Kubernetes 的用法和解析 -- 5
一.企业级镜像仓库Harbo
准备:另起一台新服务器,并配置docker yum源,安装docker 和 docker-compose
1.1 上传harbor安装包并安装
[root@harbor ~]# tar xf harbor-offline-installer-v2.5.3.tgz
[root@harbor ~]# cp harbor.yml.tmpl harbor.yml
[root@harbor ~]# vim harbor.yml
hostname: 192.168.58.146
# http related config
http:
# port for http, default is 80. If https enabled, this port will redirect to https port
port: 80
# 注释所有https的内容
[root@harbor ~]# sh install.sh1.2 浏览器访问
默认账号:admin? ? ?默认密码:Harbor12345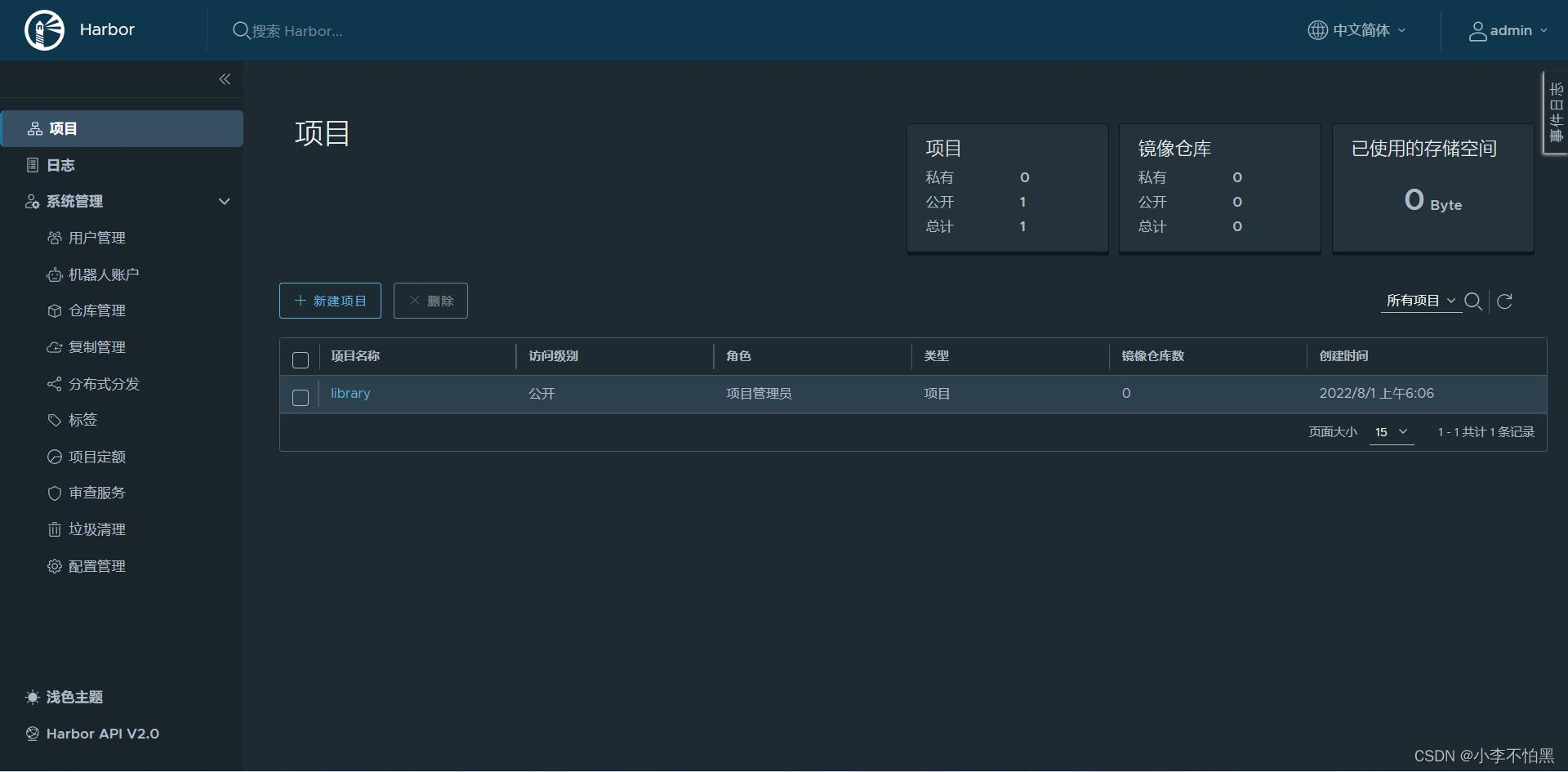
1.3 k8s使用harbor仓库
# 两台node节点执行
[root@kube-node1 ~]# vim /etc/docker/daemon.json #不存在则创建
{ "insecure-registries": ["192.168.58.146"] }
# 重启docker:
[root@kube-node1 ~]# systemctl restart docker1.4 上传镜像到仓库
[root@kube-node1 ~]# docker login http://192.168.246.168
username:admin
password:
[root@kube-node1 ~]# docker pull daocloud.io/library/nginx
[root@kube-node1 ~]# docker tag daocloud.io/library/nginx 192.168.58.146/library/nginx:v1.01.5 创建secret.yaml文件
[root@kube-node1 ~]# cat ~/.docker/config.json |base64 -w 0
ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjU4LjE0NiI6IHsKCQkJImF1dGgiOiAiWVdSdGFXNDZTR0Z5WW05eU1USXoiCgkJfQoJfQp9
#创建 secret.yaml 文件
[root@kube-master ~]# vim secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: login
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjU4LjE0NiI6IHsKCQkJImF1dGgiOiAiWVdSdGFXNDZTR0Z5WW05eU1USXo
[root@kube-master ~]# kubectl apply -f secret.yaml1.6 k8s-pod 使用镜像
[root@kube-master ~]# vim harbor-pod.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: show
spec:
replicas: 2
selector:
matchLabels:
app: show
template:
metadata:
labels:
app: show
spec:
containers:
- name: show
image: 192.168.58.146/library/nginx:v1.0
ports:
- containerPort: 80
imagePullSecrets:
- name: login
---
apiVersion: v1
kind: Service
metadata:
name: show-service
spec:
type: NodePort
selector:
app: show
ports:
- port: 80
targetPort: 80
nodePort: 32000 #范围:30000 - 32765浏览器访问:192.168.58.146:32000
二.水平扩展/收缩与滚动更新
2.1 水平扩展/收缩
2.1.1 创建一个deployment
[root@kube-master ~]# vim deployment.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: dep01
labels:
name: dep01
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
ports:
- containerPort: 80
[root@kube-master ~]# kubectl apply -f deployment.yaml2.1.2 通过声明方式扩展
