08. Springboot集成webmagic实现网页爬虫
目录
3.1、创建Springboot,并引入webmagic依赖
1、前言
在信息化的时代,网络爬虫已经成为我们获取和处理大规模网络数据的重要工具。如果将现有网络上的海量数据使用爬虫工具将数据爬取保存下来,并进行分析,就可以挖掘出一些潜在的价值。而现在市面上也出现了很多爬虫工具以及爬虫框架,今天将介绍下Java体系下一款简单使用的爬虫框架WebMagic,并可以很简单的与Springboot进行集成。
2、WebMagic
WebMagic是一款基于Java的开源爬虫框架,支持注解和设计模式,简化了爬取任务的实现。官网地址:Introduction · WebMagic Documents。
官网给出的概述:
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。
这部分提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫。
扩展部分(webmagic-extension)提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开发。
另外WebMagic还包括一些外围扩展和一个正在开发的产品化项目webmagic-avalon。
官网给出的总体架构设计图:

总架构图中我们可以发现几个核心模块,分别为Pipeline,Scheduler,Downloader,PageProcesser。其中PageProcesser便是我们今天会用到的用于实现网页内容处理的类。
3、Springboot集成Webmagic
需求场景:爬取百度搜索引擎上的热搜数据,包含标题和连接。也就是首页右侧的内容。

3.1、创建Springboot,并引入webmagic依赖
目前webmagic最新依赖版本为0.10.0。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>springboot-webmagic</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-webmagic</name>
<description>springboot-webmagic</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- webmagic核心库 -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.10.0</version>
</dependency>
<!-- webmagic扩展库 -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.10.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3.2、定义PageProcessor
创建一个网页内容处理器类BaiduHotSearchPageProcessor,用于访问http://www.baidu.com地址,以及对他的网页内容进行解析。
public class BaiduHotSearchPageProcessor implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
/**
* 定制爬虫逻辑的核心接口,在这里编写抽取逻辑
* @param page
*/
@Override
public void process(Page page) {
System.out.println(page.getHtml());
/**
* 通过page.getHtml()可以获取到main函数中Spider.create(new BaiduHotSearchPageProcessor()).addUrl中的地址的网页内容
* 1、通过$或css()方法获取到该page html下某元素dom
*/
Selectable selectable = page.getHtml().$(".theme-hot").select(
new XpathSelector("a[@class='item-wrap_2oCLZ']")
);
List<Selectable> nodes = selectable.nodes();
/**
* 获取到指定的dom后,从这些dom中提取元素内容。
*/
System.out.println("今日百度热搜:");
for (int i = 1; i <= nodes.size() - 1; i++) {
Selectable node = nodes.get(i);
String link = node.$(".item-wrap_2oCLZ", "href").get();
String title = node.$(".c-single-text-ellipsis", "text").get();
System.out.printf("%d、%s,访问地址:%s%n", i, title, link);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
// 创建一个Spider,并把我们的处理器放进去
Spider.create(new BaiduHotSearchPageProcessor())
// 添加这个Spider要爬取的网页地址
.addUrl("https://top.baidu.com/board?platform=pc&sa=pcindex_entry")
// 开启5个线程执行,并开始爬取
.thread(5).run();
}
}运行后,来看下效果:

与百度上的热搜数据比对一下,发现数据如此简单就被我们爬取下来了。
3.3、元素选择
通过上面的例子你会发现,其实整个爬虫的难点不在于工具的使用,而在于我们要爬取内容的元素选择。也就是我们爬取之前需要先定位到我们需要爬取的内容元素规则,按照这些规则在进行proessor的编写。
WebMagic定义了Selectable来进行相关元素的抽取。从上面的例子中可以看到page.getHtml()返回的是最原始的网页内容,多且繁杂,并不是都是我们需要的。Selectable定义了很多API来供我们进行元素选择和抽取,如可以采用xpath,css,或者正则表达式来进行选择。

3.3.1、F12查看网页元素
打开百度热搜网页,按F12出现开发控制台,然后点击左上角的一个小箭头(1的位置),在移动到热搜上的条目(2的位置),然后控制台上就会自动定位到该段内容的元素代码(3的位置)。

