TokenFlow详解
https://github.com/omerbt/TokenFlow/issues/25
https://github.com/omerbt/TokenFlow/issues/31
https://github.com/omerbt/TokenFlow/issues/32
https://github.com/eps696/SDfu
本文主要讲解TokenFlow的Model部分是如何构造的,代码摘自TokenFlow/tokenflow_utils.py。
tokenflow的Model构建逻辑是先加载原始的Stable Diffusion,然后重新注册需要修改的UNet的模块,修改操作的调用首先在run_tokenflow.py中:
self.init_method(conv_injection_t=pnp_f_t, qk_injection_t=pnp_attn_t)
想看懂后面的代码, 首先需要看懂SD的BasicTransformerBlock的源码,最好再看看PnP的源码 pnp-diffusers,因为TokenFlow就是基于PnP改进而来的。
def init_method(self, conv_injection_t, qk_injection_t):
self.qk_injection_timesteps = self.scheduler.timesteps[:qk_injection_t] if qk_injection_t >= 0 else []
self.conv_injection_timesteps = self.scheduler.timesteps[:conv_injection_t] if conv_injection_t >= 0 else []
register_extended_attention_pnp(self, self.qk_injection_timesteps)
register_conv_injection(self, self.conv_injection_timesteps)
set_tokenflow(self.unet)
init_method函数完成了3件事:
(1)register_extended_attention_pnp:replace unet 的 self attention(扩展为KV来自多帧,同时完成inject。
(2)register_conv_injection:replace conv 的 conv_injection (UpBlock的第二个resnet block,完成inject。
(3)set_tokenflow:replace unet 的 16 BasicTransformerBlock to TokenFlowBlock。
其中,qk_injection_timesteps 和 conv_injection_timesteps是两个timestep list,用于控制PnP Inject操作只在前几个step执行。
除了这些对UNet Model的修改,源码中batched_denoise_step函数为了先编辑关键帧也进行了register_pivotal设置关键帧id。在编辑每个batch时前进行了register_batch_idx设置batch id。在预测噪声前register_time为UNet的某些layer设置step t。
接下来,我们将按照顺序一个一个解析,tokenflow在推理过程中,对原始Stable Diffusion模型做的修改。
register_extended_attention_pnp
register_extended_attention_pnp函数的作用:为UNet的所有BasicTransformerBlock layer的attn1(16个)重构forward函数为extend attention的sa_forward,但只对其中的部分attn1(8个)注入injection_schedule使用PnP操作。
由BasicTransformerBlock的结果可知:attn1虽然Class实现上是CrossAttention,但推理时不传入context做KV,本质上是SelfAttention。
class BasicTransformerBlock(nn.Module):
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True):
super().__init__()
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # cross attention
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
def forward(self, x, context=None):
x = self.attn1(self.norm1(x)) + x
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return x
入参:register_extended_attention_pnp函数传入的两个必须参数是unet model和injection_schedule。injection_schedule用于控制推理过程中PnP Injection执行的时间步,因为我们希望只在前几个timestep进行PnP操作。
重构:因为原始tokenflow的extend_attention的forward是sa_forward,是对所有帧进行attention矩阵运算,消耗资源太大,于是我为其添加了sa_3frame_forward仅计算相邻3帧的attention。我重构过的register_extended_attention_pnp函数如下图,在原始基础上添加了一个is_3_frame参数用于选择是否使用sa_3frame_forward。
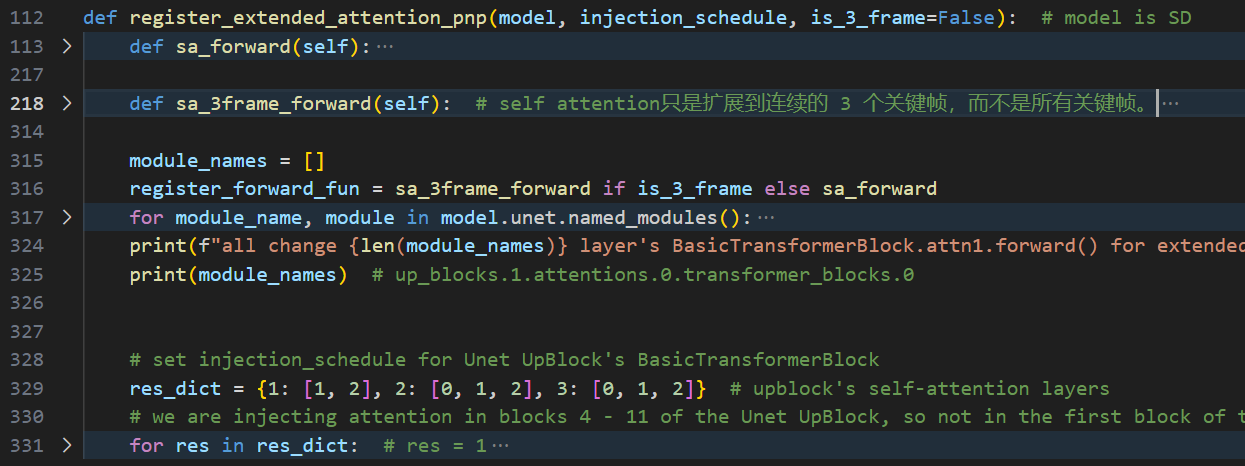
首先我们先跳过sa_forward和sa_3frame_forward这两个函数,看一下如何找到UNet对应的模块并修改其forward方法。
1. 为所有BasicTransformerBlock layer的attn1重构forward
根据 register_forward_fun 判断使用那种sa_forward,然后遍历unet的每个模块,判断改模块是否继承自BasicTransformerBlock ,如果有则为其修改forward,但将其injection_schedule置空(即不执行PnP)。
module_names = []
register_forward_fun = sa_3frame_forward if is_3_frame else sa_forward
for module_name, module in model.unet.named_modules():
if isinstance_str(module, "BasicTransformerBlock"):
