【数据采集与预处理】流数据采集工具Flume
一、Flume简介
数据流 :数据流通常被视为一个随时间延续而无限增长的动态数据集合,是一组顺序、大量、快速、连续到达的数据序列。通过对流数据处理,可以进行卫星云图监测、股市走向分析、网络攻击判断、传感器实时信号分析。
(一)Flume定义
????????Apache Flume是一种分布式、具有高可靠和高可用性的数据采集系统,可从多个不同类型、不同来源的数据流汇集到集中式数据存储系统中。Flume 基于流式架构,灵活简单。
(二)Flume作用
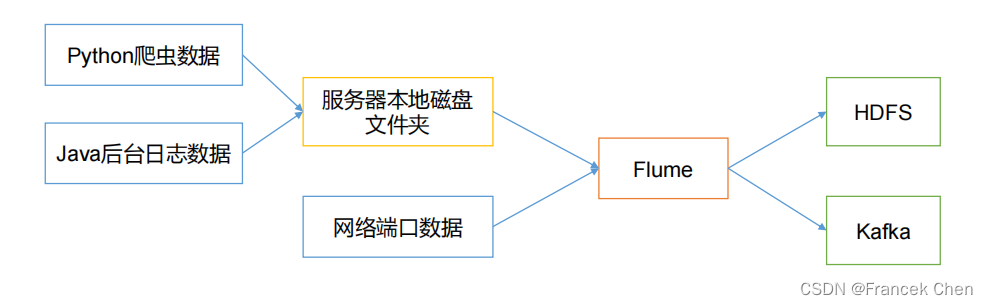
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
二、Flume组成架构

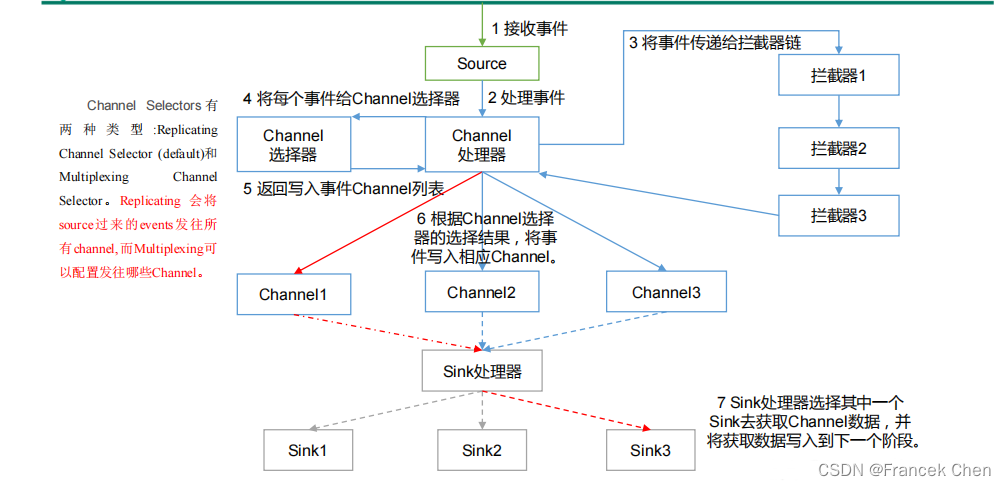
1、Agent
????????Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的,是 Flume 数据传输的基本单元。Agent 主要有 3 个部分组成,Source、Channel、Sink。
2、Source
????????Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
3、Channel
????????Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
4、 Sink
????????Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
????????Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
????????Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
5、Event
????????传输单元,Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume Agent 内部原理:
三、Flume安装配置
(一)下载Flume
到Flume官网下载Flume1.7.0安装文件,下载地址如下:
http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
下载完成后上传到虚拟机的“/usr/local/uploads”目录下。
(二)解压安装包
首先进入到“uploads”目录下。将压缩包解压到“/usr/local”目录下
[root@bigdata zhc]# cd /usr/local/uploads
[root@bigdata uploads]# tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /usr/local
 ?
?
将解压的文件修改名字为flume,简化操作。把/usr/local/flume目录的权限赋予当前登录Linux系统的用户。
[root@bigdata uploads]# cd /usr/local
[root@bigdata local]# mv apache-flume-1.7.0-bin flume
[root@bigdata local]# chown -R zhc:zhc ./flume
? ?
?
(三)配置环境变量
首先,修改/etc/profile配置文件:
[root@bigdata local]# vi /etc/profile
 ?
?
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin
export FLUME_CONF_DIR=$FLUME_HOME/conf使文件生效:
[root@bigdata local]# source /etc/profile下面修改 flume-env.sh 配置文件:
[root@bigdata local]# cd /usr/local/flume/conf
[root@bigdata conf]# cp flume-env.sh.template flume-env.sh
[root@bigdata conf]# vi flume-env.sh
?
在文件中增加一行内容,用于设置JAVA_HOME变量:
export JAVA_HOME=/usr/local/servers/jdk ?
?
然后,保存flume-env.sh文件,并退出vim编辑器。
(四)查看Flume版本信息
[root@bigdata conf]# cd /usr/local/flume
[root@bigdata flume]# ./bin/flume-ng version
然后就会发现如下报错: “错误: 找不到或无法加载主类”
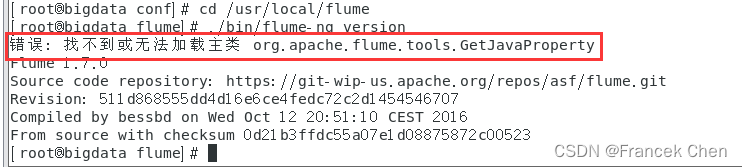
原因分析:
(1)jdk 冲突
(2)安装了HBase就会报着个错
解决方法:
到“/usr/local/flume/bin”目录下修改flume-ng文件。
[root@bigdata flume]# cd /usr/local/flume/bin
[root@bigdata bin]# vi flume-ng
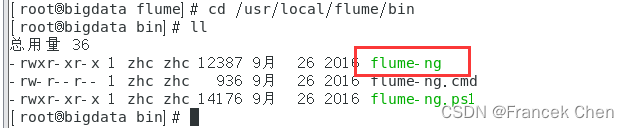
在文件中加入以下内容:
2>/dev/null | grep hbase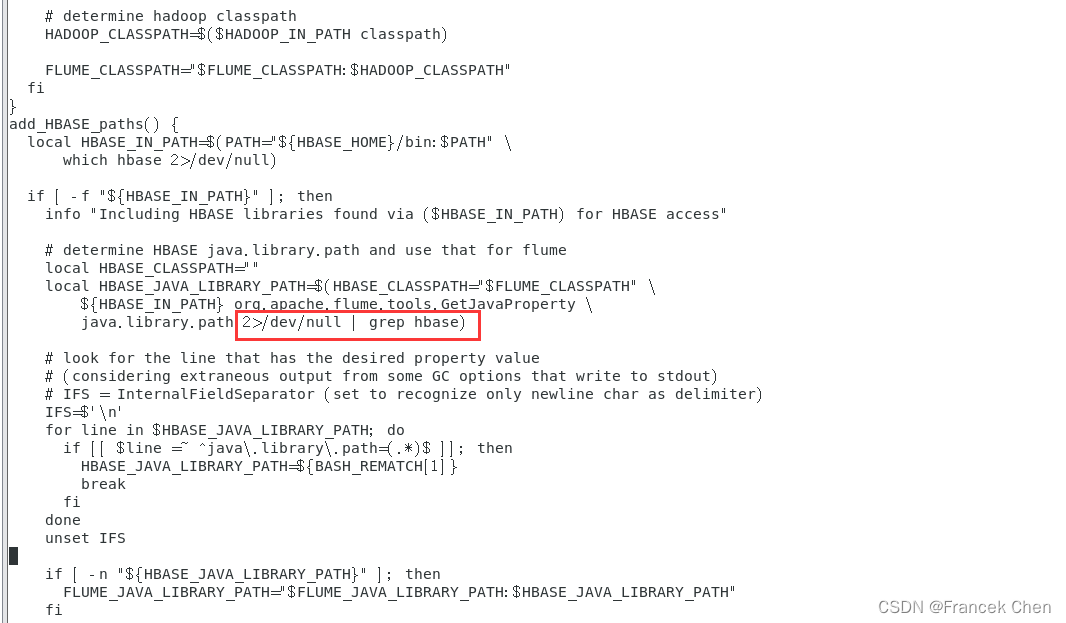
再次查看flume版本信息。

