目标检测 | YOLOv5 训练自标注数据集实现迁移学习
Hi,大家好,我是源于花海。本文主要了解?YOLOv5 训练自标注数据集(自行车和摩托车两种图像)进行目标检测,实现迁移学习。YOLOv5 是一个非常流行的图像识别框架,这里介绍一下使用 YOLOv5 给使用 Labelme 标注自己的数据集进行训练和测试。
目录
一、YOLOv5 核心基础知识
可以参考大白的?深入浅出Yolo系列之Yolov5核心基础知识完整讲解-CSDN博客?这一文章进去详细学习 YOLOv5 相关知识,当然也包含 YOLO 的其他系列的知识。
1. YOLOv5?四种网络模型
- YOLOv5s
- YOLOv5m
- YOLOv5l
- YOLOv5x
YOLOv5?的四个 pt 格式的权重模型:

?YOLOv5?作者的算法性能测试图:
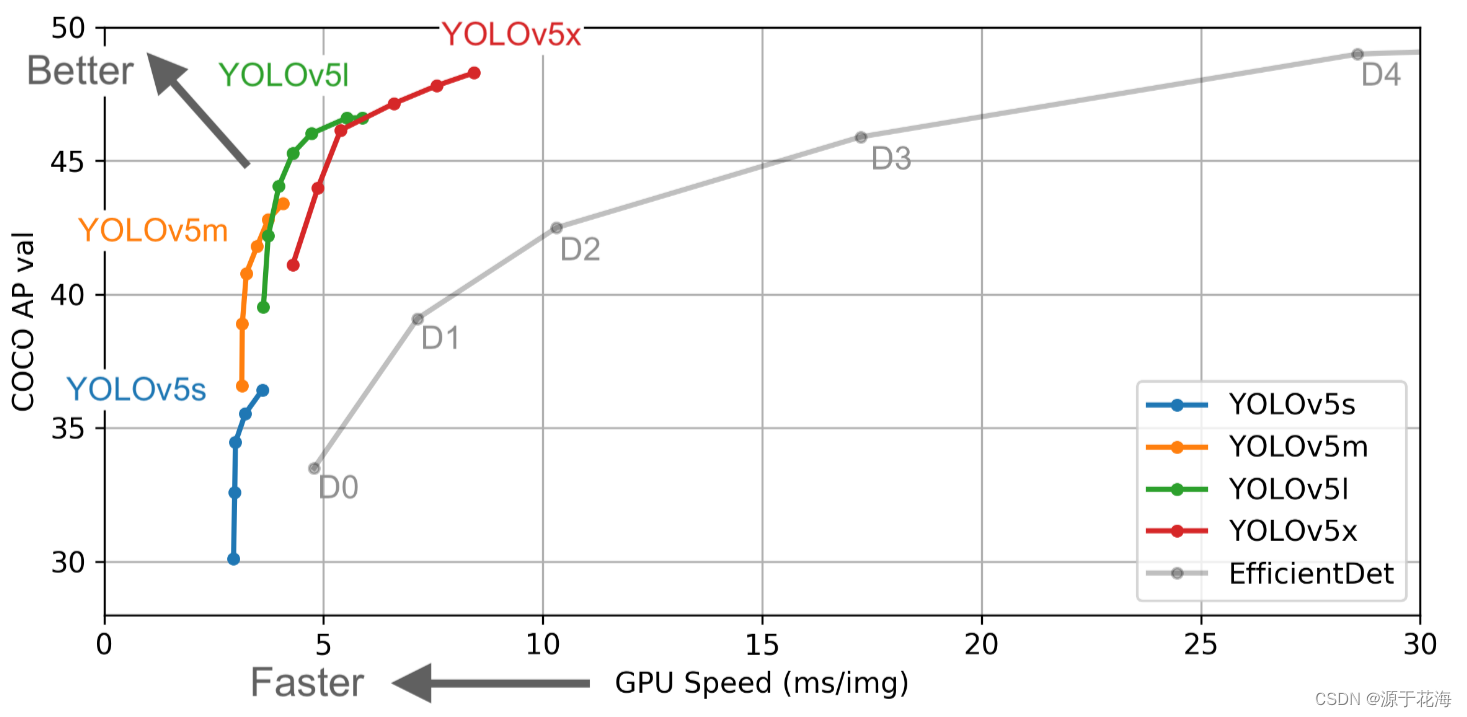
Yolov5作者也是在COCO数据集上进行的测试(COCO数据集的小目标占比)。
YOLOv5s 网络是?YOLOv5?系列中深度最小,特征图的宽度最小的网络(网络最小,速度最少,AP精度也最低)。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。
后面的三种都是在此基础上不断加深、加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
2. 核心基础内容
YOLOv5?网络结构图:
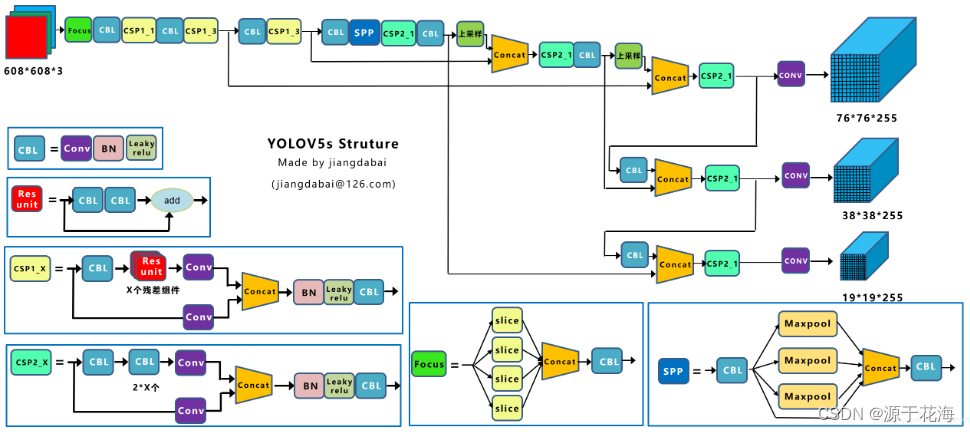
?我们可以采用?pt->onnx->netron?的折中方式,先使用?YOLOv5?代码中?models/export.py?脚本将?pt文件?转换为?onnx格式,再用?netron工具?打开,这样就可以看全网络的整体架构了。
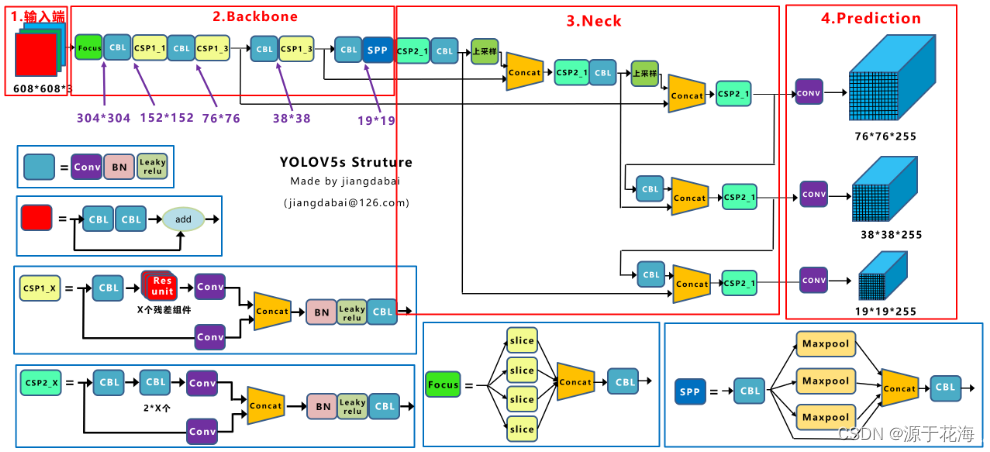
?上图即?YOLOv5?的网络结构图,可以看出,还是分为输入端、Backbone、Neck、Prediction四个部分。
