redis数据结构(二)—— 对象
文章目录
redis对象
1. 对象的类型和编码
Redis使用对象来表示数据库中的键和值,每次当我们在Redis的数 据库中新创建一个键值对时,我们至少会创建两个对象,一个对象用作 键值对的键(键对象),另一个对象用作键值对的值(值对象)。

1.1类型
对象的type属性记录了对象的类型,这个属性的值可以是表8-1列出 的常量的其中一个。
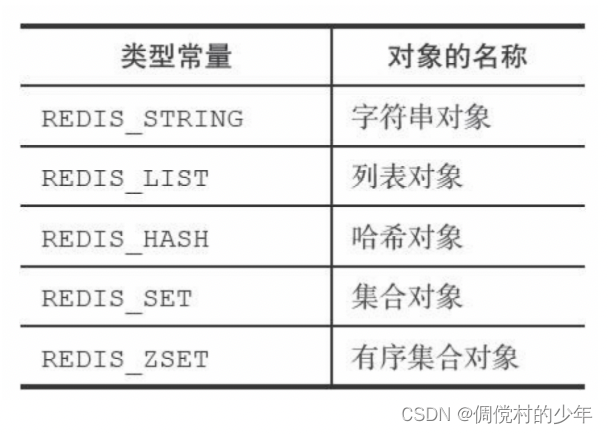
使用type获得值对象类型:type [key]
1.2编码和底层实现(重要)
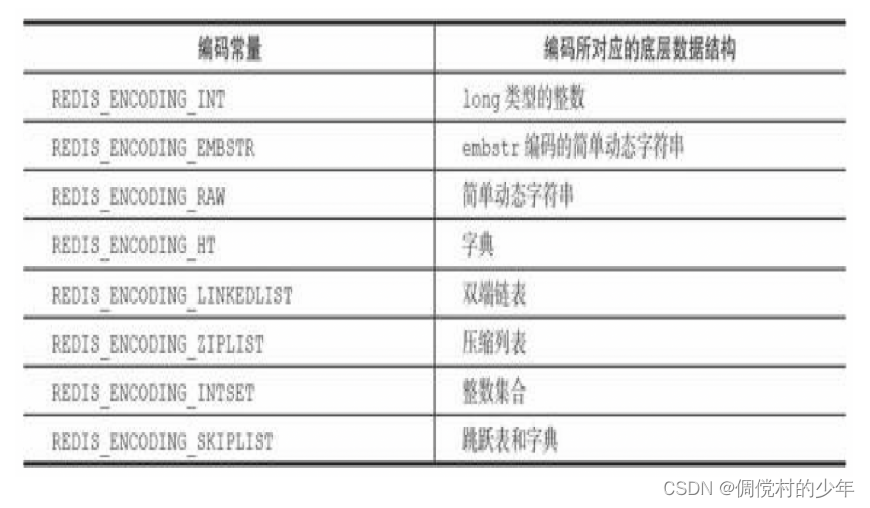
对象的ptr指针指向对象的底层实现数据结构,而这些数据结构由对象的encoding属性决定。
encoding属性记录了对象所使用的编码,也即是说这个对象使用了 什么数据结构作为对象的底层实现,这个属性的值可以是表8-3列出的 常量的其中一个。
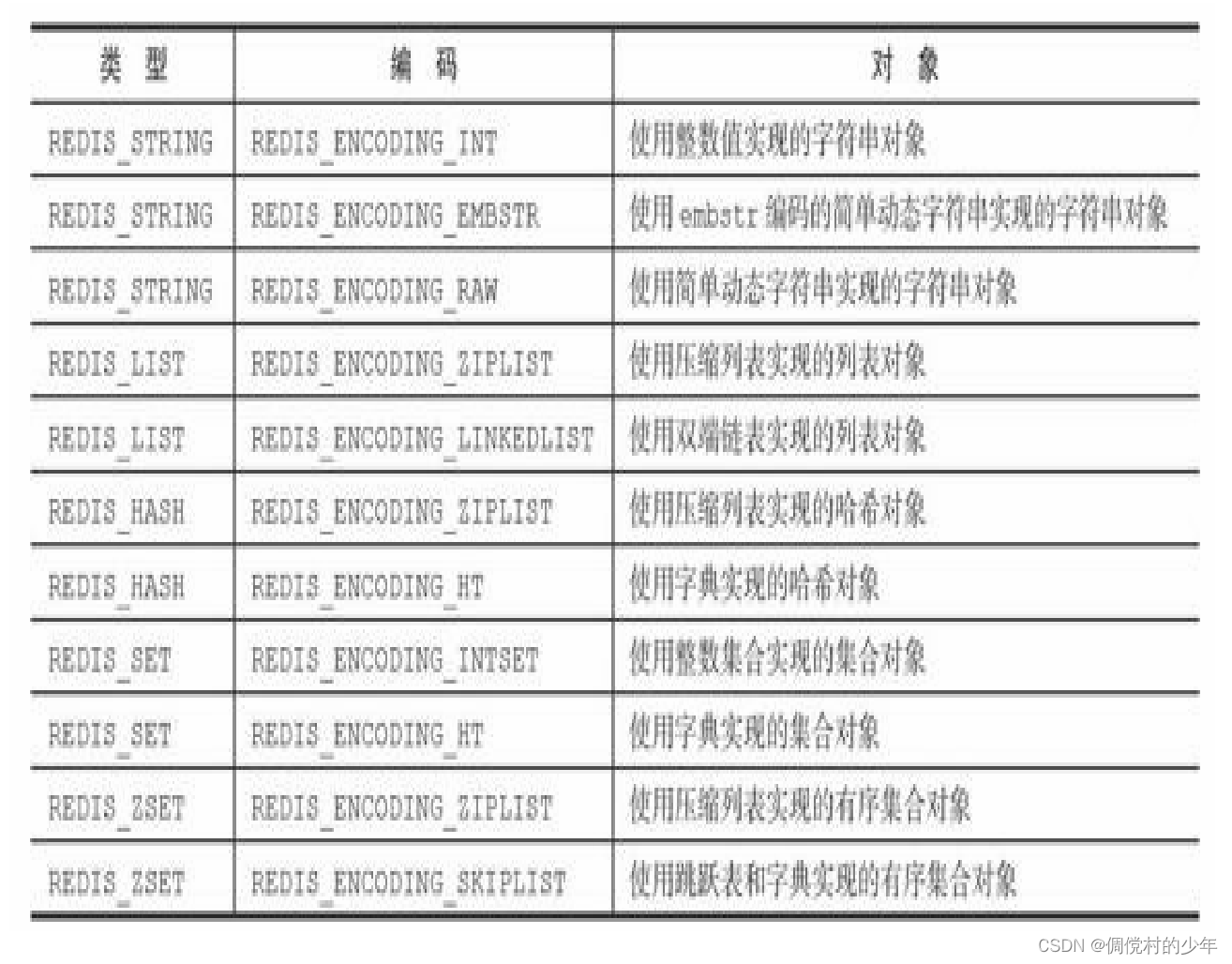
每种类型的对象都至少使用了两种不同的编码,表8-4列出了每种 类型的对象可以使用的编码。
需要大家牢牢记住以及理解
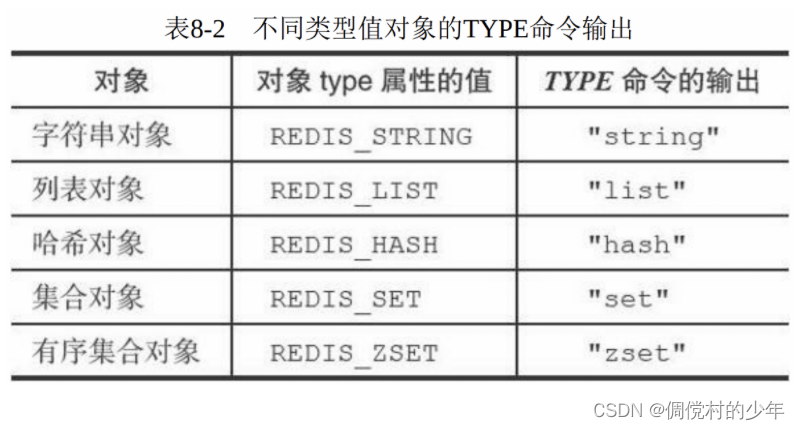
