Kubernetes网络-VXLAN

一. 网络基础
1. 计算机网络的分层
- 如今连接方式也越来也丰富,网线、WiFi、蓝牙、光纤,甚至我们普通的电线、照明所用的灯光,都可以作为接入网络的介质。如此庞大的网络,丰富多样的设备,计算机网络技术能把它们统一起来,管理得井井有条,与分层的核心思想有着紧密的联系。也正是因为计算机网络技术的分层思想因为分层,计算机网络通信协议通常是以栈的形式呈现的,即我们常说的协议栈, 也就是OSI(Open System Interconnection)七层模型, 而是结合实际,演化出一个更加简洁更容易理解模型,即现在最常说的TCP/IP四层模型
- 二层网络仅仅通过MAC寻址即可实现通讯,但仅仅是同一个冲突域内;三层网络需要通过IP路由实现跨网段的通讯,可以跨多个冲突域
2. VPN
- 虚拟专用网络(Virtual Private Network)技术, 主要是解决类似于我们想连接两套不同地域房子的网络的问题,例如一些大型跨地域企业或团队,也包括一些出差在外但希望像连接公司网络那样办公
3. Underlay和Overlay
-
Underlay网络是由各类物理设备构成,通过使用路由协议保证其设备之间的IP连通性的承载网络
-
Overlay网络是建立在Underlay网络上的逻辑网络, Overlay网络有着各种网络协议和标准,包括VXLAN、NVGRE、SST、GRE、NVO3、EVPN等
- 在Overlay网络中,设备之间可以通过逻辑链路,按照需求完成互联形成Overlay拓扑
- 相互连接的Overlay设备之间建立隧道,数据包准备传输出去时,设备为数据包添加新的IP头部和隧道头部,并且屏蔽掉内层的IP头部,数据包根据新的IP头部进行转发。当数据包传递到另一个设备后,外部的IP报头和隧道头将被丢弃,得到原始的数据包,在这个过程中Overlay网络并不感知Underlay网络
4. OSI七层模型

-
应用层
- 网络服务与最终用户的一个接口
- 协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
-
表示层
- 数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层)
- 格式有,JPEG、ASCll、EBCDIC、加密格式等 [2]
-
会话层
- 建立、管理、终止会话。(在五层模型里面已经合并到了应用层)
- 对应主机进程,指本地主机与远程主机正在进行的会话
-
传输层
- 定义传输数据的协议端口号,以及流控和差错校验
- 协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层, 最常用的80端口, 超文本传输协议
-
网络层
- 进行逻辑地址寻址,实现不同网络之间的路径选择, 最常用的IP地址
- 协议有:ICMP IGMP IP(IPV4 IPV6)
-
数据链路层
- 建立逻辑连接、进行硬件地址寻址、差错校验 [3] 等功能。(由底层网络定义协议)
- 将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。
-
物理层
- 建立、维护、断开物理连接。(由底层网络定义协议)
5. UDP
- User Datagram Protocol的简称, 中文名是用户数据报协议, 作用于四层的协议, 当报文发送之后,是无法得知其是否安全完整到达的, UDP报文没有可靠性保证、顺序保证和流量控制字段等,可靠性较差。但是正因为UDP协议的控制选项较少,在数据传输过程中延迟小、数据传输效率高,适合对可靠性要求不高的应用程序,或者可以保障可靠性的应用程序
- UDP报头由4个域组成,其中每个域各占用2个字节,具体包括源端口号、目标端口号、数据包长度、校验值
6. route
# 参数
-c 显示更多信息
-n 不解析名字
-v 显示详细的处理信息
-F 显示发送信息
-C 显示路由缓存
-f 清除所有网关入口的路由表
-p 与 add 命令一起使用时使路由具有永久性
add 添加一条新路由
del 删除一条路由
-net 目标地址是一个网络
-host 目标地址是一个主机
U Up表示此路由当前为启动状态
H Host,表示此网关为一主机
G Gateway,表示此网关为一路由器
R Reinstate Route,使用动态路由重新初始化的路由
D Dynamically,此路由是动态性地写入
M Modified,此路由是由路由守护程序或导向器动态修改
! 表示此路由当前为关闭状态
# 添加路由,直接使用route命令添加路由,一旦系统重启,配置的路由会消失, 在/etc/rc.local里添加
route add [-net|-host] target [netmask Nm] [gw Gw] [[dev] If]
route add -host 192.168.2.254 gw 192.168.3.254
7. 三次握手和四次挥手
-
握手
- 首先 Client 端发送连接请求报文
- Server 段接受连接后回复 ACK 报文,并为这次连接分配资源
- Client 端接收到 ACK 报文后也向 Server 段发生 ACK 报文,并分配资源,这样 TCP 连接就建立了。
-
挥手
- Clien发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
- Server收到FIN后,发送一个ACK给Client,Server进入CLOSE_WAIT状态。
- Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
- Client收到FIN后,Client进入TIME_WAIT状态,发送ACK给Server,Server进入CLOSED状态,完成四次握手。
二. k8s网络
(一). namespace
