计算机体系结构基础复习
1.?计算机系统可划分为哪几个层次,各层次之间的界面是什么? 你认为这样划分层次的意义何在?
答:
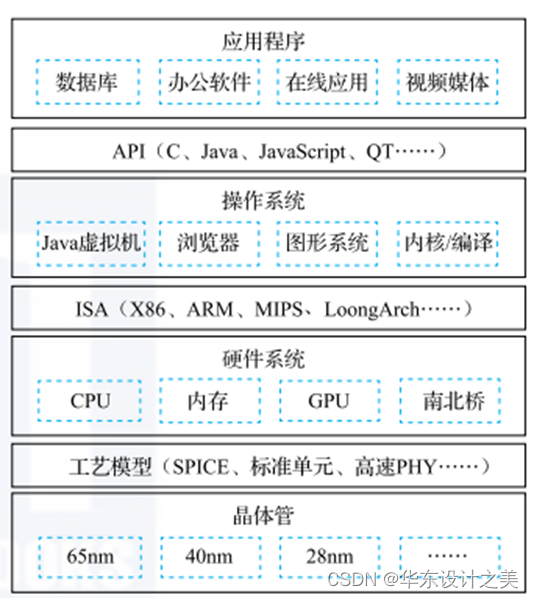
计算机系统可划分为四个层次,分别是:应用程序、 操作系统、 硬件系统、 晶体管四个大的层次。 注意把这四个层次联系起来的三个界面。各层次之间的界面如下:
第一个界面是 应用程序编程接口 API(Application Programming Interface), 也可以称作 “操作系统的指令系统”, 介于应用程序和操作系统之间。 API 是应用程序的高级语言编程接口, 在编写程序的源代码时使用。 常见的 API 包括 C 语言、 Fortran 语言、Java 语言、 JavaScript 语言接口以及 OpenGL图形编程接口等。 使用一种 API 编写的应用程序经重新编译后可以在支持该 API 的不同计算机上运行。 所有应用程序都是通过 AP编出来的, 在 IT 产业, 谁控制了 API 谁就控制了生态, API 做得好, APP(Application) 就多。 API 是建生态的起点。
第二个界面是指令系统 ISA(Instruction Set Architecture), 介于操作系统和硬件系统之间。 常见的指令系统包括 X86、ARM、 MIPS、 RISC-V 和 LoongArch 等。 由于 IT 产业的主要应用都是通过目标码的形态发布的,因此 ISA 是软件兼容的关键, 是生态建设的终点。 指令系统除了实现加减乘除等操作的指令外, 还包括系统状态的切换、 地址空间的安排、 寄存器的设置、 中断的传递等运行时环境的内容。
第三个界面是工艺模型, 介于硬件系统与晶体管之间。 工艺模型是芯片生产厂家提供给芯片设计者的界面, 除了表达晶体管和连线等基本参数的 SPICE(Simulation Program with Integrated Circuit Emphasis) 模型外, 该工艺所能提供的各种 IP 也非常重要, 如实现 PCIE 接口的物理层(简称 PHY) 等。
计算机系统划分为多个层次的意义在于:
提高代码和系统的可维护性:系统分层后,每个层次都有自己的定位和组件分工,使得系统结构更加清晰,维护起来更加明确和方便。
方便开发团队分工和开发效率的提升:有了层次的划分,开发人员可以专注于某一层的某一个模块的实现,从而提高开发效率。
提高系统的伸缩性和性能:系统分层之后,我们可以从逻辑上的分层变成物理上的分层。当系统并发量吞吐量上来了,可以将不同的层部署在不同服务器集群上,不同的组件放在不同的机器上,用多台机器去抗压力,从而提高系统的性能。压力大的时候扩展节点加机器,压力小的时候,压缩节点减机器,系统的伸缩性就是这么来的。
总的来说,通过分层,可以有效地将一个复杂的系统分解为更易于管理和理解的子系统,从而提高系统的效率和可维护性。
2.在一个包含TLB的当代处理器中,回答问题:(1) TLB的作用是什么?(2) 请阐述TLB、TLB失效例外、页表和Page Fault之间的关系;(3) 现代计算机普遍采用页表层次化的方式,请解释原因;(4)如果这样一台机器的设计,对于同样的虚拟地址、TLB 命中和 Page fault 同时发生,这 种设计是否合理,为什么?