- 输入端:?Mosaic 数据增强、自适应锚框计算
- Backbone:?Focus 结构,CSP 结构
- Neck:?FPN + PAN 结构
- Prediction:?GIOU_Loss
二、YOLOv5 迁移学习过程
1. YOLOv5 框架的下载及结构介绍
官方介绍文档:?YOLOv5官方文档?或者?YOLOv5-master?。
在 pycharm 里面大致是这样的结构:
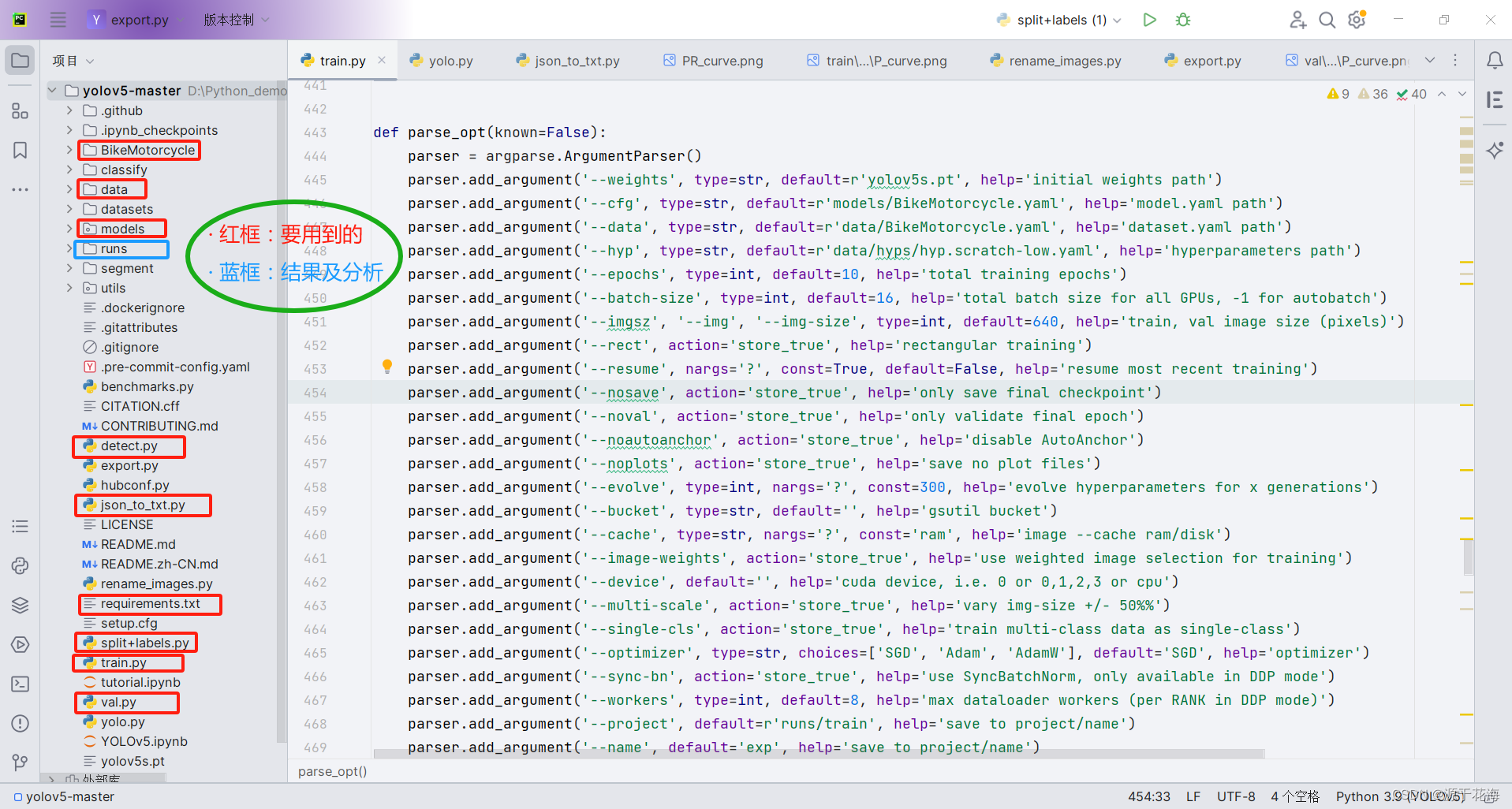
现在来对代码的整体目录做一个介绍:
- data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的 yaml 文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到 YOLOv5 项目的同级目录下面。
- models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的 yaml 文件来训练自己模型。
- utils:存放的是工具类的函数,里面有 loss 函数,metrics 函数,plots 函数等等。
- weights:放置训练好的权重参数。
- train.py:训练自己的数据集的函数。
- test.py:测试训练的结果的函数。
- detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
- requirements.txt:这是一个文本文件,里面是使用 YOLOv5 项目的环境依赖包的一些版本,可以用该文本导入相应版本的包。
以上是 YOLOv5 项目代码的整体介绍。我们训练、验证、测试自己的数据集基本就是利用到如上代码。
2. 创建 YOLOv5 虚拟环境
这边建议使用 conda 创建一个新的虚拟环境。
(1)创建虚拟环境
conda create -n YOLOv5 python=3.9(2)激活并进入虚拟环境
activate YOLOv5(3)安装各软件包
?比如使用清华镜像源安装库:
pip install torch==2.1.1?-i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torchvision==0.16.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
······打开 requirements.txt 文件,里面写有 YOLOv5 运行所需要的各种软件包,输入以下命令到 pycharm 里的终端中运行即可:(我不太记得了,感觉是在 Command Prompt 里面运行的,但是 Windows PowerShell 也可以)
pip install -r requirements.txt
这个过程可快可慢,看网速,静静地等待吧。有几个包的安装可能会出问题,没关系,把报错信息在?CSDN / ChatGPT?上搜一搜都能找到解决办法!
(4)添加此虚拟环境到该项目中
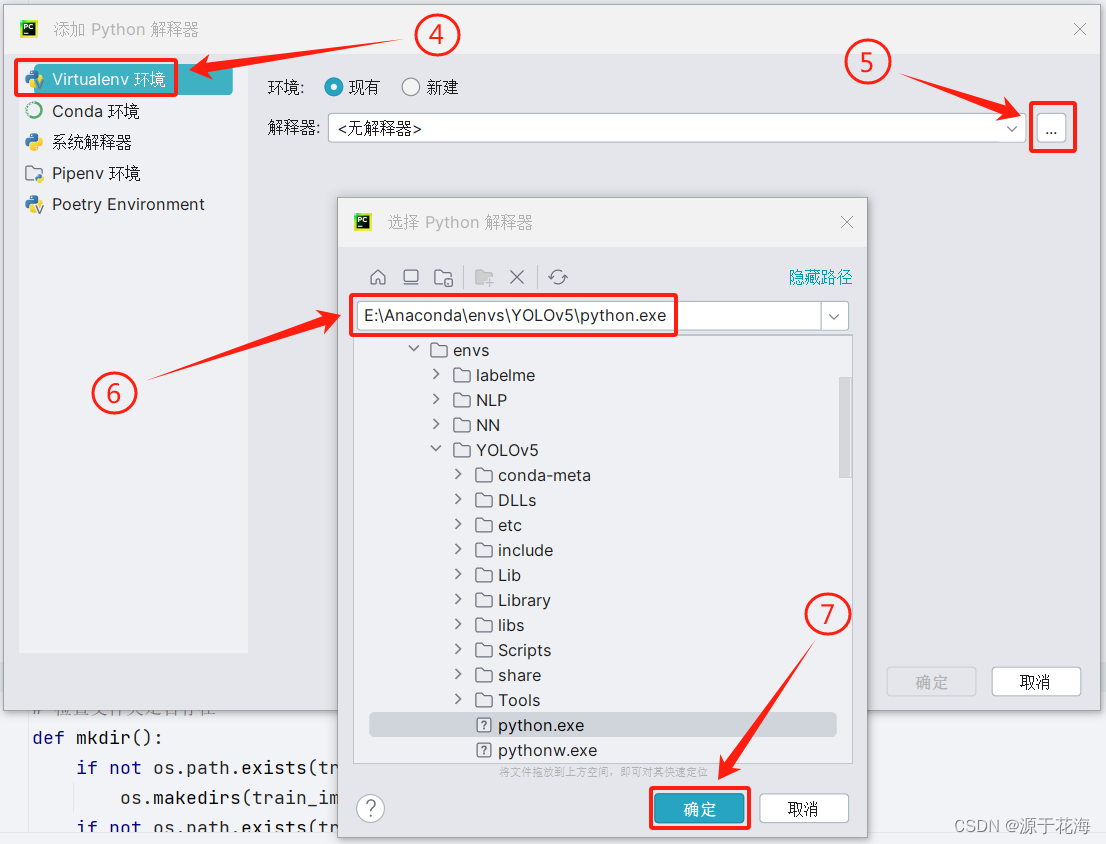
3. 数据集准备
数据集格式:
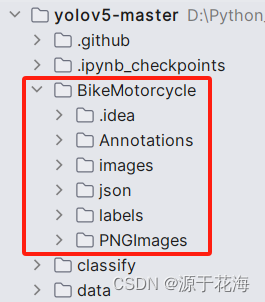
数据集文件夹的树形结构:
├──?BikeMotorcycle? ? ? ? 数据集文件夹
????????├── PNGImages? ? ?所有图像(两种放一起,命名为(名称+)编号)
? ? ? ? ├──?json? ? ? ? ? ? ? ? ? 所有图像对应的 json 文件(同上)
? ? ? ? ├──?Annotations? ? ? 由 json 文件转换的 txt 文件(同上)
? ? ? ? ├──?images? ? ? ? ? ? ?分割后的数据集(子文件夹里两种放一起,命名同上)
????????????????├── train? ? ? ? ? 训练集
????????????????├──?val? ?? ?? ? ? 验证集
????????????????├── test? ? ? ? ? ?测试集
? ? ? ? ├──?labels? ? ? ? ? ? ? ?分割后的数据集对应的 txt 标签文件(同上)