namespace的主要作用是封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源- k8s除了
time namespace没有使用到,其他namespace都有用到
| namespace | 说明 |
|---|---|
| cgroup | 控制进程使用的资源, 限制内存, cpu等, 内核 4.6添加的, 视图像宿主机一样以根形式来呈现 |
| ipc | 有自己的IPC,比如共享内存、信号量, 消息队列, posix message queues等, 隔离进程间通信 |
| network | 有自己的网络设备资源,包括网络协议栈(IPV4和IPV6协议栈)、网络设备、路由表、防火墙、端口, /proc/net 目录、/sys/class/net 目录、套接字(socket)等 |
| mount | 有自己的文件系统挂载点 |
| pid | 有自己的进程号,使得namespace中的进程PID单独编号,隔离pid, 实际是伪装 |
| time | 有自己的启动时间点信息和单调时间,比如可设置某个namespace的开机时间点为1年前启动,再比如不同的namespace创建后可能流逝的时间不一样, k8s没有使用到time namespace |
| user | 有自己的用户权限管理机制, 比如独立的UID/GID(用户/用户组),使得namespace更安全 |
| uts | 有自己的主机信息,包括主机名(hostname)、域名 |
# [4026534853] 中扩展中的是文件的inode号,如果两个容器进程的某个ns指向的是inode号是一样的,那就说明他们共享了同一个namespace,下面正式pause容器个业务容器共享的namespace信息, 同时这些文件都是硬链接
[root@xingguang ~]# ll /proc/4011221/ns/
total 0
lrwxrwxrwx 1 root root 0 Apr 27 11:14 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 ipc -> ipc:[4026534853]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 mnt -> mnt:[4026535201]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 net -> net:[4026534856]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 pid -> pid:[4026535347]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 pid_for_children -> pid:[4026535347]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 uts -> uts:[4026535346]
[root@xingguang ~]# ll /proc/4010952/ns/
total 0
lrwxrwxrwx 1 root root 0 Apr 27 11:14 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Apr 24 18:16 ipc -> ipc:[4026534853]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 mnt -> mnt:[4026534851]
lrwxrwxrwx 1 root root 0 Apr 24 18:16 net -> net:[4026534856]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 pid -> pid:[4026534854]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 pid_for_children -> pid:[4026534854]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Apr 27 11:14 uts -> uts:[4026534852]
(二). network namespace
1. ip netns 创建 network namespace
ip netns进入名称空间后可以用宿主机上的所有命令
# 查看程序的network的namespace的inode号
readlink /proc/1570493/ns/net
net:[4026532056]
# /var/run/netns/目录是是ip netns ls显示所有的network namespace, add mynet会在这个目录下生成一个挂载点
ip netns add mynet
# 查看有哪些network namespace
ip netns ls
# 当有了mynet名称空间,再进入网络名称空间,当进入mynet名称空间后,执行echo $$ 可以查看到这个名称空间在宿主机上的进程号, 也可以ip netns exec mynet echo $$获得pid
ip netns exec mynet bash
echo $$
# 查看回环网卡,发现还是DOWN状态
ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noqueue state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
# ping 127.0.0.1 是不通的
# 将down状态设置为up, 把设备打开后才可以通
ip link set dev lo up