答:
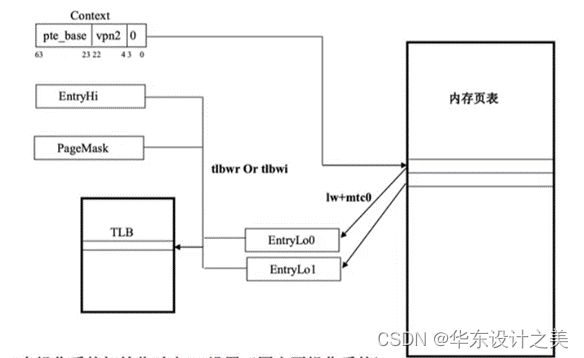
(2)当CPU访问内存时,首先会在TLB中查找对应的页表项,如果TLB中没有,会发生TLB失效例外,就会查询页表。如果页表中也没有,就会发生Page Fault,通知操作系统进行相应的处理。
TLB:页表缓冲,里面放的是一些页表文件的子集;
TLB失效例外:在TLB中,没有根据VA找到相应的页表项;
页表:也表示内存的目录,作用是实现逻辑页号导物理块号的映射,简历从逻辑页导物理页的页面映射关系,这些映射就是一张张页表;
Page fault:缺页,指TLB中没有虚拟地址VA对应的页表,主存中也没有VA对应的物理地址,此时发生缺页,需由操作系统处理,花费时间长。
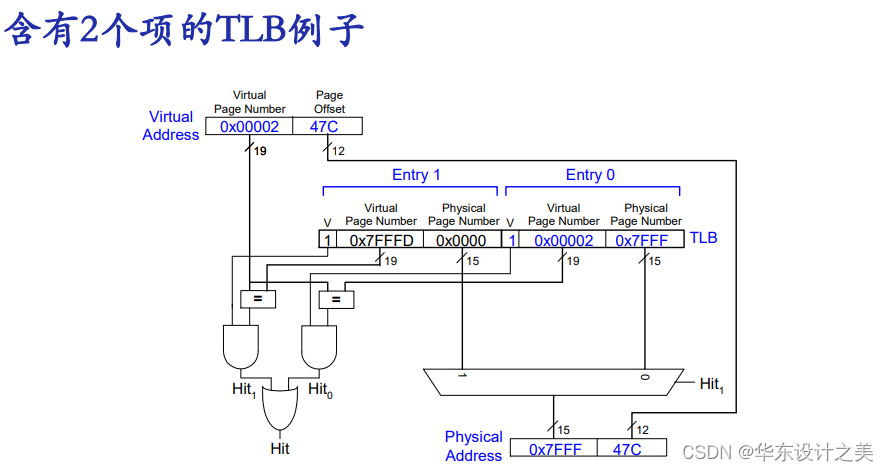
(3)?多级页表可减少存储空间的占用,比如已知处理器的逻辑空间为32位,页大小为4KB->虚地址=20位页号+12位页内偏移
1.单级页表:需220条,设每条需占用4B,共需物理内存4MB;
2.两级页表:设P1占10b,P2占10b;P1粗搜,P2细搜,则各需4KB连续物理内存,且由于并且每次访P1后都要访问P2,使得总的存储空间要比单级小得多。
| P1 | P2 | Offset |
(4)不合理,因为缺页意味着主存中没有VA对应的页表,由于TLB是页表的子集,那么TLB原则上也不该有,此时应发TLB miss,若没有miss,反而hit,说明违背了子集定义,不符合层次化设计需求。
?
(1)TLB是指页表转换后援缓冲器 (TranslationLookaside Buffer ) ,与Cache原理类似,把常用的虚实地址转换表项缓存在TLB内部,可以加快虚地址到物理地址的转换速度,提高访存性能。
转换后援缓冲器 Translation Lookaside Buffer (TLB):
- Idea:在处理器中用专用硬件来缓冲PTEs,Cache the page tableentries (PTEs) in a hardware structure in the processor;
- TLB的效率:小规模缓存:Small cache of most recently used translations (PTEs);一次性访存: Reduces number of memory accesses required for mostloads/stores to only one;
- 页表的局部性原理:数据的时空局部性很强;不同的页面大小(4KB,8KB,or 1-2GB),会使得连续的loads/stores操作大概率会访问同一个页;
- TLB:访问迅速: < 1 cycle;一般含有16- 512 项;高相关 High associativity;>95-99% 的命中率(与负载类型有关);将Load/Store操作的访存次数降低至 1。
3.????32位处理器、32-bit 地址,每页Page Size :4 KB,每个页表项PTE: 4-byte,共有 2^20 PTEs,每个用户进程的页表 4 MB,为备份全部虚拟地址空间,需要 4 GB 的swap存储空间;但如果是64位处理器,虚拟地址64 bits,每页Page Size : 4 KB,每个页表项PTE: 4-byte PTEs,请问页的数量是多少个?,每个用户的页表大小是多少?
