【霹雳吧啦】手把手带你入门语义分割の番外5:FCN 源码讲解(PyTorch)—— 关于如何通过混淆矩阵计算评价指标
发布时间:2023年12月27日
目录
前言
文章性质:学习笔记 📖
视频教程:FCN源码解析(Pytorch)- 4 通过混淆矩阵计算评价指标
主要内容:根据 视频教程 中提供的 FCN 源代码(PyTorch),讲解了如何通过混淆矩阵计算评价指标。
Preparation

一、混淆矩阵的相关代码
1、evaluate 函数
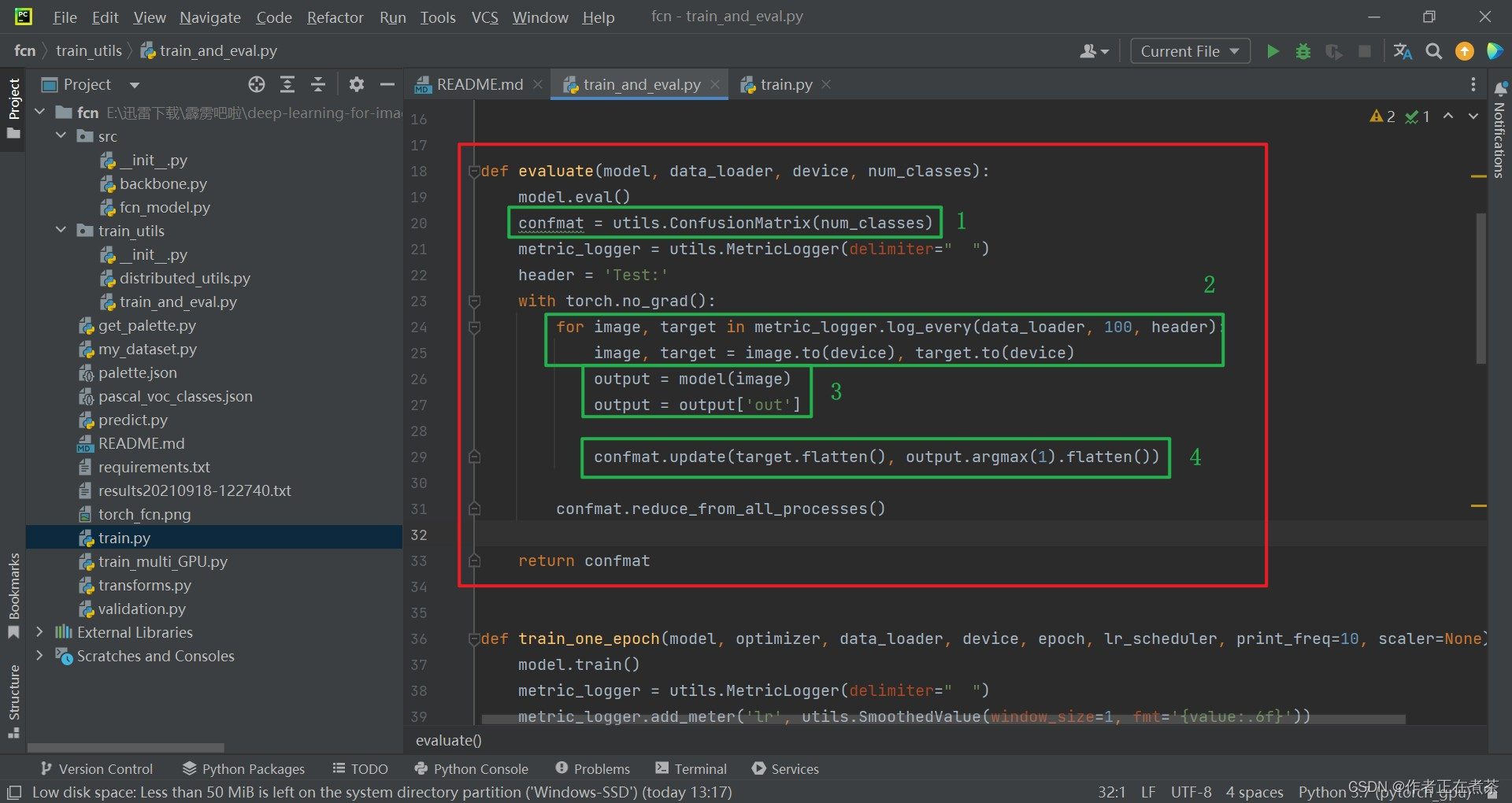
在 train_and_val.py 文件中的?evaluate?函数代码如下:
def evaluate(model, data_loader, device, num_classes):
model.eval()
confmat = utils.ConfusionMatrix(num_classes)
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, 100, header):
image, target = image.to(device), target.to(device)
output = model(image)
output = output['out']
confmat.update(target.flatten(), output.argmax(1).flatten())
confmat.reduce_from_all_processes()
return confmat【代码解析】对 evaluate 函数代码的具体解析(结合下图):
- ?创建?ConfusionMatrix 混淆矩阵
- ?使用 for 循环遍历 data_loader 得到 image 和 target 信息,并将其指给对应的设备当中
- ?再将 image 图像输入到 model 模型中进行预测,得到 output 输出(只使用主分支上的输出)