????????????????├── train? ? ? ? ? 训练集
????????????????├──?val? ?? ?? ? ? 验证集
????????????????├── test? ? ? ? ? ?测试集
3.1 数据集下载
本项目数据集是在以下链接中的图像分类里面的?VOC2005 车辆数据集(The PASCAL Visual Object Classes Challenge)中选取自行车和摩托车而得:图像处理及深度学习开源数据集大全(四万字呕心沥血整理)-CSDN博客?。
3.2?Labelme 数据标注
① Open Dir(选择并打开数据集图像的文件夹路径)
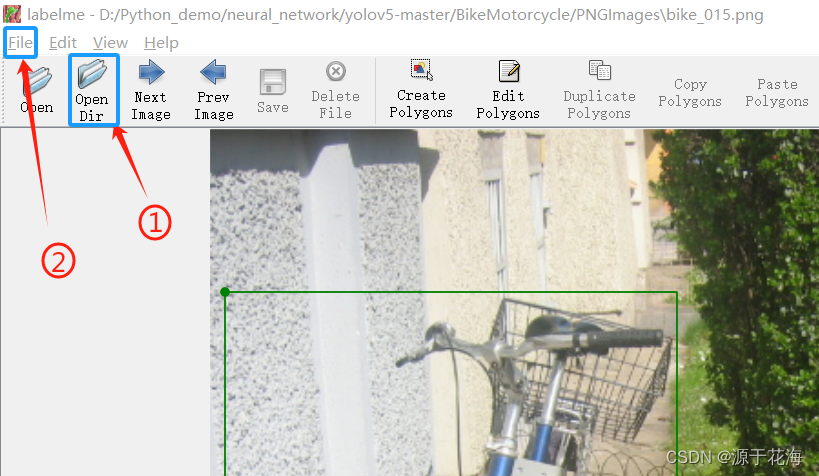
②③④ File —> Save Automatically —> Change Output Dir
- Save Automatically:自动保存,减少麻烦
- Change Output Dir:改变 json 文件输出路径
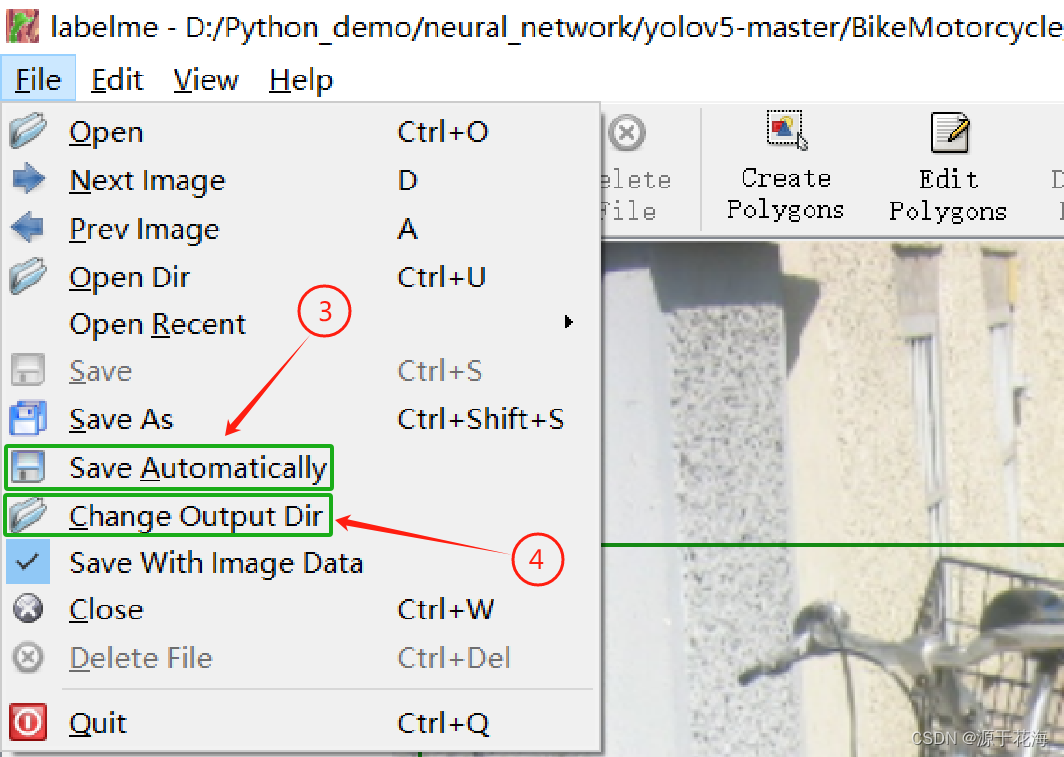
⑤ Create Rectangle(快捷键:Ctrl+R)(画矩形边界框)
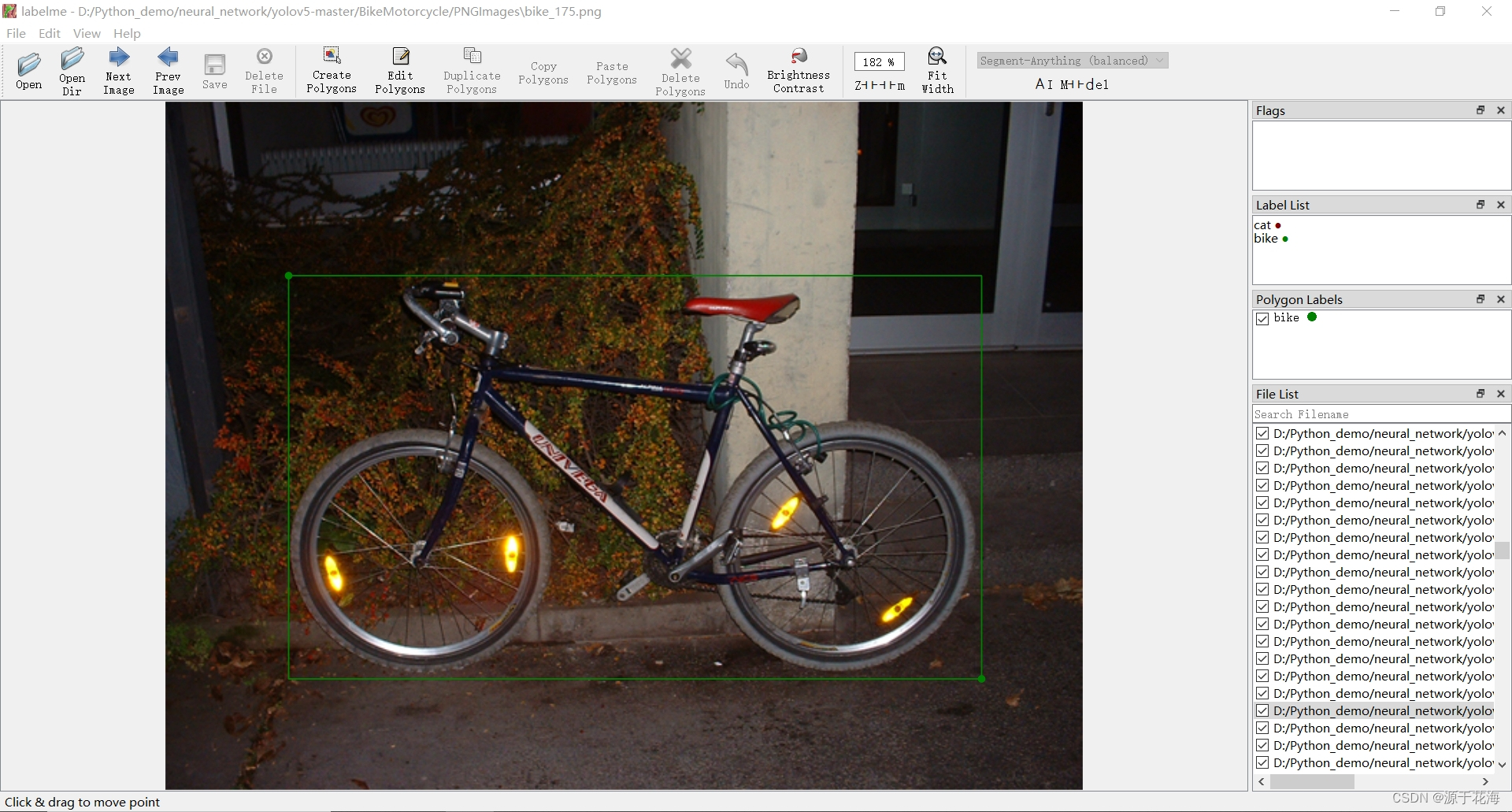
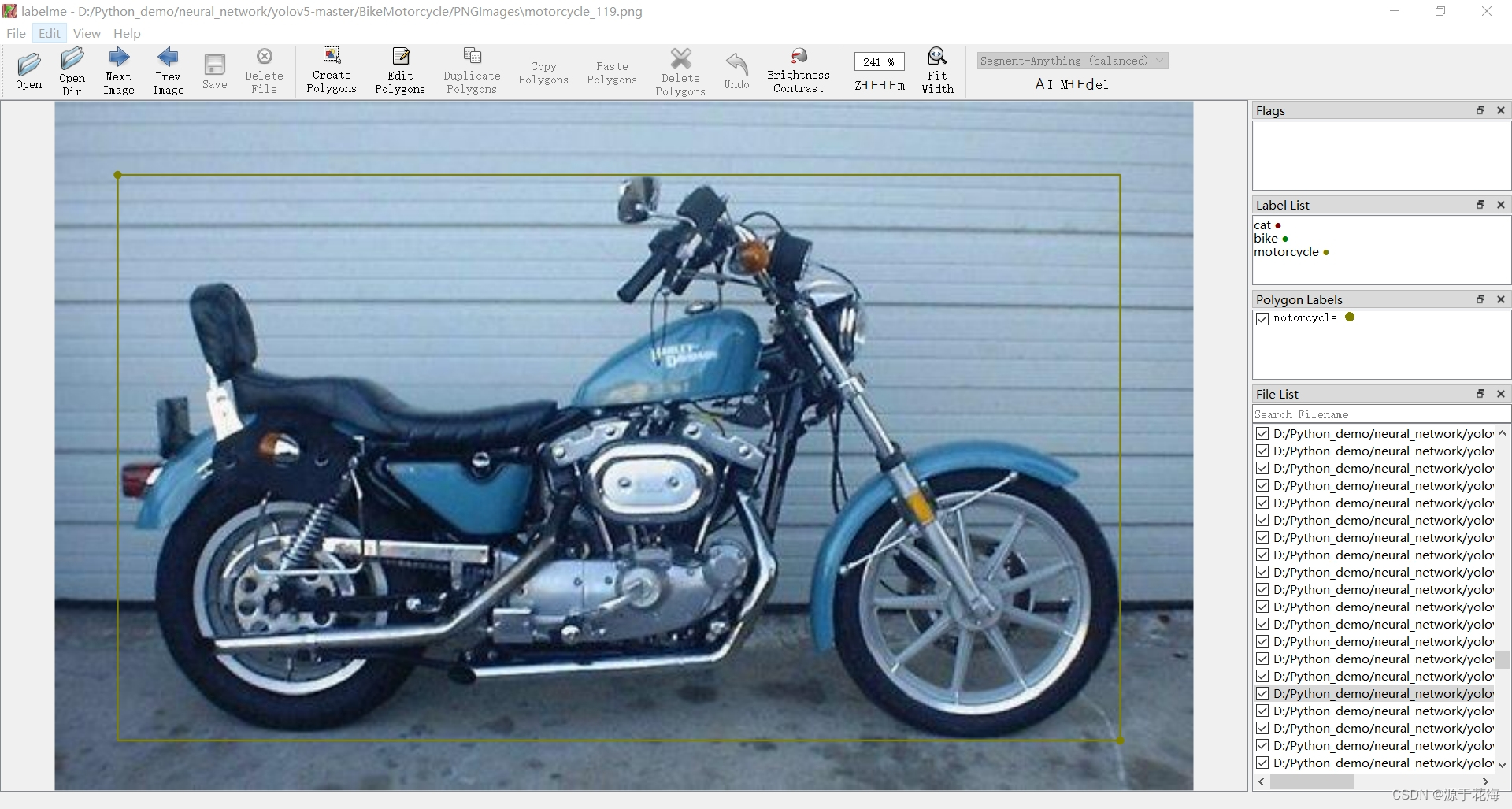
3.3?json 转 txt
json_to_txt.py?代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : yolov5-master
@File : json_to_txt.py
@IDE : PyCharm
@Author : 源于花海
@Date : 2023/12/10 19:43
"""
import json
import os