module_names.append(module_name)
# replace BasicTransformerBlock.attn1's forward with sa_forward
module.attn1.forward = register_forward_fun(module.attn1)
# set injection_schedule empty[] for BasicTransformerBlock.attn1
setattr(module.attn1, 'injection_schedule', [])
print(f"all change {len(module_names)} layer's BasicTransformerBlock.attn1.forward() for extended_attention_pnp...")
print(module_names) # up_blocks.1.attentions.0.transformer_blocks.0
isinstance_str 判断x的继承的类型列表中是否包含cls_name类:
def isinstance_str(x: object, cls_name: str):
for _cls in x.__class__.__mro__:
if _cls.__name__ == cls_name:
return True
return False
第一次重构了unet中如下16层attention的forward:6个down_block的,9个up_block,1个mid_block的。
down_blocks.0.attentions.0.transformer_blocks.0.attn1
down_blocks.0.attentions.1.transformer_blocks.0.attn1
down_blocks.1.attentions.0.transformer_blocks.0.attn1
down_blocks.1.attentions.1.transformer_blocks.0.attn1
down_blocks.2.attentions.0.transformer_blocks.0.attn1
down_blocks.2.attentions.1.transformer_blocks.0.attn1
up_blocks.1.attentions.0.transformer_blocks.0.attn1
up_blocks.1.attentions.1.transformer_blocks.0.attn1
up_blocks.1.attentions.2.transformer_blocks.0.attn1
up_blocks.2.attentions.0.transformer_blocks.0.attn1
up_blocks.2.attentions.1.transformer_blocks.0.attn1
up_blocks.2.attentions.2.transformer_blocks.0.attn1
up_blocks.3.attentions.0.transformer_blocks.0.attn1
up_blocks.3.attentions.1.transformer_blocks.0.attn1
up_blocks.3.attentions.2.transformer_blocks.0.attn1
mid_block.attentions.0.transformer_blocks.0.attn1
2. 对其中的部分attn1(8个)注入injection_schedule使用PnP操作
在res_dict 的指示下,对具体的attn1修改forward函数,同时为其注册injection_schedule,使用PnP操作。
res_dict = {1: [1, 2], 2: [0, 1, 2], 3: [0, 1, 2]} # upblock's self-attention layers
# we are injecting attention in blocks 4 - 11 of the Unet UpBlock, so not in the first block of the lowest resolution
for res in res_dict: # res = 1
for block in res_dict[res]: # res_dict[res] = [1, 2]
module = model.unet.up_blocks[res].attentions[block].transformer_blocks[0].attn1
module.forward = sa_forward(module)
setattr(module, 'injection_schedule', injection_schedule)
第二次重构8个up_blocks的:
model.unet.up_blocks.1.attentions.1.transformer_blocks.0.attn1
model.unet.up_blocks.1.attentions.2.transformer_blocks.0.attn1
model.unet.up_blocks.2.attentions.0.transformer_blocks.0.attn1
model.unet.up_blocks.2.attentions.1.transformer_blocks.0.attn1
model.unet.up_blocks.2.attentions.2.transformer_blocks.0.attn1
model.unet.up_blocks.3.attentions.0.transformer_blocks.0.attn1
model.unet.up_blocks.3.attentions.1.transformer_blocks.0.attn1
model.unet.up_blocks.3.attentions.2.transformer_blocks.0.attn1
3. sa_forward
PnP的操作:因为TokenFlow的输入同时考虑了PnP和classifer-free guidance,所以原本UNet输入的单个latent变成了3份:source_latents + x + x(其中一个 x 对应edit_prompt,一个 x 对应null_prompt,source_latents对应了source_prompt)。
latent_model_input = torch.cat([source_latents] + ([x] * 2))
这样就可以在Unet推理的时候,直接从输入的latents x中切片,分为3份将source_latents注入到uncond_latents和cond_latents(PnP的注入就是直接替换),对于self-attention,我们只替换Q和K。
source_latents = x[:n_frames]
