大模型学习之书生·浦语大模型6——基于OpenCompass大模型评测
发布时间:2024年01月22日

基于OpenCompass大模型评测
关于评测的三个问题Why/What/How
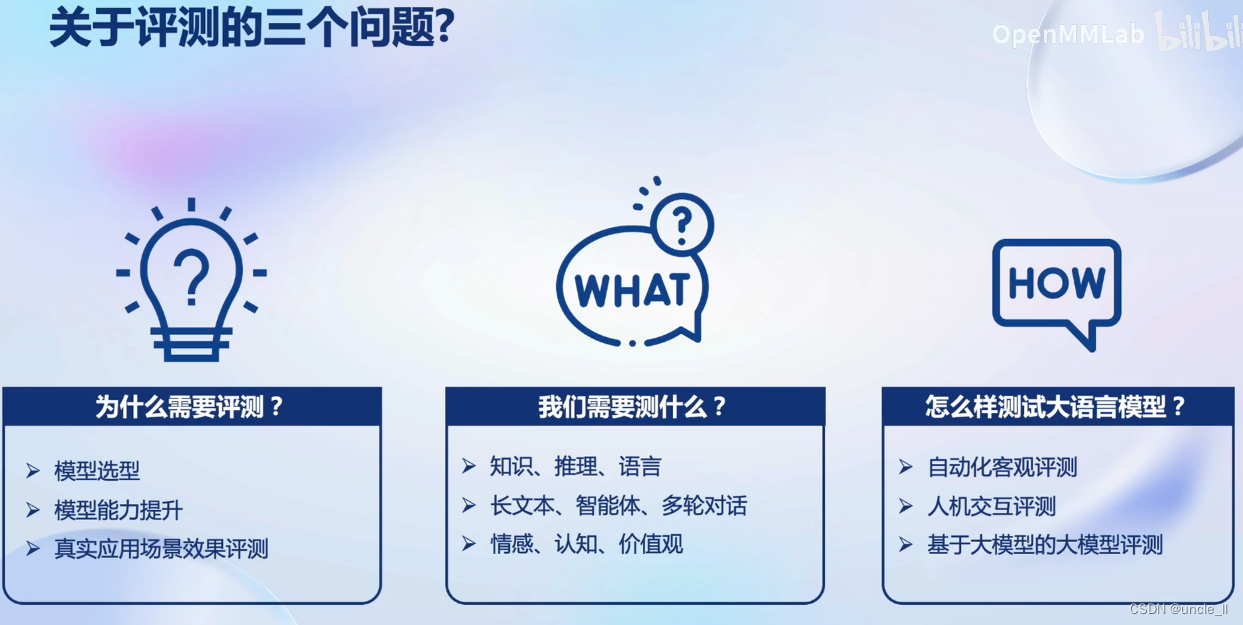
Why


