统计学-R语言-6.4
前言
本片是对以上三个介绍的篇章的题进行介绍。
总体均值的区间估计
1、利用下面的信息,构建总体均值μ的置信区间:
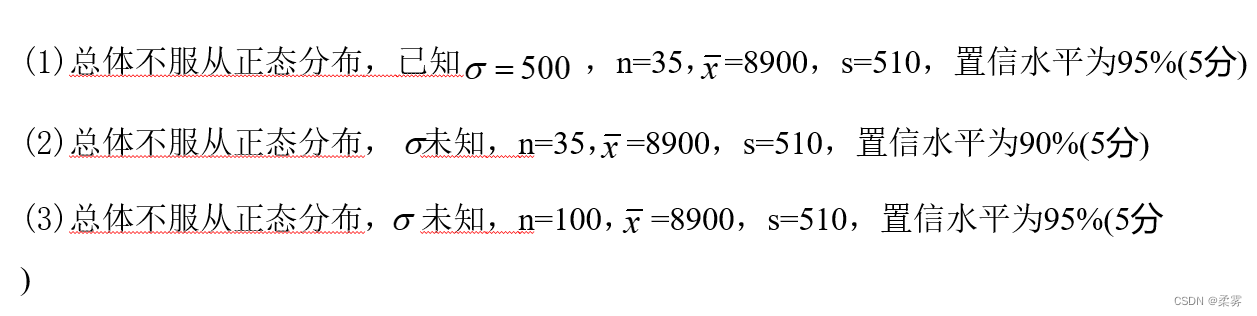
总体均值的区间估计(大样本的估计)

利用下面的信息,构建总体均值μ的置信区间:
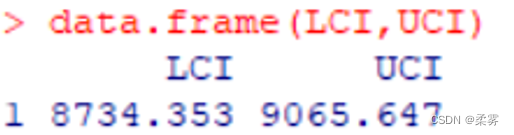
(1)总体不服从正态分布,已知 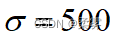 ,n=35, =8900,s=510,置信水平为95%
,n=35, =8900,s=510,置信水平为95%
q<-qnorm(0.975)
LCI<-8900-q*(500/sqrt(35))
UCI<-8900+q*(500/sqrt(35))
data.frame(LCI,UCI)
(2)总体不服从正态分布,  未知,n=35,
未知,n=35, 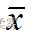 =8900,s=510,置信水平为90%
=8900,s=510,置信水平为90%
q<-qnorm(0.95)
LCI<-8900-q*(510/sqrt(35))
UCI<-8900+q*(510/sqrt(35))
data.frame(LCI,UCI)
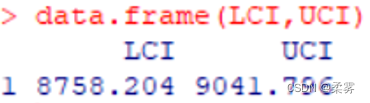
(3)总体不服从正态分布,  未知,n=100,
未知,n=100, 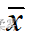 =8900,s=510,置信水平为95%
=8900,s=510,置信水平为95%
q<-qnorm(0.975)
LCI<-8900-q*(510/sqrt(100))
UCI<-8900+q*(510/sqrt(100))
data.frame(LCI,UCI)

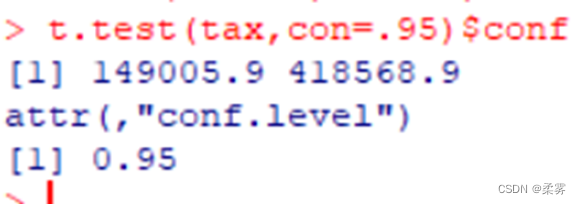
2、下面是10家企业2015年上半年缴税额数据(单位:元),根据这个样本对这类企业缴税额的总体均值𝝁做出区间估计,置信度取95%

