【Python特征工程系列】利用梯度提升(GradientBoosting)模型分析特征重要性(源码)
一、引言
应用背景介绍:??????
????? ?如果有一个包含数十个甚至数百个特征的数据集,每个特征都可能对你的机器学习模型的性能有所贡献。但是并不是所有的特征都是一样的。有些可能是冗余的或不相关的,这会增加建模的复杂性并可能导致过拟合。特征重要性分析可以识别并关注最具信息量的特征,从而带来以下几个优势:
- 改进的模型性
- 能减少过度拟合
- 更快的训练和推理
- 增强的可解释性
前期相关回顾:
【Python特征工程系列】8步教你用决策树模型分析特征重要性(源码)
【Python特征工程系列】利用随机森林模型分析特征重要性(源码)
本期相关知识:
????? ?梯度提升模型是一种集成学习方法,通过迭代地训练多个弱学习器(通常是决策树),并将它们组合成一个强学习器。梯度提升(Gradient Boosting)模型可以通过分析特征重要性来帮助我们理解数据中各个特征的相对重要程度。在Scikit-learn库中,模型提供了一个属性feature_importances_,用于获取特征的重要性分数。通过分析特征重要性,我们可以了解哪些特征对于模型的预测结果有更大的影响。重要性分数越高的特征,对模型的预测结果影响越大。这样的分析可以帮助我们进行特征选择、特征工程和模型优化等任务。需要注意的是,特征重要性分数的解释和计算方式可能会因模型和数据的不同而有所差异。因此,在实际应用中,应该根据具体的情况和需求来解释和使用特征重要性分数。
二、具体实现过程
导入第三方库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
import matplotlib.pyplot as plt
import seaborn as sns2.1 准备数据
data = pd.read_csv(r'dataset.csv')
df = pd.DataFrame(data)
2.2 目标变量和特征变量
target = 'target'
features = df.columns.drop(target)?特征变量如下:

2.3 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)?X_train如下:

2.4 训练梯度提升模型
model = GradientBoostingRegressor(n_estimators=100, max_depth=10)
model.fit(X_train, y_train)2.5 提取特征重要性
feature_importance = model.feature_importances_
feature_names = features?feature_importance如下:

2.6 创建特征重要性的dataframe
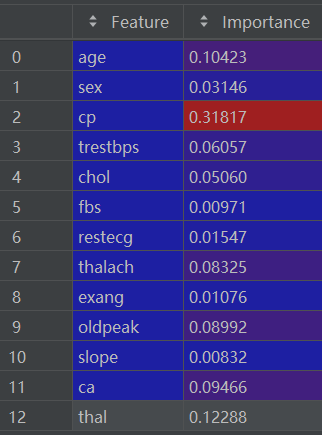
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importance})?importance_df如下:
2.7 对特征重要性进行排序
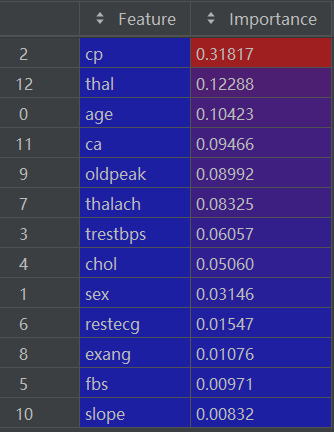
importance_df = importance_df.sort_values(by='Importance', ascending=False)排序后的 importance_df如下:
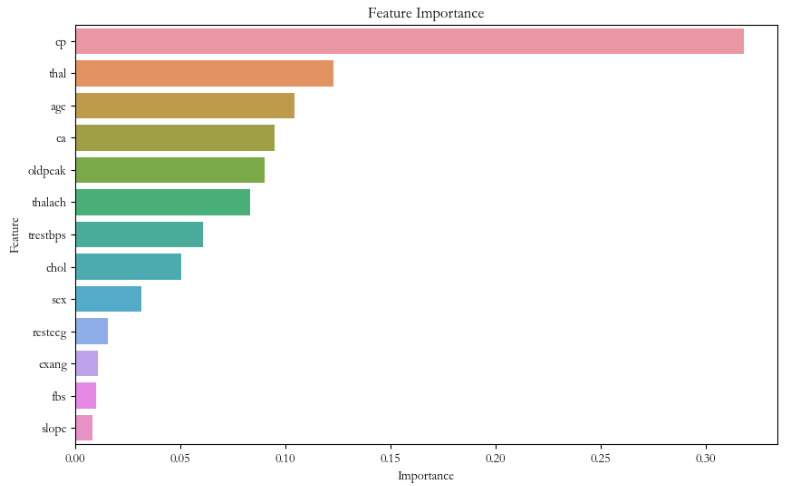
2.8 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()?可视化结果如下:
本期内容就到这里,我们下期再见!需要数据集和源码的小伙伴可以关注私信作者或者底部公众号添加作者微信!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Edge 浏览器出现“你的连接不是专用连接”提示,怎么办?
- vue跑马灯
- 2 快速前端开发
- 民用激光雷达行业简析
- Java参数校验详解:使用@Valid注解和自定义注解进行参数验证
- map, set, unordered_map,unordered_set的用法和区别
- SCT2A23STER:4.5V-100V Vin, 1.2A, DCDC降压转换器
- 基于Spring Cloud + Spring Boot的企业电子招标采购系统源码
- Nat Med | Tau靶向反义寡核苷酸
- nrm的保姆级使用教程