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 2/2 2 2 4h41m
我们将dep01的副本数量变成4个,现在2个
[root@kub-k8s-master prome]# vim deployment.yaml #修改如下内容
将replicas: 2
修改为:
replicas: 4[root@kub-k8s-master prome]# kubectl apply -f deployment.yaml --record
deployment.apps/dep01 configured
--record ?kubectl apply 每次更新应用时 Kubernetes 都会记录下当前的配置,保存为一个 revision(版次),这样就可以回滚到某个特定 revision。检查nginx-deployment 创建后的状态信息:
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 4/4 4 4 4h53m返回结果中四个状态字段含义:
DESIRED:?
如果有就表示用户期望的 Pod 副本个数(spec.replicas 的值);CURRENT:
当前处于 Running 状态的 Pod 的个数;UP-TO-DATE:
当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;AVAILABLE:
当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。只有这个字段,描述的才是用户所期望的最终状态。
2.1.3 通过edit方式收缩
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 4/4 4 4 4h59m
将dep01的副本将4变为3个
[root@kub-k8s-master prome]# kubectl edit deployment/dep01
# reopened with the relevant failures.
#
apiVersion: apps/v1
...
spec:
progressDeadlineSeconds: 600
replicas: 3 #将这里原来的4改为3
revisionHistoryLimit: 10
selector:
matchLabels:
...
保存退出,vim的方式
[root@kub-k8s-master prome]# kubectl edit deployment/dep01
deployment.apps/dep01 edited2.2 滚动更新
概念:
将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是"滚动更新"。
2.2.1 进行版本的升级
创建一个新的deploy
[root@kub-k8s-master prome]# cp nginx-depl.yml nginx-depl02.yml
[root@kub-k8s-master prome]# vim nginx-depl02.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dep02 #注意修改
spec:
selector:
matchLabels:
app: web1
replicas: 2
template:
metadata:
name: testnginx9
labels:
app: web1
spec:
containers:
- name: testnginx9
image: daocloud.io/library/nginx:1.14 #注意修改
ports:
- containerPort: 80
[root@kub-k8s-master prome]# kubectl apply -f nginx-depl02.yml
deployment.apps/dep02 created
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep01-58f6d4d4cb-997jw 1/1 Running 0 16m
dep01-58f6d4d4cb-g6vtg 1/1 Running 0 5h32m
dep01-58f6d4d4cb-k6z47 1/1 Running 0 5h32m
dep02-78dbd944fc-47czr 1/1 Running 0 44s
dep02-78dbd944fc-4snsj 1/1 Running 0 25s
将nginx的版本从1.14升级到1.16
[root@kub-k8s-master prome]# kubectl edit deployment/dep02
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
...
spec:
containers:
- image: daocloud.io/library/nginx:1.16 #将这里原来的nginx:1.14修改为nginx:1.16
imagePullPolicy: Always
name: testnginx9
ports:
- containerPort: 80
...