接下来就要考察我们的眼力了,通过观察发现,热搜的每一条条目对应的是一个a标签,而这些a标签有一个通用的属性“href”,即该条热搜内容的访问连接。而每个a标签下都有一个class="c-single-text-ellipsis"的div元素。该元素下的文字内容即为标题。
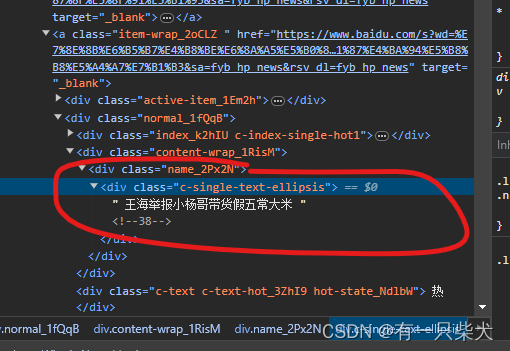
3.3.2、元素选择
既然我们已经找到了合适的规则,那么我们就要选取一种方式来定位这些元素。常用的有xpath,或css定位。我们可以观察到,热搜整个代码块是包含在一个class="theme-hot"的div下的(通常此类的布局都会有一个相应的class或id用来对该布局进行样式定义)。所以我们可以用以下代码定位到热搜的代码片段:
page.getHtml().$(".theme-hot")然后需要在此片段的基础上,继续一层一层往下找,找到我们前面说到的a标签,由于a标签可能会有很多个,所以我们使用xpath选择器选择a标签且class定义为item-wrap_2oCLZ的元素。
Selectable selectable = page.getHtml().$(".theme-hot").select(
new XpathSelector("a[@class='item-wrap_2oCLZ']")
);到此,就可以把我们的a标签全部都找出来了,接下来就是要一条一条的解析a中的内容:
for (int i = 1; i <= nodes.size() - 1; i++) {
Selectable node = nodes.get(i);
String link = node.$(".item-wrap_2oCLZ", "href").get();
String title = node.$(".c-single-text-ellipsis", "text").get();
System.out.printf("%d、%s,访问地址:%s%n", i, title, link);
}其中$("", "")第二个参数就是对应的属性值,这样就可以顺利的爬取到我们所需的内容了。
3.3.3、注意事项
其实,有些朋友已经发现了,我们上面所选取的class=‘item-wrap_2oCLZ’感觉很奇怪,像是动态生成的。确实是,不同网站实现都不一样,如果有遇到动态生成的class,那么采用这种class来定位,可能网页每次刷新每次获取到的都会不一样。因此在选择元素的时候,选取的class或id也要慎重选择。
4、小结
此类爬虫的规则其实就是依靠元素定位来获取我们所需的内容。如果网页元素发生变更,或者xpath路径发生变化,又或者是网页进行了更新,那么都有可能会使当前规则失效,此时就需要重新寻找规律并重新获取元素。因此,如果有想要爬取的朋友要稍微注意下:
- 注意网页元素规则的更新
- 注意爬虫频率,很多网页或接口都具备限流或者IP流量检测的机制,如果爬取的频率太频繁,很容易把别人网站搞崩,又或者是IP被封禁。因此还是要礼貌爬取,文明爬取,合法爬取。
- 注意隐私和版权,如果爬取到了一些数据,且这些数据使用不当,就很容易侵权或成为非法使用者,这点要切记。
因此,科学上网,文明爬取。爬虫虽好,可不要贪杯哦!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一款好用的漏洞扫描工具
- Jetpack Room使用
- 认知能力测验,⑤破解图形推理测试题,校招社招网申在线测评必用
- 微信小程序有几个文件
- 机器学习系列13:通过随机森林获取特征重要性
- python接口自动化(十)--post请求四种传送正文方式(详解)
- vscode运行python,终端能正常运行,输出(Code Runner)不能正常运行
- 代码随想录算法训练营第二十九天| 491.递增子序列、46.全排列 、47.全排列 II
- 2023 | 美团技术团队热门技术文章汇总
- 配置 Prometheus 通过 query-exporter 自定义 SQL 抓取云上MySQL 监控指标