四、使用Flume作为Spark Streaming数据源
????????Flume是非常流行的日志采集系统,可以作为Spark Streaming的高级数据源。请把Flume Source设置为netcat类型,从终端上不断给Flume Source发送各种消息,Flume把消息汇集到Sink,这里把Sink类型设置为avro,由Sink把消息推送给Spark Streaming,由自己编写的Spark Streaming应用程序对消息进行处理。
(一)Spark准备工作
1、下载spark-streaming-flume_2.11-2.3.4.jar
首先,到官网下载spark-streaming-flume_2.11-2.3.4.jar:
https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume
上面的网址要是打不开,可以用下面的这个网址:
Central Repository: org/apache/spark/spark-streaming-flume_2.11

2、把这个jar文件放到“/usr/local/spark/jars/flume”目录下
[root@bigdata flume]# cd /usr/local/spark/jars
[root@bigdata jars]# mkdir flume
[root@bigdata jars]# cd flume
[root@bigdata flume]# cp /usr/local/uploads/spark-streaming-flume_2.11-2.3.4.jar .

注意:此处不要将“/usr/local/flume/lib”目录下的所有jar包都拷贝到“/usr/local/spark/jars/flume” 目录下,不然会使Spark和Hadoop版本与Guava库的版本不兼容,从而导致后面运行程序时会报错!
3、修改spark-env.sh文件
[root@bigdata flume]# cd /usr/local/spark/conf
[root@bigdata conf]# vi spark-env.sh
将如下内容加到文件中:?
:/usr/local/spark/jars/flume/*:/usr/local/flume/lib/*
这样,Spark环境就准备好了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 太强了!MySQL、Oracle、PostgreSQL 数据库备份拿来就用的 Shell 脚本!
- 信息学奥赛一本通1015:计算并联电阻的阻值
- C语言算法赛——蓝桥杯(省赛试题)
- 成都直播电商市场发展空间广阔,成都直播产业园预计未来三年市场规模持续上升
- 欧洲十大跨境电商平台,自养号测评下单的重要性及优势
- 13个数据可视化工具 一键生成可视化图表
- 第一个Python程序-HelloWorld
- Fortinet【SD-WAN】& 阿里云企业网CEN混合组网解决方案,计算巢一键交付
- ros python 接收GPS RTK 串口消息再转发 ros 主题消息
- 完全适配各类中小医院专科医院和诊所的云HIS系统源码【前端:Angular+Nginx ,后台:SpringBoot】