使用OBJECT ENCODING命令可以查看一个数据库键的值对象的编 码:object encoding [key]
2. 字符串对象
字符串对象的编码可以是int、raw或者embstr。
特别提示:浮点数用字符串类型(raw或者embstr)表示
int类型:
如果一个字符串对象保存的是整数值,并且这个整数值可以用long 类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属 性里面(将void*转换成long),并将字符串对象的编码设置为int。
raw类型:
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度 大于32字节,那么字符串对象将使用一个简单动态字符串(SDS)来保 存这个字符串值,并将对象的编码设置为raw。
embstr类型:
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度 小于等于32字节,那么字符串对象将使用embstr编码的方式来保存这个 字符串值。
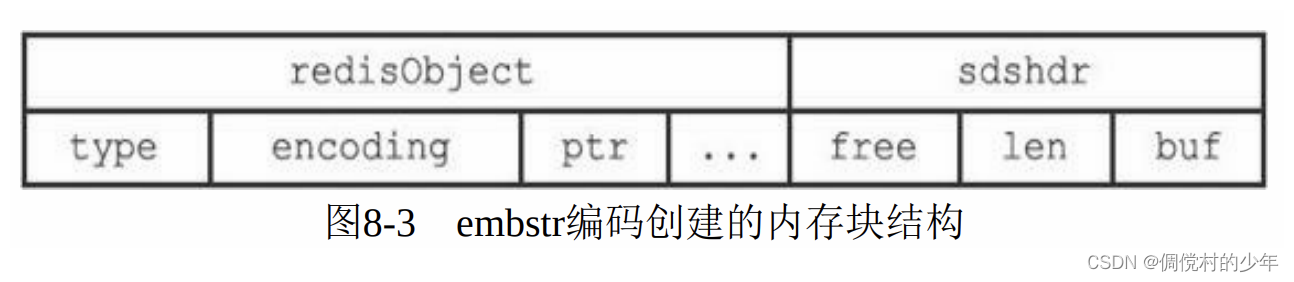
raw和embstr的区别:
相同:都是用SDS实现 的
不同:
-
embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次。(具体为什么是一次,是代码实现的)
