Med-YOLO:3D + 医学影像 + 检测框架
?
提出背景
论文链接:https://arxiv.org/abs/2312.07729
代码链接:https://github.com/JDSobek/MedYOLO
提出背景:人工智能已经应用于大量的医学影像的识别,但是还缺少通用的3D医学影像检测框架。
在中大尺寸结构(如心脏、肝脏和胰腺)上的性能非常高。
然而,模型在处理非常小或罕见的结构时存在困难。
这就有点尴尬了,因为医学病灶好多都很小,认真的寻找才能刚好看到。
?
MedYOLO 是基于 Ultralytics YOLOv5 检测模型开发的,对于中等和大型结构的检测具有很高的准确性。
-
YOLO v5:https://blog.csdn.net/qq_41739364/article/details/131836818
-
与YOLOv5相比,MedYOLO的主要区别在于用其3D版本替换了2D神经网络层。
?
设计思路
假设你是一位医生,正在查看一系列的3D医学影像,比如CT扫描图。你的目标是在这些图像中找到并标记出特定的结构,比如肿瘤或器官。这就像是在一堆照片中寻找并圈出一个特定的物体。
-
传统方法 - 分割模型: 这就像是用细笔在每张图像上精确描绘出你要找的物体的边界。这种方法虽然非常精确,但也非常耗时和费力。因为你需要对每个像素都进行标记,而且还需要确保不同的专家对边界的理解是一致的。想象一下,如果你需要在成百上千张图像上都做这样的工作,这将是多么繁重的任务!
-
新方法 - 目标检测模型 (例如MedYOLO): 这就像是用一个大笔画一个框,框出你要找的物体所在的大致区域。这种方法不需要对每个像素都进行精确标记,只需要识别出目标物体大概在哪里。这样做比较快,而且通常对于医学诊断来说足够准确了。特别是对于一些大的结构,比如较大的肿瘤或器官,这种方法非常有效。
Med-YOLO 优点在于能够快速而准确地在3D医学影像中识别和标记出较大的结构,而不需要像传统的分割模型那样耗时耗力。
这对于快速、高效地处理大量医学影像数据来说是一个很大的进步。
?
网络设计
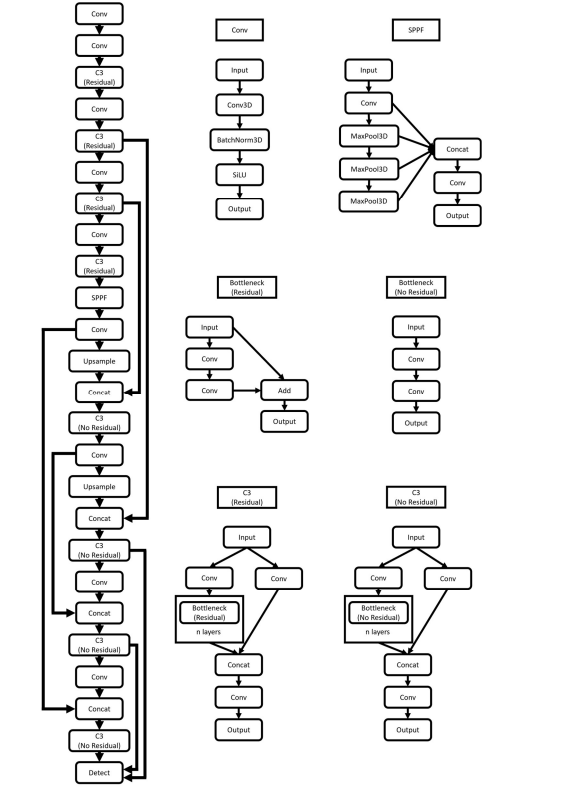
MedYOLO 是 YOLOv5 为 3D 医学图像分析的复杂改编,其在网络架构、数据处理和预处理方面进行了调整,以适应医学扫描的独特特性。
-
3D 医学成像重点:与为 2D 图像设计的 YOLOv5 不同,MedYOLO 专为 3D 医学扫描(如 CT 和 MRI)量身定做。它可以处理 NIfTI 文件,这是医学成像中常见的格式。
-
网络结构更改:MedYOLO 修改了 YOLOv5 的卷积神经网络(CNN),使其适用于 3D 数据。通过将网络中的 2D 层替换为 3D 版本,它能够理解和分析医学图像中的三维结构。
-
可配置的架构:MedYOLO 的神经网络设计可以使用 yaml 文件进行调整,提供小型、中型和大型配置。这种灵活性允许用户在性能和计算需求之间选择合适的平衡。
-
依赖项和数据处理修改:YOLOv5 使用的一些库(如 OpenCV)不支持 3D 数据。为了克服这一点,MedYOLO 对其数据处理管道进行了重大更改,并不得不移除或修改某些图像增强例程。
-
使用 k-均值聚类的锚框:锚框是 CNN 中对象检测的关键部分。MedYOLO 使用其训练数据上的 k-均值聚类来确定这些框的大小和宽高比。它通常使用六个锚框,与 YOLOv5 的三个形成对比。
-