- ?调用 update 方法时,在计算每一批数据预测结果与真实结果对比的过程中,将 target 和 output.argmax(1) 进行 flatten 处理
【注意】?output.argmax(1) 中的 1 是指在 channel 维度,而 argmax 方法用于?将每个像素预测值最大的类别作为其预测类别 。
2、ConfusionMatrix 类
在 distributed_utils.py 文件中的?ConfusionMatrix 类代码如下:
class ConfusionMatrix(object):
def __init__(self, num_classes):
self.num_classes = num_classes
self.mat = None
def update(self, a, b):
n = self.num_classes
if self.mat is None:
# 创建混淆矩阵
self.mat = torch.zeros((n, n), dtype=torch.int64, device=a.device)
with torch.no_grad():
# 寻找GT中为目标的像素索引
k = (a >= 0) & (a < n)
# 统计像素真实类别a[k]被预测成类别b[k]的个数(这里的做法很巧妙)
inds = n * a[k].to(torch.int64) + b[k]
self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)
def reset(self):
if self.mat is not None:
self.mat.zero_()
def compute(self):
h = self.mat.float()
# 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)
acc_global = torch.diag(h).sum() / h.sum()
# 计算每个类别的准确率
acc = torch.diag(h) / h.sum(1)
# 计算每个类别预测与真实目标的iou
iu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))
return acc_global, acc, iu
def reduce_from_all_processes(self):
if not torch.distributed.is_available():
return
if not torch.distributed.is_initialized():
return
torch.distributed.barrier()
torch.distributed.all_reduce(self.mat)
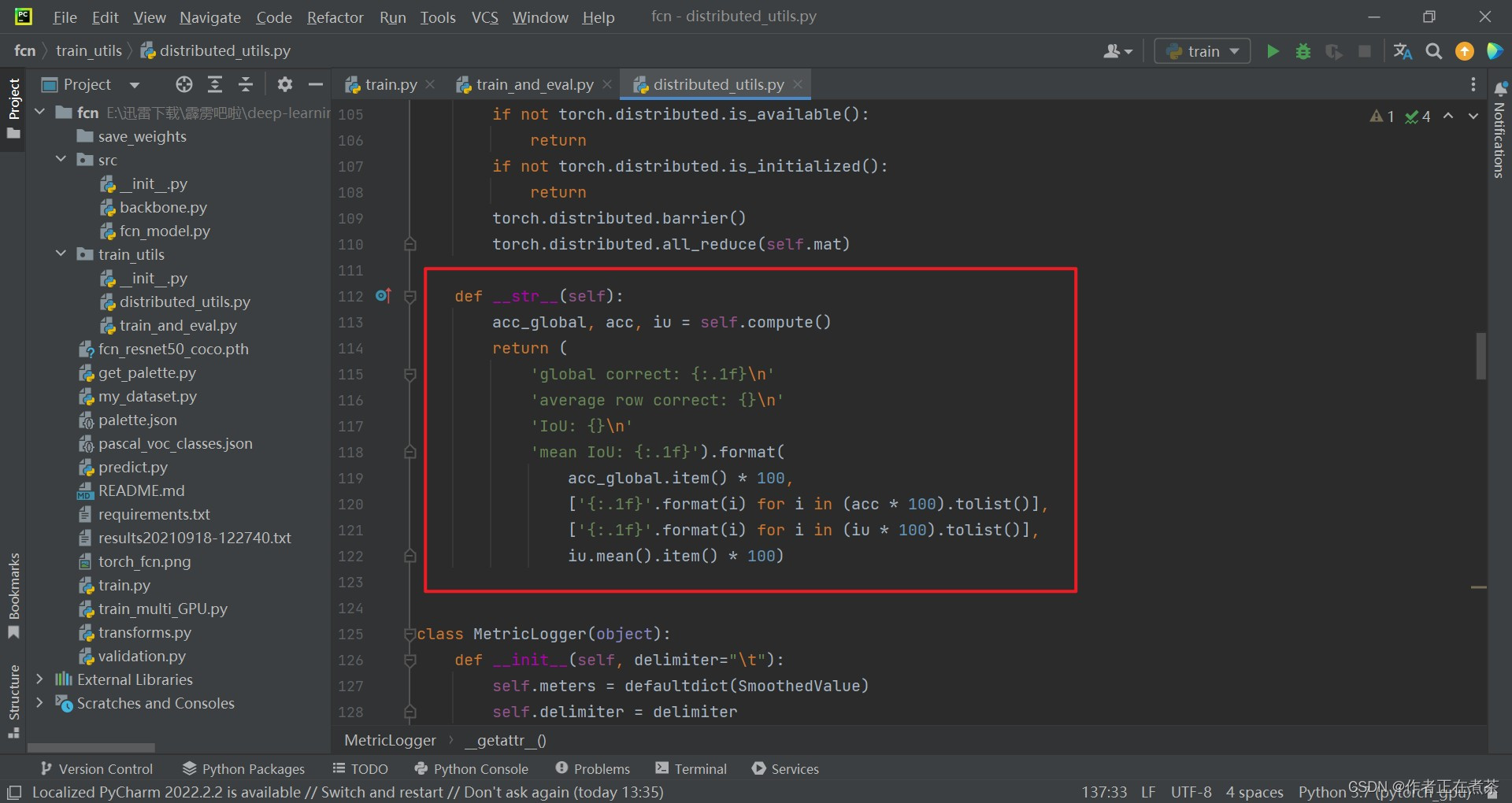
def __str__(self):
acc_global, acc, iu = self.compute()
return (
'global correct: {:.1f}\n'
'average row correct: {}\n'
'IoU: {}\n'
'mean IoU: {:.1f}').format(
acc_global.item() * 100,
['{:.1f}'.format(i) for i in (acc * 100).tolist()],
['{:.1f}'.format(i) for i in (iu * 100).tolist()],
iu.mean().item() * 100)(1)update 函数

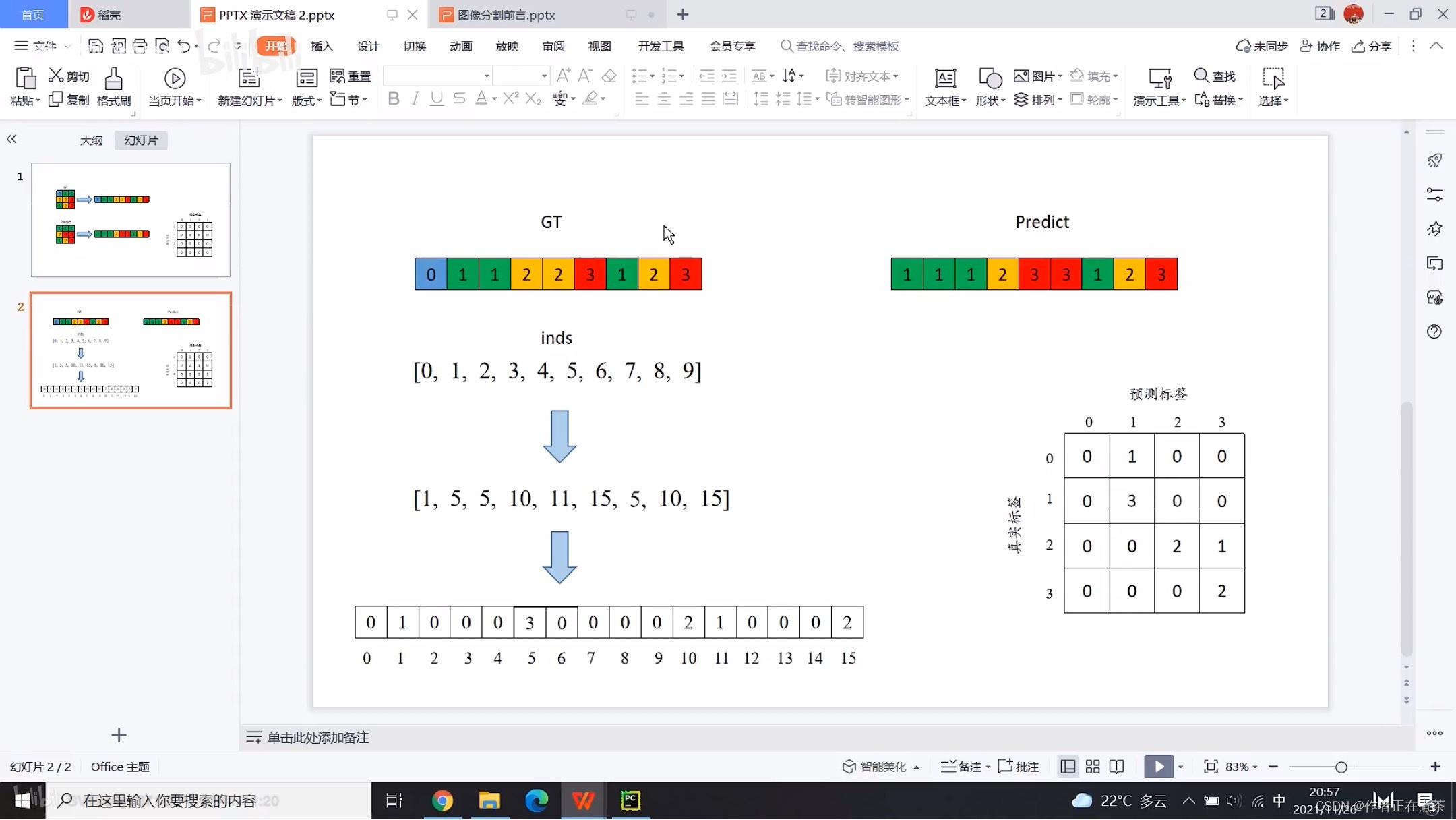
【代码解析】ConfusionMatrix 类中的 update 函数传入了真实标签 a 和预测标签 b 等参数,代码的具体解析(结合上图):
