强化学习与监督学习【区别】
强化学习很强大,但是有大多数场景毫无使用它的必要,监督学习就够了。下面分析强化学习和监督学习的区别和强化学习有前景的应用。
决策是否改变环境
监督学习假设模型的决策不会影响环境,而强化学习假设模型的决策会改变环境。 比如,
玩游戏时,我们的每个操作都会改变游戏的状态;
机器人/自动驾驶汽车在运动时,会改变当前所处的环境;
大型投资机构的大笔交易会改变当前的股价;而小散户(韭菜)的交易几乎不会影响股市;
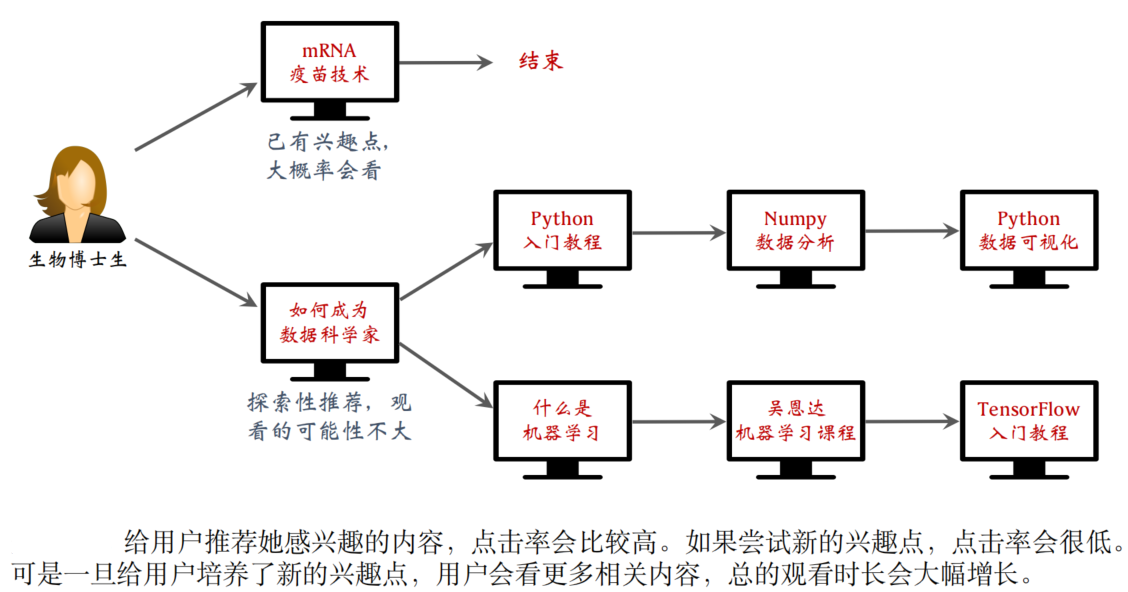
推荐系统每次推荐的内容(决策)会改变用户的兴趣点(环境);监督学习假设用户的兴趣点是固定的,推荐系统只会拟合用户的喜好,而强化学习则假设用户的兴趣点可以被改变,学出来的推荐策略会挖掘用户新的兴趣点。
(其中主要原因是强化学习允许探索,尝试历史数据中不存在的动作,而监督学习通常不做探索,只是拟合历史记录,无法挖掘用户新的兴趣点)
当前奖励还是长线回报
使用监督学习或是强化学习,还取决于目标是当前的奖励还是长线的回报。
人脸识别、邮件过滤这类问题就是 “一锤子买卖”,只需获得当前奖励即可,仅关注单次决策的结果,因此适用于监督学习。
象棋等游戏则应该考虑长线回报:吃掉对方一个马,虽然得到了眼前的利益,但是可能不利于赢得这局棋。强化学习涉及一系列决策(即策略),不仅关注单次决策的结果。
滴滴中为司机派发订单的应用中,就需要最大化长线回报(总收入),而不是眼前的奖励(单笔订单的收入)。比如,一方面,目的地有“冷”和“热”之分,会影响司机后续的等待时间和收入。另一方面,接单虽然能立刻赚到钱,但是会花费“机会成本”,如果稍等一下可能会接到更好的单。
总结
强化学习的目标:学习在给定环境中采取何种行动以最大化累积奖励或实现特定目标。
监督学习的目标:根据带有标签的训练数据学习映射函数,预测新数据的输出。
强化学习模型决策会改变环境,特别适合于那些涉及连续决策和追求长期回报的场景。
本文内容为看完王树森和张志华老师的《深度强化学习》一书的学习笔记,十分推荐大家去看原书!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java数据结构---链表的基本用法(如创建等基本使用方法)
- 第12章_集合框架(Collection接口,Iterator接口,List,Set,Map,Collections工具类)
- 基于微信支付的体育场馆预订小程序开发笔记一
- [C#]C# OpenVINO部署yolov8实例分割模型
- mysql从库重新搭建的流程
- python入门小程序-账单管理系统
- java体育馆数据管理系统(开题+源码)
- 外贸业务员该如何写好一份有质感的年终总结?内附外贸大神例文
- 1.单表查询
- Qlik Sense Services