忆阻器芯片STELLAR权重更新算法(清华大学吴华强课题组)
参考文献(清华大学吴华强课题组)
Zhang, Wenbin, et al. “Edge learning using a fully integrated neuro-inspired memristor chip.” Science 381.6663 (2023): 1205-1211.

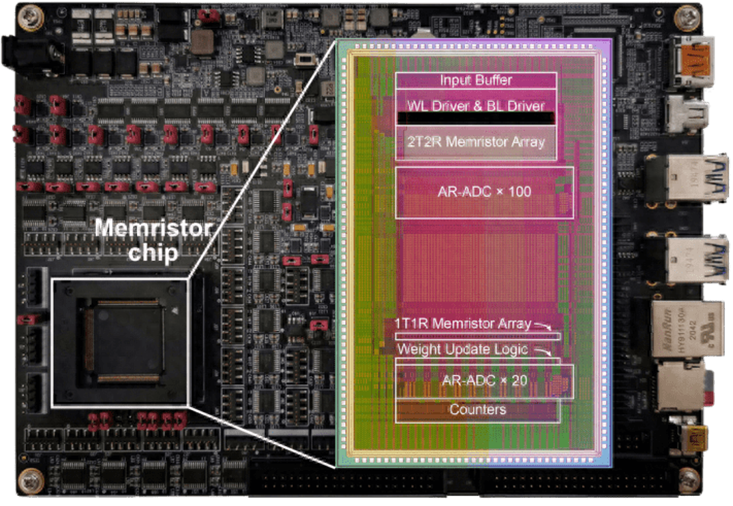
STELLAR更新算法原理
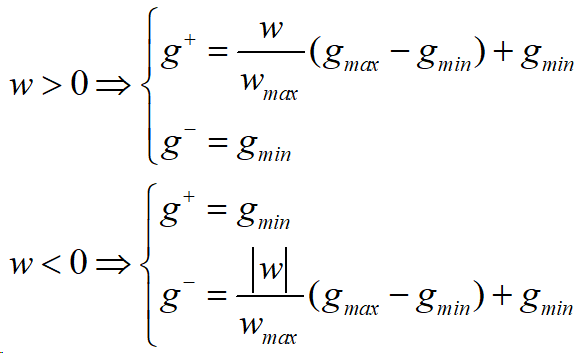
在权值更新阶段,只需根据输入、输出和误差的符号计算权值更新方向。此外,该算法预先定义了一个阈值,在计算误差符号时过滤掉小误差信号,并通过避免过于敏感和不必要的更新。省略掉小更新信号后,在STELLAR更新方案下基于忆阻器的梯度向量可以更接近地近似标准BP梯度向量。设定的阈值是硬件可重构的,以适应各种学习任务。STELLAR算法取决于权重更新的方向,将对应的相同SET和RESET脉冲施加到忆阻器单元。
前向传播(inference)

对每个输入向量执行权重更新。该学习算法以网络输出和目标的损失函数最小为目标,对电导进行最优更新。
反向传播——损失函数(平方损失函数)

反向传播——权重更新量(基于阈值性方向)
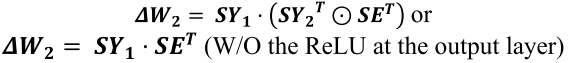
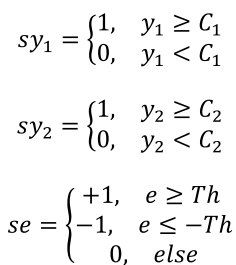
C
1
,
C
2
C_1,C_2
C1?,C2?可灵活配置。如果将ReLU激活函数应用于加权和输出向量
Z
\textbf{Z}
Z,则
C
1
C_1
C1?通常是第一层输出中的最大值乘以0.4,
C
2
C_2
C2?值通常设置为零。如果输出层省略了ReLU激活函数,则没有
C
2
C_2
C2?,且
C
1
C_1
C1?设置为零。
关于激活函数
在这项工作中,ReLU激活函数是在制造的芯片上进行实验证明的。当输出层神经元函数配置为sigmoid、tanh函数时,
s
y
2
sy_2
sy2?需要由神经元对应的导数函数量化,而不是直接用
y
2
y_2
y2?的值进行量化。
器件非对称切换下的STELLAR更新方案
实际的忆阻器器件存在非理想的调谐行为,例如更新曲线的非线性和不对称性,这阻碍了基于忆阻器的边缘学习应用的开发和探索。
STELLAR更新方法引入了一种基于阈值的三值化方案来计算输入和输出导数向量(derivative vectors),随后将其用于计算基于符号的权重梯度。这种STELLAR方案有利于简化梯度计算和权重更新的硬件设计,节省硬件成本,以实现用于边缘学习的完全集成的忆阻器芯片。
实验模拟结果和理论分析表明,STELLAR方案可以适应器件的非对称更新。
定制设计的电路能耗从忆阻器芯片中使用的电路和Cadence仿真器获得;
传统BP算法产生的功耗(Intel Xeon E5-2699处理器产生的功耗)估算方法为:计算操作数/能效(Jouppi et al.)