- ?这里的 num_classes 是指包含了背景的类别个数。
- ?如果 self.mat 是?None ,就使用 torch.zeros 创建一个全零矩阵作为混淆矩阵,大小为 n x n ,用于记录真实标签和预测标签之间的关系。
- ?通过检查真实标签 a 中的元素是否属于有效类别范围 [ 0 , N ) 来寻找属于目标类别的像素索引。
- ?根据像素的真实类别 a [ k ] 和预测类别 b [ k ] 计算类别索引 inds ,用于统计真实类别为 a [ k ] 被预测成 b [ k ] 的像素个数。
- ?使用 torch.bincount 统计类别索引 inds 在 [ 0 , n**2 ) 内的出现次数,并将结果重塑成 ( n , n ) 的矩阵形状,统计数据累加到混淆矩阵中。
【注意】关于?FCN 源码中的混淆矩阵,其横坐标是预测标签,纵坐标是真实标签,与【回顾】中的混淆矩阵恰好相反。
(2)compute 函数

【代码解析】具体的计算过程可以参考【回顾】中的截图,注意代码中混淆矩阵的横纵坐标与【回顾】示例中的相反:
- 调用 torch.diag(h) 方法去获取混淆矩阵对角线上的元素,得到的是列表形式,再用 sum() 求和的方法来计算对角线上的元素之和。
- 使用 h.sum() 方法对混淆矩阵 所有元素 进行求和。
- 使用 h.sum(1) 方法对混淆矩阵 每行元素 进行求和,即所有真实类别为该类别的像素个数。
- 使用 h.sum(0) 方法对混淆矩阵 每列元素 进行求和,即所有预测类别为该类别的像素个数。
- 使用?torch.diag(h) / h.sum(1) 计算 预测正确的类别个数 除以 所有真实类别为该类别的像素个数 。
- 使用 torch.diag(h) / ( h.sum(1) + h.sum(0) - torch.diag(h) ) 计算 预测正确的类别个数 除以?( 对应行列的元素之和?- 预测正确的类别个数 )?。
(3)__str__ 函数?