uncond_latents = x[n_frames:2*n_frames]
cond_latents = x[2*n_frames:]
# source inject uncond
q[n_frames:2*n_frames] = q[:n_frames]
k[n_frames:2*n_frames] = k[:n_frames]
# source inject cond
q[2*n_frames:] = q[:n_frames]
k[2*n_frames:] = k[:n_frames]
Extend_Attention:tokenflow实现扩展的self-attention使用,因为对于第i帧,计算self attention时,Q是第i帧的特征,KV要来自其他所有帧,所以要repeat一下K和V,方便后面计算。
T
b
a
s
e
=
S
o
f
t
m
a
x
(
Q
i
;
[
K
i
1
,
.
.
.
,
K
i
k
]
d
)
?
[
V
i
1
,
.
.
.
,
V
i
k
]
T_{base}=Softmax(\frac{Q^i;[K^{i1},...,K^{ik}]}{\sqrt{d}})\cdot[V^{i1},...,V^{ik}]
Tbase?=Softmax(d?Qi;[Ki1,...,Kik]?)?[Vi1,...,Vik]
# KV reshape and repeat for extend_attention: Softmax(Q_i_frame @ K_all_frame) @ V_all_frame
# (n_frames, seq_len, dim) -> (1, n_frames * seq_len, dim) -> (n_frames, n_frames * seq_len, dim)
k_source = k[:n_frames]
k_uncond = k[n_frames:2 * n_frames].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
k_cond = k[2 * n_frames:].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
v_source = v[:n_frames]
v_uncond = v[n_frames:2 * n_frames].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
v_cond = v[2 * n_frames:].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
因为逐帧进行计算,而且多头注意力逐头进行计算,构造双重for循环计算attention 得到第 i 帧第 j 头的 attention out,最后分别concat帧维度和头维度得到最终atention结果:
Q @ K -> sim:
(b, 1, seq_len, dim//head) @ (b, 1, dim//head, frame*seq_len) -> (b, 1, seq_len, frame*seq_len)
sim @ V -> out:
(b, 1, seq_len, frame*seq_len) @ (b, 1, frame*seq_len, dim//head) -> (b, 1, seq_len, dim//head)
cat each head's out:
(b->n_frames, 1, seq_len, dim//head) -> (n_frames, 1, seq_len, dim//head)
cat each frame's out:
(n_frames, 1, seq_len, dim//head) -> (n_frames, heads, seq_len, dim//heads)
sa_forward完整代码如下:
def sa_forward(self):
to_out = self.to_out # self.to_out = [linear, dropout]
if type(to_out) is torch.nn.modules.container.ModuleList:
to_out = self.to_out[0]
else:
to_out = self.to_out
def forward(x, encoder_hidden_states=None, attention_mask=None):
is_cross = encoder_hidden_states is not None # corss-attention or self-attention
h = self.heads
batch_size, sequence_length, dim = x.shape # (3*n_frames, seq_len, dim)
# batch: 前n_frames个样本为source feature, 中间n_frames个样本为uncond featur, 后n_frames个样本为cond feature
n_frames = batch_size // 3
# source_latents = x[:n_frames], uncond_latents = x[n_frames:2*n_frames], cond_latents = x[2*n_frames:]
encoder_hidden_states = encoder_hidden_states if is_cross else x
q = self.to_q(x)
k = self.to_k(encoder_hidden_states)
v = self.to_v(encoder_hidden_states)
# PnP Injection QK:只需要sample过程中的前几个timestep进行injection (判断t是否符合),且只在UpBlock进行inject
if self.injection_schedule is not None and (self.t in self.injection_schedule or self.t == 1000):
# source inject into unconditional
q[n_frames:2 * n_frames] = q[:n_frames]
k[n_frames:2 * n_frames] = k[:n_frames]
# source inject into conditional
q[2 * n_frames:] = q[:n_frames]
k[2 * n_frames:] = k[:n_frames]
# KV reshape and repeat for extend_attention: Softmax(Q_i_frame @ K_all_frame) @ V_all_frame
# (n_frames, seq_len, dim) -> (1, n_frames * seq_len, dim) -> (n_frames, n_frames * seq_len, dim)
k_source = k[:n_frames]