What
有许多任务评测,包括垂直领域
How



包含客观评测和主观评测,其中主观评测分人工和模型来评估。
提示词工程

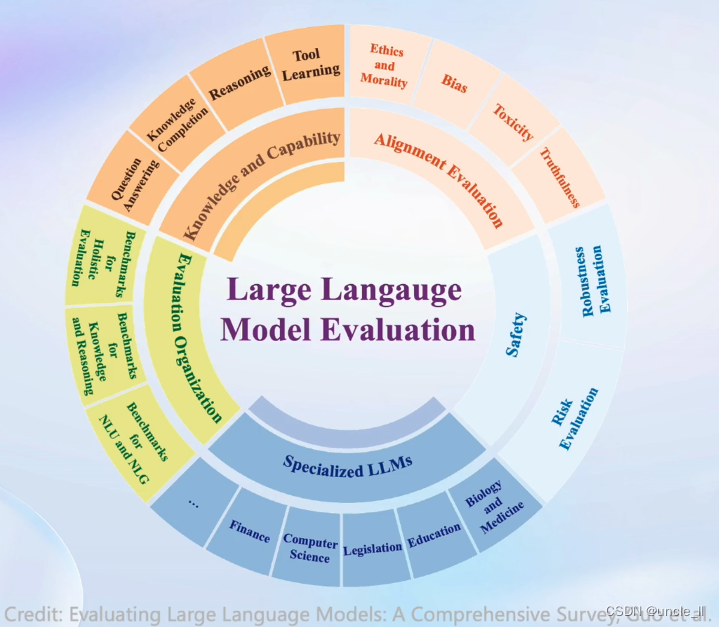
主流评测框架

OpenCompass 能力框架


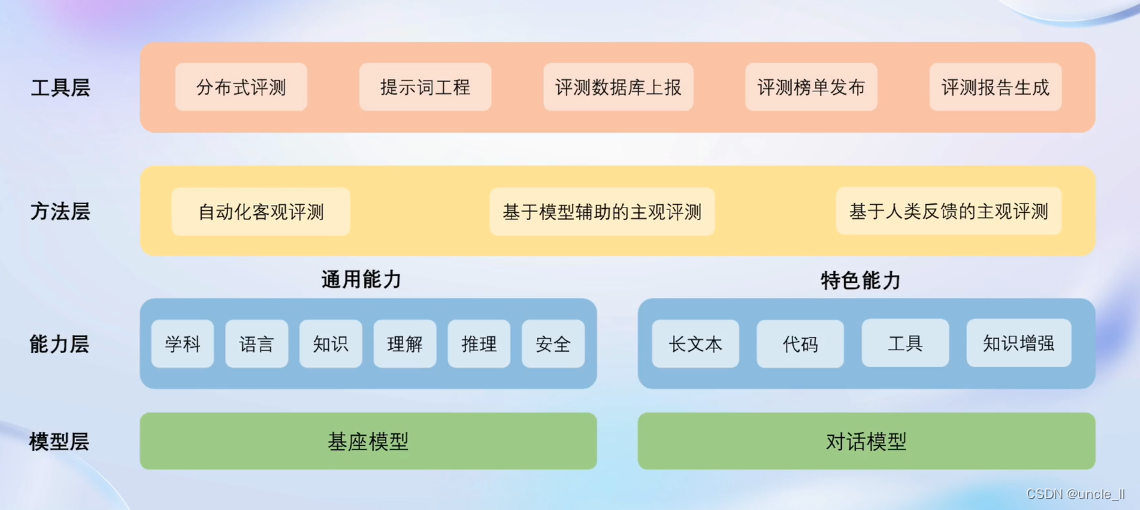
- 模型层
- 能力层
