【csapp】cachelab
实验全程参考大佬的博客CS:APP3e 深入理解计算机系统_3e CacheLab实验 ,感觉大佬在矩阵转置那块介绍的还是有些简略,我自己又做了点动图加以补充理解。膜拜大佬!
Part A
先解决解析命令行参数的问题,文档推荐使用getopt()函数进行解析:
#include <unistd.h>
#include <stdlib.h>
#include <getopt.h>
int getopt(int argc, char *const argv[], const char *optstring);
着重关注第三个参数——选项字符串,如ab:c:de::就是一个选项字符串。对应到命令行就是-a ,-b ,-c ,-d, -e。冒号表示参数,一个冒号就表示这个选项后面必须带有参数,但是这个参数可以和选项连在一起写,也可以用空格隔开,比如-b123和-b 123。两个冒号的就表示这个选项的参数是可选的,即可以有参数,也可以没有参数,有参数时,参数与选项之间不能有空格。如果后面不带冒号则说明没有选项参数。
其返回值就是对应选项字符的ascii码值,有选项参数,则参数字符串保存在extern char* optarg中。如果选项读完了就返回-1。更具体的信息可以使用man手册查看:man 3 getopt。
我们要实现的例子中命令行参数有[-hv] -s <s> -E <E> -b <b> -t <tracefile>,所以对应的选项字符串就是hvs:E:b:t:。
首先需要定义缓存数据结构,cache的结构如下:
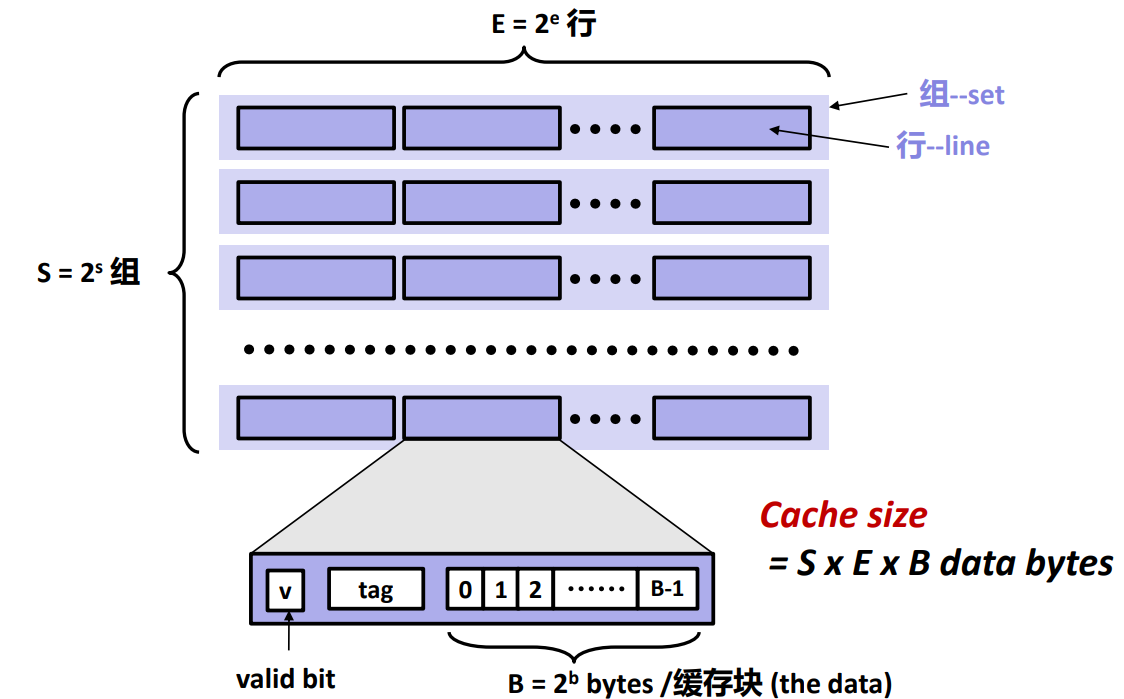
由于题目只关注hit/miss/eviction的次数,不需要实际存取数据,为了简便就不实现缓存块block了,如果实现的话就是添加一个指针,分配缓存空间的时候需要malloc分配2b个字节的空间。所以只需要valid和tag即可。
题目要求替换算法采用LRU,也就是eviction时替换最近没有被使用的line,所以需要添加一个记录最后访问时间的成员,每次访问的时候就更新一下。这里直接采用最简单粗暴的方式,用一个时间戳从0开始计数,每访问一次就+1,最小的则是访问时间最为久远的,进行替换。
由此可以定义数据类型:
typedef struct
{
bool valid;
unsigned long tag;
unsigned long time;
}line_;
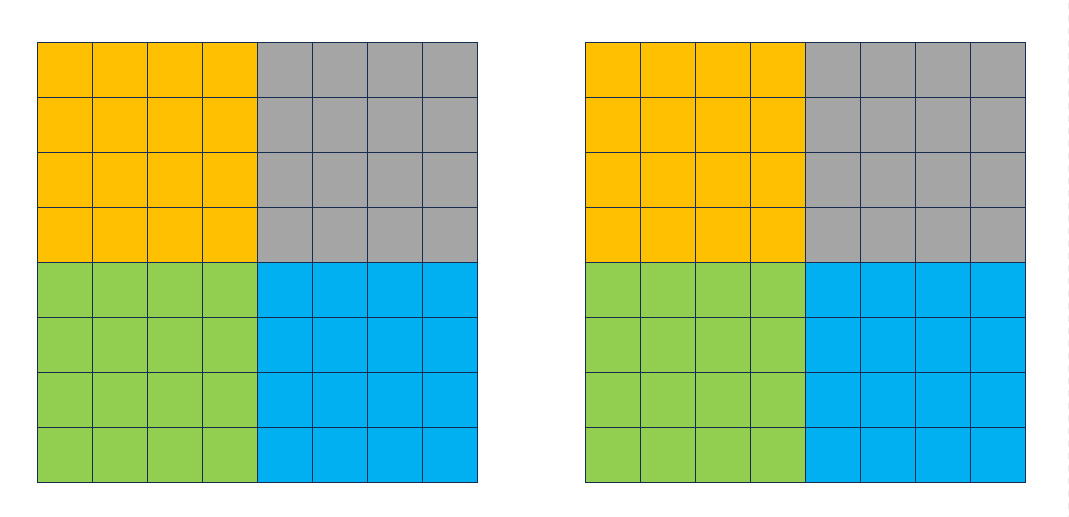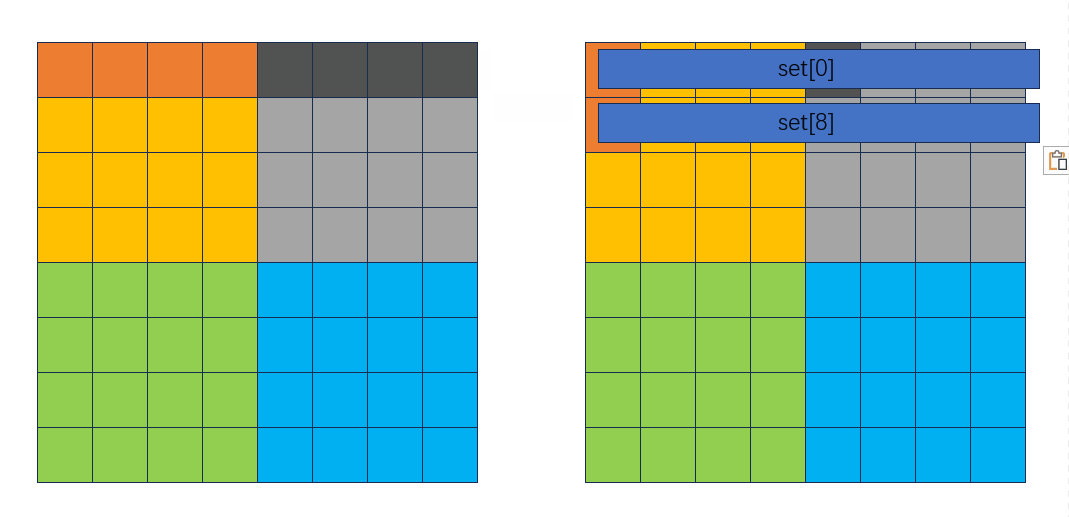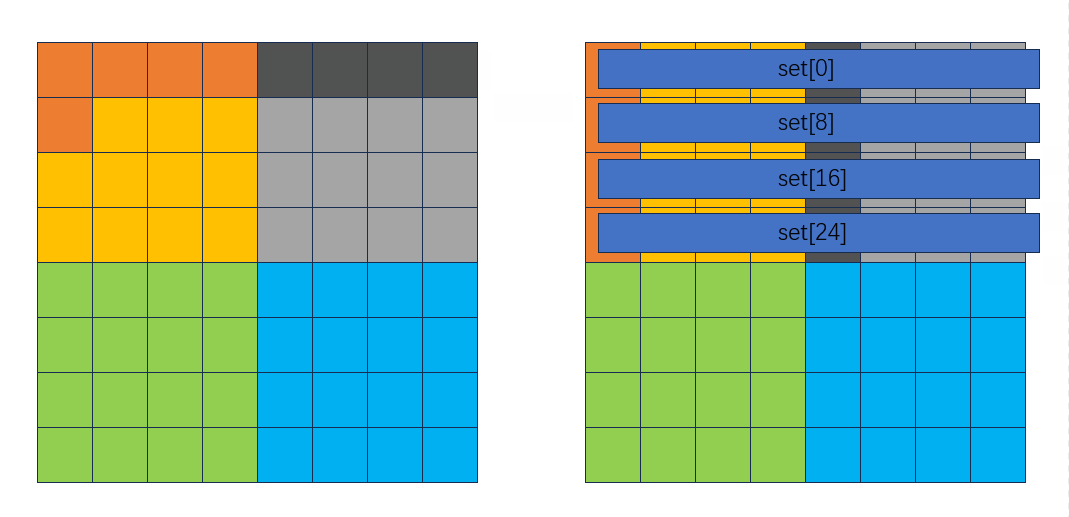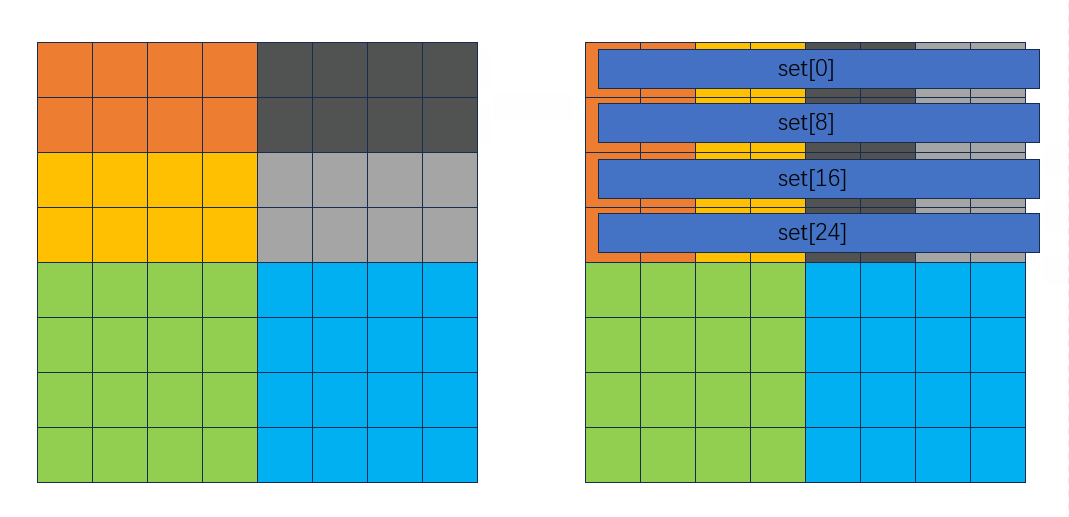
这就是line的类型,2e个行构成了一个组(set),为了方便再定义一个组类型:
typedef line_* set_;
组其实就是一个line数组,数组名是指针类型,后续方便malloc动态分配2e * sizeof(line_)的空间。
然后2s个组就构成了整个缓存结构,所以3为了方便再定义一个类型:
typedef set_* cache_;
和上面一样,这就是一个set数组,后续分配2s * sizeof(set_)的空间。
需要定义三个全局变量记录最终结果:
int hit;
int miss;
int eviction;
此外还需要定义几个全局变量,分别是-h选项对应的help信息,这个直接照抄示例程序的就行:
const char *help_message =
"Usage: ./csim-ref [-hv] -s <num> -E <num> -b <num> -t <file>\n\
Options:\n\
-h Print this help message.\n\
-v Optional verbose flag.\n\
-s <num> Number of set index bits.\n\
-E <num> Number of lines per set.\n\
-b <num> Number of block offset bits.\n\
-t <file> Trace file.\n\n\
Examples:\n\
linux> ./csim-ref -s 4 -E 1 -b 4 -t traces/yi.trace\n\
linux> ./csim-ref -v -s 8 -E 2 -b 4 -t traces/yi.trace";
选项字符串:
const char *command_options = "hvs:E:b:t:";
要追踪的文件名:
FILE* tracefile = NULL;
缓存对象:
cache_ cache = NULL;
是否输入-v选项,也就是是否显示跟踪信息的可选详细标志默认为false,当命令行参数检测到v后置为true即可:
bool verbose = false;
还有几个记录缓存大小相关的数据:
unsigned long s = 0;
unsigned long b = 0;
unsigned long S = 0;
unsigned long E = 0;
其中2s是sets的数量;2b是每行中缓存块的数量,这里不关注;S就是块的数量,数值等于2s;E是每个set中的line数。
数据类型定义完成,开始逐步处理。首先是解析命令行参数,代码如下:
int checkCommand(int argc, char* argv[])
{
char ch;
while ((ch = getopt(argc, argv, command_options)) != -1)
{
switch(ch)
{
case 'h':
printf("%s\n", help_message);
exit(0);
case 'v':
verbose = true;
break;
case 's':
s = atol(optarg);
S = 1 << s;
if (s <= 0)
{
printf("%s\n", help_message);
exit(-1);
}
break;
case 'E':
E = atol(optarg);
if (E <= 0)
{
printf("%s\n", help_message);
exit(-1);
}
break;
case 'b':
b = atol(optarg);
if (b <= 0)
{
printf("%s\n", help_message);
exit(-1);
}
break;
case 't':
if ((tracefile = fopen(optarg, "r")) == NULL)
{
printf("%s\n", "Failed to open tracefile");
exit(-1);
}
break;
default:
printf("%s\n", help_message);
exit(-1);
}
}