k_uncond = k[n_frames:2 * n_frames].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
k_cond = k[2 * n_frames:].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
v_source = v[:n_frames]
v_uncond = v[n_frames:2 * n_frames].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
v_cond = v[2 * n_frames:].reshape(1, n_frames * sequence_length, -1).repeat(n_frames, 1, 1)
# project QKV's source, cond and uncond, respectively
q_source = self.reshape_heads_to_batch_dim(q[:n_frames]) # q (n_frames*heads, seq_len, dim//heads)
q_uncond = self.reshape_heads_to_batch_dim(q[n_frames:2 * n_frames])
q_cond = self.reshape_heads_to_batch_dim(q[2 * n_frames:])
k_source = self.reshape_heads_to_batch_dim(k_source) # kv (n_frames*heads, n_frames * seq_len, dim//heads)
k_uncond = self.reshape_heads_to_batch_dim(k_uncond)
k_cond = self.reshape_heads_to_batch_dim(k_cond)
v_source = self.reshape_heads_to_batch_dim(v_source)
v_uncond = self.reshape_heads_to_batch_dim(v_uncond)
v_cond = self.reshape_heads_to_batch_dim(v_cond)
# split heads
q_src = q_source.view(n_frames, h, sequence_length, dim // h)
k_src = k_source.view(n_frames, h, sequence_length, dim // h)
v_src = v_source.view(n_frames, h, sequence_length, dim // h)
q_uncond = q_uncond.view(n_frames, h, sequence_length, dim // h)
k_uncond = k_uncond.view(n_frames, h, sequence_length * n_frames, dim // h)
v_uncond = v_uncond.view(n_frames, h, sequence_length * n_frames, dim // h)
q_cond = q_cond.view(n_frames, h, sequence_length, dim // h)
k_cond = k_cond.view(n_frames, h, sequence_length * n_frames, dim // h)
v_cond = v_cond.view(n_frames, h, sequence_length * n_frames, dim // h)
out_source_all = []
out_uncond_all = []
out_cond_all = []
# each frame or single_batch frames
single_batch = n_frames<=12
b = n_frames if single_batch else 1 # b=1
# do attention for each frame respectively. frames [frame:frame=b]
for frame in range(0, n_frames, b):
out_source = []
out_uncond = []
out_cond = []
# do attention for each head respectively. head j
for j in range(h):
# do attention for source, cond and uncond respectively, (b, 1, seq_len, dim//head) @ (b, 1, dim//head, frame*seq_len) -> (b, 1, seq_len, frame*seq_len)
sim_source_b = torch.bmm(q_src[frame: frame+ b, j], k_src[frame: frame+ b, j].transpose(-1, -2)) * self.scale
sim_uncond_b = torch.bmm(q_uncond[frame: frame+ b, j], k_uncond[frame: frame+ b, j].transpose(-1, -2)) * self.scale
sim_cond = torch.bmm(q_cond[frame: frame+ b, j], k_cond[frame: frame+ b, j].transpose(-1, -2)) * self.scale
# append each head's out, (b, 1, seq_len, frame*seq_len) @ (b, 1, frame*seq_len, dim//head) -> (b, 1, seq_len, dim//head)
out_source.append(torch.bmm(sim_source_b.softmax(dim=-1), v_src[frame: frame+ b, j]))
out_uncond.append(torch.bmm(sim_uncond_b.softmax(dim=-1), v_uncond[frame: frame+ b, j]))
out_cond.append(torch.bmm(sim_cond.softmax(dim=-1), v_cond[frame: frame+ b, j]))
# cat each head's out, (b->n_frames, 1, seq_len, dim//head) -> (n_frames, 1, seq_len, dim//head)
out_source = torch.cat(out_source, dim=0)