name2id = {'bike': 0, 'motorcycle': 1} # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def decode_json(json_floder_path, json_name):
txt_name = 'D:\\Python_demo\\neural_network\\yolov5-master\\BikeMotorcycle\\Annotations\\' + json_name[0:-5] + '.txt'
# 存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if i['shape_type'] == 'rectangle':
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'D:\\Python_demo\\neural_network\\yolov5-master\\BikeMotorcycle\\json'
# 存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)3.4 数据集分割及其对应标签生成
split+labels.py 代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : yolov5-master
@File : split+labels.py
@IDE : PyCharm
@Author : 源于花海
@Date : 2023/12/10 19:29
"""
import shutil
import random
import os
# 将图片和标注数据按比例切分为训练集、验证集和测试集
# 数据集路径
image_original_path = './BikeMotorcycle/PNGImages/'
label_original_path = './BikeMotorcycle/Annotations/'
# 训练集路径
train_image_path = './BikeMotorcycle/images/train/'
train_label_path = './BikeMotorcycle/labels/train/'
# 验证集路径
val_image_path = './BikeMotorcycle/images/val/'
val_label_path = './BikeMotorcycle/labels/val/'
# 测试集路径
test_image_path = './BikeMotorcycle/images/test/'
test_label_path = './BikeMotorcycle/labels/test/'
# 数据集划分比例,训练集75%,验证集15%,测试集10%,按需修改
train_percent = 0.75
val_percent = 0.15
test_percent = 0.1
# 检查文件夹是否存在
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
def main():
mkdir()
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.png'
srcLabel = label_original_path + name + '.txt'
if i in train:
dst_train_Image = train_image_path + name + '.png'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = val_image_path + name + '.png'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = test_image_path + name + '.png'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
main()
4. 模型配置
模型配置其实就是一些预训练权重的准备,在?YOLOv5 中,主要是 .yaml 配置文件及一些 .py 文件的参数或路径修改。
4.1 修改数据集配置文件