if (s == 0 || b ==0 || E == 0 || tracefile == NULL)
{
printf("%s\n", "Command line arguments are missing");
printf("%s\n", help_message);
exit(-1);
}
}
while嵌套switch结构仅仅能判断输入的命令行参数中输入的值合法,但不能判断缺少命令行参数的情况。所以还需要加个if判断,确保命令行参数输入齐全。
接下来该给缓存对象分配空间了,一共需要开辟S个set,每个块中开辟E个line,每个line中就不需要开辟block了。我们此前定义的缓存对象为cache_ cache = NULL,其中cache_是set_*类型,所以cache是一个set数组指针,每一个成员是一个set,一共有S个成员,所以需要给它分配S * sizeof(set_)个字节的空间,并且需要初始化为0。对于它的每一个成员,又是一个line数组,每个成员都有E个line,所以需要循环遍历给每个成员开辟E * sizeof(line_)个字节的空间:
void initCache()
{
cache = calloc(S, sizeof(set_));
if (cache == NULL)
{
printf("Failed to calloc set\n");
exit(-1);
}
for (unsigned long i = 0; i < S; i++)
{
cache[i] = calloc(E, sizeof(line_));
if (cache[i] == NULL)
{
printf("Failed to calloc line\n");
exit(-1);
}
}
}
同时把free函数也写出来,开辟时从上至下开辟,释放时就要从下至上释放:
void freeCache()
{
for (unsigned long i = 0; i < S; i++)
free(cache[i]);
free(cache);
}
接下来就是程序的核心部分,测试hit/miss/eviction的次数。
文件中I表示指令加载,我们要统计的是数据加载,所以遇到I开头的指令直接忽略,其余指令开头都有一个空格,以此区分。
如果命令是L(a data load)或S(a data store),则需要判断一次是否命中或替换。如果命令是M(a data modify, a data load followed by a data store),则相当于一个L和一个M,需要进行两次判断。
判断用一个函数实现,那这个函数需要哪些参数呢?这就需要了解缓存读取规则了。
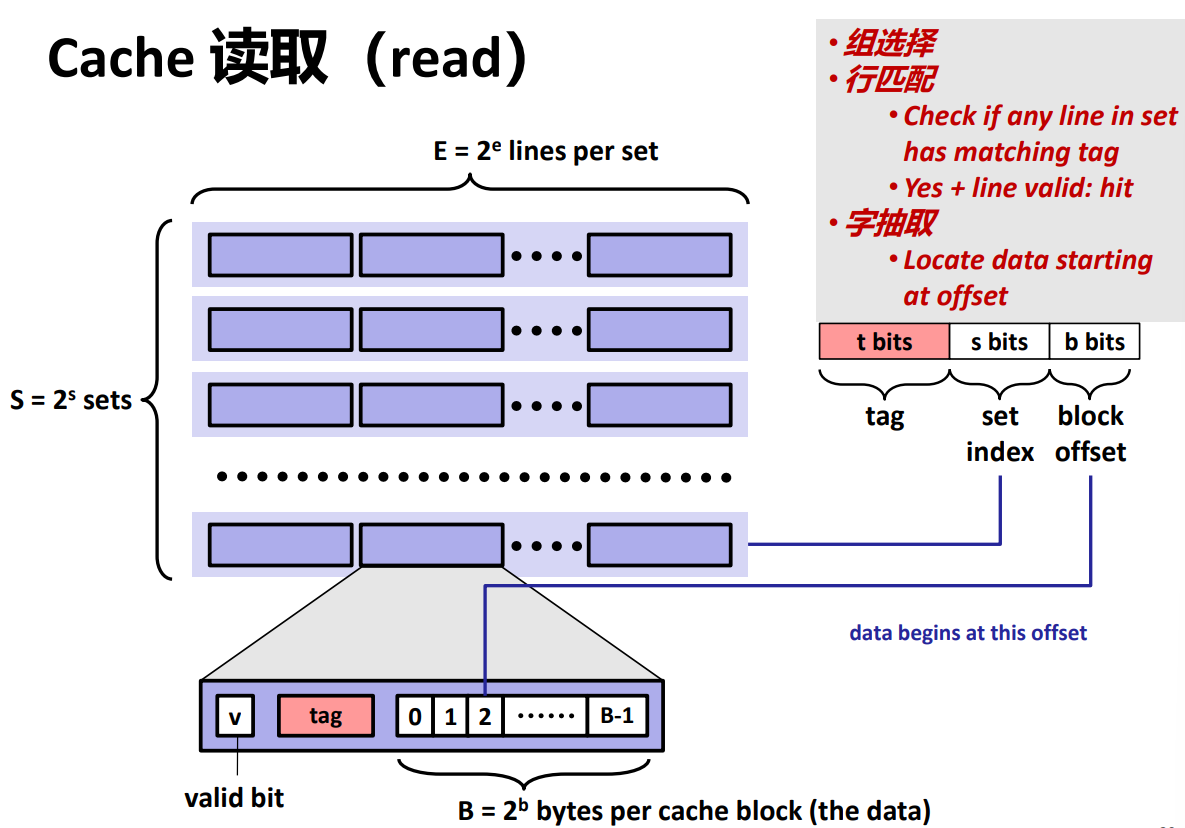
首先进行组选择,也就是在哪个set中进行查找,通过提取addr对应图中的s bits位可以得到:(addr >> b) & ((1 << s) - 1)。
首先
addr >> b得到低s位为目标值,(1 << s) - 1得到低s位为全1,二者按位与即为目标值。
然后进行行匹配,这一步需要提取tag:addr >> (s + b)。
所以测试函数就可以写出来:
void test()
{
char op;
unsigned long addr;
int size;
while (fscanf(tracefile, " %c %lx,%d", &op, &addr, &size) != EOF)
{
if (op == 'I')
continue;
if (verbose)
