【OCR项目】之用HALCON的深度学习工具进行文字识别,并导出到C++调用
发布时间:2024年01月21日
前言
HALCON是一个强大的机器视觉工具,包含了2D,3D图像各种算子,以及各种任务的深度学习工具,包括目标检测,实例分割,文字识别等。
这次从实际生产的角度,来分享一下如何用HALCON进行文字识别。
衡量一个技术是否能在实际工业生产使用,要考虑的因素:
- 最重要的一点,精度要高且稳定。在复杂的工业场景,需要能稳定的做到非常高的精度,而不是像简单的示例程序或者学生作品一样,只是学习和展示使用。这点HALCON的深度学习OCR可以满足大部分普通的工业场景。
- 这里有一个细节,HALCON的版本越高,理论上提供的模型结构要越先进,预训练模型精度也越高。这里使用的是22.05的版本。
- 速度要快。HALCON做深度学习OCR即使使用CPU进行识别,速度也非常快。
- 需要能整合到实际开发的软件工程里。HALCON支持导出成C++,只需要少量的调整。
HALCON代码

HALCON的OCR和现在主流的字符识别任务一样,分成两阶段任务。
- 文本检测Detection,识别出文本行的位置。
- 文本识别Recognition,把Detection任务检测出来的文本行抠出来进行识别。
并且HALCON支持像上面图片这样倾斜的文字,下面是简单的实现代码和逐行解释。
* 读取图片
read_image (Image, 'D:/Project/OCR_demo.jpg')
* 获取显示窗口的句柄
dev_get_window (WindowHandle)
* 设置文字的字体和大小
set_font (WindowHandle, 'Courier New-Bold-' + round(26))
* 创建OCR识别句柄
create_deep_ocr ('mode', 'auto', DeepOcrHandle)
* 创建CPU/GPU设备句柄
query_available_dl_devices ('runtime', 'cpu', DLDeviceHandle)
* 设置OCR使用的设备
set_deep_ocr_param (DeepOcrHandle, 'device', DLDeviceHandle)
* 记录开始时间
count_seconds(StartTime)
* 执行OCR
apply_deep_ocr (Image, DeepOcrHandle, 'auto', DeepOcrResult)
* 记录结束时间
count_seconds(EndTime)
* 计算耗时
Duration := EndTime - StartTime
* 绘制文字
write_string (WindowHandle, '耗时'+Duration+'s')
* 获取结果
get_dict_tuple (DeepOcrResult, 'words', WordsRes)
* 获取文字区域的行坐标
get_dict_tuple (WordsRes, 'row', Rows)
* 获取文字区域的列坐标
get_dict_tuple (WordsRes, 'col', Cols)
* 获取文字区域的倾斜角度
get_dict_tuple (WordsRes, 'phi', Phis)
* 获取文字区域的矩形长边
get_dict_tuple (WordsRes, 'length1', Length1s)
* 获取文字区域的矩形短边
get_dict_tuple (WordsRes, 'length2', Length2s)
* 获取识别文字结果
get_dict_tuple (WordsRes, 'word', Words)
* 设置绘制模式为画轮廓
dev_set_draw('margin')
* 设置画线的宽度
dev_set_line_width (2)
for Index := 0 to |Rows|-1 by 1
* 绘制带方向的矩形
disp_rectangle2(WindowHandle, Rows[Index], Cols[Index], Phis[Index], Length1s[Index], Length2s[Index])
* 设置文字的坐标
set_tposition(WindowHandle, Rows[Index], Cols[Index])
* 绘制文字
write_string (WindowHandle, Words[Index])
endfor上面的代码运行结果如下,可以看到HALCON在CPU上的速度也是非常快的。

导出C++
HALCON导出到C++也非常方便,只需要点击
【文件】-【导出程序】
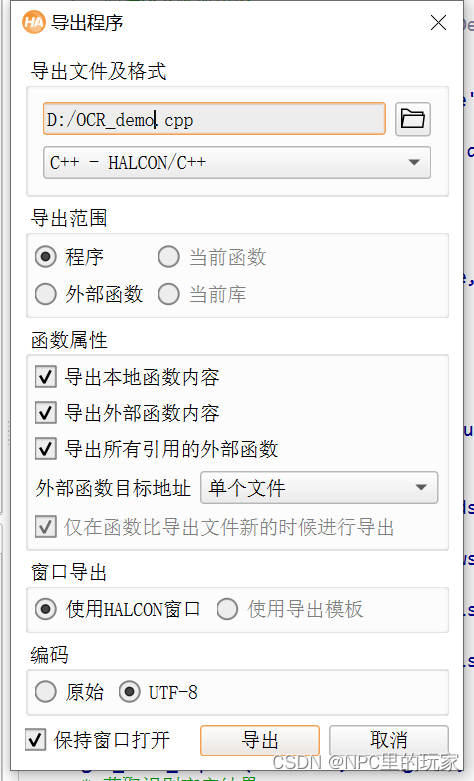
需要注意的点是,上面的HALCON代码虽然在HALCON里运行没有问题,但是直接导出C++运行是会报错的。
因为上面使用的是HALCON自带的模型,导出C++之后,程序里是不带有这个模型的。所以需要将自带的模型导出,然后设置成使用这个模型来进行识别。
使用以下HALCON代码进行模型导出
* 创建自带的OCR模型
create_deep_ocr ('mode', 'auto', DeepOcrHandle)
* 设置导出模型的路径
Filename := 'D:/model.hdo'
* 导出模型
write_deep_ocr (DeepOcrHandle, Filename)然后把上面的识别代码从创建默认OCR识别模型句柄,改成读取指定的模型。
* 创建OCR识别句柄
* create_deep_ocr ('mode', 'auto', DeepOcrHandle)
* 读取指定的模型
read_deep_ocr ('D:/model.hdo', DeepOcrHandle)再进行C++代码导出,就可以使用了。
在C++工程里调用也非常简单,只需要包含halcon.dll,halconcppdll,halcondl.dll即可。
案例
在实际项目中,如果文字足够清晰,预处理足够干净,文本定位足够准确的话,即使使用默认的模型也能达到非常高的精度。
比如下面的例子,通过内容区域提取,透视变换,文本检测,文本位置精细定位,背景分割过滤等手段,将文本区域精准提取出来之后,直接使用默认的模型也可以达到很好的效果。


当然,在针对性的场景,通过标注对应的数据集,并在预训练模型的基础上进行针对性训练,可以达到一个更好的效果,这个步骤也很简单,后面机会再展开讲一下。
文章来源:https://blog.csdn.net/ailaier/article/details/135732047
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue 使用AES加密
- 哪些方法能将静图变动图?这一个网站帮你解决
- mybtis动态SQL注解 脚本动态SQL\方法中构建SQL\SQL语句构造器
- 【开题报告】基于SSM的汉服装造预约平台的设计与实现
- Done和往常一样,内存地址的格式和值将随系统而异
- 红警1源代码下载,编译,单步调试操作步骤
- 打印的前后顺序
- three.js 缓动算法.easing(渐入相机动画)
- 批量置入视频封面:一分钟教程,简单易学
- 用css和js实现Timeline 时间线组件效果