在 data 目录下复制 VOC.yaml,并粘贴重命名为 BikeMotorcycle.yaml,打开进行修改。
- path:项目当前的路径
- train、val、test:对应的训练集、验证集、测试集的路径
- nc:类别数
- names:类别名
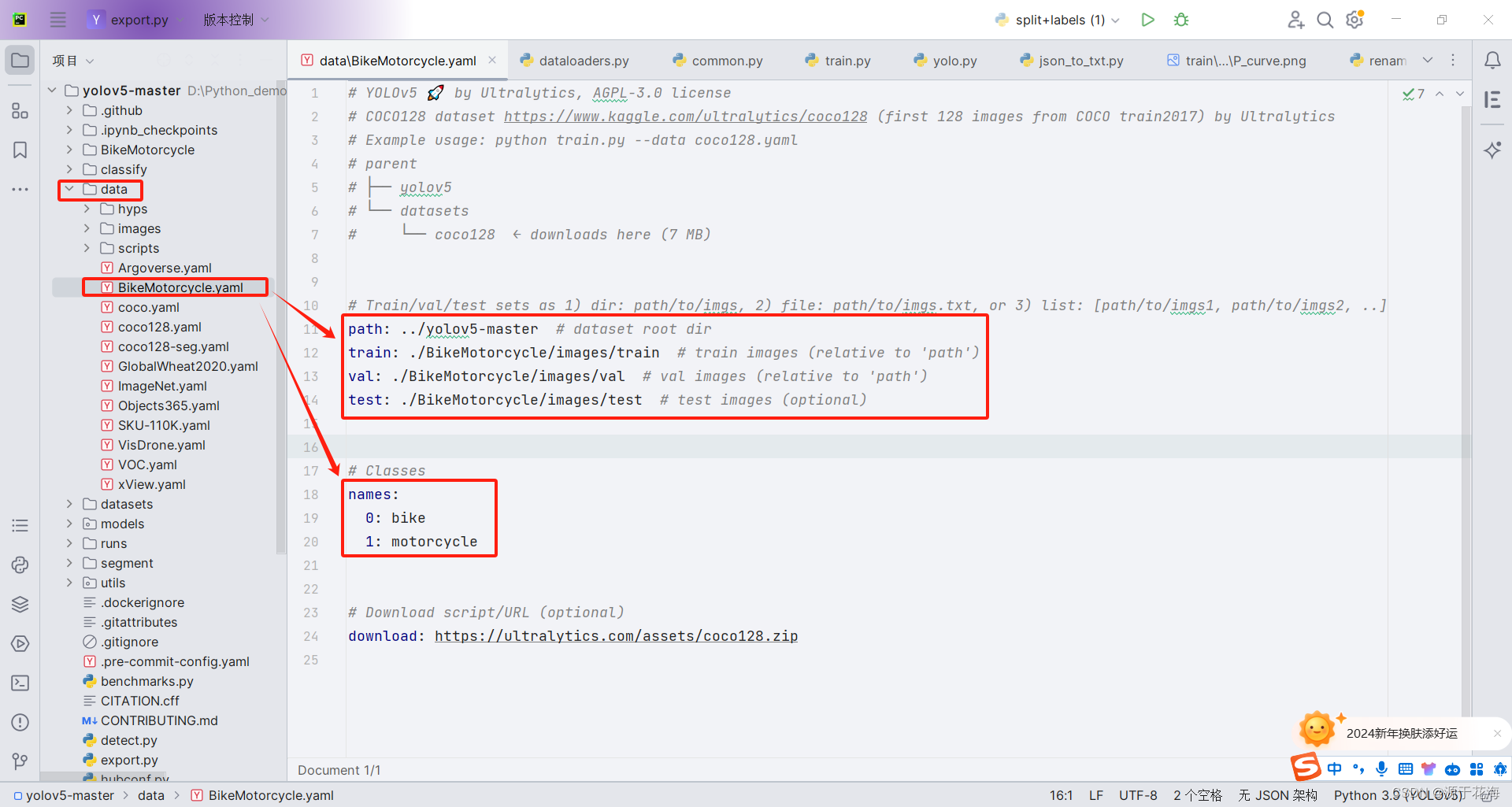
4.2 修改模型配置文件
在 models 目录下找到 yolov5s.yaml,将其复制一份,并重命名为 BikeMotorcycle.yaml,然后打开它,把 nc 改成数据集类别数。
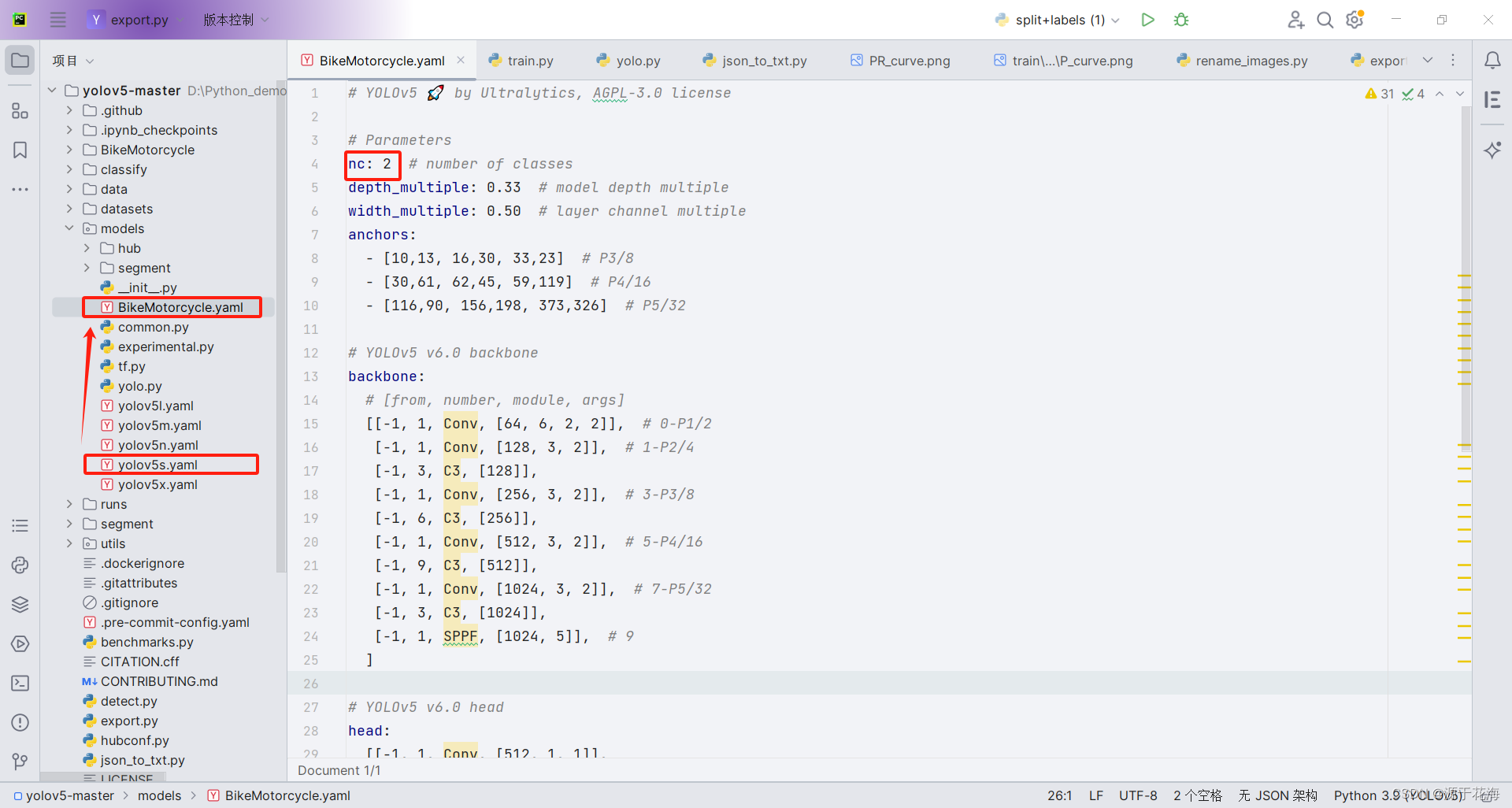
4.3 其他修改
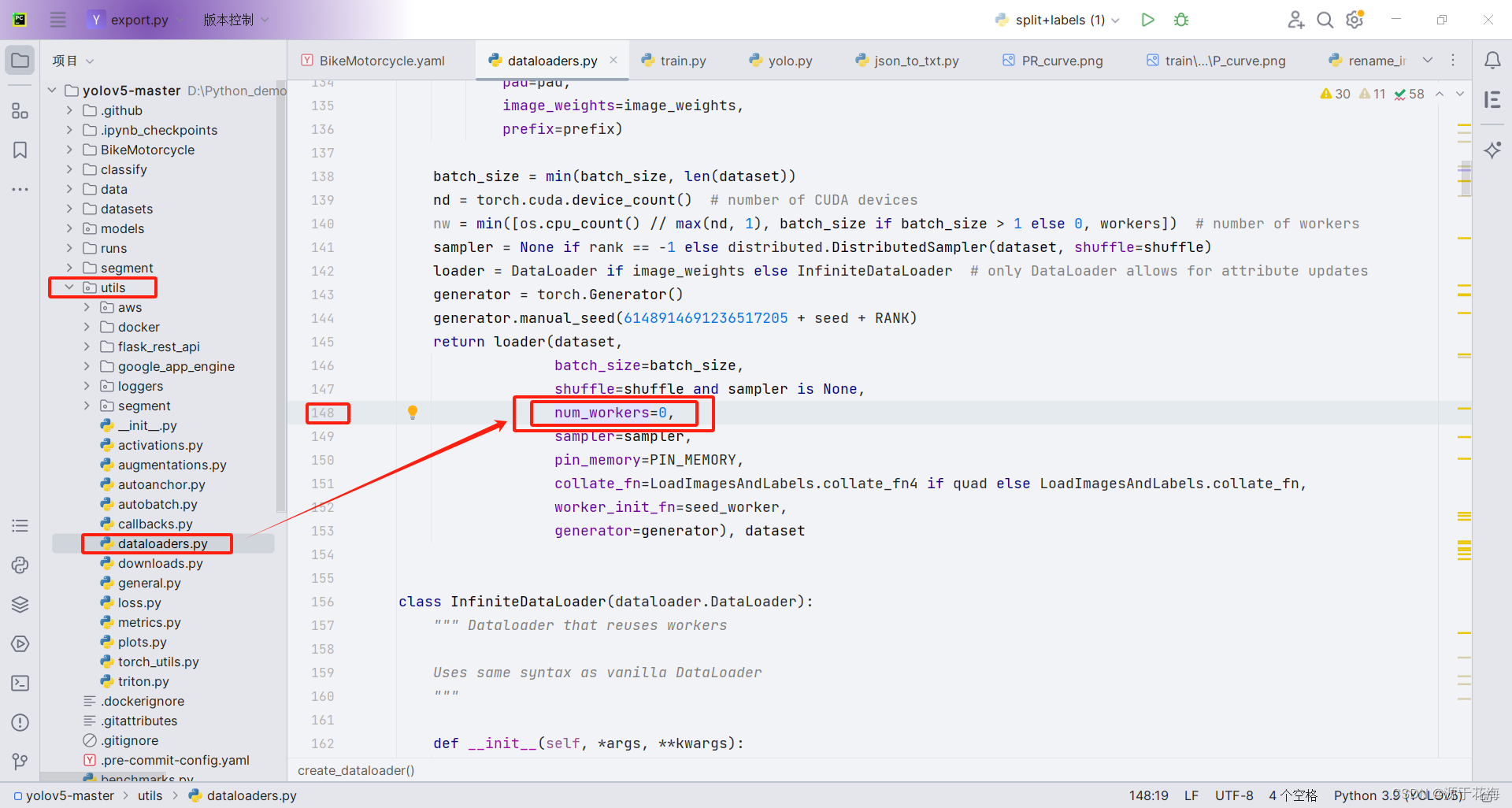

5. 模型训练
- ① weights: r'yolov5s.pt'
- ② cfg: r'models/BikeMotorcycle.yaml''
- ③ data: r'data/BikeMotorcycle.yaml'
- ④ epochs:?训练次数:10
- ⑤ batch-size:?训练的批次:16
修改 train.py 文件上面的信息之后运行,开始训练:
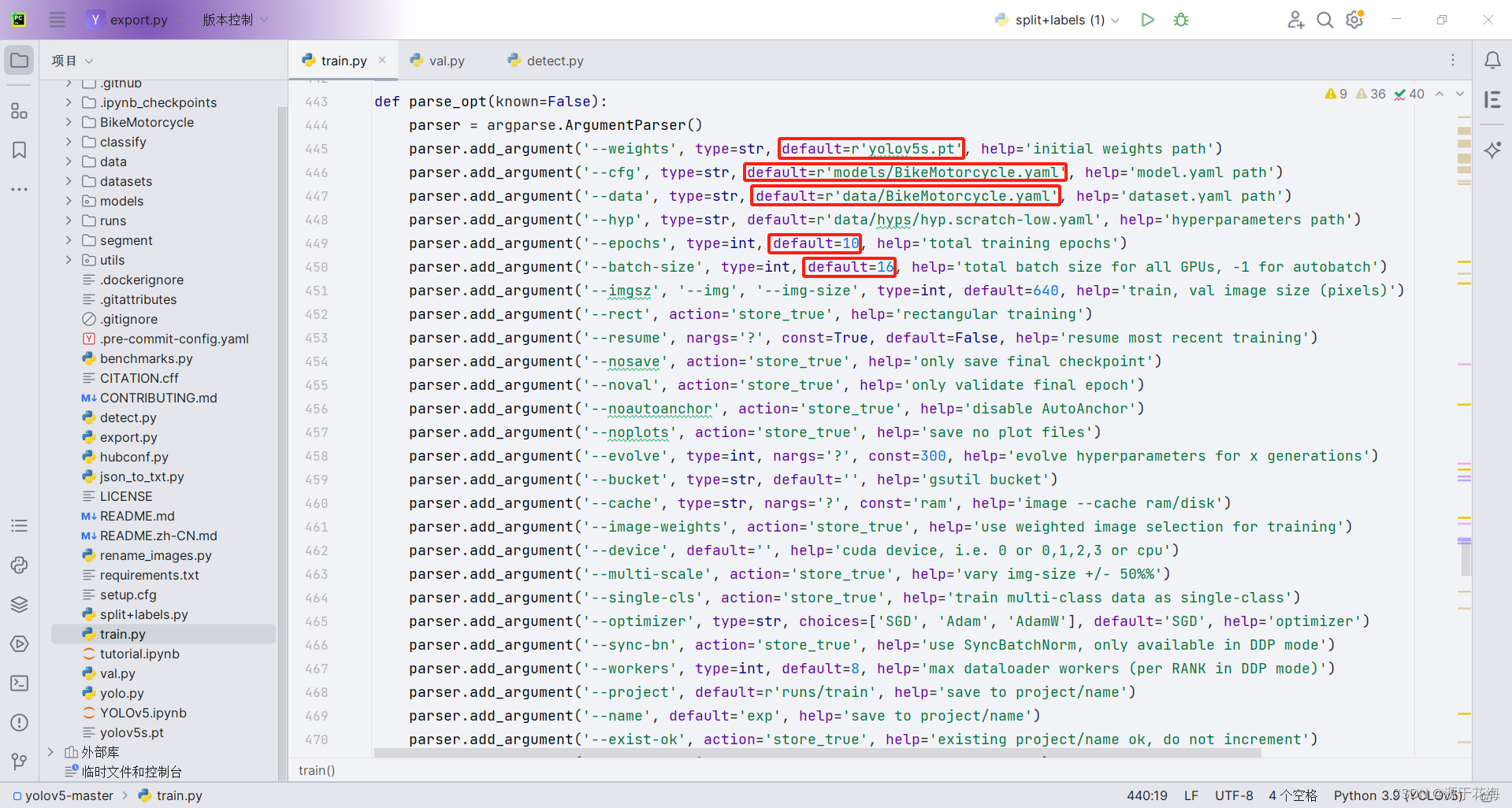
训练结果对应 runs\train\exp 文件夹下:
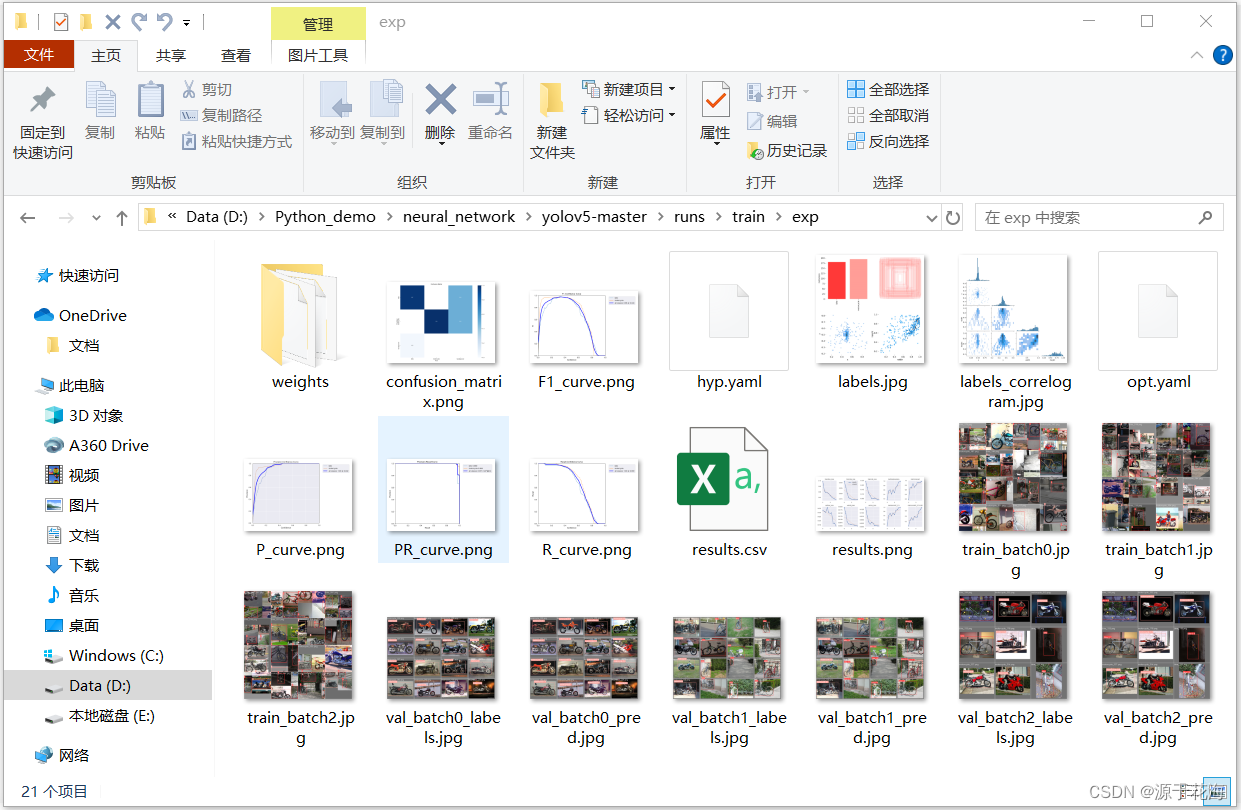
result.png 结果如下:
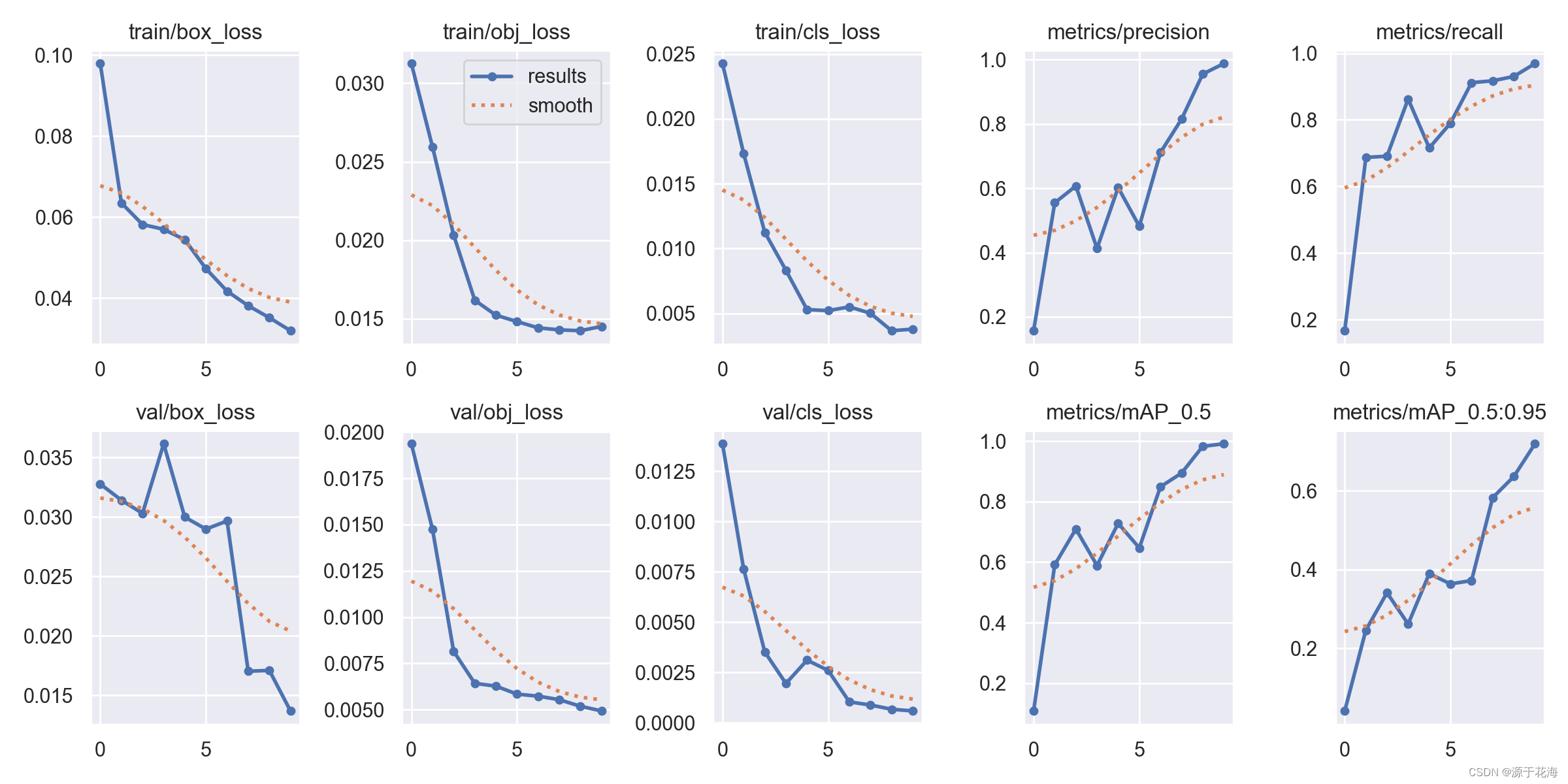
由上图可以看出,本项目 YOLOv5 训练效果很好,准确率为 99.1%?。
6. 模型验证
评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估,在目标检测中最常使用的评估指标为 mAP。
- ① weights: 训练好的模型的权重 r'runs\train\exp30\weights\best.pt'
- ② data: r'data/animal_detection.yaml'