printf("%c %lx ", op, addr);
unsigned long set_index = (addr >> b) & ((1 << s) - 1);
unsigned long tag = addr >> (b + s);
if (op == 'L' || op == 'S')
judge(set_index, tag);
else if (op == 'M')
{
judge(set_index, tag);
judge(set_index, tag);
}
}
}
接下来需要完善judge判断函数,判断每次访问是hit,还是miss,或是eviction。
现在拿到了要查找的set的下标,只需要遍历set匹配tag即可。如果匹配上了并且valid是true,就是hit,更新时间戳,judge结束,直接返回即可。如果miss了,则需要找出上次访问时间最为久远的line,如果没数据则填充进去(因为没有实现block,所以直接将valid置为true即可),然后更新tag和时间戳,如果有数据则发生冲突,eviction++。time值最小的line那个自然就是要替换的,然后更新time也要注意,这里有两种策略,一种是在遍历的同时把最大的time记录下来,+1就是要更新的值;或者设置一个全局变量计数。这里采用前者策略。
所以judge函数也就写出来了:
void judge(unsigned long set_index, unsigned long tag)
{
for (unsigned long i = 0; i < E; i++)
{
if (cache[set_index][i].tag == tag && cache[set_index][i].valid)
{
if (verbose)
printf("hit\n");
hit++;
cache[set_index][i].time++;
return;
}
}
if (verbose)
printf("miss\n");
miss++;
// 找出时间戳最小的一个并记录下标,同时记录最大的时间戳
unsigned long max = 0, min = -1, line_index = 0;
for (unsigned long i = 0; i < E; i++)
{
if (cache[set_index][i].time <= min)
{
min = cache[set_index][i].time;
line_index = i;
}
if (cache[set_index][i].time >= max)
max = cache[set_index][i].time;
}
cache[set_index][line_index].time = max + 1;
cache[set_index][line_index].tag = tag;
if (cache[set_index][line_index].valid)
{
if (verbose)
printf(" and eviction\n");
eviction++;
}
else
{
if (verbose)
printf("\n");
cache[set_index][line_index].valid = true;
}
}
拼凑一下就凑出了main函数:
int main(int argc, char* argv[])
{
checkCommand(argc, argv);
initCache();
test();
freeCache();