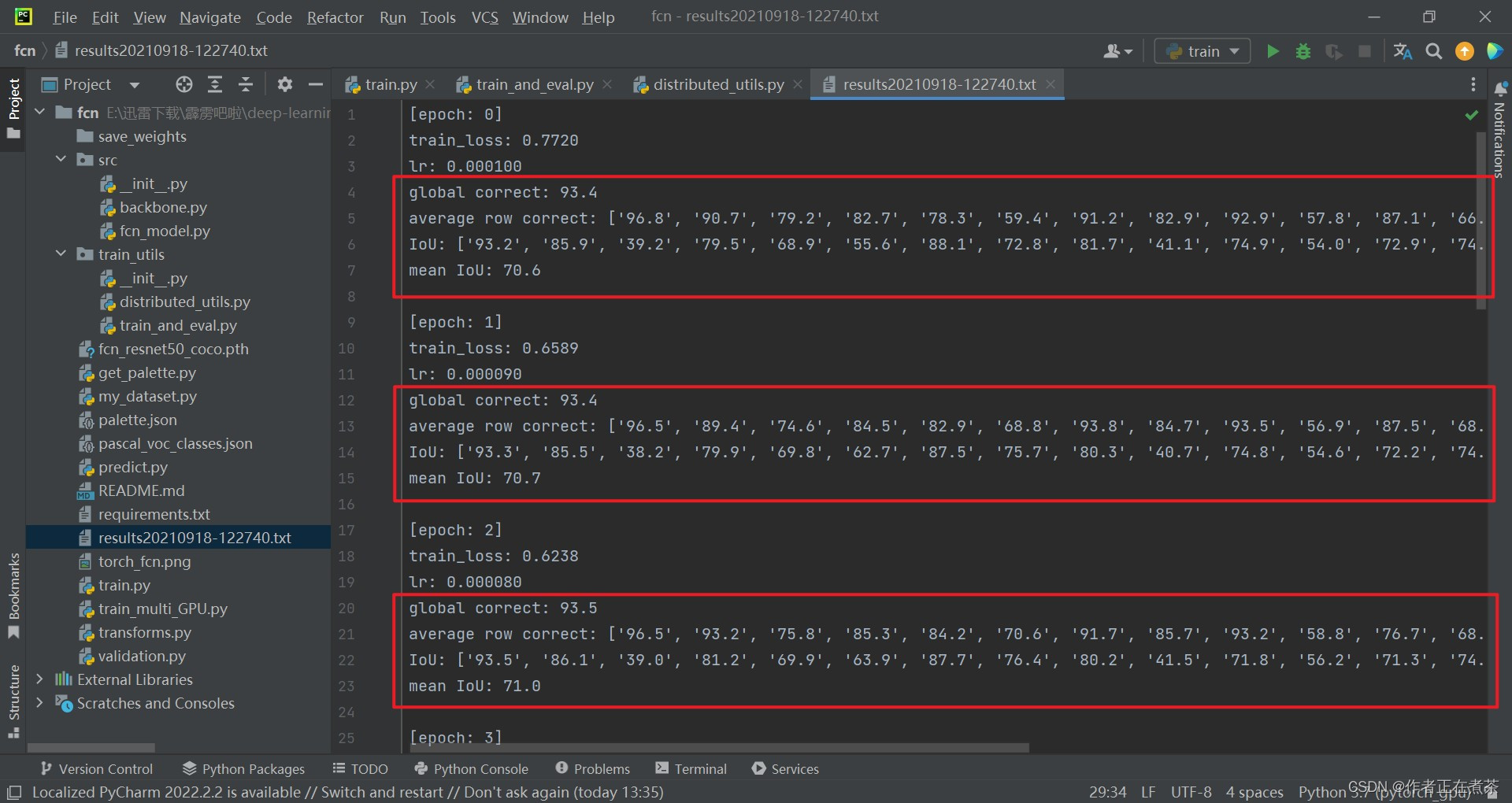
【说明】用 * 100 表示百分数,使用 iu.mean() 计算平均数,输出格式如下图所示:
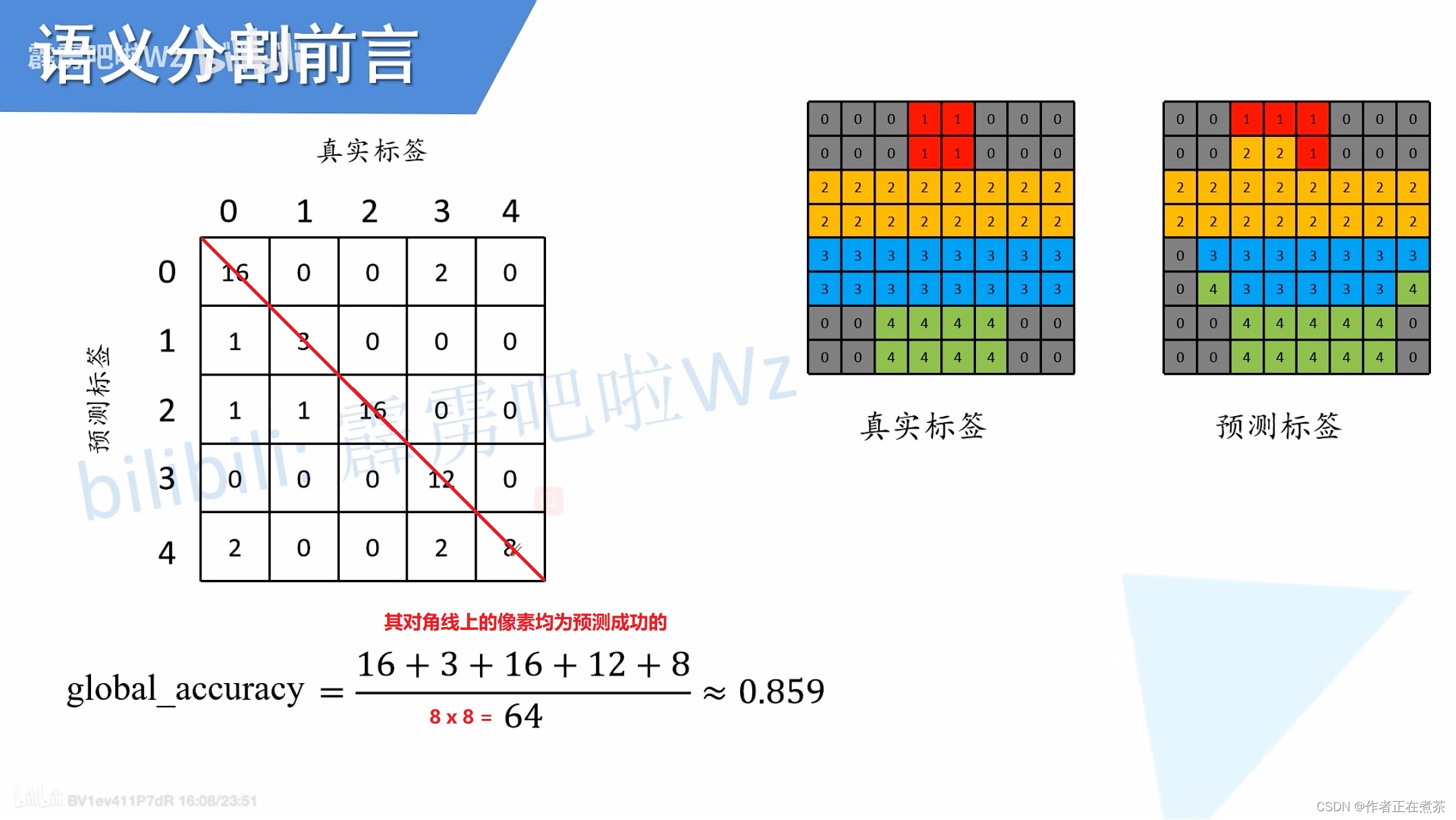
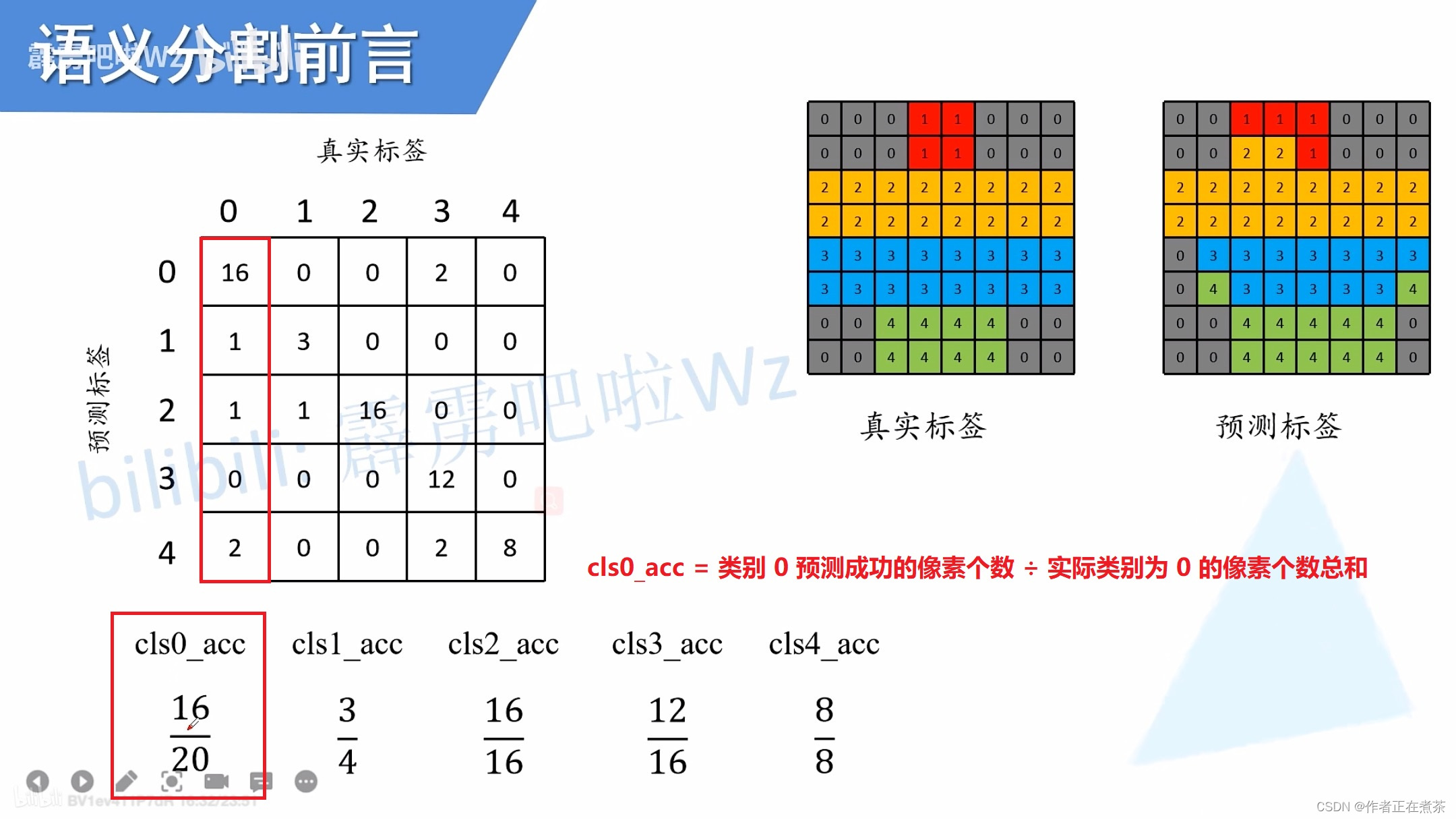
回顾:语义分割的评价指标
常见的语义分割评价指标主要包括 Pixel Accuracy ( Global Accuracy )、mean Accuracy、mean IoU 等:
- Pixel Accuracy = 类别预测正确的像素个数总和 ÷ 图片的总像素个数
- mean Accuracy = 对每个类别的 Accuracy 求平均值
- mean IoU = 对每个类别的 IoU 求平均值
关于语义分割评价指标,微臣在本系列的第一篇文章中已经作了详细的讲解,王子公主们请移驾我的这篇博文:

文章来源:https://blog.csdn.net/nanzhou520/article/details/135120471
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 17/100全排列 18/100电话号码的字母组合 19/100四数之和
- 数据结构,第8章:排序(复习)
- 【WinForm.NET开发】实现使用后台操作的窗体
- 智能计价器Scratch-第14届蓝桥杯Scratch省赛真题第5题
- 《ORANGE’S:一个操作系统的实现》读书笔记(三十一)文件系统(六)
- 印尼小胖子表情包大全
- Python---类(初始化函数)
- 自动化测试与功能测试
- xshell可以远程登录服务器但是vscode一直显示让输入密码的解决方案
- 统计学-R语言-2.1