out_uncond = torch.cat(out_uncond, dim=0)
out_cond = torch.cat(out_cond, dim=0)
if single_batch: # if use single_batch, view single_batch frame's out
out_source = out_source.view(h, n_frames,sequence_length, dim // h).permute(1, 0, 2, 3).reshape(h * n_frames, sequence_length, -1)
out_uncond = out_uncond.view(h, n_frames,sequence_length, dim // h).permute(1, 0, 2, 3).reshape(h * n_frames, sequence_length, -1)
out_cond = out_cond.view(h, n_frames,sequence_length, dim // h).permute(1, 0, 2, 3).reshape(h * n_frames, sequence_length, -1)
# append each frame's out
out_source_all.append(out_source)
out_uncond_all.append(out_uncond)
out_cond_all.append(out_cond)
# cat each frame's out, (n_frames, 1, seq_len, dim//head) -> (n_frames, heads, seq_len, dim//heads)
out_source = torch.cat(out_source_all, dim=0)
out_uncond = torch.cat(out_uncond_all, dim=0)
out_cond = torch.cat(out_cond_all, dim=0)
# cat source, cond and uncond's out, (n_frames, heads, seq_len, dim//heads) -> (3*n_frames, heads, seq_len, dim//heads)
out = torch.cat([out_source, out_uncond, out_cond], dim=0)
out = self.reshape_batch_dim_to_heads(out)
return to_out(out)
return forward
3. sa_3frame_forward
因为使用了PnP:每次进行self attention不再是像sa_forward一样,对输入repeat重复n_frames,而是 source_latent 进行正常的KV来自单帧的self attention forward_original,uncond_latent 和 cond_latent 进行 KV 来自相邻3帧 的self attention forward_extended。
每次计算第 i 帧的attention时(window_size=3),以第 i 帧为中心 ,取下标=[i-1, i, i+1]的3帧作为KV:
def sa_3frame_forward(self): # self attention只是扩展到连续的 3 个关键帧,而不是所有关键帧。
to_out = self.to_out
if type(to_out) is torch.nn.modules.container.ModuleList:
to_out = self.to_out[0]
else:
to_out = self.to_out
# 原始的UNet attention forward
def forward_original(q, k, v):
n_frames, seq_len, dim = q.shape
h = self.heads
head_dim = dim // h
q = self.head_to_batch_dim(q).reshape(n_frames, h, seq_len, head_dim)
k = self.head_to_batch_dim(k).reshape(n_frames, h, seq_len, head_dim)
v = self.head_to_batch_dim(v).reshape(n_frames, h, seq_len, head_dim)
out_all = []
for frame in range(n_frames):
out = []
for j in range(h):
sim = torch.matmul(q[frame, j], k[frame, j].transpose(-1, -2)) * self.scale # (seq_len, seq_len)
out.append(torch.matmul(sim.softmax(dim=-1), v[frame, j])) # h * (seq_len, head_dim)
out = torch.cat(out, dim=0).reshape(-1, seq_len, head_dim) # (h, seq_len, head_dim)
out_all.append(out) # n_frames * (h, seq_len, head_dim)
out = torch.cat(out_all, dim=0) # (n_frames * h, seq_len, head_dim)
out = self.batch_to_head_dim(out) # (n_frames, seq_len, h * head_dim)
return out
# extend UNet attention forward(all frames)
def forward_extended(q, k, v):
n_frames, seq_len, dim = q.shape
h = self.heads
head_dim = dim // h
q = self.head_to_batch_dim(q).reshape(n_frames, h, seq_len, head_dim)
k = self.head_to_batch_dim(k).reshape(n_frames, h, seq_len, head_dim)
v = self.head_to_batch_dim(v).reshape(n_frames, h, seq_len, head_dim)
out_all = []
window_size = 3
for frame in range(n_frames): # frame=32, window_size=3: window=[14, 15, 16, 17, 18]
out = []