printSummary(hit, miss, eviction);
return 0;
}
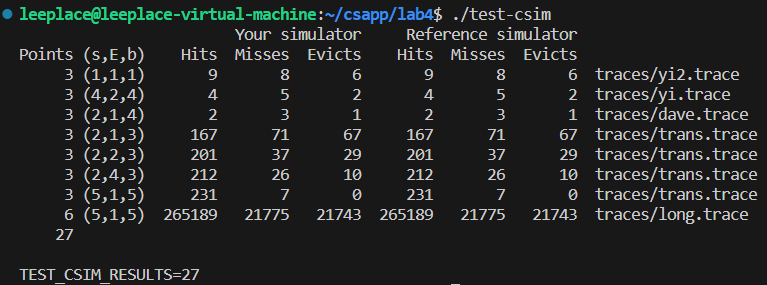
测试一下,可以通过:
Part B
以下均假设数组第一个元素映射到set[0][0] 为前提。
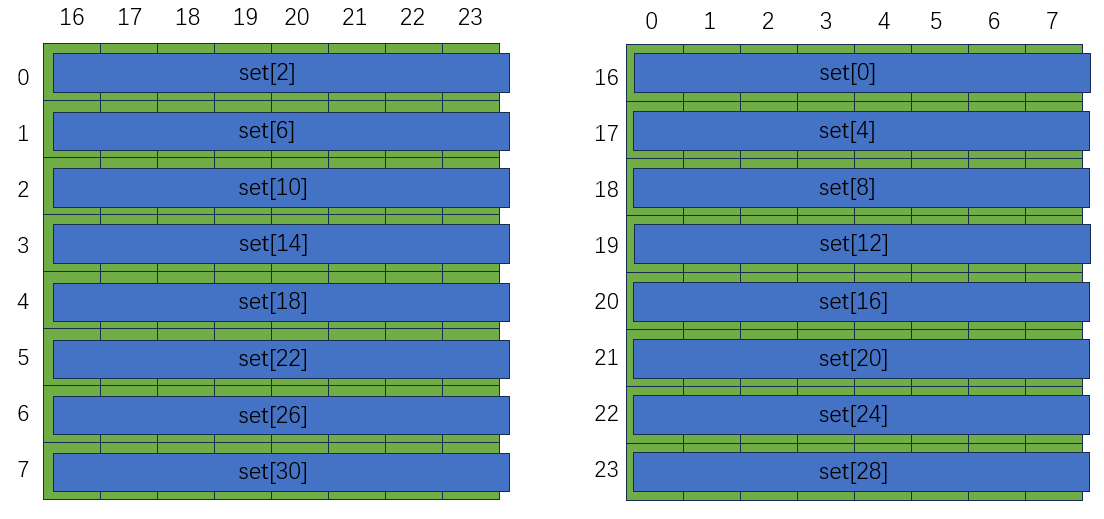
文档给了缓存的大小参数:s = 5, E = 1, b = 5,其实就是下面这样:
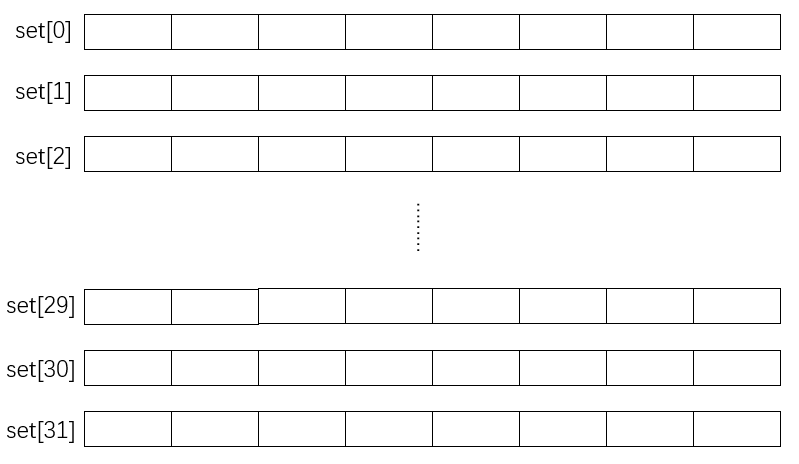
一共有25 = 32个set,每个set有1个line,每个line中有25 = 32byte大小的block,可以存放32 / 4 = 8个int类型的数据。所以cache最多存放32 * 8 = 256个int类型的数据。那么当(&int1 - &int2) / 4 = 256 * k时,两个数据就会映射到同一个位置,也就是会发生冲突。
以32*32的矩阵进行举例,一行32个int需要占用4个set,所以缓存一次性最多存8行,也就是两个元素正好差八行的整数倍就会发生冲突,比如A[7][0] = A[0][0],二者会映射到同一个位置,会发生冲突。
不过这种冲突情况是不会发生的,因为A转置到B的两个元素并不会正好相差8*k行。
还有一个很隐藏的点,在文件tracegen.c文件中可以看到A、B数组原型为A[256][256],俩都是256 * 256的数组,A[0][0]和B[0][0]正好差了256 * 256个数据,会映射到同一个位置!这个是很重要的,所以如果进行B[7][0] = A[0][0]这样的赋值也会发生冲突。因为B[7][0]和A[7][0]映射到了一个位置。并且在转置过程中,对角线上的元素是不变的,也就是B[i][i] = A[i][i],如果直接赋值也必然会发生冲突,需要单独考虑。
32 * 32
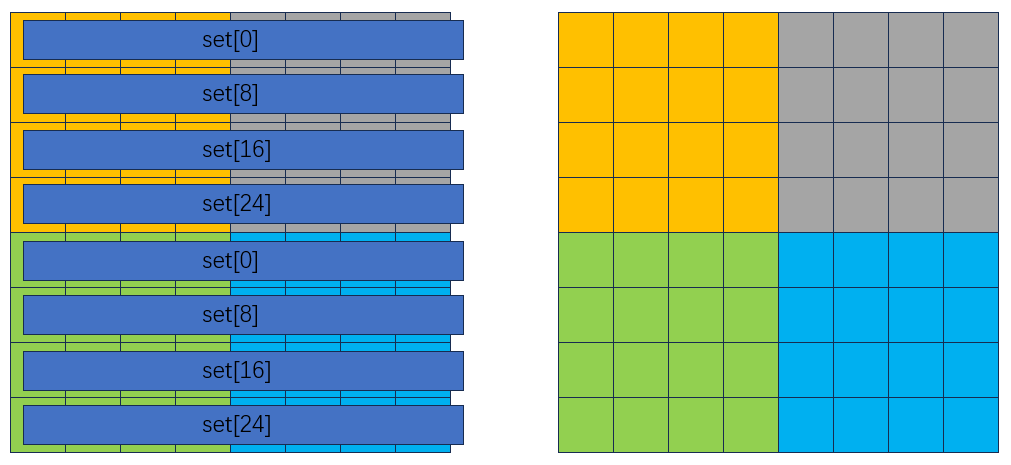
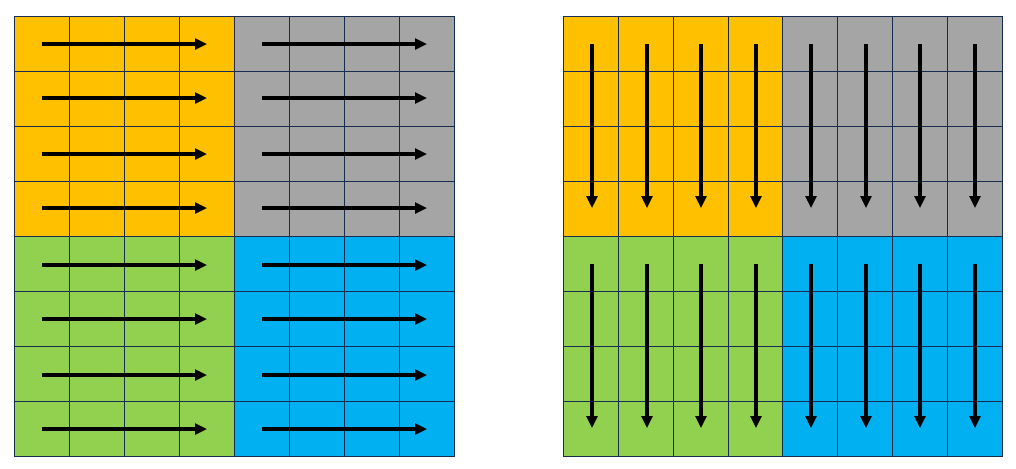
下面尝试8 * 8进行矩阵分块,理解一下分块是如何减少不命中和冲突的,下图中每一个色块覆盖8*8的区域:

缓存映射情况如下:

以绿色色块为例:
左侧对应A数组,右侧对应B数组。赋值语句为B[j][i] = A[i][j]。对应数据可以全部加载进缓存不冲突:
这样虽然只同时利用了16个set,但是只会在加载分块进缓存的时候产生冲突,而如果使用更大的分块,在加载分块的时候必然会加载两个正好相差8行的元素,产生更多冲突。如果采用更小的分块,虽然没有增加冲突,但是缓存的利用率更低了。所以权衡一下8*8就是最优分块。
就用这种分块策略进行测试:
for (int i = 0; i < N; i += 8)
for (int j = 0; j < M; j += 8)
for (int m = i; m < i + 8; ++m)
for (int n = j; n < j + 8; ++n)
B[n][m] = A[m][n];
结果如下:
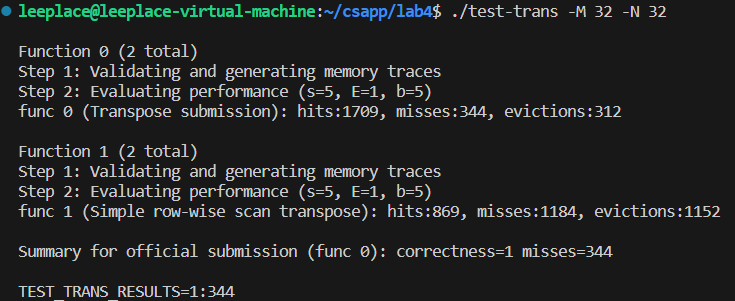
与300次的要求还有差距,这就需要解决一下对角线上的元素冲突问题。以第一个白色块为例:
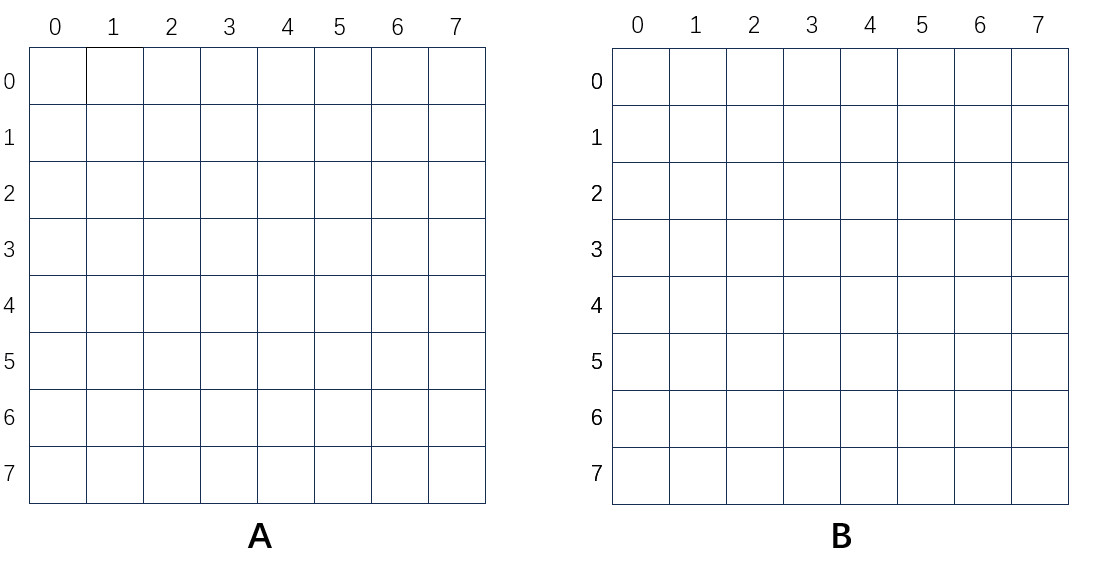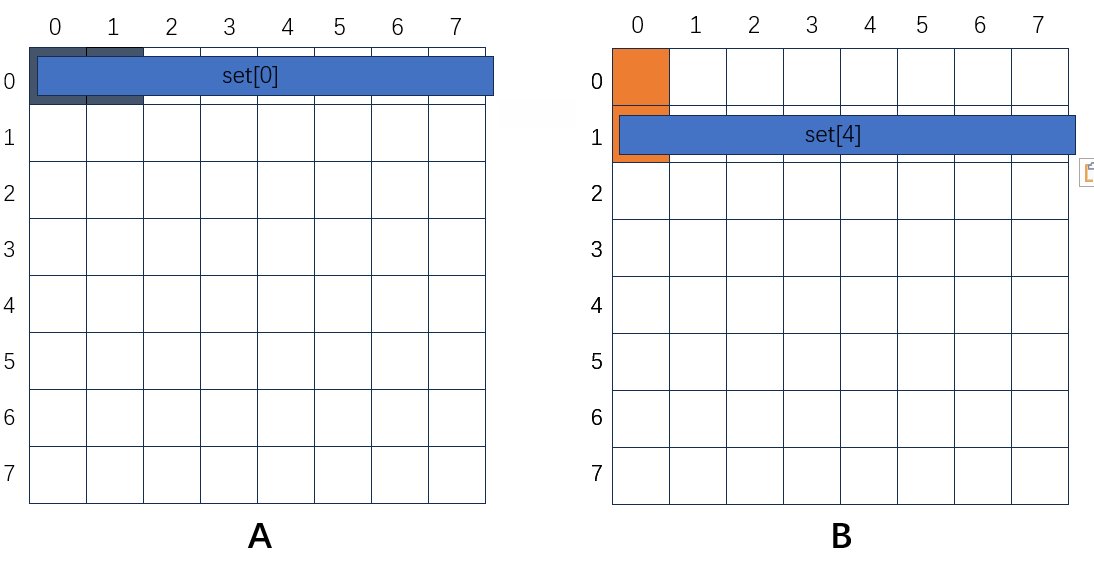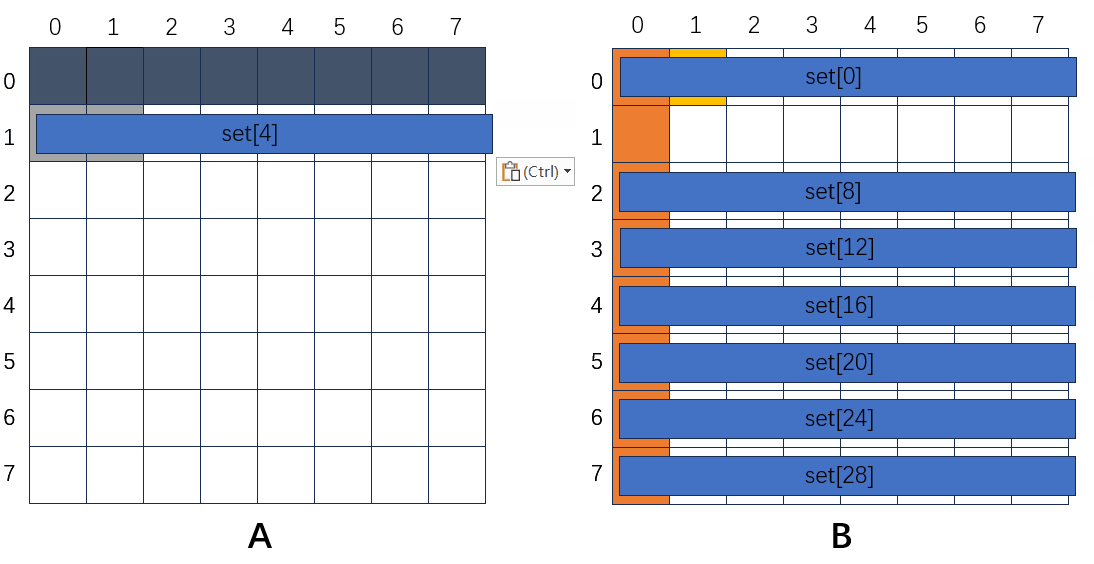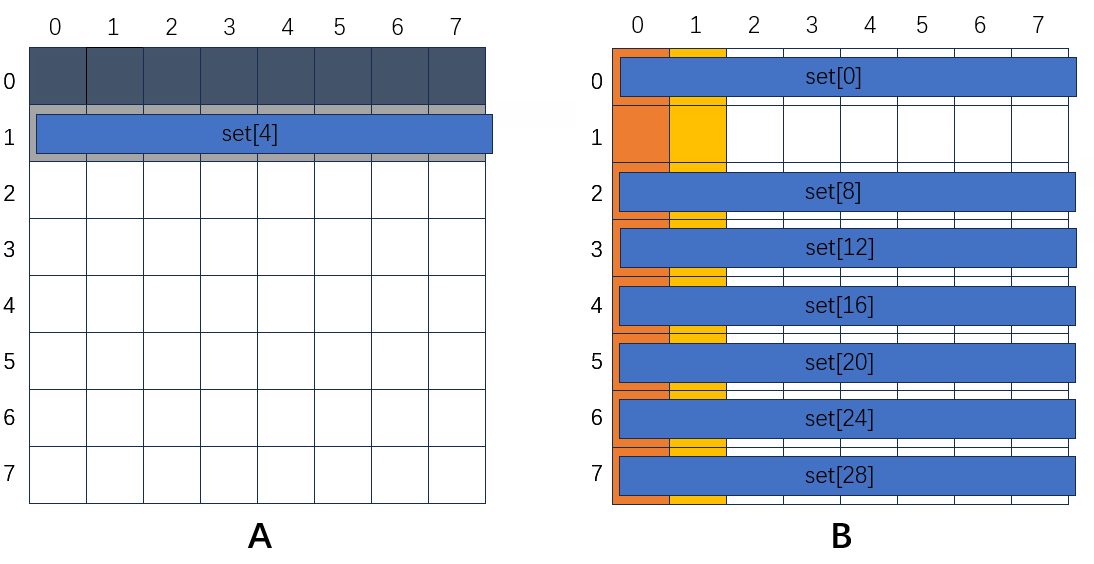