保存退出,vim的方式
[root@kub-k8s-master prome]# kubectl edit deployment/dep02
deployment.apps/dep01 edited这时可以通过查看 Deployment 的 Events,看到这个"滚动更新"的流程
[root@kub-k8s-master prome]# kubectl describe deployment dep02
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 50s deployment-controller Scaled up replica set dep02-846bf8775b to 2
Normal ScalingReplicaSet 9s deployment-controller Scaled up replica set dep02-58f8d5678 to 1
Normal ScalingReplicaSet 8s deployment-controller Scaled down replica set dep02-846bf8775b to 1
Normal ScalingReplicaSet 8s deployment-controller Scaled up replica set dep02-58f8d5678 to 2
Normal ScalingReplicaSet 5s deployment-controller Scaled down replica set dep02-846bf8775b to 0如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。
2.2.2 验证
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep02-78dbd944fc-69t8x 1/1 Running 0 11h
dep02-78dbd944fc-7cn86 1/1 Running 0 11h
[root@kub-k8s-master prome]# kubectl exec -it dep02-78dbd944fc-69t8x /bin/bash
root@dep02-78dbd944fc-69t8x:/# nginx -v
nginx version: nginx/1.16.1
root@dep02-78dbd944fc-69t8x:/# exit2.2.3 滚动更新的好处
在升级刚开始的时候,集群里只有 1 个新版本的 Pod。如果这时,新版本 Pod 有问题启动不起来,那么"滚动更新"就会停止,从而允许开发和运维人员介入。而在这个过程中,由于应用本身还有两个旧版本的 Pod 在线,所以服务并不会受到太大的影响。
2.3 版本回滚
2.3.1 查看版本历史
[root@kub-k8s-master prome]# kubectl rollout history deployment/dep02
deployment.apps/dep02
REVISION CHANGE-CAUSE
1 <none>
2 <none>2.3.2 回滚到以前的旧版本:
? ?把整个 Deployment 回滚到上一个版本:
[root@kub-k8s-master prome]# kubectl rollout undo deployment/dep02
deployment.apps/dep02 rolled back查看回滚状态
[root@kub-k8s-master prome]# kubectl rollout status deployment/dep02
deployment "dep02" successfully rolled out验证:
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep02-8594cd6447-pqtxk 1/1 Running 0 55s
dep02-8594cd6447-tt4h4 1/1 Running 0 51s
[root@kub-k8s-master prome]# kubectl exec -it dep02-8594cd6447-tt4h4 /bin/bash
root@dep02-8594cd6447-tt4h4:/# nginx -v
nginx version: nginx/1.14.22.3.3 回滚到更早之前的版本
-
使用 kubectl rollout history 命令查看每次 Deployment 变更对应的版本。
[root@kub-k8s-master prome]# kubectl rollout history deployment/dep02
deployment.apps/dep02
REVISION CHANGE-CAUSE
2 <none>
3 <none>
#默认配置下,Kubernetes 只会保留最近的几个 revision,可以在 Deployment 配置文件中通过 revisionHistoryLimit: 属性增加 revision 数量。由于在创建这个 Deployment 的时候,指定了--record 参数,会将创建这些版本时执行的 kubectl 时文件中的配置,都会记录下来。
? ?查看每个版本对应的 Deployment 的 API 对象的细节:
[root@kub-k8s-master prome]# kubectl rollout history deployment/dep02 --revision=3
deployment.apps/dep02 with revision #3
Pod Template:
Labels: app=web1
pod-template-hash=8594cd6447
Containers:
testnginx9:
Image: daocloud.io/library/nginx:1.14
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>2.在 kubectl rollout undo 命令行最后,加上要回滚到的指定版本的版本号,就可以回滚到指定版本了。
[root@kub-k8s-master prome]# kubectl rollout undo deployment/dep02 --to-revision=2
deployment.apps/dep02 rolled back
#验证:
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep02-78dbd944fc-8nvxl 1/1 Running 0 86s
dep02-78dbd944fc-sb9sj 1/1 Running 0 88s
[root@kub-k8s-master prome]# kubectl exec -it dep02-78dbd944fc-8nvxl /bin/bash
root@dep02-78dbd944fc-8nvxl:/# nginx -v
nginx version: nginx/1.16.1三.DeamonSet详解
3.1 何为DaemonSet
介绍DaemonSet我们先来思考一个问题:相信大家都接触过监控系统比如zabbix,监控系统需要在被监控机安装一个agent,安装agent通常会涉及到以下几个场景:
- 所有节点都必须安装agent以便采集监控数据
- 新加入的节点需要配置agent,手动或者运行脚本
k8s中经常涉及到在node上安装部署应用,它是如何解决上述的问题的呢?答案是DaemonSet。DaemonSet守护进程简称DS,适用于在所有节点或部分节点运行一个daemon守护进程。
DaemonSet 的主要作用,是让你在 k8s 集群里,运行一个 Daemon Pod。
这个 Pod 有如下三个特征:
这个 Pod 运行在 k8s 集群里的每一个节点(Node)上;
每个节点上只有一个这样的 Pod 实例;
当有新的节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的 Pod 也相应地会被回收掉。
举例:
????????各种网络插件的 Agent 组件,都必须运行在每一个节点上,用来处理这个节点上的容器网络;
????????各种存储插件的 Agent 组件,也必须运行在每一个节点上,用来在这个节点上挂载远程存储目录,操作容器的 Volume 目录;
????????各种监控组件和日志组件,也必须运行在每一个节点上,负责这个节点上的监控信息和日志搜集。
3.2 DaemonSet 的 API 对象的定义
所有node节点分别下载镜像
# docker pull daocloud.io/daocloud/fluentd-elasticsearch:1.20
# docker pull daocloud.io/daocloud/fluentd-elasticsearch:v2.2.0fluentd-elasticsearch 镜像功能:
通过 fluentd 将每个node节点上面的Docker 容器里的日志转发到 ElasticSearch 中。
编写daemonset配置文件
Yaml文件内容如下
[root@k8s-master ~]# mkdir set
[root@k8s-master ~]# cd set/
[root@k8s-master set]# vim fluentd-elasticsearch.yaml # DaemonSet 没有 replicas 字段
apiVersion: apps/v1
kind: DaemonSet #创建资源的类型
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations: #容忍污点
- key: node-role.kubernetes.io/master #污点
effect: NoSchedule #描述污点的效应
containers:
- name: fluentd-elasticsearch
image: daocloud.io/daocloud/fluentd-elasticsearch:1.20
resources: #限制使用资源
limits: #定义使用内存的资源上限
memory: 200Mi
requests: #实际使用
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: varlog
hostPath: #定义卷使用宿主机目录
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containersDaemonSet 没有 replicas 字段
selector :
选择管理所有携带了 name=fluentd-elasticsearch 标签的 Pod。
Pod 的模板用 template 字段定义:
定义了一个使用 fluentd-elasticsearch:1.20 镜像的容器,而且这个容器挂载了两个 hostPath 类型的 Volume,分别对应宿主机的 /var/log 目录和 /var/lib/docker/containers 目录。
fluentd 启动之后,它会从这两个目录里搜集日志信息,并转发给 ElasticSearch 保存。这样,通过 ElasticSearch 就可以很方便地检索这些日志了。Docker 容器里应用的日志,默认会保存在宿主机的 /var/lib/docker/containers/{{. 容器 ID}}/{{. 容器 ID}}-json.log 文件里,这个目录正是 fluentd 的搜集目标。
DaemonSet 如何保证每个 Node 上有且只有一个被管理的 Pod ?