*整个训练过程中的电导调谐操作的总能量*消耗估算方法为:**调谐操作数每个操作的平均能量**。调谐操作数来自片上学习仿真。根据忆阻器芯片产生的测量结果估计write操作的平均能量,从8-bit分辨率的130 nm ADC获得read操作的能量
循环并联电导调谐方案(2T2R)
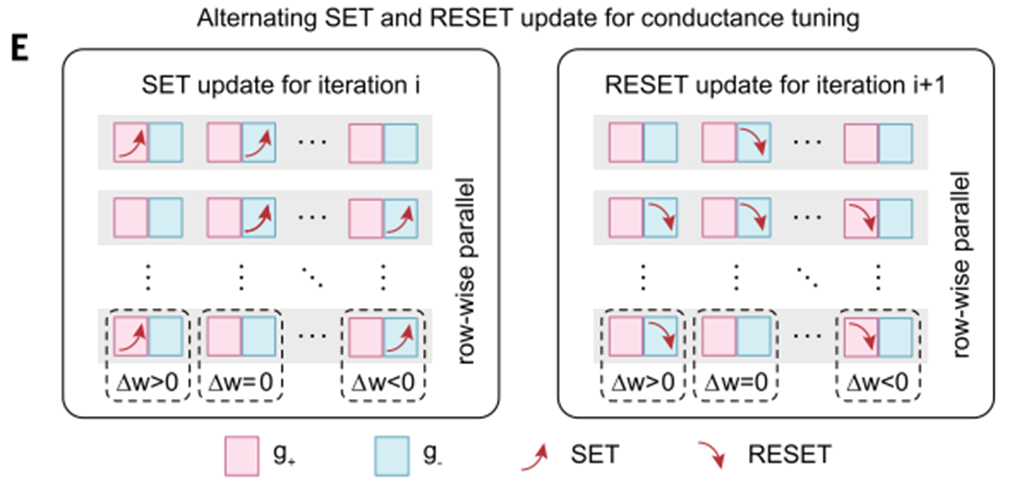
*比较编程脉冲数[周期并行STELLAR(stellar1)、非周期并行STELLAR(stellar2)、具有写入验证方案的常规BP(BP w/verify)]: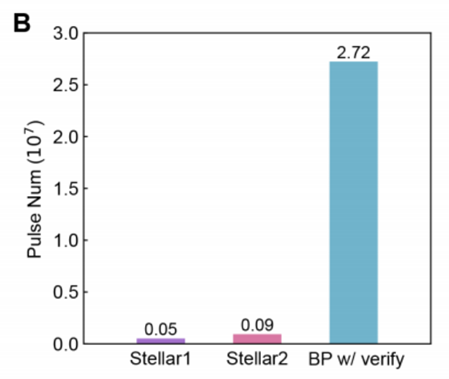
循环并行STELLAR方案可以在相同的训练时期内具有与BPw/verify一样快地收敛。但是STELLAR方案所需的脉冲数远低于后者。stellar1相比于stellar2只需要近一半的脉冲数
权重迁移算法
硬件上实现电导更新电压控制的方法
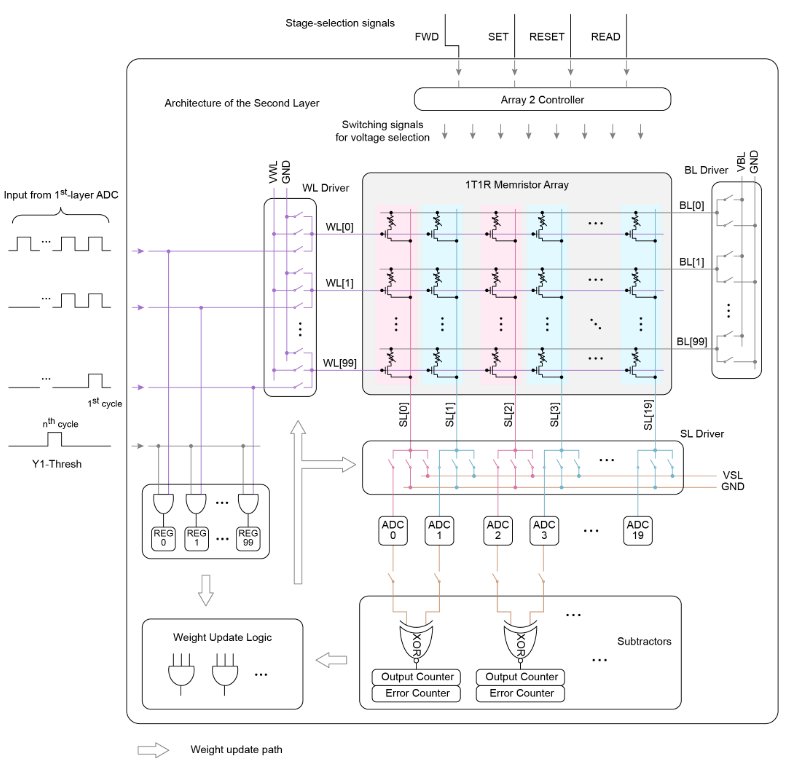
控制器将输入级选择信号解码为用于电压选择的输出信号。将电压选择信号作为BL/WL和SL驱动器的控制信号。通过驱动器中的MUX选择要加到忆阻器阵列上的电压。
