么意?
- MySQL外键约束 一对多 多对多
- 4_操作符详解
- Java内存模型(JMM)是基于多线程的吗
- 谈谈我的三次考研经历
- 跨境批量下单购物商城平台开发(H5,app)
- C++_拷贝构造函数
- 如何使用手机公网远程访问本地群辉Video Station中视频文件【内网穿透】