DaemonSet Controller,首先从 Etcd 里获取所有的 Node 列表,然后遍历所有的 Node。这时,它就可以很容易地去检查,当前这个 Node 上是不是有一个携带了 name=fluentd-elasticsearch 标签的 Pod 在运行。
检查结果有三种情况:
1. 没有这种 Pod,那么就意味着要在这个 Node 上创建这样一个 Pod;指定的 Node 上创建新 Pod 用 nodeSelector,选择 Node 的名字即可。
2. 有这种 Pod,但是数量大于 1,那就说明要把多余的 Pod 从这个 Node 上删除掉;删除节点(Node)上多余的 Pod 非常简单,直接调用 Kubernetes API 就可以了。
3. 正好只有一个这种 Pod,那说明这个节点是正常的。
tolerations:
DaemonSet 还会给这个 Pod 自动加上另外一个与调度相关的字段,叫作 tolerations。这个字段意思是这个 Pod,会"容忍"(Toleration)某些 Node 的"污点"(Taint)。
tolerations 字段,格式如下:
apiVersion: v1
kind: Pod
metadata:
name: with-toleration
spec:
tolerations:
- key: node.kubernetes.io/unschedulable #污点的key
operator: Exists #将会忽略value;只要有key和effect就行
effect: NoSchedule #污点的作用含义是:"容忍"所有被标记为 unschedulable"污点"的 Node;"容忍"的效果是允许调度。可以简单地把"污点"理解为一种特殊的 Label。
正常情况下,被标记了 unschedulable"污点"的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)。可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,保证每个节点上都会被调度一个 Pod。如果这个节点有故障的话,这个 Pod 可能会启动失败,DaemonSet 会始终尝试下去,直到 Pod 启动成功。
DaemonSet 的"过人之处",其实就是依靠 Toleration 实现的
DaemonSet 是一个控制器。在它的控制循环中,只需要遍历所有节点,然后根据节点上是否有被管理 Pod 的情况,来决定是否要创建或者删除一个 Pod。
更多种类的Toleration
可以在 Pod 模板里加上更多种类的 Toleration,从而利用 DaemonSet 实现自己的目的。
比如,在这个 fluentd-elasticsearch DaemonSet 里,给它加上了这样的 Toleration:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule这是因为在默认情况下,Kubernetes 集群不允许用户在 Master 节点部署 Pod。因为,Master 节点默认携带了一个叫作node-role.kubernetes.io/master的"污点"。所以,为了能在 Master 节点上部署 DaemonSet 的 Pod,就必须让这个 Pod"容忍"这个"污点"。
3.3 DaemonSet实践
3.3.1 创建 DaemonSet 对象
[root@k8s-master set] # kubectl create -f fluentd-elasticsearch.yamlDaemonSet 上一般都加上 resources 字段,来限制它的 CPU 和内存使用,防止它占用过多的宿主机资源。
创建成功后,如果有 3 个节点,就会有 3 个 fluentd-elasticsearch Pod 在运行
[root@k8s-master set]# kubectl get pod -n kube-system -l name=fluentd-elasticsearch
NAME READY STATUS RESTARTS AGE
fluentd-elasticsearch-6lmnb 1/1 Running 0 21m
fluentd-elasticsearch-9fd7k 1/1 Running 0 21m
fluentd-elasticsearch-vz4n4 1/1 Running 0 21m3.3.2 查看 DaemonSet 对象
[root@k8s-master set]# kubectl get ds -n kube-system fluentd-elasticsearch
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-elasticsearch 3 3 3 3 3 <none> 22m注:k8s 里比较长的 API 对象都有短名字,比如 DaemonSet 对应的是 ds,Deployment 对应的是 deploy。
3.3.3 DaemonSet 版本管理
[root@k8s-master set]# kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonset.apps/fluentd-elasticsearch
REVISION CHANGE-CAUSE
1 <none>3.3.4 DaemonSet 的容器镜像版本到 v2.2.0
[root@k8s-master set]# kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=daocloud.io/daocloud/fluentd-elasticsearch:v2.2.0 --record -n=kube-system
daemonset.apps/fluentd-elasticsearch image updated这个 kubectl set image 命令里,第一个 fluentd-elasticsearch 是 DaemonSet 的名字,第二个 fluentd-elasticsearch 是容器的名字。
--record 参数:
升级使用到的指令会自动出现在 DaemonSet 的 rollout history 里面,如下所示:
[root@k8s-master set]# kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonset.apps/fluentd-elasticsearch
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=daocloud.io/daocloud/fluentd-elasticsearch:v2.2.0 --record=true --namespace=kube-system有了版本号,也就可以像 Deployment 一样,将 DaemonSet 回滚到某个指定的历史版本了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Flink-Kafka-To-Hive】使用 Flink 实现 Kafka 数据写入 Hive
- Python基础入门第九课笔记(文件和文件夹)
- 【ARM Cortex-M 系列 5 -- RT-Thread renesas/ra4m2-eco 移植编译篇】
- k8s安装配置dashboard
- c语言链表的基本操作
- 【自动化测试入门】用Airtest - Selenium对Firefox进行自动化测试(0基础也能学会)
- 元旦烟花特效 Python代码实现
- 驱动模块之间通知链
- 解决vue3 动态引入报错问题
- 代码随想录算法训练营第60天|84.柱状图中最大的矩形