输入数据处理:医学扫描通常是各向异性的(具有不同的尺寸)。MedYOLO 使用三线性插值将这些扫描重塑成立方体形式,保持所有维度上的均匀性。这些立方体的边长是可配置的,但在测试中,每侧 350 体素是常见的选择。
-
GPU 资源管理:不同配置的 MedYOLO 需要不同数量的 GPU 内存。该论文提供了一个表格(表1),显示了不同模型大小和输入比例的 VRAM 消耗。
-
数据管道:为 MedYOLO 准备扫描的过程涉及几个步骤:
- 将扫描转换为 PyTorch 张量。
- 将张量重塑成立方体形式。
- 应用数据增强(如需要)。
- 使用适合医学成像类型的技术对数据进行规范化。
-
定制化:用户可以应用自己的数据预处理和规范化例程,使 MedYOLO 适应于各种医学成像任务和数据集。
?
训练设计
MedYOLO的训练过程紧密遵循YOLOv5的模式,但进行了适应3D医学图像的调整。
-
与YOLOv5相似的训练方法:MedYOLO在训练上几乎完全遵循YOLOv5的方法,使用了几乎相同的超参数(用于指导训练过程的参数),唯一的区别是增加了一些用于数据增强的超参数。
-
数据增强的调整:由于MedYOLO用于处理灰度图像(3D医学图像通常是灰度的),某些YOLOv5的数据增强方法(如颜色值变化和随机视角变换)无法应用。因此,MedYOLO使用了三种特定的数据增强方法:
- 随机剪裁增强
- 随机平移增强
- 随机缩放增强
-
训练周期和提前停止:MedYOLO的小型版本在每个数据集上训练了1000个周期,如果连续200个周期没有进步,训练就会提前停止。这是为了防止过度训练和优化时间。
-
损失函数:MedYOLO使用了针对3D体积调整的YOLOv5复合损失函数。这包括:
- 边界框损失:比较预测边界框和目标边界框的重叠度(IoU)和中心点之间的距离。
- 对象性损失:通过比较它们的IoU和模型的置信度来训练模型评估其预测,使用二元交叉熵计算。
- 分类损失:对预测的类别使用二元交叉熵。
-
比较研究:为了比较,研究者还使用nnDetection框架在相同的数据集上进行了训练,这是另一个用于3D NIfTI图像的通用医学成像对象检测框架。但与MedYOLO单次检测方法不同,nnDetection使用滑动窗口方法检测对象。nnDetection还包括自动预处理、增强和5折交叉验证。
讨论分析
主要特点和性能分析:
-
性能:MedYOLO 在检测中等和大型结构时表现良好,尤其是与使用滑动窗口方法的 nnDetection 框架相比。但它在检测非常小或分散的结构时存在困难。
-
鲁棒性:在不同结构上能够获得高精度(mAP)而无需过度调整超参数,这表明 MedYOLO 对不完美的参数选择有一定的抵抗力。
-
应用:它适用于机器学习流程中的快速和准确定位中到大型结构,以便在传递给下游模型之前找到相关的数据。
-
改进空间:目前的实现还有很大的提升空间。特别是在数据增强方面,增加新的增强例程可能会提高其在某些任务(如 BRaTS 肿瘤检测)上的性能。
- 问题:假设你在训练一个用于识别苹果的机器学习模型。目前,你的模型只在识别红苹果方面表现良好,但在识别绿苹果或不同光线下的苹果时表现不佳。
- 改进:引入数据增强。就像在模型训练中加入各种颜色和光照条件下的苹果图片,帮助模型学习在不同条件下识别苹果。
-
输入数据处理:使用三线性插值将 3D 输入数据转换为立方体形状。考虑使用更复杂的重采样方法,如超分辨率,可能提供额外的细节并增加价值。
- 问题:想象你有一张低分辨率的家庭照片,你想将其放大打印出来。