-
释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数。
-
因为embstr编码的字符串对象的所有数据都保存在一块连续的内存 里面,所以这种编码的字符串对象比起raw编码的字符串对象能够更好 地利用缓存带来的优势。
2.1编码的转换
int转为raw:
向int 增加字符是的保持的对象不再是数值,那么会转为raw。

embstr转为raw:
embstr没设有操作接口,每一个都是不可变的,所以只要增加字符,就会转为raw。

2.2 字符串操作命令
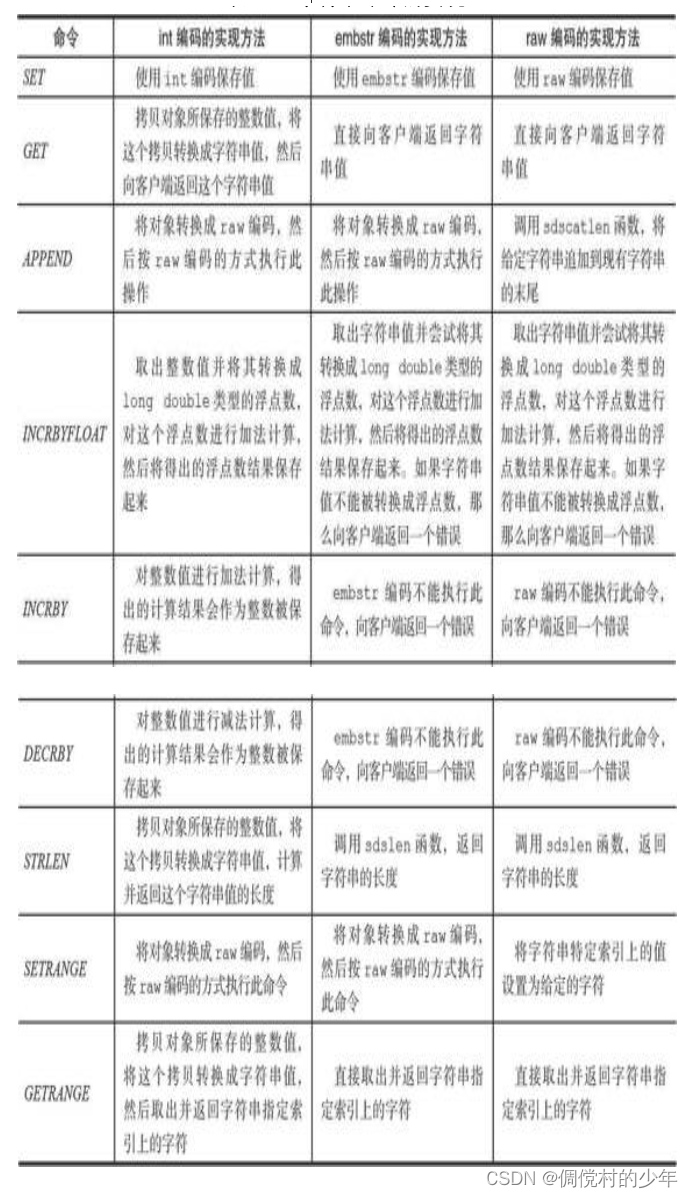
3.列表对象
列表对象的编码可以是ziplist或者linkedlist。
ziplist编码的列表对象使用压缩列表作为底层实现,每个压缩列表 节点(entry)保存了一个列表元素。举个例子,如果我们执行以下 RPUSH命令,那么服务器将创建一个列表对象作为numbers键的值:
RPUSH numbers 1 "1231" 5
另一方面,linkedlist编码的列表对象使用双端链表作为底层实现, 每个双端链表节点(node)都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素。
注意:
linkedlist编码的列表对象在底层的双端链表结构中包含了多 个字符串对象,这种嵌套字符串对象的行为在稍后介绍的哈希对象、集 合对象和有序集合对象中都会出现,字符串对象是Redis五种类型的对 象中唯一一种会被其他四种类型对象嵌套的对象。(这里是字符串对象,而不是字符串结构)
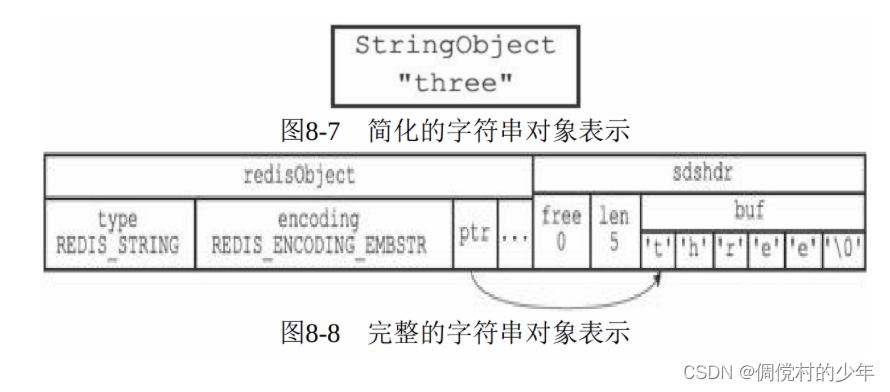
3.1 编码转换
当列表对象可以同时满足以下两个条件时,列表对象使用ziplist编码:
- 列表对象保存的所有字符串元素的长度都小于64字节;
- 列表对象保存的元素数量小于512个;不能满足这两个条件的列表 对象需要使用linkedlist编码。
注意:
以上两个条件的上限值是可以修改的,具体请看配置文件中关于 list-max-ziplist-value选项和list-max-ziplist-entries选项的说明。
3.2列表命令的实现
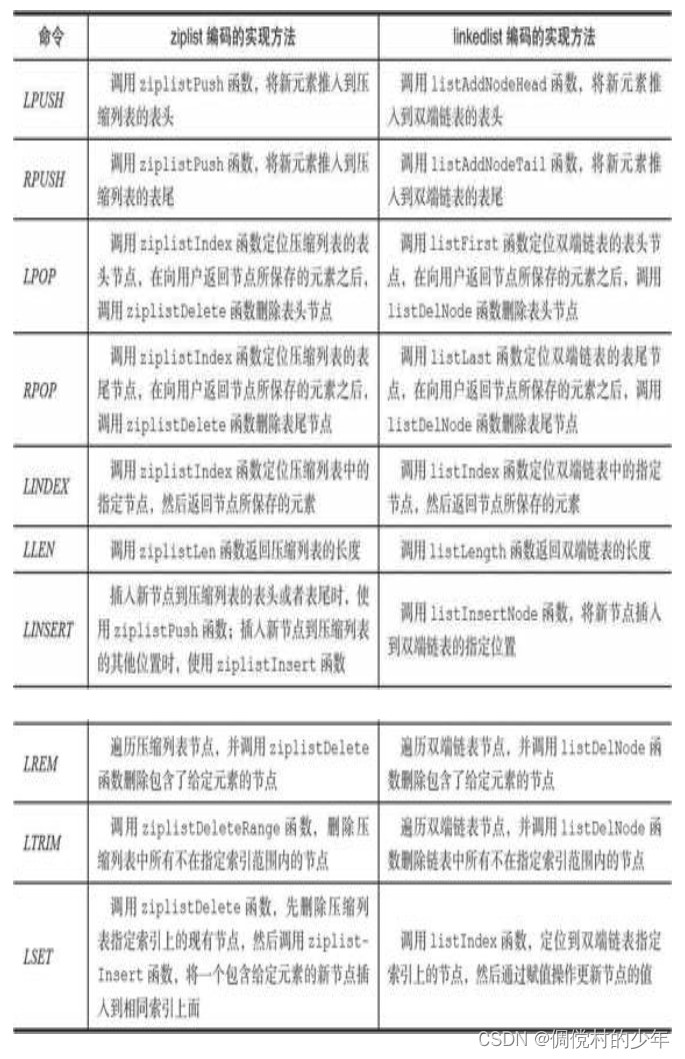
4.哈希对象
哈希对象的编码可以是ziplist或者hashtable。
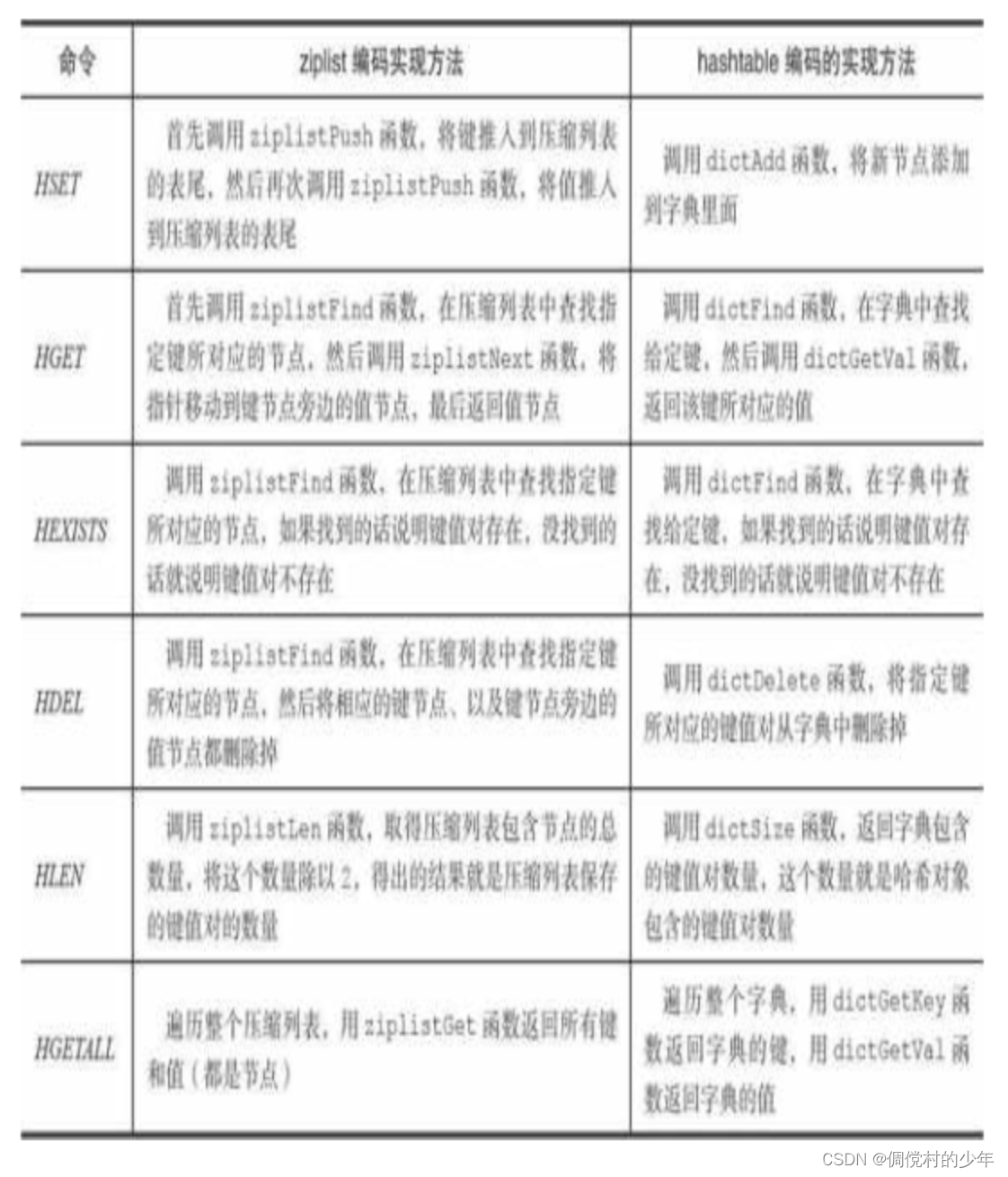
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键 值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到 压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此:
- 保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
举例:
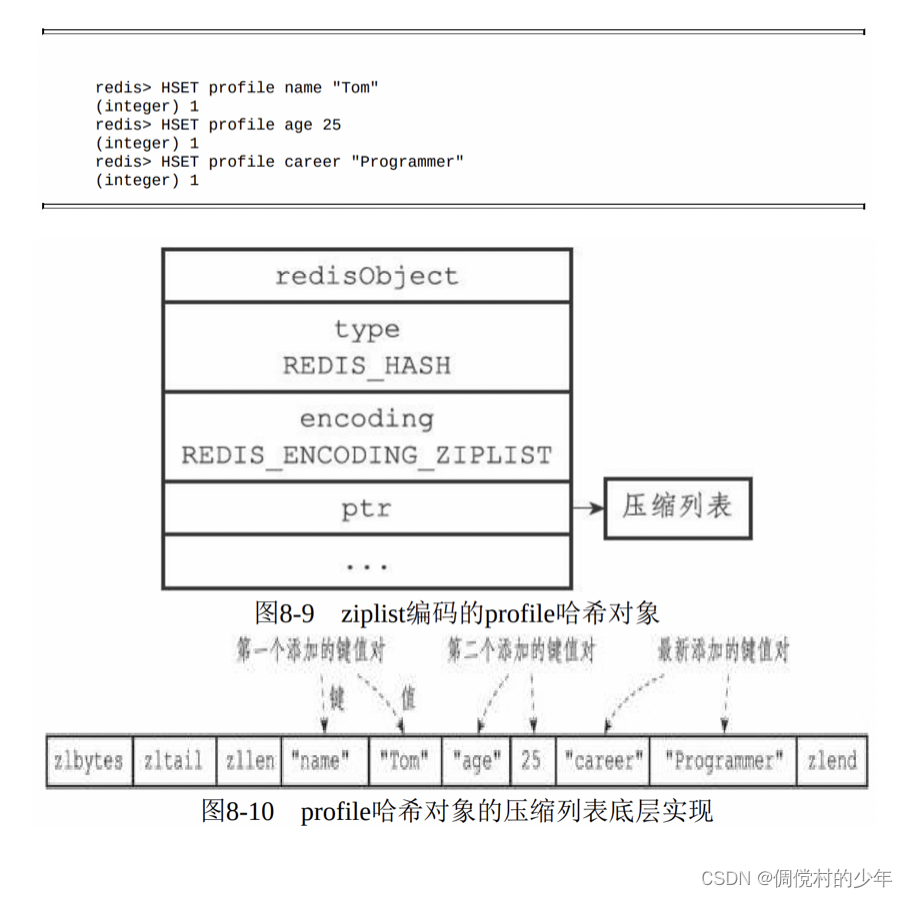
hashtable编码的哈希对象使用字典作为底层实现,哈希 对象中的每个键值对都使用一个字典键值对来保存:
- 字典的每个键都是一个字符串对象,对象中保存了键值对的键;
- 字典的每个值都是一个字符串对象,对象中保存了键值对的值。
4.1编码转换
当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节;
- 哈希对象保存的键值对数量小于512个;不能满足这两个条件的哈 希对象需要使用hashtable编码。
注意:
这两个条件的上限值是可以修改的,具体请看配置文件中关于hashmax-ziplist-value选项和hash-max-ziplist-entries选项的说明。
4.2哈希命令的实现
5.集合对象
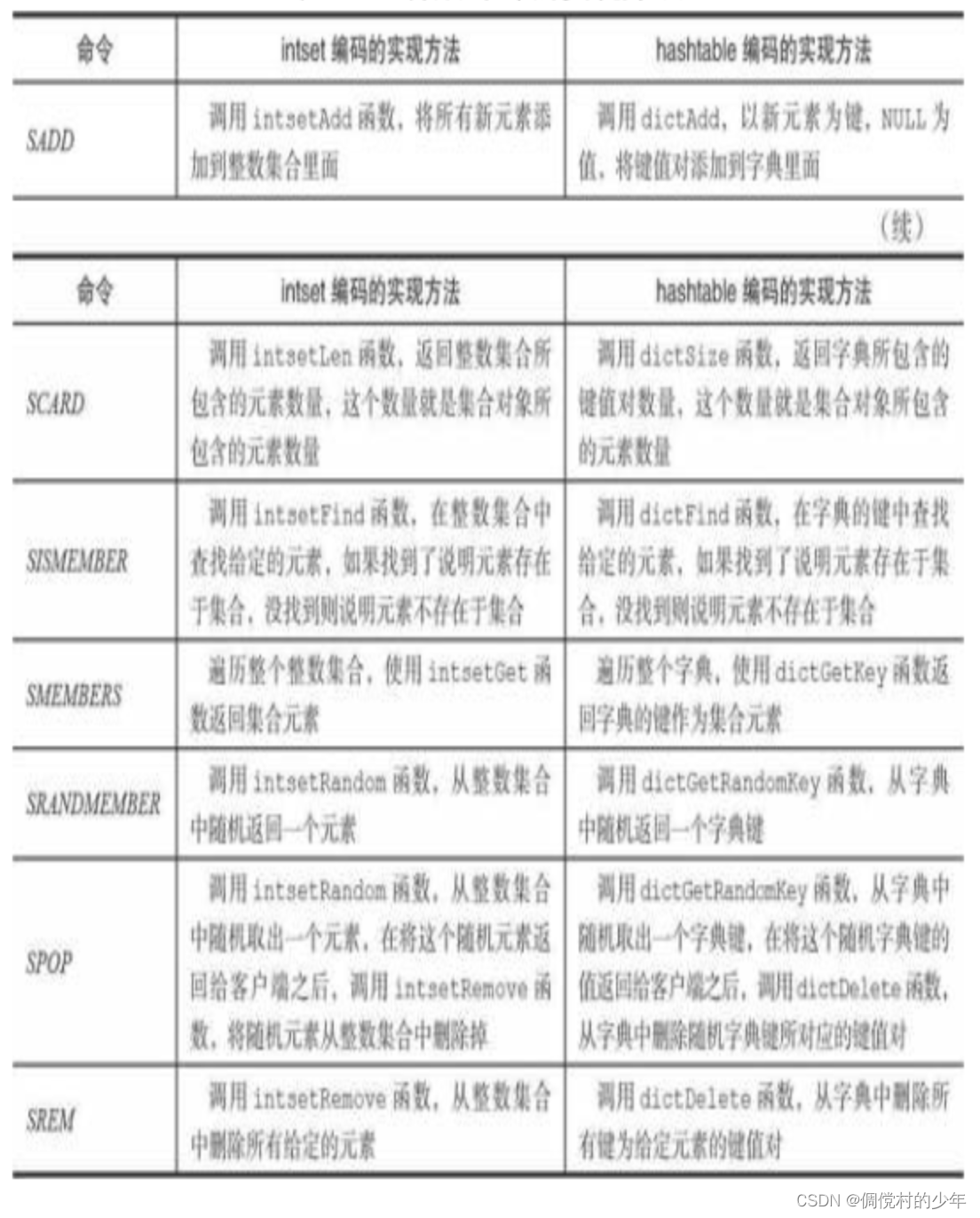
集合对象的编码可以是intset或者hashtable。