- 方法层
- 工具层

支持丰富的模型
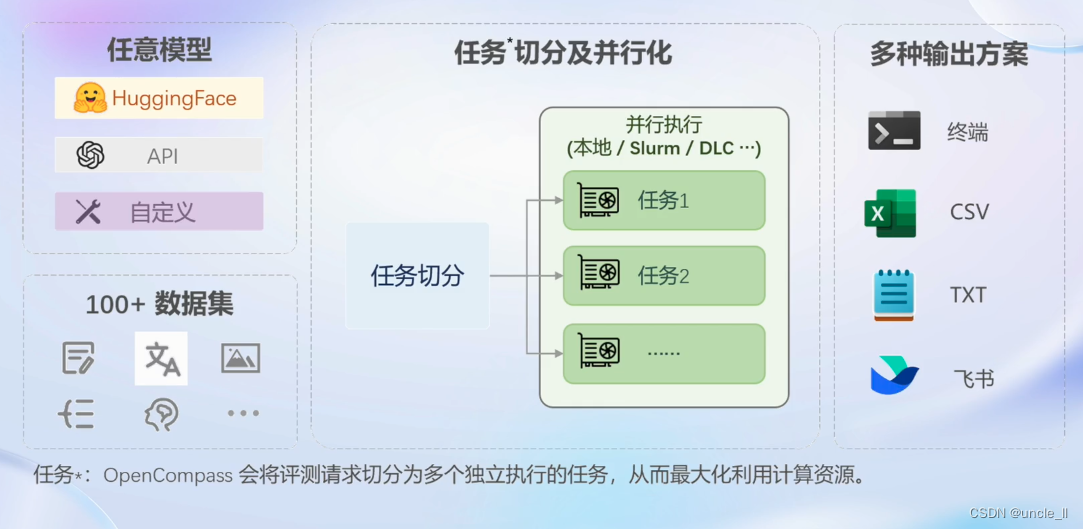
评测流水线设计,能切分多个独立执行的任务,最大化利用计算资源。
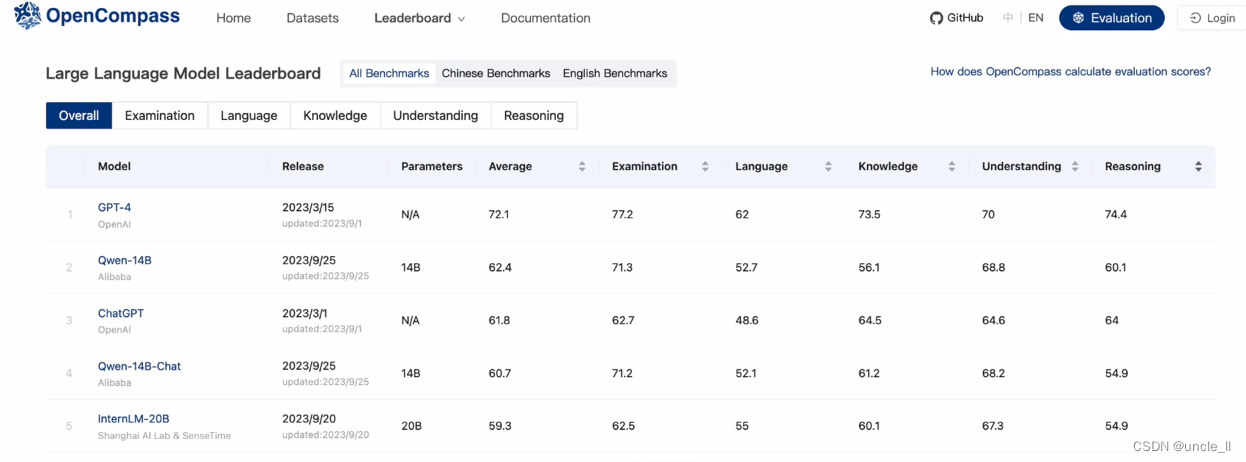
大模型能力对比结果输出
前言探索
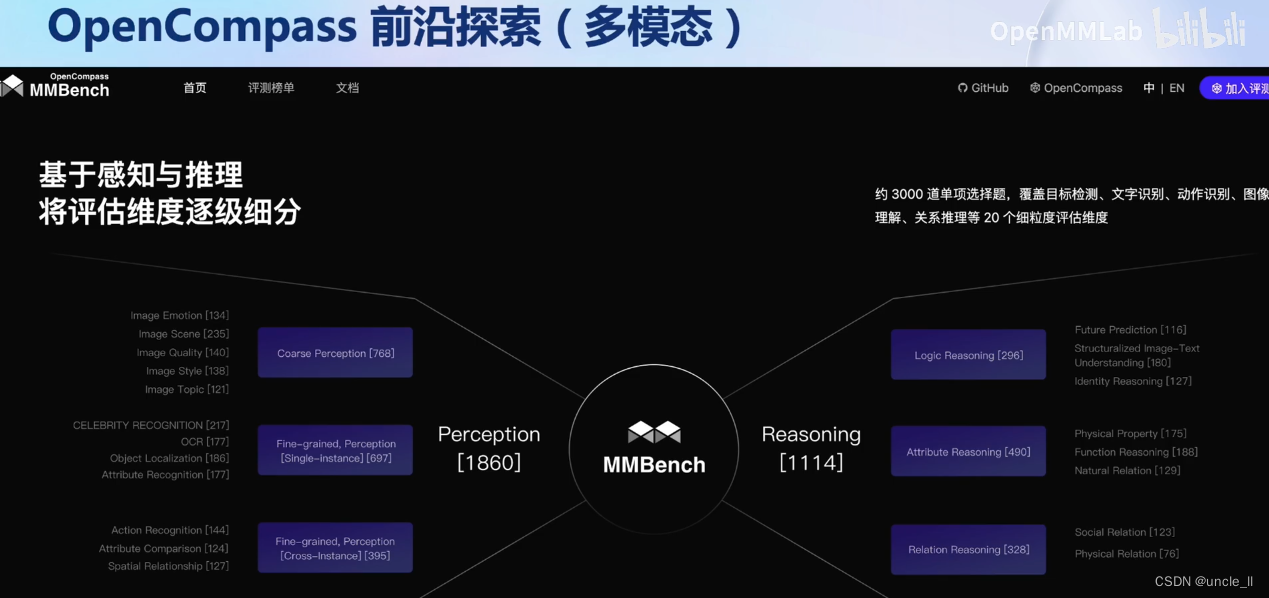