# sliding window to improve speed. 以当前帧frame为中心,取window_size大小的帧,如frame_idx=1时, window: [0, 1, 2]
window = range(max(0, frame-window_size // 2), min(n_frames, frame+window_size//2+1))
for j in range(h):
sim_all = [] # 存当前帧frame和window内3帧的sim,len(sim_all)=3
for kframe in window: # (1, 1, seq_len, head_dim) @ (1, 1, head_dim, seq_len) -> (1, 1, seq_len, seq_len)
# 当前帧frame 依次和window内的帧kframe,计算sim存入sim_all
sim_all.append(torch.matmul(q[frame, j], k[kframe, j].transpose(-1, -2)) * self.scale) # window * (seq_len, seq_len)
sim_all = torch.cat(sim_all).reshape(len(window), seq_len, seq_len).transpose(0, 1) # (seq_len, window, seq_len)
sim_all = sim_all.reshape(seq_len, len(window) * seq_len) # (seq_len, window * seq_len)
out.append(torch.matmul(sim_all.softmax(dim=-1), v[window, j].reshape(len(window) * seq_len, head_dim))) # h * (seq_len, head_dim)
out = torch.cat(out, dim=0).reshape(-1, seq_len, head_dim) # (h, seq_len, head_dim)
out_all.append(out) # n_frames * (h, seq_len, head_dim)
out = torch.cat(out_all, dim=0) # (n_frames * h, seq_len, head_dim)
out = self.batch_to_head_dim(out) # (n_frames, seq_len, h * head_dim)
return out
def forward(x, encoder_hidden_states=None, attention_mask=None):
batch_size, sequence_length, dim = x.shape
h = self.heads
n_frames = batch_size // 3
is_cross = encoder_hidden_states is not None
encoder_hidden_states = encoder_hidden_states if is_cross else x
q = self.to_q(x)
k = self.to_k(encoder_hidden_states)
v = self.to_v(encoder_hidden_states)
if self.injection_schedule is not None and (self.t in self.injection_schedule or self.t == 1000):
# inject unconditional
q[n_frames:2 * n_frames] = q[:n_frames]
k[n_frames:2 * n_frames] = k[:n_frames]
# inject conditional
q[2 * n_frames:] = q[:n_frames]
k[2 * n_frames:] = k[:n_frames]
# source_latent 正常的self attention, uncond 和 cond进行 KV来自相邻3帧的self attention
out_source = forward_original(q[:n_frames], k[:n_frames], v[:n_frames])
out_uncond = forward_extended(q[n_frames:2 * n_frames], k[n_frames:2 * n_frames], v[n_frames:2 * n_frames])
out_cond = forward_extended(q[2 * n_frames:], k[2 * n_frames:], v[2 * n_frames:])
out = torch.cat([out_source, out_uncond, out_cond], dim=0) # (3 * n_frames, seq_len, dim)
return to_out(out)
return forward
register_conv_injection
为UNet注册完SelfAttention的forward后,再来为其UNet的unet.up_blocks[1].resnets[1]的ResnetBlock2D注册新的forward,同时注册injection_schedule控制PnP注入时间步。
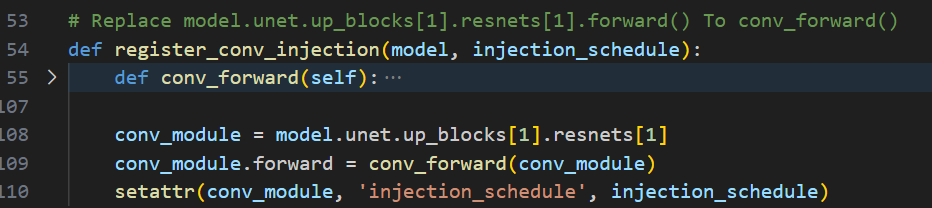
在conv_forward中只比普通的ResnetBlock2D的forward多了一步PnP Inject的操作:
if self.injection_schedule is not None and (self.t in self.injection_schedule or self.t == 1000):
source_batch_size = int(hidden_states.shape[0] // 3)
# inject unconditional
hidden_states[source_batch_size:2 * source_batch_size] = hidden_states[:source_batch_size]
# inject conditional
hidden_states[2 * source_batch_size:] = hidden_states[:source_batch_size]
set_tokenflow
__class__就是返回自己的父类,set_tokenflow就是找到UNet中所有父类是BasicTransformerBlock的模块,对他们把BasicTransformerBlock作为父类,外面再套一层TokenFlowBlock类。
def set_tokenflow(model: torch.nn.Module):
"""
Sets the tokenflow attention blocks in a model.