# 获取namespace名字
ip netns identify ${pid}
# 同样unshare也可以创建并进入新的network namespace,但是namespace没有名字, 进入后执行echo $$也可以得到pid,unshare
unshare -n bash
# 删除network namespace,但是他只是移除了这个network namespace对应的挂载点,只要里面还有进程运行着,这个namespace就会一直存在(之前的Linux内核版本)
ip netns delete mynet
2. 维持namespace存在
- 上面的
ip netns等操作, 我们在创建一个新的名称空间后,得到一个pid, 当退出名称空间后,名称空间并不会删除, 当打开/proc/$$/ns/目录下的文件的时候,只要文件描述符保持open状态, 对应的namespace就会一直存在, 哪怕是namespace中的进程终止了(Linux内核黑科技) nsenter命令也可以这样执行
# 如下操作就是保持文件描述符处于open状态
# 创建一个新文件
touch /var/run/netns/mynet
# 创建名称空间并进入, unshare很像clone方法(netns其实就是实现clone方法),区别在于unshare作用在一个已存在的进程上,而clone会创建一个新的进程
unshare -n bash
echo $$
# 获得namespace的ID
readlink /proc/$$/ns/net
# 绑定挂载把当前进程的 network namespace 文件挂载mynet文件上,通过查看文件inode和namespace的ID是一样的,就算退出名称空间,文件的inode号也不会发生变化
mount -B /proc/$$/ns/net /var/run/netns/mynet
ll -i /var/run/netns/mynet
# 取消挂载, 如果/proc/self/ns/net目录
umount /var/run/netns/mynet
(三). veth pair
veth pair设备总是成对的, 常用于跨network namespace之间通讯, 其原理就是将veth pair的两端放在不同的namespace里, 任意一端接收数据,都会在另一端转发出去veth pair设备在转发过程中不会篡改数据包中的内容
mtu(Maximum Transmission Unit)是最大传输单元,用来通知对方所能接受数据服务单元的最大尺寸,说明发送方能够接受的有效载荷大小
# 创建veth pair,名字分别为veth0和veth1
ip link add veth0 type veth peer name veth1
# 查看,veth1@veth0, veth0@veth1很好的诠释了他们之间的关系,但是他们却是DOWN状态,mtu是1500, veth0和veth1设备都没有绑定ip地址
ip link list
23: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether b6:59:64:6f:de:8c brd ff:ff:ff:ff:ff:ff
24: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ca:04:6b:9b:ae:3c brd ff:ff:ff:ff:ff:ff
# 将两块网卡设备up
ip link set dev veth0 up
ip link set dev veth1 up
# 给设备配置ip地址
ifconfig veth0 10.0.0.10/24
# 或者这样可以配ip地址
ip addr add 10.0.0.10/24 dev veth0
ip addr add 10.0.0.11/24 dev veth1
# 给另一块设备放到network namespace中, mynet是上面创建的network namespace
ip link set veth1 netns mynet
1. 容器veth pair
- 容器中的
eth0设备实际上和宿主机上的某个veth是成对的(pair)关系
# 进入一个容器查看
cat /sys/class/net/eth0/iflink
21964
# 或者容器中
ip link show eth0
21963: eth0@if21964: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 00:00:00:8c:a9:66 brd ff:ff:ff:ff:ff:ff
# 或者在容器中ethtool -S eth0,列出veth pair对端的网卡, 如果容器没有这个命令可以nsenter
nsenter -t 4011221 -n ethtool -S eth0
NIC statistics:
peer_ifindex: 21964
rx_queue_0_xdp_packets: 0
rx_queue_0_xdp_bytes: 0
rx_queue_0_xdp_drops: 0
# 在这个容器所在的宿主机上
ip a | grep 21964
21964: f07cb212eb59_h@if21963: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master ovs-system state UP group default qlen 1000
# 或者
cat /sys/class/net/f07cb212eb59_h/iflink
21963
(四). Bridge
- Bridge(网桥),