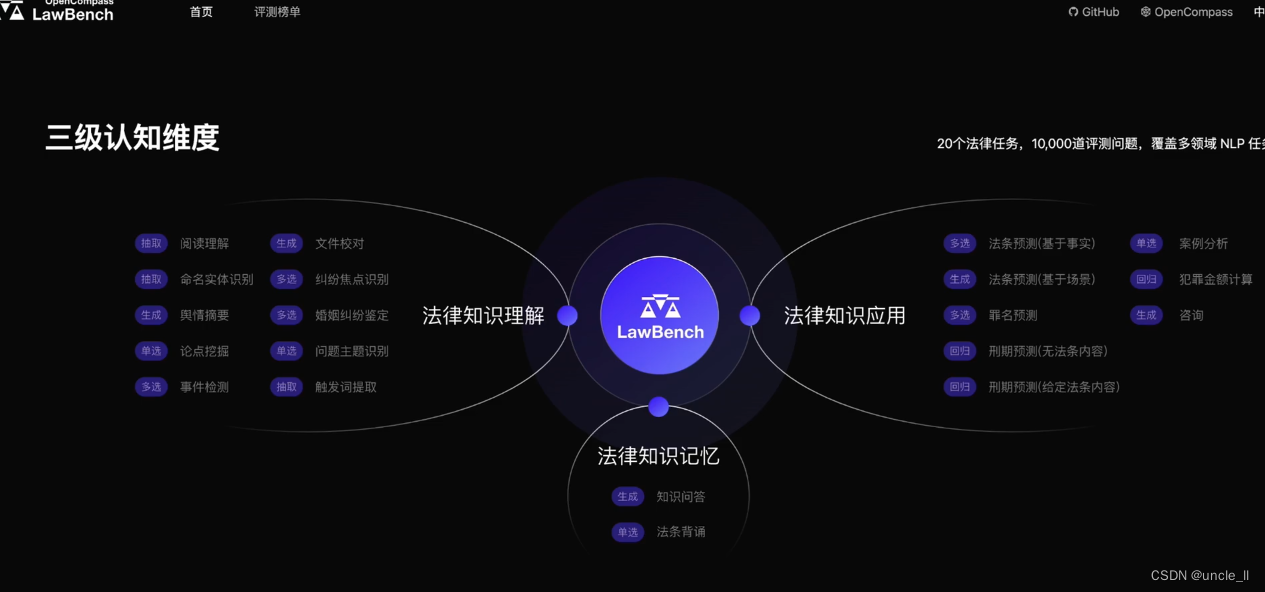
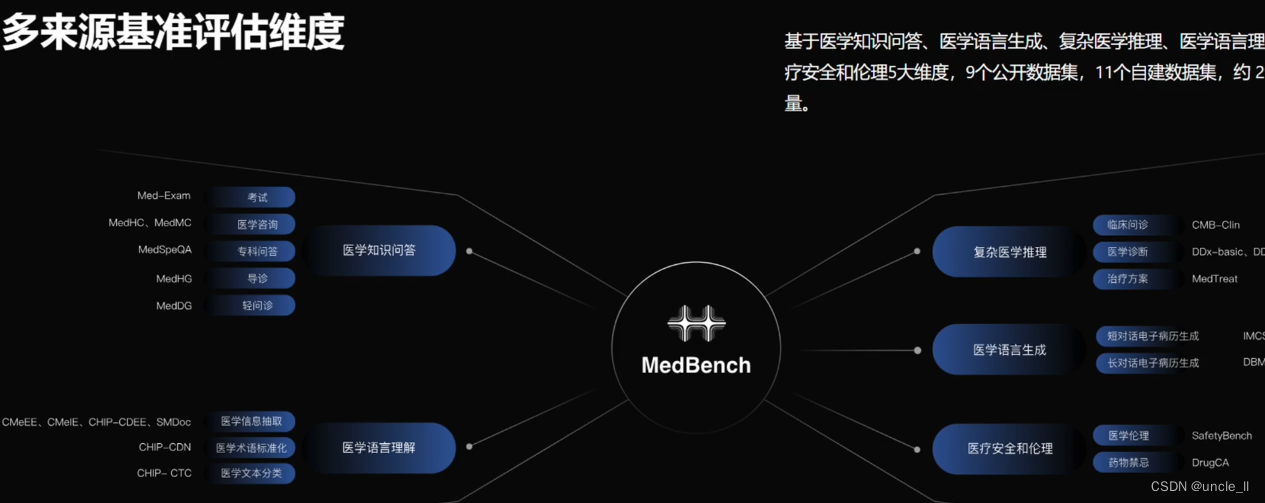
探索性方向涵盖:
- 多模态
- 法律
- 医生
挑战
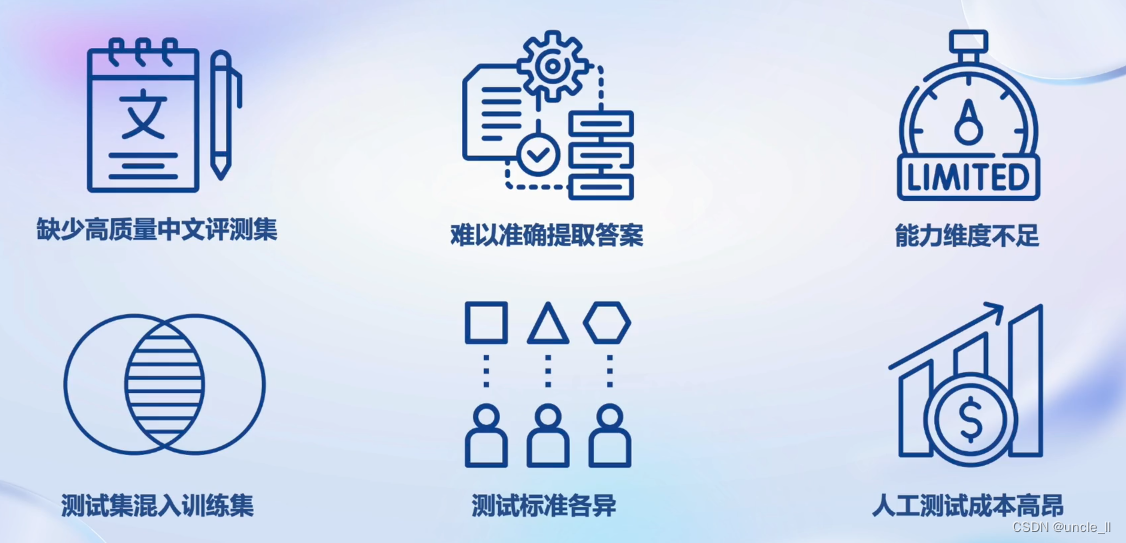
实践
创建开发环境和准备数据集

