【C++干货铺】会搜索的二叉树(BSTree)
=========================================================================
个人主页点击直达:小白不是程序媛
C++系列专栏:C++干货铺
代码仓库:Gitee
=========================================================================
目录
前言:
在C语言的数据结构期间我们介绍过二叉树的一些概念;并且实现了其链式结构和实现了前、中、后序的遍历;有些OJ题使用C语言方式实现比较麻烦,比如有些地方要返回动态开辟的二维数组,非常麻烦。因此本节借二叉树搜索树,对二叉树部分进行收尾总结。并且后面的map和set特性需要先铺垫二叉搜索树,而二叉搜索树也是一种树形结构;二叉搜索树的特性了解,有助于更好的理解map和set的特性。
二叉搜索树
二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树

二叉搜索树操作
二叉搜索树的中序遍历根据其存储结构是排好序的。
- 如果左边存储比根小的数字右边存储比根大的数字,中序遍历的结果是升序的;
- 如果左边存储比根大的数组右边存储比根小的数字,中序遍历的结果是降序的;
int a[] = {8, 3, 1, 10, 6, 4, 7, 14, 13};
注意:二叉搜索树是没有“修改”的,因为如果随便修改一个数据,整棵树都要重新去实现。?
二叉搜索树的查找
- 从根开始比较,查找,比根大则往右边走查找,比根小则往左边走查找。
- 最多查找高度次,走到空,还没找到,这个值不存在。?
注意:
二叉搜索树有一个特别重要的特点:树中没有两个相同的元素。
?二叉搜索树的插入
插入的具体过程如下:
- 树为空,则直接新增节点,赋值给root指针
- 树不空,按二叉搜索树性质查找插入位置,插入新节点?

二叉搜索树元素的删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情
况:
- 要删除的结点无孩子结点
- 要删除的结点只有左孩子结点
- 要删除的结点只有右孩子结点
- 要删除的结点有左、右孩子结点
看起来有待删除节点有4中情况,实际情况1可以与情况2或者3合并起来,因此真正的删除过程
如下:?
- 情况b:删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点--直接删除
- 情况c:删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点--直接删除
- 情况d:在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该结点的删除问题--替换法删除

二叉搜索树的实现
BSTree结点
节点中包含两个该节点类型的指针,分别代表着指向左右孩子和节点中存储的值。
template <class K>
struct BSTNode
{
BSTNode<K>* _left;
BSTNode<K>* _right;
K _key;
//结点的构造函数
BSTNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
{
}
};BSTree框架
成员变量为结点类型的指针。
template<class K>
class BST
{
typedef BSTNode<K> Node;
private:
Node* _root=nullptr;
};拷贝构造函数和无参构造函数
因为我们自己写了拷贝构造函数,所以编译器不会默认生成无参构造函数。在C++11中可以让默认构造函数等于default,让编译器再次自动生成默认构造函数。
拷贝一个二叉搜索树开始要使用递归进行调用的。?
BST() = default;
BST(const BST<K>& st)
{
_root=Copy(st._root);
}析构函数
因为我们在类外面显示调用根节点很麻烦,直接在类内部以根节点为参数直接递归实现。
public:
~BST()
{
Destory(_root);
}
private:
?
void Destory(Node*& root)
{
if (root == nullptr)
{
return;
}
Destory(root->_left);
Destory(root->_right);
delete root;
root = nullptr;
}
?赋值重载(operator=)
swap函数是库std中的函数,深拷贝;
BST<K>& operator=(BST<K> t)
{
swap(_root, t._root);
return *this;
}插入Insert ()
非递归版本
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
parent = cur;
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key);
if (parent->_key < key)
{
parent->_right = cur;
}
else if (parent->_key > key)
{
parent->_left = cur;
}
}
- 首先还是要判断传入的根结点是否为空,如果为空直接开辟一个新的结点即可;
- 如果不为空,先创建一个父亲的结点便于插入的时候做修改;然后在创建一个结点从根节点开始根据二叉搜索树的特点开始找适合插入的位置,当找到时开辟一个新的结点,然后让合适位置的根节点指向开辟好的新节点即可;
递归版本
pbulic:
bool InsertR(const K & key)
{
return _InsertR(_root, key);
}
private:
?