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的 所有元素都被保存在整数集合里面。
hashtable编码的集合对象使用字典作为底层实现,字典 的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素, 而字典的值则全部被设置为NULL。
5.1编码转换
当集合对象可以同时满足以下两个条件时,对象使用intset编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过512个
注意:
第二个条件的上限值是可以修改的,具体请看配置文件中关于setmax-intset-entries选项的说明。
5.2集合命令实现
6.有序集合对象
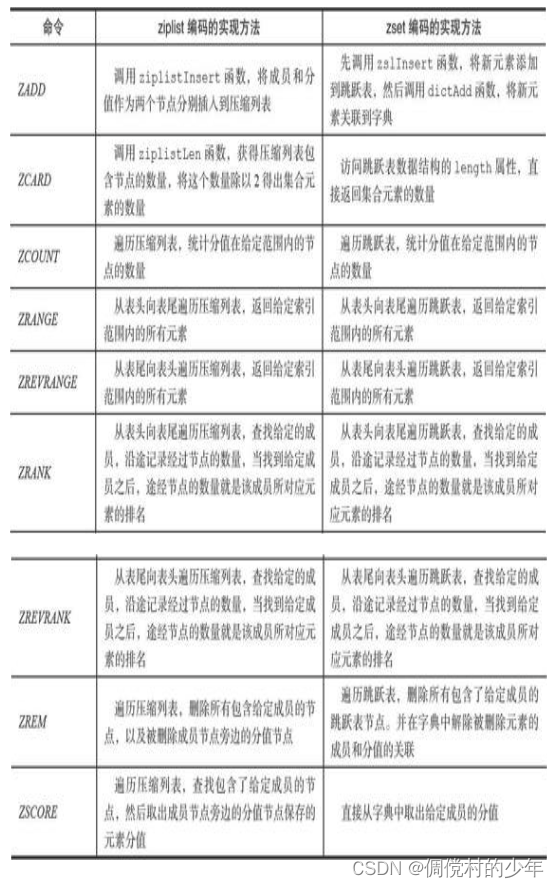
有序集合的编码可以是ziplist或者skiplist。
ziplist编码的压缩列表对象使用压缩列表作为底层实现,每个集合 元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素 的成员(member),而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素 被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方 向。
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表
字典用于存储key-value映射,获取value复杂度为O(1),跳跃表用于排序,例如获取最大5个值,那么复杂度只要O(1),两个联合使用效率就很高。
这种思想值得学习:说到底就是空间换时间,利用两种数据结构优势的互补,牺牲了一点空间获取了效率。
6.1编码的转换
当有序集合对象可以同时满足以下两个条件时,对象使用ziplist编码:
- 有序集合保存的元素数量小于128个;
- 有序集合保存的所有元素成员的长度都小于64字节;
以上两个条件的上限值是可以修改的,具体请看配置文件中关于 zset-max-ziplist-entries选项和zset-max-ziplist-value选项的说明。
6.2有序集合命令的实现
额外的一些常用的命令
ZINCRBY key increment member
有序集合中对指定成员的分数加上增量 increment
ZINTERSTORE destination numkeys key [key …]
计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 中,相同元素score相加
ZUNIONSTORE destination numkeys key [key ...]