- 改进:使用超分辨率技术,类似于在照片编辑软件中提高照片的清晰度和细节,而不仅仅是简单地放大照片。
-
输入数据的形状要求:将输入数据转换为立方体体积可能是该流程中最大的弱点。这增加了模型所需的计算资源,并可能导致输入图像的不均匀变形。
- 假设你有一堆长方形的乐高积木,但你需要用这些积木建造一个完美的立方体。
- 改进:重新组合这些积木,使它们形成一个立方体,即使这意味着某些积木可能不得不被切割或留下空隙。
-
批次大小和解析度的平衡:为了平衡批次内存限制和批次统计的准确性,需要使用更小的立方体并降低轴向解析度。使用批量累积渐变可能有助于解决这一问题。
- 问题:你正在烹饪,并需要同时煮不同大小的土豆。
- 改进:切割土豆使它们大小一致,这样它们就可以在同一时间煮熟,而不是一些煮得过熟,另一些还没煮熟。
-
医学成像数据集的挑战:这些数据集通常由具有可变切片数量的图像组成。将这些数据集重塑为固定的立方体大小可能会以不可预测的方式相对彼此扭曲输入图像。
- 问题:想象一本书的每一页厚度都不一样,但你需要将它们装订成一个标准厚度的书。
- 改进:调整每一页的厚度,使整本书的厚度一致,即使这可能改变某些页面的原始厚度。
-
2.5D 方法的潜力:未来的框架可能在不破坏批次大小或引入重塑失真的情况下,使用类似于 YOLO 的方法,在 2.5D 范式中表现更好。尽管 2.5D 方法与 3D 方法相比在维护大型结构的边界框准确性方面需要更多的标注工作,但它们相对于体素精确分割仍减轻了标注工作。
- 问题:你正在制作一幅画,需要在二维纸上表现出三维的景象。
- 改进:使用 2.5D 方法,即在二维空间中利用阴影和透视等技术来创造三维效果,这比构建实际的三维模型更简单,但效果依然生动。
?
魔改代码:加强小目标检测
MedYOLO 的层数和宽度的配置可以通过 YAML 文件进行,其中包含小型、中型和大型版本。
加强小目标、遮挡、不完整、模糊检测,可以试试以下的方案改造:
- 卷积层: 动态蛇形卷积、SPD-Conv、多分支卷积模块 RFB-Conv、感受野注意力卷积 RFA-Conv、DCNv3可变形卷积、PConv、ODConv
- 损失函数:Wasserstein Distance Loss
- 检测头:添加微小物体检测头
- 特征集成:BiFPN、Gold-YOLO、多尺度融合模块EVC、多尺度 MultiSEAM
- 注意力机制:SEAM、跨空间学习的高效多尺度注意力 EMA、动态稀疏注意力 BiFormer、LSKblockAttention、TripletAttention、通道优先卷积注意力 CPCA、MobileViTAttention
- 网络架构:上下文增强和特征细化网络ContextAggregation、RepViT、Dual-ViT(多尺度双视觉Transformer)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- easyUI 获取修改行的下标
- 基于springboot的火锅店管理系统设计与实现
- CSS的三大特性(层叠性、继承性、优先级---------很重要)
- [AI编程]AI辅助编程助手-亚马逊AI 编程助手 Amazon CodeWhisperer
- js获取当前时间并转换横杠 YYYY-MM-dd HH:MM:SS 格式
- Linux网络的命令和配置
- 好用的网站性能监测与服务可用性监测工具盘点
- 导航守卫之详情
- RSA加密、解密算法详解
- 在流媒体应用中推流,拉流,转发,转码都是何含义