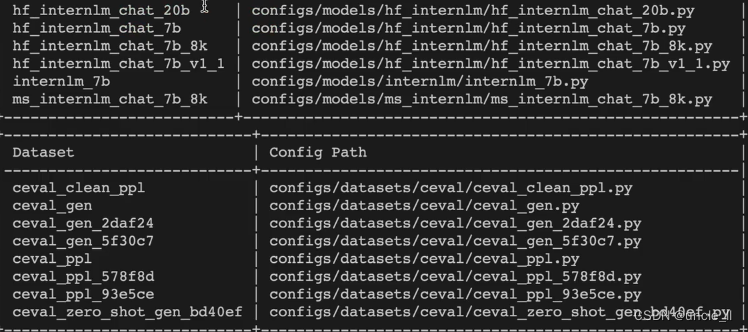
查看支持的数据集:
启动评测
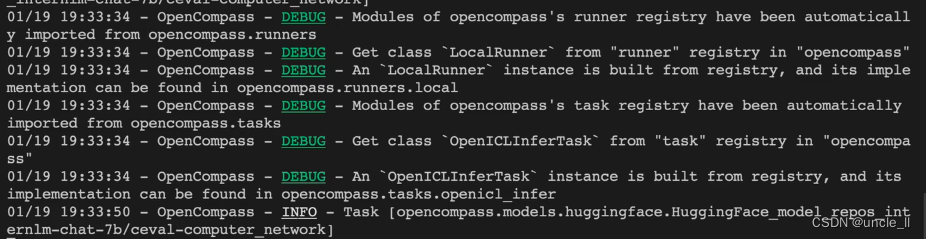
客观评测
主要是run.py代码文件

- datasets:指定数据集
- hf-path:模型文件
- tokenizer-path:tokenizer路径
- max-seq-len:模型读入的最大长度
- max-out-len:模型输出的最大长度,客观题设置一般较小
- –debug:debug模式,打印出所有的过程

主观评测
主要是eval_sbujective_alignbench.py文件修改,需要注意model,max_out_len等处的修改。
文章来源:https://blog.csdn.net/uncle_ll/article/details/135727570
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python基础(十八、文件操作读取)
- JS 遍历本月所有日期
- 浅谈当下企业环境下建设企业微电网能效系统的重要性
- Go语言实现跳动的爱心(附带源码)
- 核货宝订单管理系统提高企业效率
- 数组与 Web 程序打包
- 企微群发宝:企业微信营销的新利器
- 【Python】—— pandas数据处理
- LENOVO联想笔记本小新Pro 14 IRH8 2023款(83AL)电脑原装出厂Win11系统恢复预装OEM系统
- 建筑项目管理系统的设计与实现(源码+开题)