在 val.py 文件中指定数据集配置文件和训练结果模型,运行进行测试某一张图片或某个文件夹里的图片,直接?"右键+运行",或者在终端输入以下命令:
python val.py --data data/BikeMotorcycle.yaml --weights runs\train\exp\weights\best.pt --augment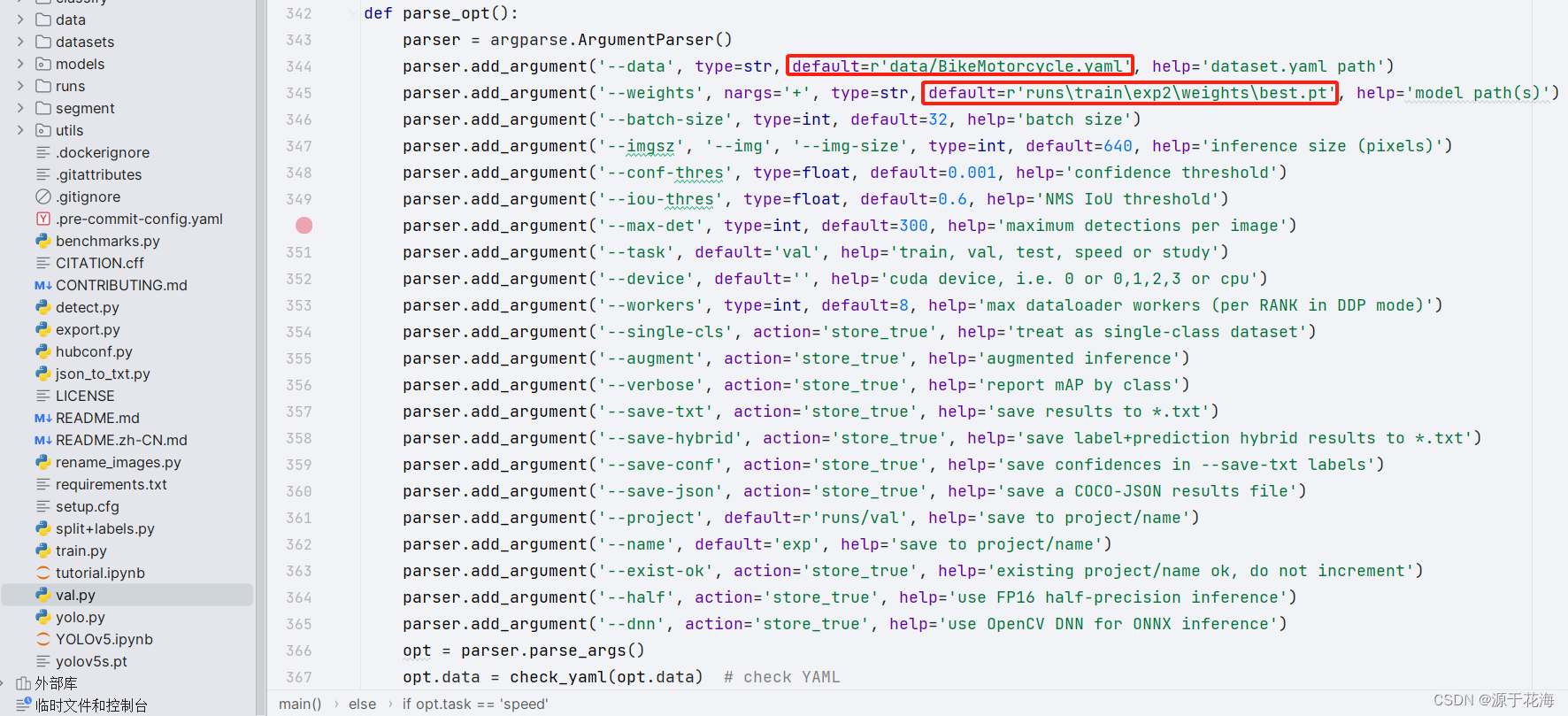
验证结果对应 runs\val\exp 文件夹下:
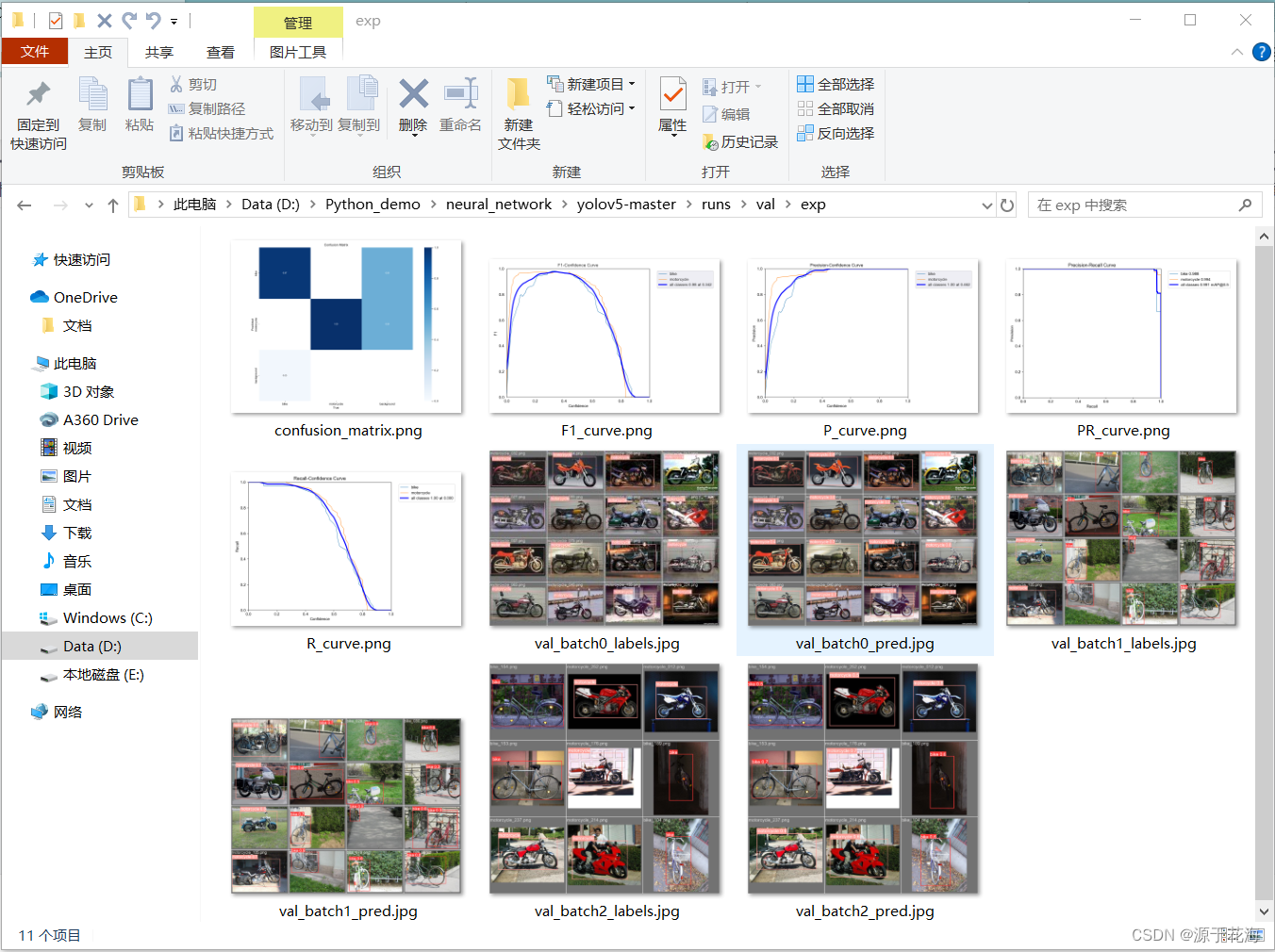
由上图可以看出,本项目 YOLOv5 验证效果很好,准确率同样接近 100% 。
7. 模型预测
模型推理和模型测试比较类似,主要区别是模型推理是对那些没有标注的数据集上进行推理,修改detect.py文件的要进行推理的图片和模型的路径:
- ① weights:?训练好的模型的权重 r'runs\train\exp\weights\best.pt'
- ② source:?r'BikeMotorcycle\images\test'
- ③ data:?r'data/BikeMotorcycle.yaml'
在?test.py 文件中指定数据集配置文件和训练结果模型,运行进行推理某一张图片或某个文件夹里的图片,直接?"右键+运行",或者在终端输入以下命令:
python detect.py --weights runs\train\exp\weights\best.pt --source BikeMotorcycle\images\test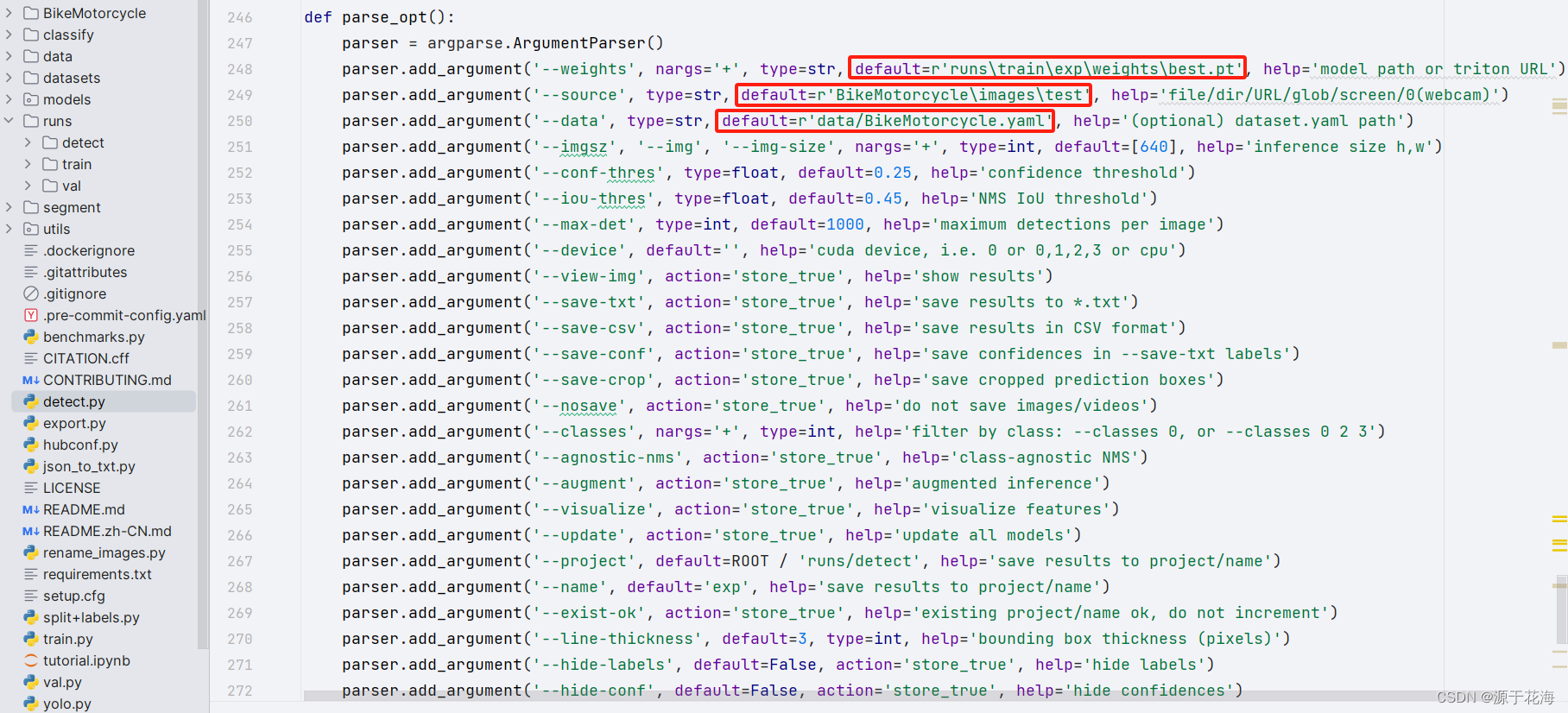
预测结果对应 runs\detect\exp 文件夹下:
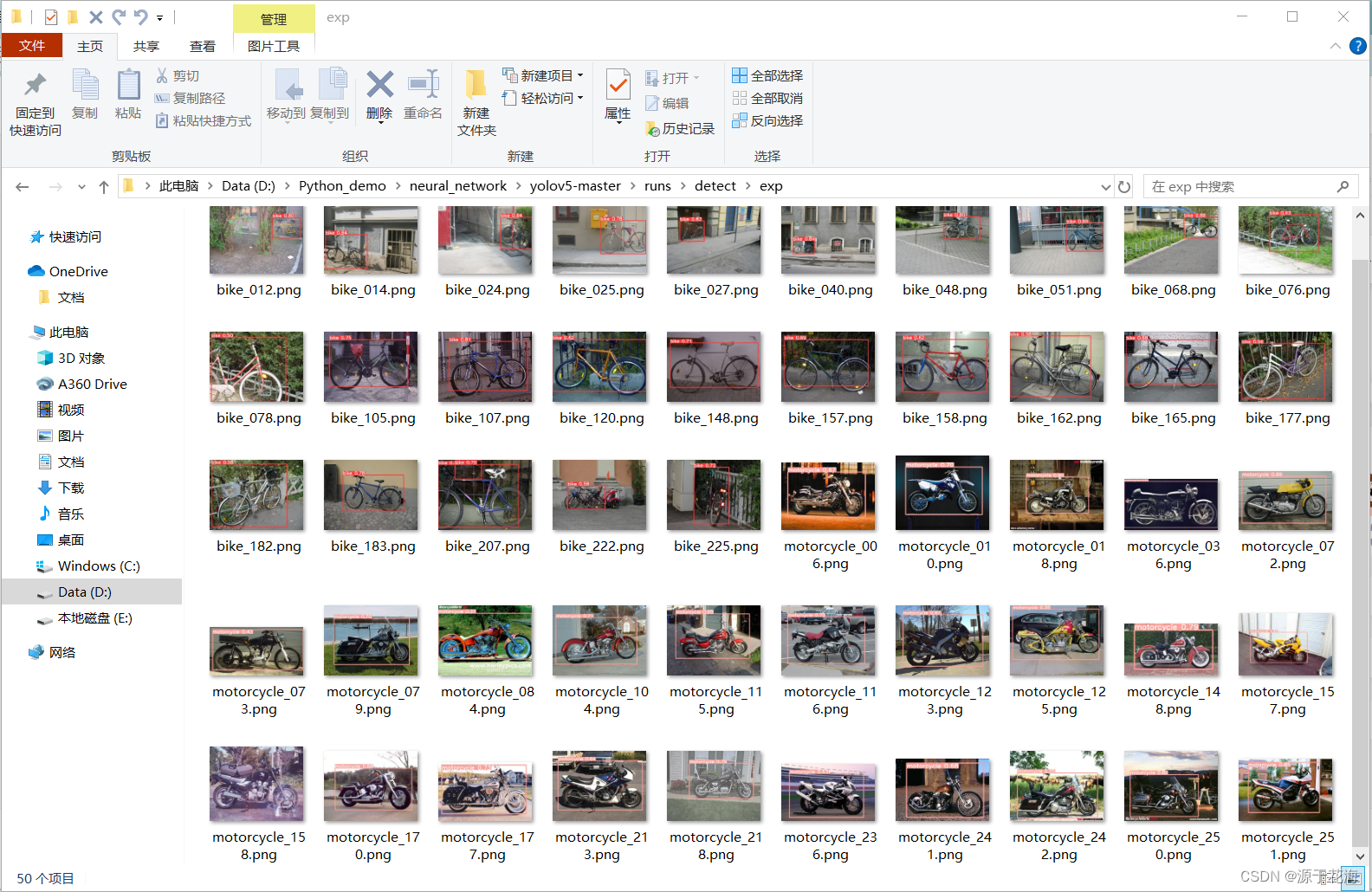
?由上图可以看出,本项目 YOLOv5 预测效果很好,检测类别的准确度达到?100% 。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!