A的第一行要赋值到B的第一列,首先读A[0][0],第一次肯定不命中,加载进来,set[0]存A[0];然后读B[0][0],还是不在,加载进来,set[0]存B[0];然后读A[0][1],不命中,加载进来,set[0]又存A[0],直到A的第一行全部读完。再读下一行,首先读A[1][0],不命中,加载进来,set[4]存A[1];再读B[0][1],不命中,加载进来,set[0]存B[0];再读A[1][1],不命中,加载进来,set[4]存A[1];再读B[1][1],不命中,加载进来,set[4]存B[1];再读A[1][2],不命中,加载进来,set[4]存A[1],直到A的第二行全部读完,缓存都会命中。
以此类推,后面每一行相比第一行都多了2次不命中,一个对角块有8行,一块就会多14次不命中,一共有4块,总共就会多56次不命中。如果把这些解决了,理论上就能控制在300以内。
解决方法也很粗暴,直接定义8个局部变量,局部变量可以存放在寄存器中。依次把A的一行全部读出来,依次给B对应的一列赋值,这样可以避免中间多余的两次不命中:
for (int i = 0; i < N; i += 8)
for (int j = 0; j < M; j += 8)
for (int k = i; k < i + 8; k++)
{
int t0 = A[k][j];
int t1 = A[k][j+1];
int t2 = A[k][j+2];
int t3 = A[k][j+3];
int t4 = A[k][j+4];
int t5 = A[k][j+5];
int t6 = A[k][j+6];
int t7 = A[k][j+7];
B[j][k] = t0;
B[j+1][k] = t1;
B[j+2][k] = t2;
B[j+3][k] = t3;
B[j+4][k] = t4;
B[j+5][k] = t5;
B[j+6][k] = t6;
B[j+7][k] = t7;
}
测试如下:
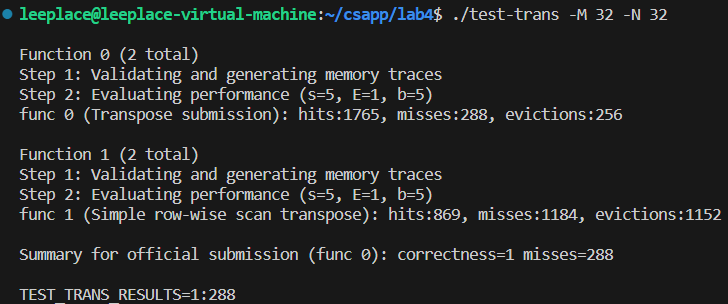
结果正好比预想的少56次。也达到了题目要求。
再看一下优化对角线后的读取情况加深理解:
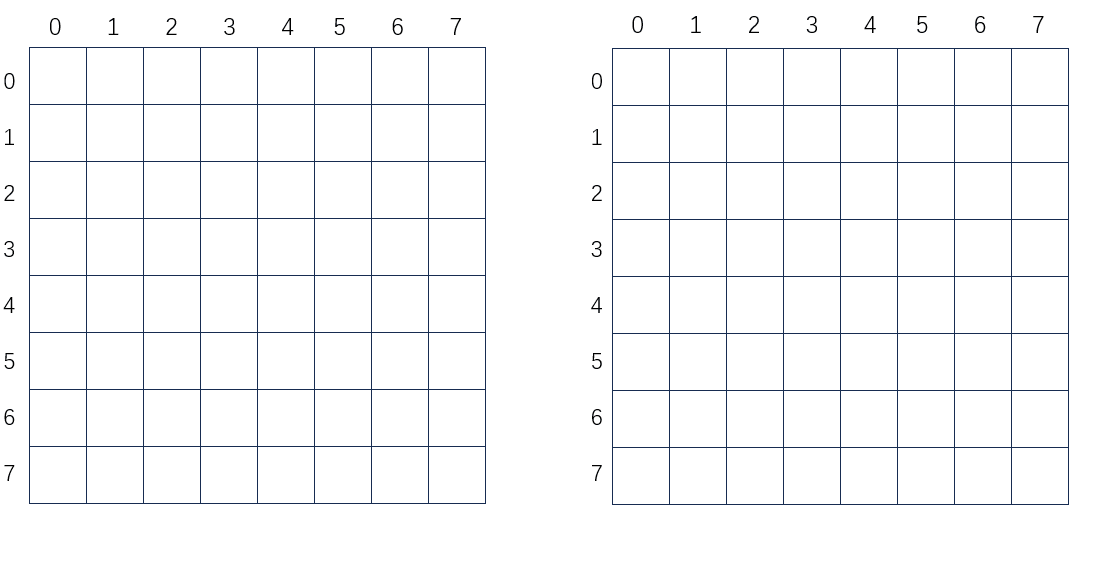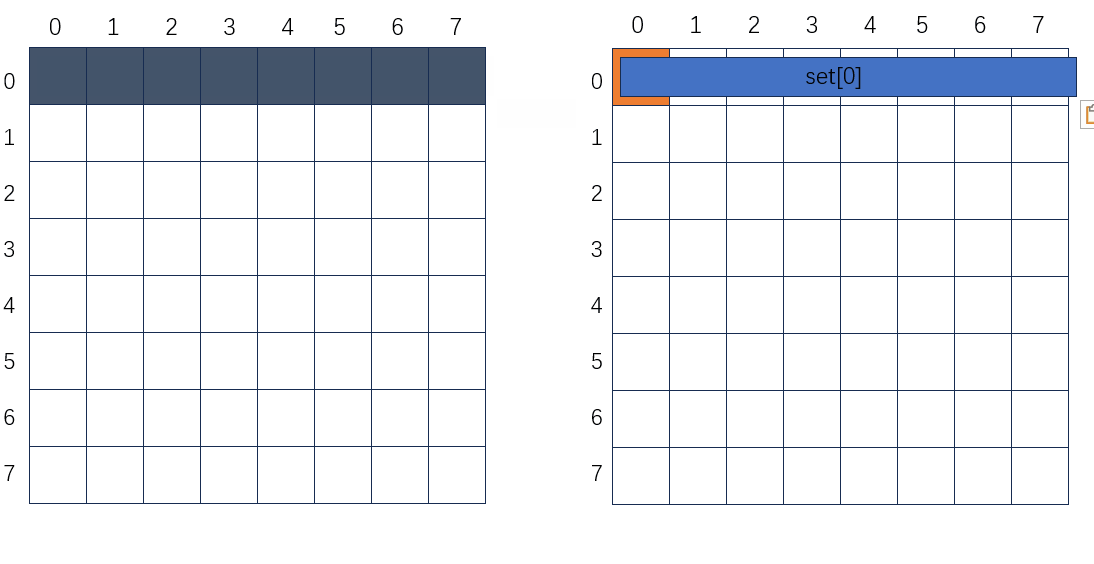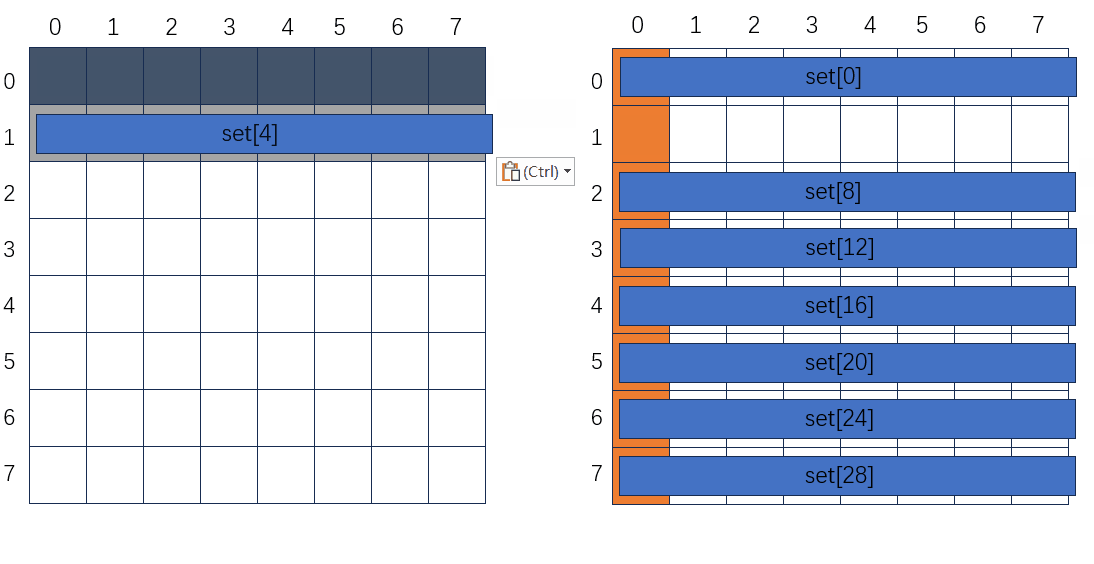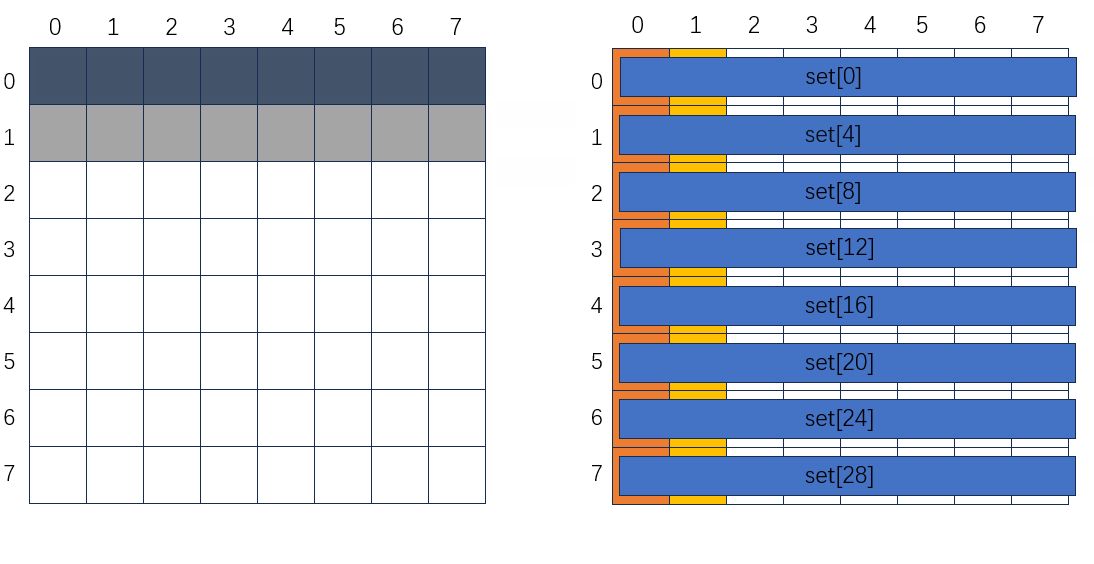
64 * 64
做完动图突然发现不合适的地方,右边为要转置到B中的某个分块,分块初始应该是白色的没有数据的,就当白色看吧。
此时数据一行有64个元素,8个set才能存满一行,cache存满最多能存4行。也就是两个元素中间差4行的整数倍就会发生冲突比如A[0][0]和A[4][0]都会映射到cache[0][0]位置。
如果仍使用8 * 8分块,那么每个分块内部读取的时候都会发生冲突,比如A[0][0]和A[4][0]都在一个分块内。如果使用4 * 4分块,那cache利用率就减半,结果肯定也不理想。
还是考虑8 * 8分块,把每一个块分成4部分:
本来是要把黄色部分转置到黄色部分,灰色部分本应转置到绿色部分,但是绿色部分和黄色部分映射到同一块缓存,会发生冲突,先把灰色部分转置到灰色部分。下图颜色加深代表要访问某个元素,左边是A矩阵,右边是B矩阵:
为了避免对角线分块上会多miss的问题,还是采用先把A的一行全部读出来的策略。这样就以较少的miss把B矩阵初步填满,此时填满之后效果如下:
再交换灰色块和绿色块,就完成了整个分块的转置。可惜的是这样优化仍拿不到满分。
进一步优化,在转换灰色块时逆序转换:

过程如下:
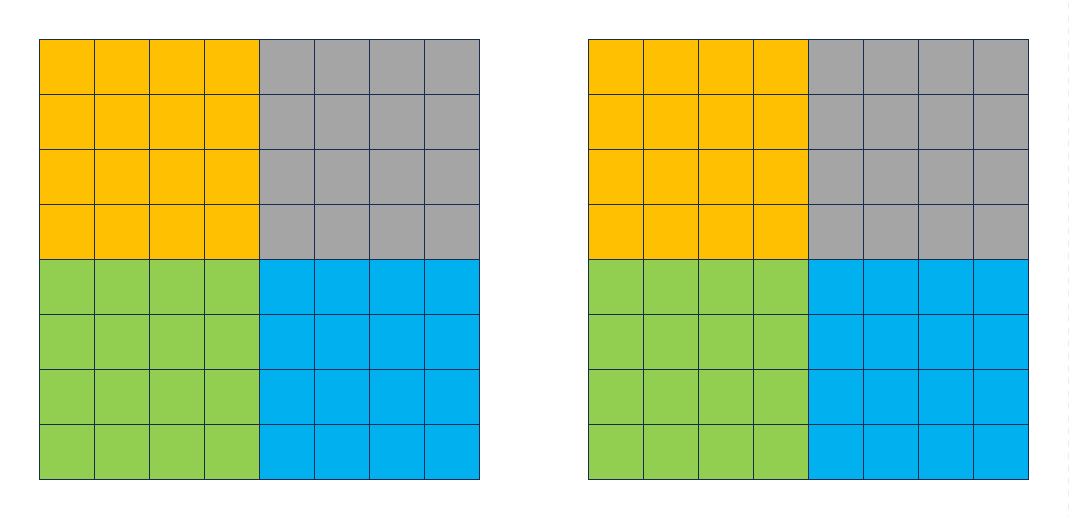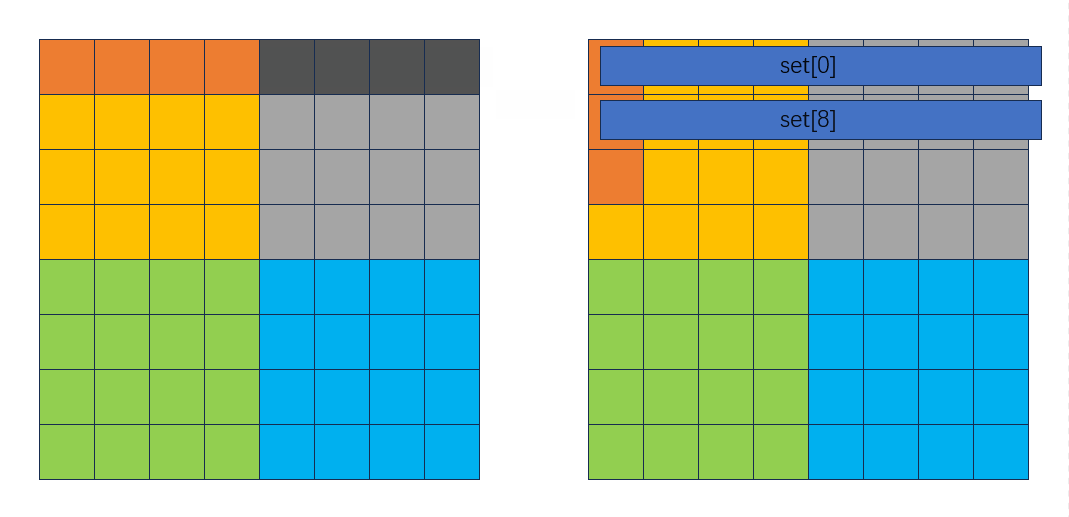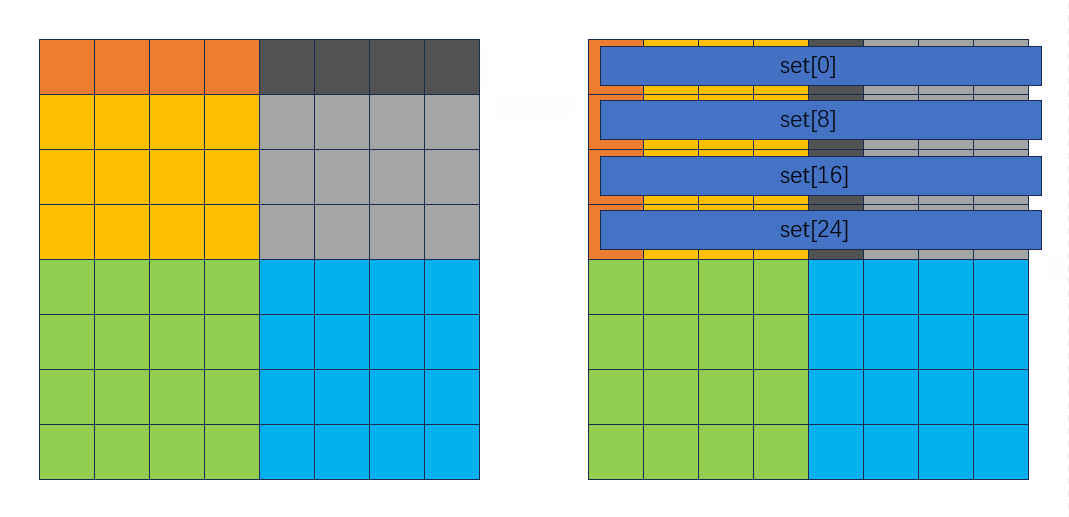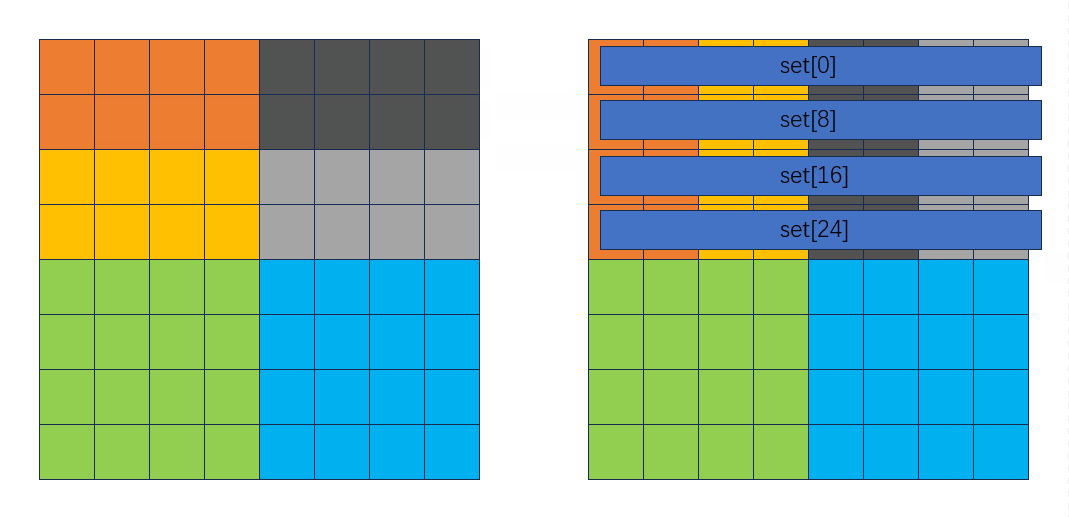
整个过程并没有因为逆序存放发生多余的miss。
然后读绿色块和蓝色块时按列来读,从内到外:
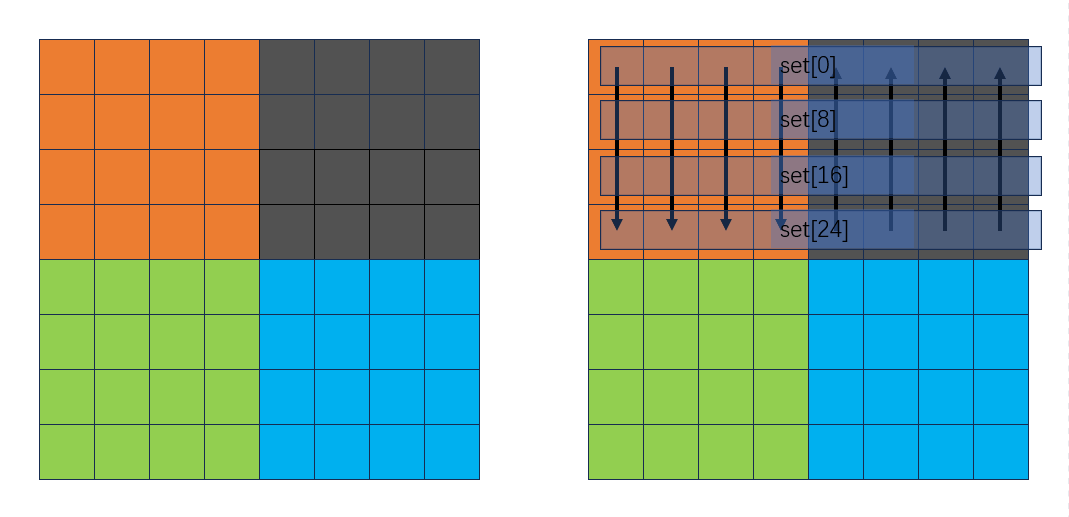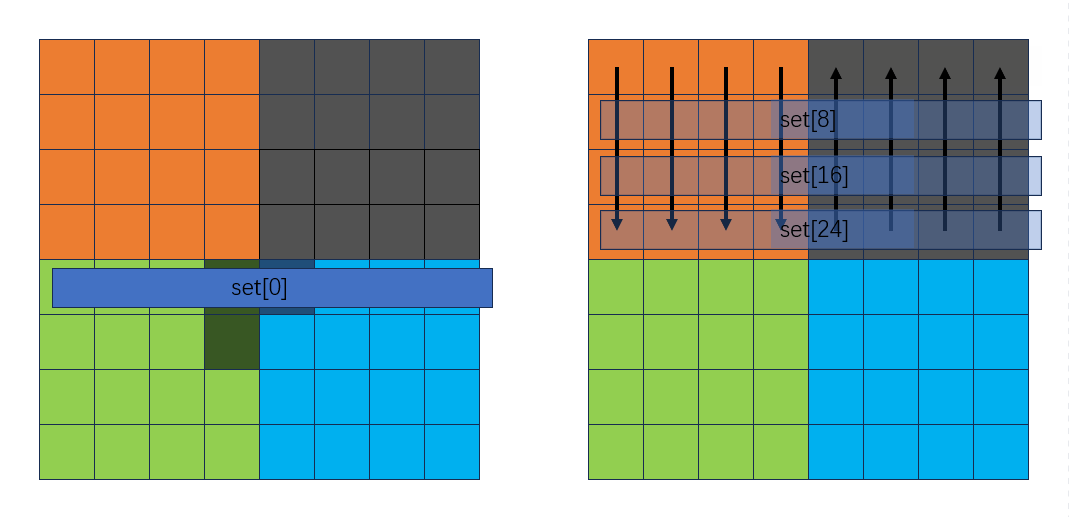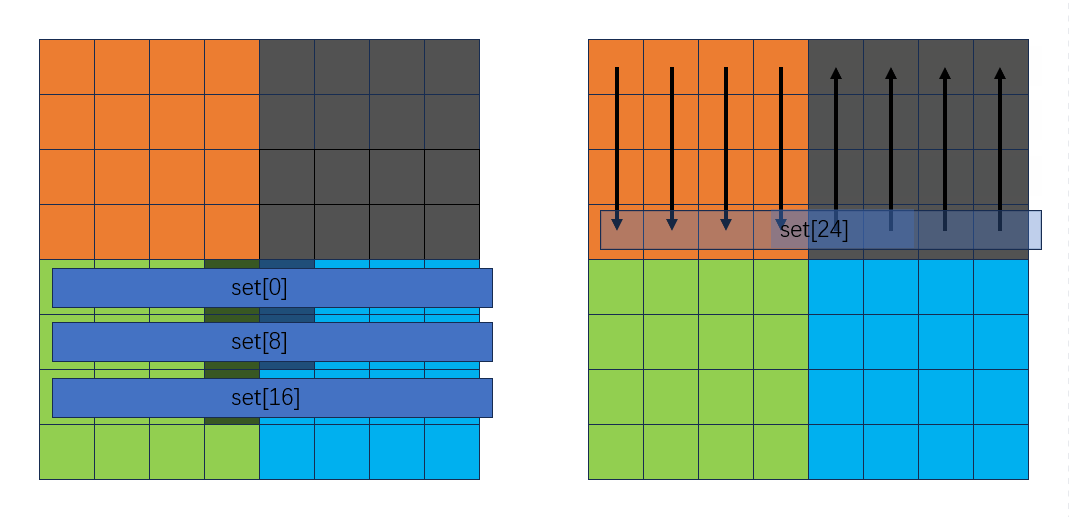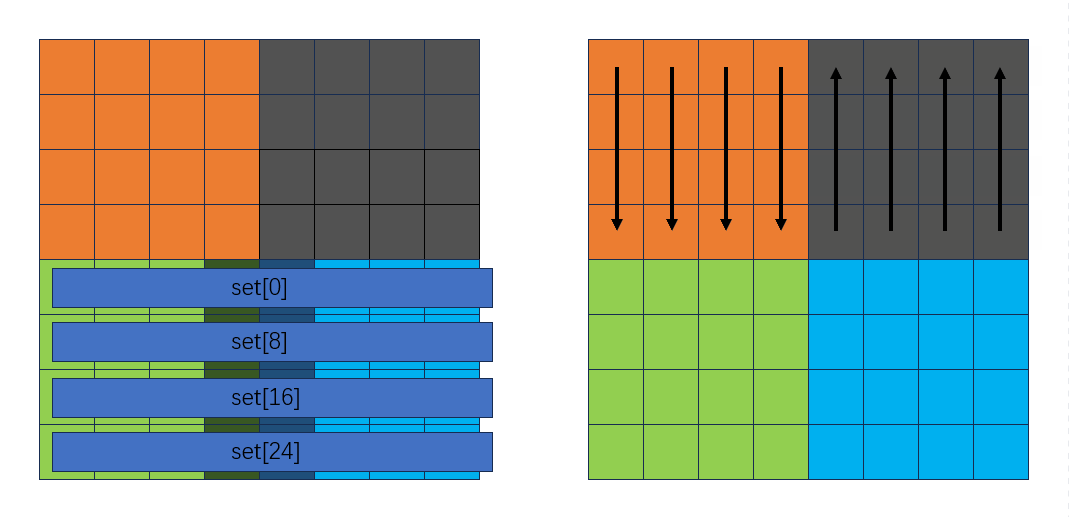
从下向上按行转换B中的灰色块到绿色块:
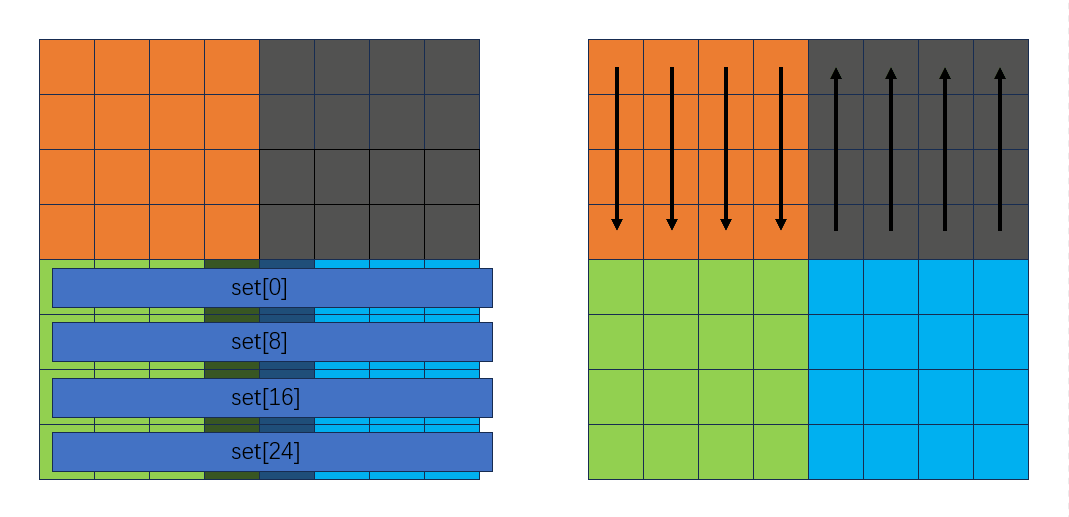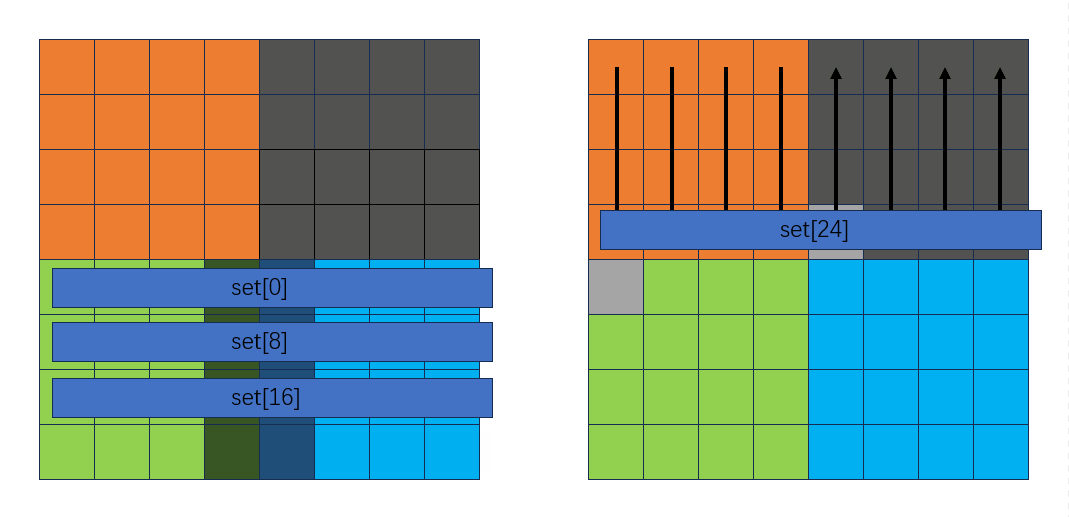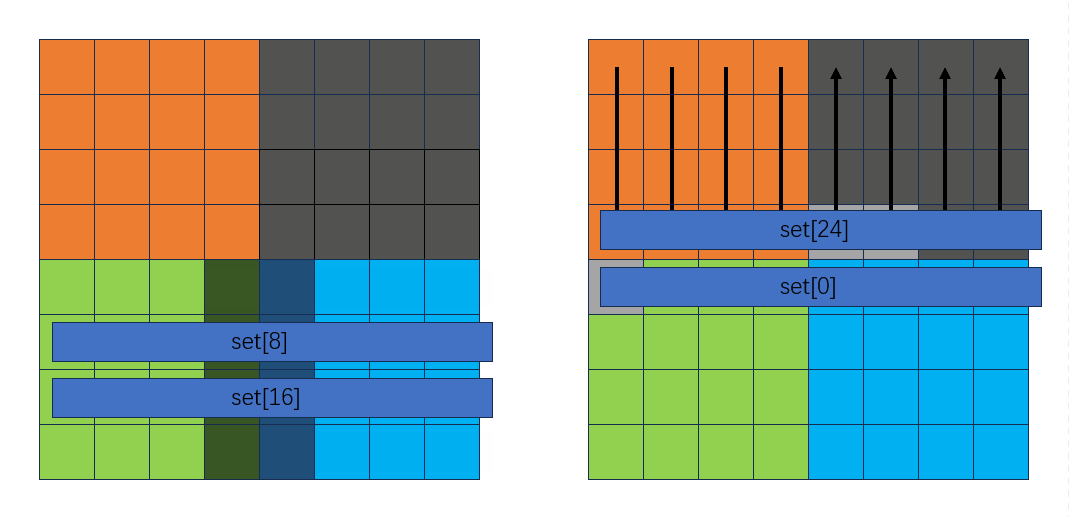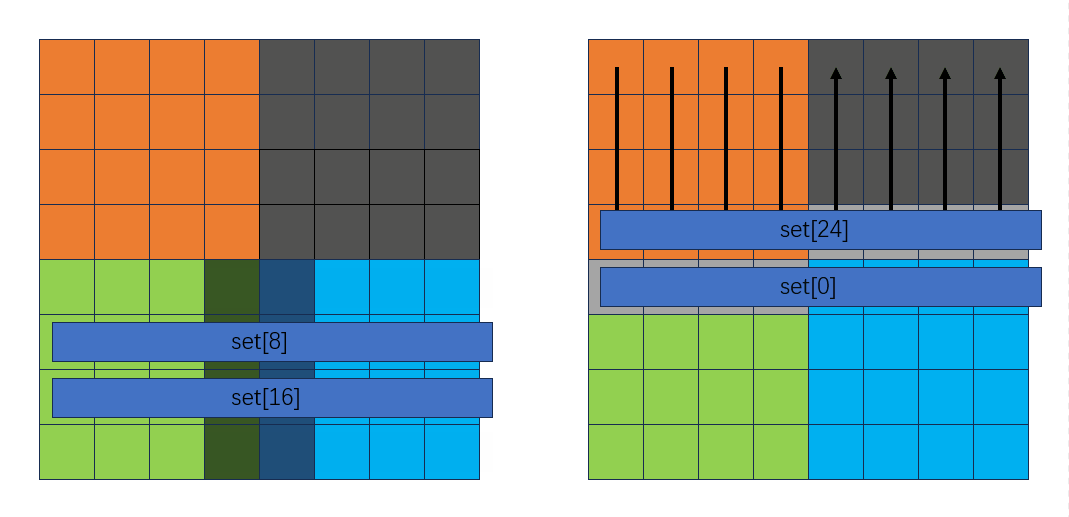
此时可以发现,正好可以把用临时变量存放的A中的绿色块和蓝色块赋到B中:
并且这个过程不会发生miss!复原灰色块的同时把绿色块和蓝色块也转置了。
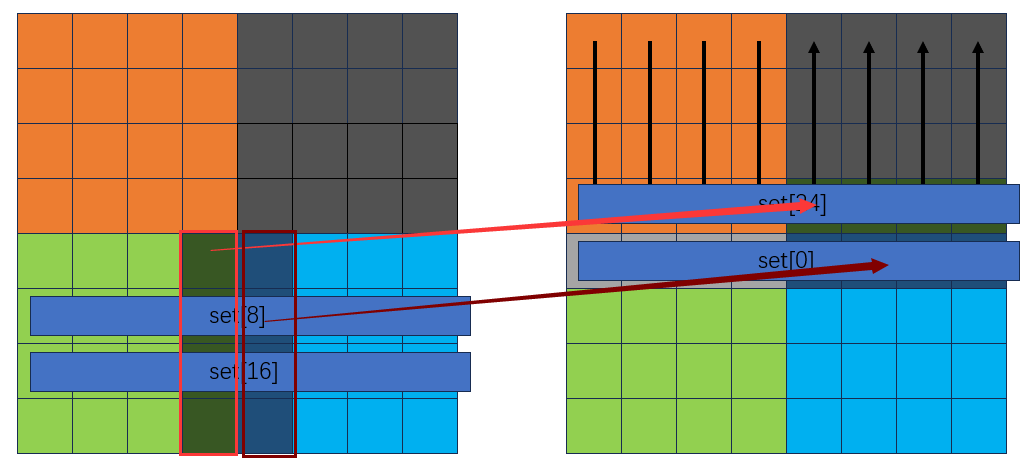
继续后面的过程:
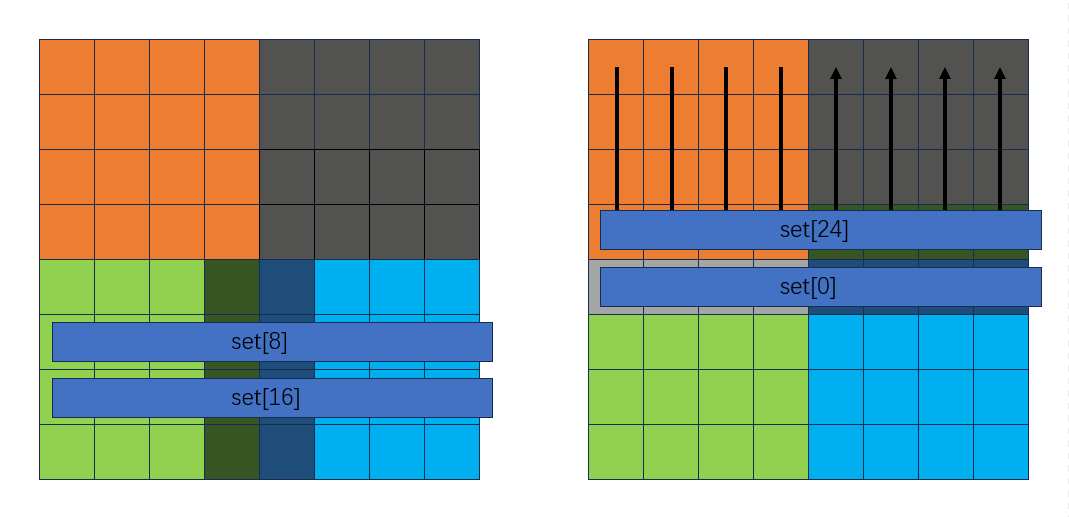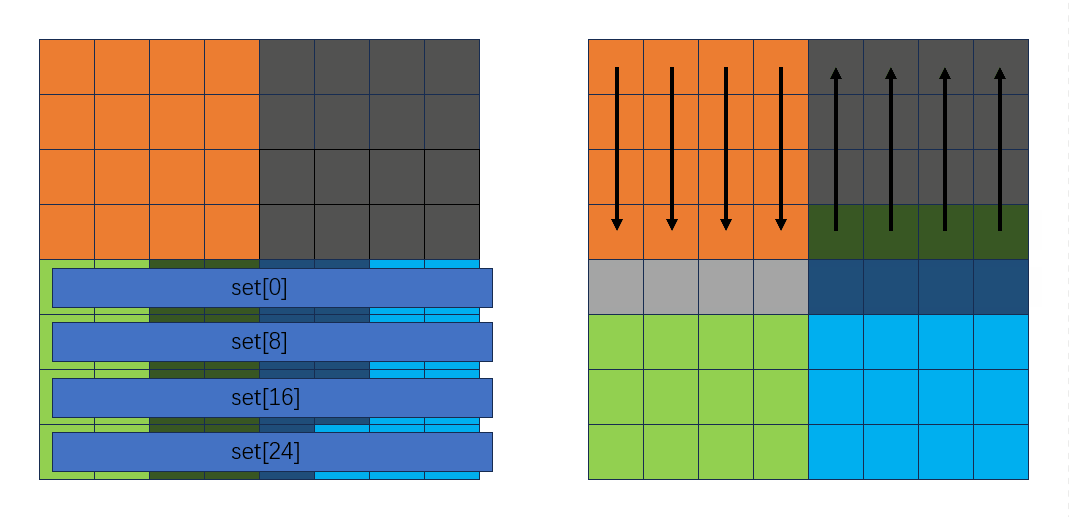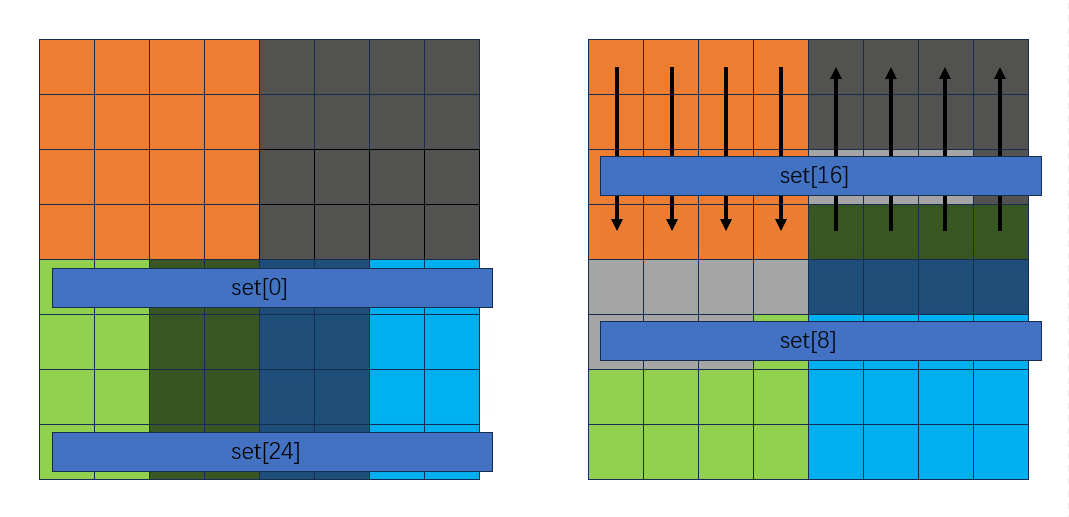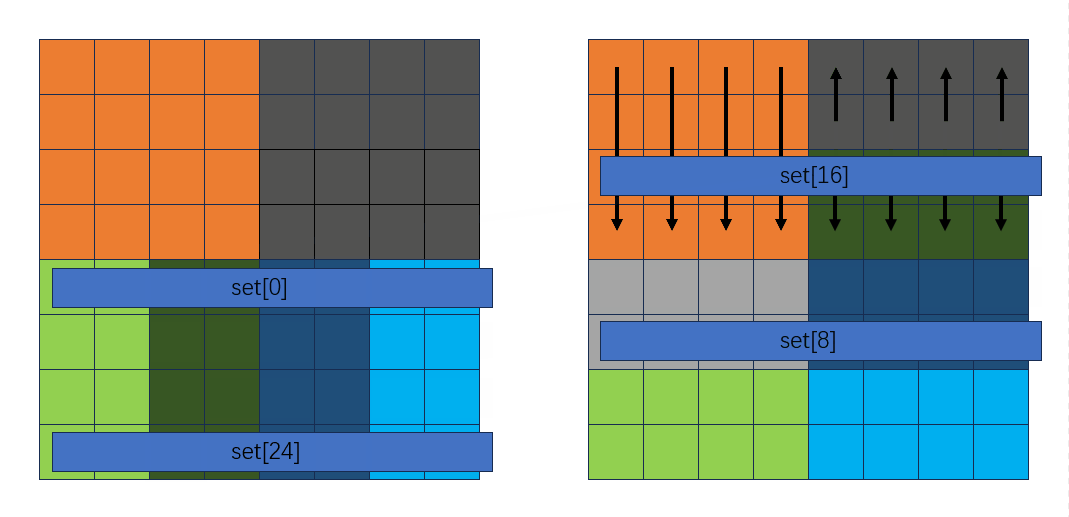
此时转置情况如下:
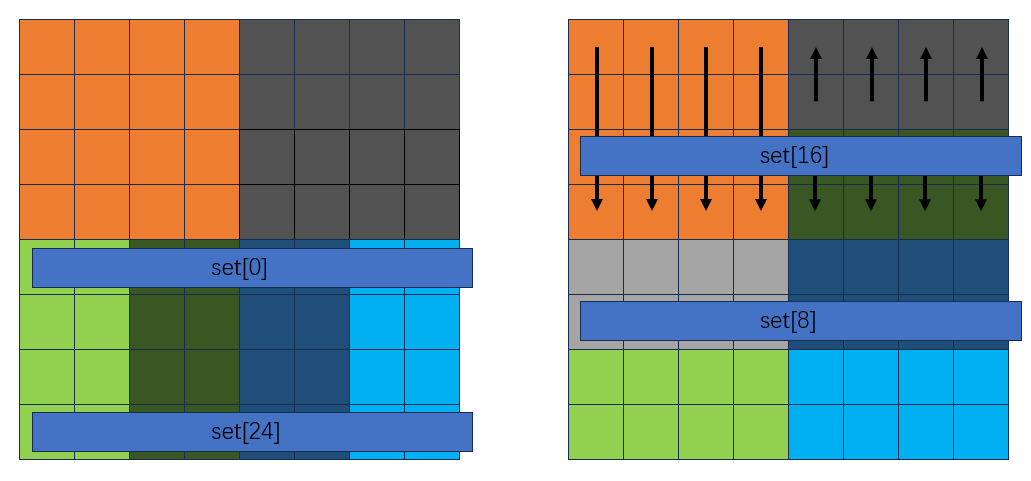
剩下的就不列举了,都是一样的过程,代码如下:
for (int i = 0; i < N; i += 8)
{
for (int j = 0; j < M; j += 8)
{
for (int k = i; k < i + 4; ++k)
{
// 读取A中的黄色块和灰色块
int t0 = A[k][j];
int t1 = A[k][j+1];
int t2 = A[k][j+2];
int t3 = A[k][j+3];
int t4 = A[k][j+4];
int t5 = A[k][j+5];
int t6 = A[k][j+6];
int t7 = A[k][j+7];
// 黄色块在B中正常转置
B[j][k] = t0;
B[j+1][k] = t1;
B[j+2][k] = t2;
B[j+3][k] = t3;
// 灰色块在B中灰色块位置逆序放置
B[j][k+4] = t7;
B[j+1][k+4] = t6;
B[j+2][k+4] = t5;
B[j+3][k+4] = t4;
}
for (int l = 0; l < 4; ++l)
{