计算给定的一个或多个有序集的并集并将结果集存储在新的有序集合 destination 中,相同元素score相加;如果destination已经存在,那么会覆盖里面的值
ZLEXCOUNT key min max
在有序集合中计算指定字典区间内成员数量
ZREMRANGEBYSCORE key min max
删除制定区间成员
7.类型检查和命令多态
Redis中用于操作键的命令基本上可以分为两种类型。
其中一种命令可以对任何类型的键执行,比如说DEL命令、 EXPIRE命令、RENAME命令、TYPE命令、OBJECT命令等。
而另一种命令只能对特定类型的键执行,比如说:
- SET、GET、APPEND、STRLEN等命令只能对字符串键执行;
- HDEL、HSET、HGET、HLEN等命令只能对哈希键执行;
- RPUSH、LPOP、LINSERT、LLEN等命令只能对列表键执行;
- SADD、SPOP、SINTER、SCARD等命令只能对集合键执行;
- ZADD、ZCARD、ZRANK、ZSCORE等命令只能对有序集合键执 行;
多态:
同一命令对同一类型进行操作,但是这一类型有多种实现,但是仍然能正确操作。
8.内存回收
引用计数法
9.对象共享
主要是值共享:
在Redis中,让多个键共享同一个值对象需要执行以下两个步骤:
1)将数据库键的值指针指向一个现有的值对象;
2)将被共享的值对象的引用计数增一
Redis只对包含整数值的字符串对象进行共享,复杂字符串想要共享的话,那么就需要验证是否是完全相同的,这需要的时间很长。
-
如果共享对象是保存整数值的字符串对象,那么验证操作的 复杂度为O(1);
-
如果共享对象是保存字符串值的字符串对象,那么验证操作 的复杂度为O(N);
-
如果共享对象是包含了多个值(或者对象的)对象,比如列 表对象或者哈希对象,那么验证操作的复杂度将会是O(N * N)。
10.对象的空转时长
除了前面介绍过的type、encoding、ptr和refcount四个属性之外, redisObject结构包含的最后一个属性为lru属性,该属性记录了对象最后 一次被命令程序访问的时间。
除了可以被OBJECT IDLETIME命令打印出来之外,键的空转时长 还有另外一项作用:如果服务器打开了maxmemory选项,并且服务器用 于回收内存的算法为volatile-lru或者allkeys-lru,那么当服务器占用的内 存数超过了maxmemory选项所设置的上限值时,空转时长较高的那部分 键会优先被服务器释放,从而回收内存。
总结
本文主要介绍了Redis中对象的类型和编码,以及各种不同类型的对象的特性和使用场景。包括字符串对象、列表对象、哈希对象、集合对象和有序集合对象等。同时,也提到了一些常用的命令操作,如增加元素、获取交集并集、计算成员数量等。此外,还介绍了Redis中的对象共享、内存回收机制以及对象的空转时长等概念。
对于不同的对象底层使用的对象,需要大家熟记于心,在使用的时候才能选对正确的类型。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【EI会议征稿】2024年粤港澳大湾区数字经济与人工智能国际学术会议(DEAI2024)
- 【MySQL】数据处理之增删改
- 微信公众号网页授权登录获取用户信息存入数据库
- 百度CTO王海峰:文心一言用户规模破1亿
- 面试题:Docker命令大全及相关技术名词
- 27 在Vue3中使用监听器
- 山西电力市场日前价格预测【2024-01-06】
- redis集群 —— 高性能
- weblogic部署应用包(从开发到部署)
- 爬虫工作量由小到大的思维转变---<第二十五章 Scrapy开始很快,越来越慢(追溯篇)>