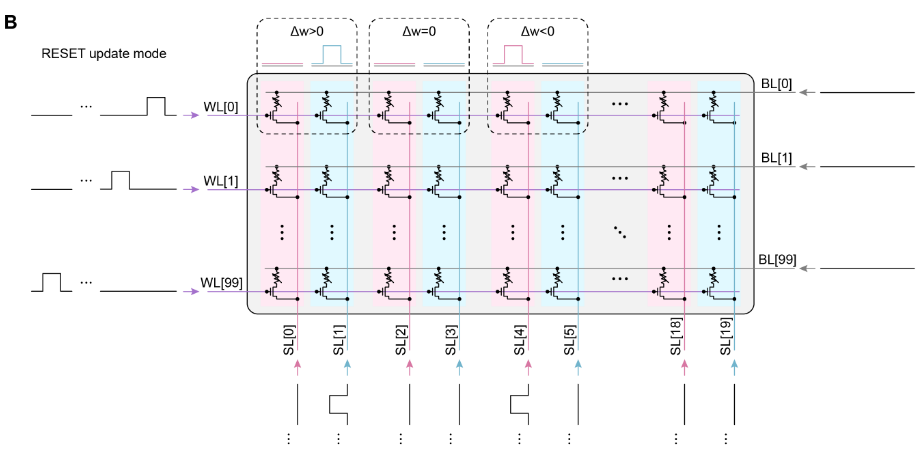
第一层阵列采用2T2R来降低IR压降,第二层阵列采用1T1R配置,两个相邻列分别表示正权重和负权重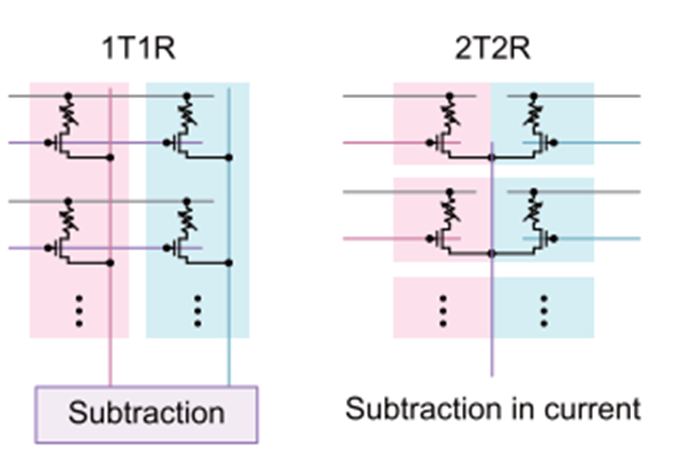
硬件上实现其他计算模块的方法
忆阻器阵列和片上ADC执行VMM运算,实现前向传播;
ADC配置沿模拟VMM信号的量化实现ReLU激活函数;
基于脉冲数的定时依赖方案、差分对减法输出、误差计算电路、符号变换电路略(依靠定制电路和逻辑电路实现)
片外训练与片内推理
网络训练在定制的外围电路中实现,然后通过权重迁移算法和周期STELLAR方案的电压脉冲写入器件电导
芯片测试系统主要集成了FPGA和相应的电压发生器。FPGA为忆阻器生成控制命令,沿BL向忆阻器发送输入,并接入SL读取结果。电压发生器为VMM操作和忆阻器编程(电导更新)提供可编程的电压。
FPGA通过以太网连接与实现用户界面的PC进行通信。(他们还做出了应用程序编程接口(API))