bool _InsertR(Node*& root,const K& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (root->_key < key)
{
return _InsertR(root->_right, key);
}
else if (root->_key > key)
{
return _InsertR(root->_left, key);
}
else
{
return false;
}
}
?这里的递归也是根据二叉搜索树左右两边孩子的特点巧妙使用引用来实现的,每次递归的参数为上一个根节点指向左孩子或者右孩子的引用,去掉了记录父亲节点。?
查找Find()
非递归版本
也是根据二叉搜索树左右孩子的特点实现的。如果查找的值比根结点的值大则和根节点的右孩子比较,反之;
注意:搜索二叉树中是没有两个相同的值的。
bool find(const K& key)
{
if (_root == nullptr)
{
return false;
}
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return true;
}
}
return false;
}递归版本
public :
bool FindR(const K & key)
{
return _FindR(_root, key);
}
private :
?
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
{
return false;
}
if (root->_key < key)
{
return _FindR(_root->_right, key);
}
else if (root->_key > key)
{
return _FindR(root->_left, key);
}
else
{
return true;
}
}
?删除()
非递归版本
删除这里的情况还比较复杂,先要根据上面查找函数的思路找到结点;
- 如果左孩子为空,且该结点为父节点的左孩子,则让父节点指向的左孩子为该节点的右支;删掉此节点。如果该结点为父节点的右孩子,则让父节点指向的右孩子为该节点右支;删掉此节点。
- 如果右孩子为空,且该节点为父节点的左孩子,则让父节点指向的左孩子为该节点的右支;删掉此节点。如果该节点为父节点的右孩子,则让父节点指向的左孩子为该节点的左支;删掉此节点。
- 如果左右孩子都不为空,则要取左支最大的(最右结点)或者取右支最小的(最左结点),这里实现的是取右支最小的;先进入该结点的右边,然后使用循环找到最左结点;对该节点和其父节点的值进行交换,然后按照上面左孩子为空调整其父节点指向的孩子结点。然后删除结点。
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
//左为空
if (cur->_left == nullptr)
{
//删除根节点的值
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else if (parent->_right == cur)
{
parent->_right = cur->_right;
}
}
delete cur;
}
//右为空
else if (cur->_right == nullptr)
{
//删除根节点的值
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else if (parent->_right == cur)
{
parent->_right = cur->_left;
}
}
delete cur;
}
else
{
//右树的最小值
Node* subleft = cur->_right;
Node* parent = cur;
while (subleft->_left)
{
parent = subleft;
subleft = subleft->_left;
}
swap(cur->_key, subleft->_key);
if (subleft == parent->_left)
{
parent->_left = subleft->_right;
}
else
{
parent->_right = subleft->_right;
}
delete subleft;
}
return true;
}
}
return false;
}递归版本
public:
bool EraseR(const K&key)
{
return _EraseR(_root, key);
}
private:
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
{
return false;
}
if (root->_key < key)
{
return _EraseR(root->_right, key);
}
else if (root->_key > key)
{
return _EraseR(root->_left, key);
}
else
{
if (root->_left == nullptr)
{
Node* del = root;
root = root->_right;
delete del;
return true;
}
else if (root->_right == nullptr)
{
Node* del = root;
root = root->_left;
delete del;
return true;
}
else
{
Node* subleft = root->_right;
while (subleft->_left)
{
subleft = subleft->_left;
}
swap(root->_key, subleft->_key);
return _EraseR(root->_right, key);
}
}
}?中序遍历
public:
void Inorder()
{
_Inorder(_root);
cout << endl;
}
private:
?
void _Inorder(Node* root)
{
if (root == nullptr)
{
return;
}
_Inorder(root->_left);
cout << root->_key << " ";
_Inorder(root->_right);
}
?二叉搜索树的应用
1. K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如给一个单词word,判断该单词是否拼写正确,具体方式如下:
- 以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
- 在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
2. KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:
- 比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;
- 再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。?