"""
for _, module in model.named_modules():
if isinstance_str(module, "BasicTransformerBlock"):
# 16个 module.__class__ = <class 'diffusers.models.attention.BasicTransformerBlock'>
make_tokenflow_block_fn = make_tokenflow_attention_block
# 将BasicTransformerBlock作为父类,外面再套一层TokenFlowBlock类
module.__class__ = make_tokenflow_block_fn(module.__class__)
# Something needed for older versions of diffusers
if not hasattr(module, "use_ada_layer_norm_zero"):
module.use_ada_layer_norm = False
module.use_ada_layer_norm_zero = False
return model
make_tokenflow_attention_block
这个函数就是定义了一个TokenFlowBlock类,然后返回TokenFlowBlock类。TokenFlowBlock就继承自BasicTransformerBlock类,只重写了forward函数。
首先pivotal_pass判断是否是关键帧:
- 关键帧,就存下
pivot_hidden_states - 非关键帧,取非关键帧与关键帧的
source_latent,计算其与关键帧的余弦相似度cosine_sim,shape=(n_frames * seq_len, len(batch_idxs) * seq_len),求得相似度最大的帧下标idx,然后为source、uncond、cond 堆叠3份。- 如果当前batch不是第一个batch,
len(batch_idxs) =2, 分别保存最相似的帧下标到idx1和idx2 - 如果是第一个batch,
len(batch_idxs) =1,保存最相似的帧下标到idx1
- 如果当前batch不是第一个batch,
batch_size, sequence_length, dim = hidden_states.shape # (batch, seq_len, dim)
n_frames = batch_size // 3 # batch = 3 * n_frames: source + uncond + cond
mid_idx = n_frames // 2
hidden_states = hidden_states.view(3, n_frames, sequence_length, dim) # (source + uncond + cond, n_frames, seq_len, dim)
norm_hidden_states = self.norm1(hidden_states).view(3, n_frames, sequence_length, dim)
if self.pivotal_pass: # is_pivotal = True # 关键帧,存下
self.pivot_hidden_states = norm_hidden_states # (3, n_frames, sequence_length, dim) ,关键帧的n_frames=5
else: # is_pivotal = False # 非关键帧,与关键帧计算source_latent的cosine_sim
idx1 = []
idx2 = []
batch_idxs = [self.batch_idx] # 每batch_size帧进行一批处理,batch_idx是第几个batch,如32帧,batch_size=8,batch_idx可以为0或1或2或3或4
if self.batch_idx > 0: # 如果不是第一个batch
batch_idxs.append(self.batch_idx - 1) # 加入前一个batch的idx,如当前batch_idx=1时,再加入0,则batch_idxs=[1,0]
# 取source_latent的非关键帧与关键帧计算cosine_sim,如果batch_idxs=[1,0],则只拿第0个batch和第1个batch的关键帧和其norm_hidden_states计算sim
sim = batch_cosine_sim(norm_hidden_states[0].reshape(-1, dim), # (n_frames*sequence_length, dim)
self.pivot_hidden_states[0][batch_idxs].reshape(-1, dim)) # (len(batch_idxs)*sequence_length, dim)
if len(batch_idxs) == 2: # 如果不是第一个batch, 分别保存最相似的帧下标到idx1和idx2
# sim: (n_frames * seq_len, len(batch_idxs) * seq_len), len(batch_idxs)=2
sim1, sim2 = sim.chunk(2, dim=1)
idx1.append(sim1.argmax(dim=-1)) # (n_frames * seq_len) 个数,每个数在[0,76]之间
idx2.append(sim2.argmax(dim=-1)) # (n_frames * seq_len) 个数,每个数在[0,76]之间
else: # 如果是第一个batch,保存最相似的帧下标到idx1
idx1.append(sim.argmax(dim=-1))
# 为source、uncond、cond 堆叠3份
idx1 = torch.stack(idx1 * 3, dim=0) # (3, n_frames * seq_len)
idx1 = idx1.squeeze(1)
if len(batch_idxs) == 2:
idx2 = torch.stack(idx2 * 3, dim=0) # (3, n_frames * seq_len)
idx2 = idx2.squeeze(1)
接下来依次进行Self-Attention attn1、Cross-Attention attn2、和Feed-forward ff,其中Cross-Attention和Feed-forward没有任何改变,唯一改变的就是Self-Attention过程 :