片内推理(前向传播)在芯片内部的crossbar阵列内实现,测量测试集准确率。输入图像采用二值化像素。导入的电导能够长期存储(训练后48天内测试集准确率不变)
周期性STELLAR更新方案的电路设计(1T1R)
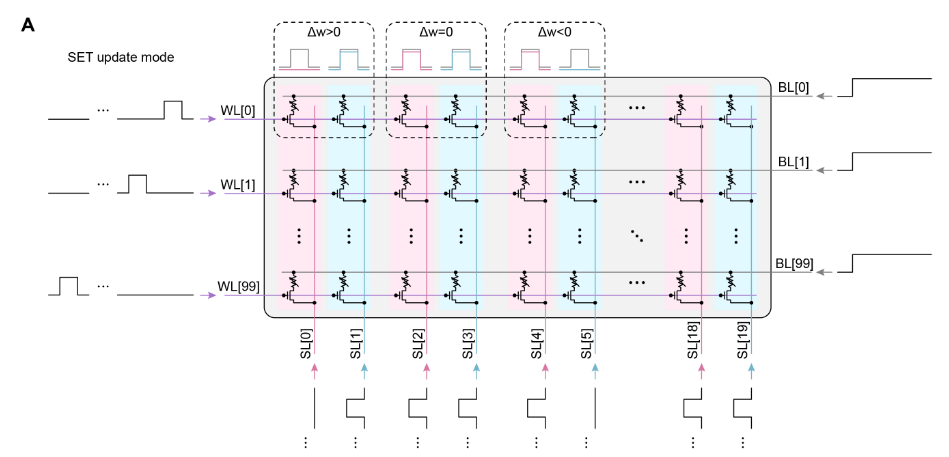
第二层阵列的完整电路图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微服务最佳实践:构建可扩展且高效的系统
- 美易官方:美股内在的杠杆原理:投资者疯狂的背后是什么魔力?
- 2023年,我46岁,进入关机模式,稳了
- 软件测试/测试开发|pytest用例执行顺序,这篇文章就够了
- 【花雕动手做】ASRPRO语音识别(45)---红外光敏双模块感控继电器
- 上海亚商投顾:三大指数小幅反弹,旅游、机器人板块集体走强
- SpringBoot + vue3 + TypeScript + activiti7 + 动态表单 的工作流引擎
- Java大数据hadoop2.9.2搭建伪分布式yarn资源管理器
- Weblogic 中间件性能调优
- 如何用二维码看视频?视频做成二维码的快捷教程