答:
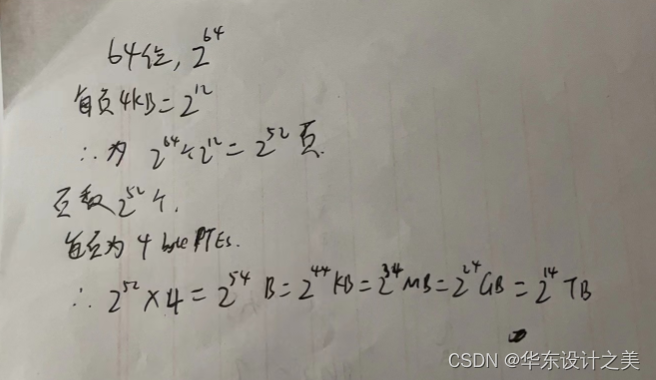
4.在片上网络系统中,请回答一下问题:(1)请列举片上网络的经典拓扑结构,并说明该拓扑结构的优缺点;(2)片上网络路由算法可分为哪几种类型?(3)在自适应路由算法中,可采用哪几种方法避免网络死锁。
答:(1)总线Bus (simplest);点对点Point-to-point connections (ideal and most costly);交叉开关Crossbar (less costly);环Ring;树Tree;网格Mesh;环面Torus;超立方Hypercube;欧米伽网络Omega;
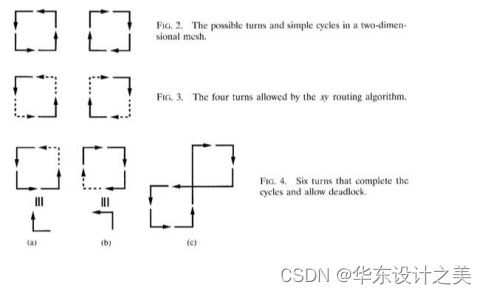
(2)路由算法 Routing Algorithm,三种类型:
- 确定性路由 Deterministic:始终为通信源-目的地对选择相同的路径;
- 流量无关路由 Oblivious:不考虑网络状态,选择不同的路径;
- 自适应路由 Adaptive: 可选择不同的路径来适应网络状态;
路由算法的设计遵从自适应原则设计:局部/全局反馈;最小或非最小路径。
(3)死锁问题 Deadlock的起因:进展停止;由对资源的循环依赖引起;每个数据包等待下游另一个数据包占用的缓冲区;
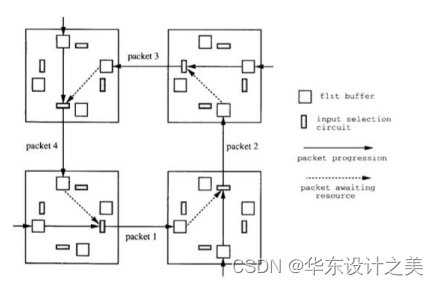
解决方案:
- 避免在路由中循环:维度顺序路由 Dimension order routing(无法建立循环相依性);转向记录与限制 Restrict the “turns” each packet can take;
- 加缓冲:通过添加更多缓冲来避免死锁((escape paths));
- 监测和打破死锁Detect and break deadlock:可抢占缓冲区;
- 转向模型 Turn Model to Avoid Deadlock:分析数据包在网络中可能转向的方向;确定这样的转弯可以形成的循环;禁止足够的转弯来打破可能的循环
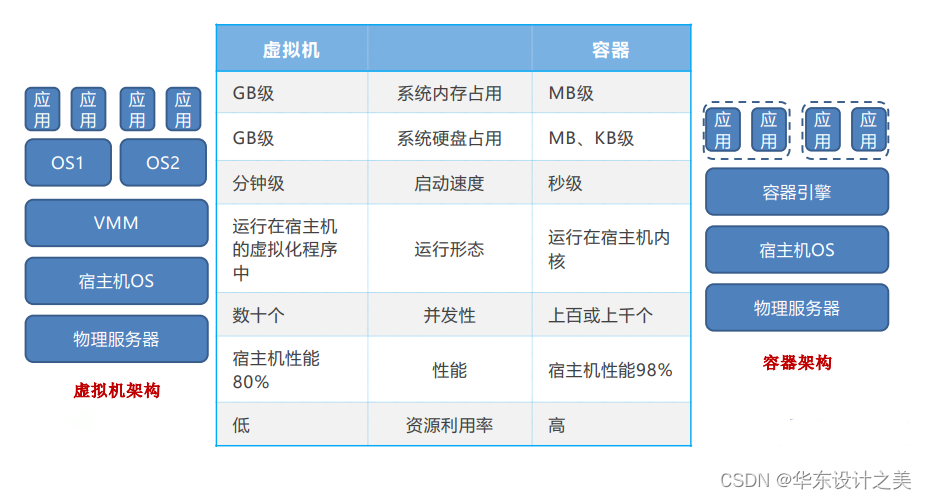
5.对于计算机虚拟化技术,回答下列问题:(1)简述Type-1和Type-2 Hypervisor的区别,可画简图;(2)简述虚拟机监控器技术和容器技术技术原理差异,可画简图。
答:(1)Hypervisor虚拟机管理程序
客户端操作系统在VM内运行,而主机操作系统在PM上运行;
Type 1 hypervisor:直接在硬件上运行,不需要主机操作系统;