- 对于关键帧,计算 self-attention 结果,并将其保存下来。
- 对于非关键帧,将其与关键帧的 attention 结果进行融合。融合方式为加权平均,权重由帧与关键帧之间的距离决定。如果非关键帧是第一个 batch 中的帧,则直接使用关键帧的 attention 结果。如果非关键帧是第二个 batch 中的帧,则计算与第一个 batch 中的关键帧和第二个 batch 中的关键帧的 attention 结果,然后进行加权平均。权重由帧与两个关键帧之间的距离决定。具体公式如下:
w e i g h t = ∣ s ? p 1 ∣ / ( ∣ s ? p 1 ∣ + ∣ s ? p 2 ∣ ) weight = |s - p1| / (|s - p1| + |s - p2|) weight=∣s?p1∣/(∣s?p1∣+∣s?p2∣)
其中,s 表示帧的编号,p1 表示第一个关键帧的编号,p2 表示第二个关键帧的编号。
# 1. Self-Attention
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if self.pivotal_pass:
# norm_hidden_states.shape = 3, n_frames * seq_len, dim
self.attn_output = self.attn1(
norm_hidden_states.view(batch_size, sequence_length, dim),
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
**cross_attention_kwargs,
)
# 3, n_frames * seq_len, dim - > 3 * n_frames, seq_len, dim
self.kf_attn_output = self.attn_output
else:
batch_kf_size, _, _ = self.kf_attn_output.shape
self.attn_output = self.kf_attn_output.view(3, batch_kf_size // 3, sequence_length, dim)[:,
batch_idxs] # 3, n_frames, seq_len, dim --> 3, len(batch_idxs), seq_len, dim
# gather values from attn_output, using idx as indices, and get a tensor of shape 3, n_frames, seq_len, dim
if not self.pivotal_pass:
if len(batch_idxs) == 2:
attn_1, attn_2 = self.attn_output[:, 0], self.attn_output[:, 1]
attn_output1 = attn_1.gather(dim=1, index=idx1.unsqueeze(-1).repeat(1, 1, dim))
attn_output2 = attn_2.gather(dim=1, index=idx2.unsqueeze(-1).repeat(1, 1, dim))
s = torch.arange(0, n_frames).to(idx1.device) + batch_idxs[0] * n_frames
# distance from the pivot
p1 = batch_idxs[0] * n_frames + n_frames // 2
p2 = batch_idxs[1] * n_frames + n_frames // 2
d1 = torch.abs(s - p1)
d2 = torch.abs(s - p2)
# weight
w1 = d2 / (d1 + d2)
w1 = torch.sigmoid(w1)
w1 = w1.unsqueeze(0).unsqueeze(-1).unsqueeze(-1).repeat(3, 1, sequence_length, dim)
attn_output1 = attn_output1.view(3, n_frames, sequence_length, dim)
attn_output2 = attn_output2.view(3, n_frames, sequence_length, dim)
attn_output = w1 * attn_output1 + (1 - w1) * attn_output2
else:
attn_output = self.attn_output[:,0].gather(dim=1, index=idx1.unsqueeze(-1).repeat(1, 1, dim))
attn_output = attn_output.reshape(
batch_size, sequence_length, dim) # 3 * n_frames, seq_len, dim
else:
attn_output = self.attn_output
hidden_states = hidden_states.reshape(batch_size, sequence_length, dim) # 3 * n_frames, seq_len, dim
hidden_states = attn_output + hidden_states # res_connect
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java学习,一文掌握Java之SpringBoot框架学习文集(8)
- linux文档的控制访问总结
- TCP/IP的网络层(即IP层)之IP地址和网络掩码,在视频监控系统中的配置和应用
- 部署promethues采集kubelet数据报错:server returned HTTP status 403 Forbidden
- docker-compose安装及常用指令学习和harbor安装使用
- PaddleOCR实现对表格的提取
- golang学习笔记——面试题 使用 3 个协程顺序打印 cat、dog、fish 各 100 次
- Java实现校园电商物流云平台 JAVA+Vue+SpringBoot+MySQL
- CAN 三: STM32 CAN相关寄存器介绍
- 深度剖析跨境商城源码架构,助你把握行业动向