二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二
叉搜索树的深度的函数,即结点越深,则比较次数越多。但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:?
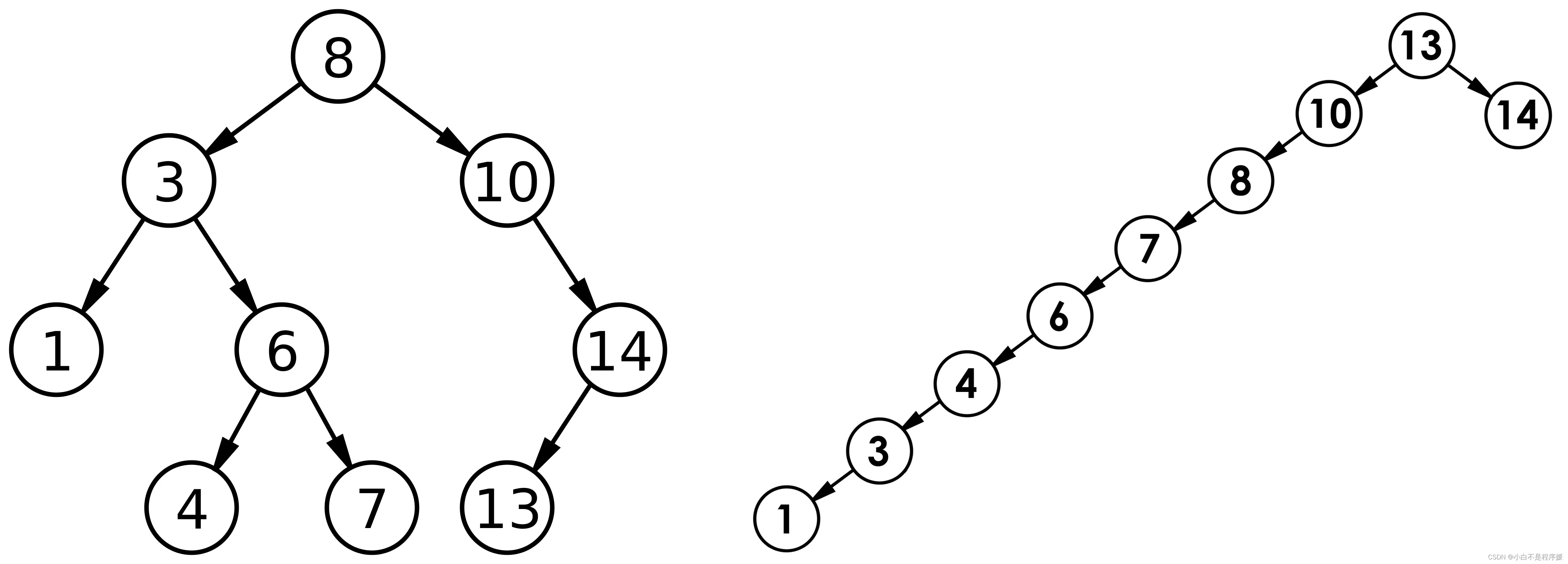
- 最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:O(logN)
- 最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:O(N);如果退化成了单支树,那么二叉搜索树的性能就失去了。此时就需要用到即将登场的 AVL 树和红黑树了。
今天对二叉搜索树的介绍、使用、模拟实现的分享到这就结束了,希望大家读完后有很大的收获,也可以在评论区点评文章中的内容和分享自己的看法。您三连的支持就是我前进的动力,感谢大家的支持!!?!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!