Type 2 (hosted) hypervisor:作为应用程序运行在主机操作系统之上;

(2)容器和虚拟机的对比
6.对于如下分布式文件存储系统,回答问题:(1)Chunk的位置是否需要持久化?(2)如果一个Chunk大小64MB,元数据64bit,每个文件独立存储三份,那么1PB数据对应的元数据大小是多少?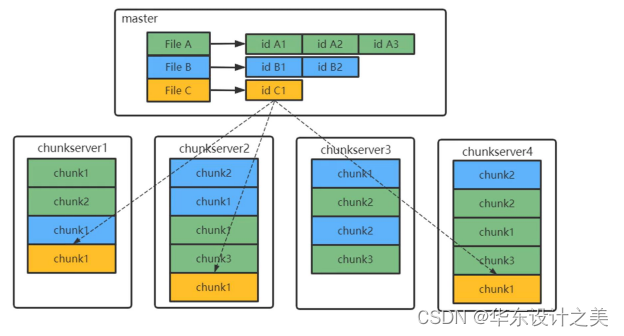
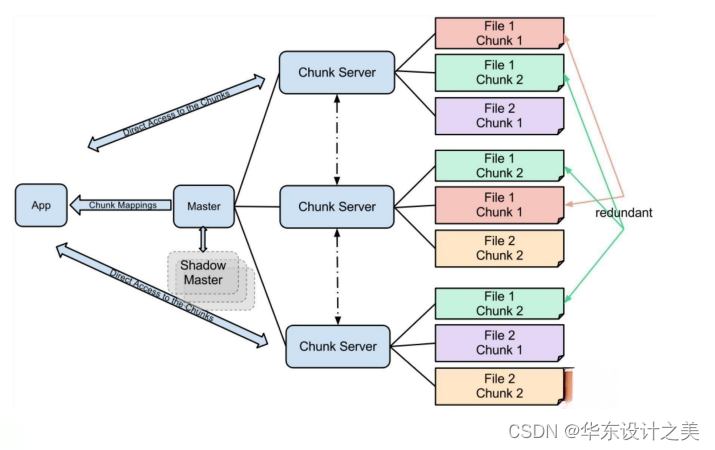
补充:GFS采用了一系列措施来确保master不会成为整个系统的瓶颈:1.DGFS所有的数据流都不经过master,而是直接由client和chunkserver交互;GFS把控制流和数据流分离,只有控制流才会经过master;2.GFS的client会缓存master中的元数据,在大部分情况下,都无需访问master;3.为了避免master的内存成为系统的瓶颈,GFS采用了一些手段来节省master的内存,包括增大chunk的大小以节省chunk的数量、对元数据进行定制化的压缩等。
答:(1)因为master在重启的时候,可以从各个chunkserver处收集chunk的位置信息;
(2)由下述过程可以轻易得到1TB的文件需要3MB,因此1PB则需要3GB;
总结回顾复习重点:
- Cache的工作原理
- Cache一致性问题,监听一致性协议 (MSI)
- 向量处理器的工作原理
- 超长指今字 (VLIW) 以及其他可以提高指令并行的技术
- 硬件加速器的主要作用
- 包含SIMD处理器的 GPU 体系结构
- 给定指今段中的数据依赖关系和执行时序图
- 分支指今流水线及其冲突控制加速比
- 处理器的时钟周期和CPI
- 乱序执行算法(eg.计分板算法)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- iTOP-RK3588开发板使用FFMpeg进行推流
- 由于找不到kernel32.dll无法继续执行此代码的解决方法
- Prometheus配置Grafana监控大屏(Docker)
- 深入理解 C++ 右值引用和移动语义:全面解析
- 文件上传报错总结
- Mac安装Typora实现markdown自由
- 闪存特性总结
- QT+OSG/osgEarth编译之四十八:pcre+Qt编译(一套代码、一套框架,跨平台编译,版本:Cal3D-0.13)
- 【Antlr】Antlr 解析 DOT 格式
- 商家转账到零钱开通证明材料怎么办?