该总体方差未知,小样本情形
假定该总体有正态分布。在R中采用下面的语句求出置信区间:
tax=c(283192,232600,51000,191927,16281,449066,673669,315000,293515,331624)
t.test(tax,con=.95)$conf #R语言内置函数t.test,t.test(x,conf.level=0.95)用于求95%置信区间#$conf用于获取置信度
[1] 149005.9 418568.9
attr(,"conf.level")#attr(x,which):得到或设置x的属性
[1] 0.95
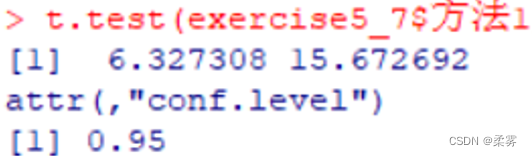
3、一家人才测评机构对随机抽取的10名小企业的经理人用两种方法进行自信心测试,得到的自信心测试分数如下:
构建两种方法平均自信心得分之差的95%的置信区间。
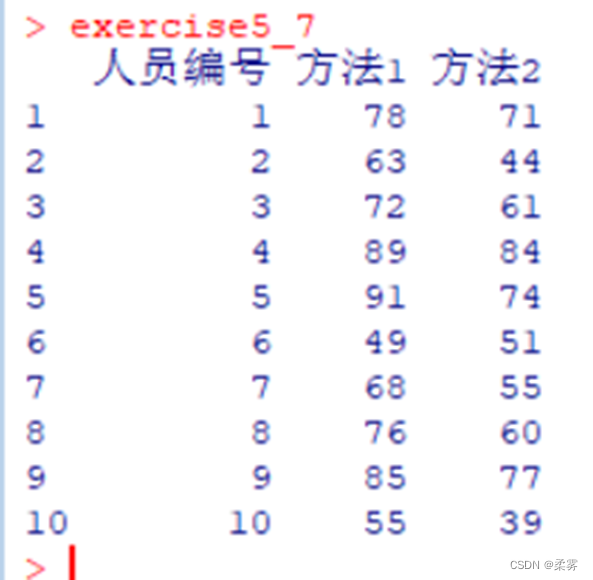
load("C:/example/ch5/exercise5_7.RData")
t.test(exercise5_7$方法1,exercise5_7$方法2,paired=TRUE)$conf.int
总体比例的区间估计
1、从两个总体中各抽取一个n1=n2=250的独立随机样本,来自总体1的样本比例为p1=40%,来自总体2的样本比例为p2=30%
(1)求 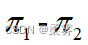 的90%的置信区间
的90%的置信区间
n1=250;n2=250
p1=0.4;p2=0.3
q1<-qnorm(0.95)
LCI<-p1-p2-q1*sqrt(p1*(1-p1)/n1+p2*(1-p2)/n2)
UCI<-p1-p2+q1*sqrt(p1*(1-p1)/n1+p2*(1-p2)/n2)
data.frame(UCI,LCI)
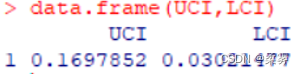
(2)求 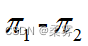 的95%的置信区间
的95%的置信区间
n1=250;n2=250
p1=0.4;p2=0.3
q2<-qnorm(0.975)
UCI<-p1-p2-q2*sqrt(p1*(1-p1)/n1+p2*(1-p2)/n2)
LCI<-p1-p2+q2*sqrt(p1*(1-p1)/n1+p2*(1-p2)/n2)
data.frame(LCI,UCI)
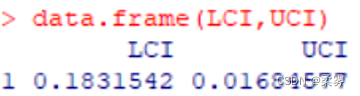
总体方差的区间估计
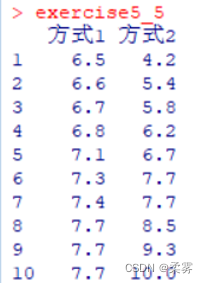
顾客到银行办理业务时住需要等待一些时间,而等待时间的长短与许多因素有关,比如银标的业务员办理业务的速度、顾客等待排队的方式等等。为此,某银行准备采取两种排队方式进行试验,第一种排队方式是所有顾客都进入一个等待队伍,第二种排队方式是顾客在三个业务ロ处列队三排等待为比较哪种排队方式使顾客等待的时间更短,银行各随机抽取10名顾客,他们在办理业务时所等待的时间(单位:分钟)如下
(1)构建第二种排队方式等待时间方差的95%的置信区间
library(TeachingDemos)
sigma.test(exercise5_5$方式2,conf.level=0.95)$conf.int

样本量的确定

确定合适的样本量需要综合考虑以下三因素:
(1)希望达到的置信度。置信度越高,要求样本量越大
(2)研究者可以承受的误差范围。最大可容许误差 (maximum allowable error)越小,要求样本量越大;反之,样本量越小
(3)所研究总体的标准差。如果总体的离散程度较高, 要求样本量较大;如果总体比较集中或一致,则要求的 样本量较小。然而,在通常的情况下我们并不知道总体标准差,因此必须对其进行估计。
1、青原博士对毕业生起薪进行调查。假设最大可容许误差E为100元,90%置信度所对应的z值为1.64485,即z0.05=1.64485,总体标准差的估计为2000元。需要多少样本量?
最大容许误差、总体标准差的估计以及z值都已知,将数据代入估计总体均值所需样本量的公式,可得样本量
z=qnorm(0.05,low=F)#计算z值
z
[1]1.64485
s=2000 #总体标准差
E=100#要求的最大可容许误差
n=(z*s/E)^2#计算所需样本量
n
[1] 1082.217
样本量计算的结果通常并不是整数。当出现这种情况时,取不小于该数的最小整数
对于此例,结果为1082.217,取样本量为1083。也这就是说样本量至少为1083个。
如果提高置信度到95%,在95%的置信度下对应的z值为
1.95996
z1=qnorm(0.025,low=F)#计算z值
n1=(z1*s/E)^2#计算所需样本量
n1
[1] 1536.584
此时的样本量取1537
置信度提高,则样本量应相应增大
具体来看,当置信度由95%提高到99%时,样本量增加280
这会大大增加调查的时间和成本,因此置信度的选择应该慎重
关于比例估计问题样本量的确定,与上面的过程基本 一致,也有三个因素需要确定:
(1)希望达到的置信度
(2)研究者可以承受的误差大小
(3)总体比例的估计
总体比例的样本量由下面的公式确定:
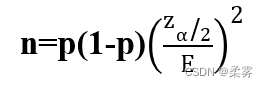

2、在延迟退休支持比例的调查中,假设最大可容许误差E为0 . 1 , 90 % 的置信度所对应的z值为1 . 64485 , 即 z0.05=1.64485,那么需要调查的样本量是多少?
z=qnorm(0.05,low=F)#计算z值
hat.p=0.5 #总体比例p的估计
E=0.1#要求的最大可容许误差
n=hat.p*(1-hat.p)*(z/E)^2#计算所需样本量
n
[1] 96.03647
解出n=96.03647。取大于它的最小整数, 得到n=97。
总结
以上就是本节的练习题介绍。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- GitHub访问慢:分享两个镜像加速网站
- 您没有专业应用组许可,请联系系统管理员分配许可!
- 力扣:56. 合并区间(贪心)
- 华硕天选大小核设置
- 1991-2022年A股上市公司股价崩盘风险指标数据
- 企业电子招投标系统源码之电子招投标系统建设的重点和未来趋势
- 传iPhone17 不会使用自研Wi-Fi芯片 | 百能云芯
- opengauss-高斯数据库的安装部署及MySQL数据迁移实战.
- 用MATLAB函数在图表中建立模型
- 动态规划问题--爬楼梯