// 由内到外按列读取A中绿色块和蓝色块
int t0 = A[i+4][j+3-l];
int t1 = A[i+5][j+3-l];
int t2 = A[i+6][j+3-l];
int t3 = A[i+7][j+3-l];
int t4 = A[i+4][j+4+l];
int t5 = A[i+5][j+4+l];
int t6 = A[i+6][j+4+l];
int t7 = A[i+7][j+4+l];
// 从下至上按行转换B中的灰色块到绿色块
B[j+4+l][i] = B[j+3-l][i+4];
B[j+4+l][i+1] = B[j+3-l][i+5];
B[j+4+l][i+2] = B[j+3-l][i+6];
B[j+4+l][i+3] = B[j+3-l][i+7];
// 将临时变量中存放的A中的绿色块和蓝色块B中的灰色块和蓝色块,完成转置
B[j+3-l][i+4] = t0;
B[j+3-l][i+5] = t1;
B[j+3-l][i+6] = t2;
B[j+3-l][i+7] = t3;
B[j+4+l][i+4] = t4;
B[j+4+l][i+5] = t5;
B[j+4+l][i+6] = t6;
B[j+4+l][i+7] = t7;
}
}
}
测试通过:
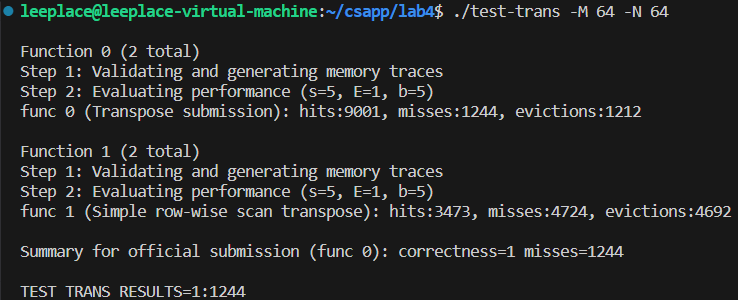
61 * 67
此时矩阵不是32或64的方阵,不会像之前一样隔4行或8行就映射到同一个缓存快,所以可以尝试一下依次利用更大的缓存,大胆一点全部用上,进行16 * 16分块,不过Aii和Bii还是会映射到同一个缓存快,还需要单独处理,用临时变量存放,代码如下:
for (int i = 0; i < N; i += 16)
{
for (int j = 0; j < M; j += 16)
{
for (int k = i; k < i + 16 && k < N; ++k)
{
int temp_position = -1;
int temp_value = 0;
int l;
for (l = j; l < j + 16 && l < M; ++l)
{
// 横坐标等于纵坐标,局部变量暂存,整个block读完再处理
if (l == k)
{
temp_position = k;
temp_value = A[k][k];
}
else
B[l][k] = A[k][l];
}
// 遇到了冲突元素
if (temp_position != -1)
B[temp_position][temp_position] = temp_value;
}
}
}
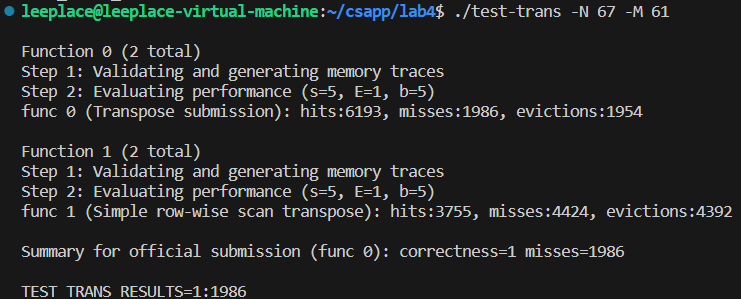
测试通过,正好卡在了2000线边缘:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java课程设计团队博客 —— 基于网页的时间管理系统
- 【数据结构 】哈夫曼编译码器
- 【IC设计】我爱运动,我爱乒乓!
- OpenCV图像处理实现手势识别贪吃蛇(含完整代码)
- Linux-CentOS7(无图形界面版)部署stable-diffusion-webui 全过程
- 【随笔】程序员必备的面试技巧,如何成为那个令HR们心动的程序猿!
- 自动化测试(终章)webdriver的常用api(2)以及新的开始
- 一、MOJO环境部署和安装
- C++ 蓝桥杯基础 数列特征
- 当我分别问8款GPT一个问题。。。