veth pair可以让两个network namespace连接起来, 理论上k8s中的每一个pod都是独立的network namespace,这么多的名称空间,相互连接,veth pair就捉襟见肘了,这时候就需要Bridge了 Bridge是用于连接两个不同的局域网, 网桥是二层网络设备, 工作在数据链路层(Data Link), 主要功能是根据 MAC 地址来将数据包转发到网桥的不同端口(Port)上, Linux Bridge有多个端口, 数据可以从任何端口进来, 进来之后从哪个口出去取决于目的Mac地址, 原理和物理交换机差不多, Linux Bridge不能跨机连接网络设备
# 创建bridge
[root@xingguang ~]# ip link add name br0 type bridge
[root@xingguang ~]# ip link set br0 up
[root@xingguang ~]# ip a | grep br0
25: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
# 还可以这样创建
brctl addbr br0
- 当创建一个bridge时, 他是一个独立的网络设备, 只有1个端口连着协议栈,其他端口什么都没连接, 这样的bridge没有任何实际功能, 但是将
veth0绑定到bridge的br0的时候, bridge在veth0和协议栈之间做了一次拦截,将veth0本来要发给协议栈的数据拦截下来,全部转发给bridge, 同时bridge也可以向veth0发数据- br0的MAC地址变成了veth0的MAC
- br0个veth0连接起来,并且是双向通道
- 协议栈能发数据给veth0, veth0从外面收到的数据不会转发给协议栈
# 根据上面创建的veth pair, veth0和veth1, 并给他们绑定相应的ip地址,如果没有创建,则创建如下(ip地址根据服务器的物理网卡eth0同一网段就行)
ip link add veth0 type veth peer name veth1
ip addr add 10.0.0.10/24 dev veth0
ip addr add 10.0.0.11/24 dev veth1
ip link set dev veth0 up
ip link set dev veth1 up
# 根据上面创建的bridge,将veth pair的一端veth0绑定到br0上
ip link set dev veth0 master br0
# 或者用brctl命令来绑定
brctl addif br0 veth0
# 查看当前网桥有哪些网路设备
bridge link
# 或者brctl查看
brctl show
bridge name bridge id STP enabled interfaces
br0 8000.000000000000 no veth0
(五). tun/tap
- tun是tunnel(隧道)的缩写,
tun/tap设备的用处是将协议栈(处于内核空间)中部分数据包转发给用户空间的应用程序, 在操作系统内核和用户应用程序之间传递 IP 包, TUN 设备是一种虚拟网络设备
1. 网络设备
- 对于一个物理网卡来说,它的两端分别是内核协议栈和外面的物理网络,从内核协议栈接收到的数据会通过物理网络发送出去,通过物理网络接收到的数据会转发到内核协议栈进行处理, 而对于一个虚拟网卡来说,它的两端分别是内核协议栈和网络设备驱动(用户空间),从网络驱动接收到的数据会发送到内核协议栈,应用程序从内核协议栈发送过来的数据会发送到网络驱动,
tun/tap就是虚拟网卡- 物理网卡以比特流的方式传输数据,虚拟网卡则直接在内存中拷贝数据(即,在内核之间和读写虚拟网卡的程序之间传输), 所以,绝不可能通过虚拟网卡向外界发送数据,外界数据也不可能直接发送到虚拟网卡上。能够直接收发外界数据的,只能是物理设备, 但是,虚拟网卡可以将数据传输到本机的另一个网卡(虚拟网卡或物理网卡)或其它虚拟设备(如虚拟交换机)上, 那么就可以在用户空间运行一个可读写虚拟网卡的程序,该程序可将流经虚拟网卡的数据包进行处理,比如OpenVPN 程序
- 用户空间的程序是无法对数据包做任何封装和解封操作的,所有的封装和解封都只能由内核的网络协议栈来完成
- 用户空间是: 应用层, 表示层, 会话层
- 内核空间是: **传输层, 网络层, 数据链路层 **
- 硬件是: 物理层
2. 用户空间与内核空间的数据传输
-
从Linux角度看,
tun/tap设备是可以用文件句柄操作字符设备, 从网络虚拟化角度,他是虚拟网卡,一端连着网络协议栈,另一端连着用户态程序, 他的作用是可以TCP/IP协议栈处理好的网络包发送给任何一个使用tun/tap驱动的进程,由进程重新处理后发送到物理链路中 -
tun/tap驱动程序包括两个部分,一个是字符设备驱动,一个是网卡驱动。这两部分驱动程序分工不太一样,字符驱动负责数据包在内核空间和用户空间的传送,网卡驱动负责数据包在 TCP/IP 网络协议栈上的传输和处理, 在 Linux 中,用户空间和内核空间的数据传输有多种方式,字符设备就是其中的一种,tap/tun通过驱动程序和一个与之关联的字符设备,来实现用户空间和内核空间的通信接口, 设备文件即充当了用户空间和内核空间通信的接口。当应用程序打开设备文件时,驱动程序就会创建并注册相应的虚拟设备接口,一般以tunX或tapX命名。当应用程序关闭文件时,驱动也会自动删除tunX和tapX设备,还会删除已经建立起来的路由等信息,tap/tun设备文件就像一个管道,一端连接着用户空间,一端连接着内核空间。当用户程序向文件/dev/net/tun或/dev/tap0写数据时,内核就可以从对应的tunX或tapX接口读到数据,反之,内核可以通过相反的方式向用户程序发送数据- 在 Linux 内核 2.6.x 之后的版本中,tap/tun 对应的字符设备文件分别为:
- tap:/dev/tap0
- tun:/dev/net/tun
- 在 Linux 内核 2.6.x 之后的版本中,tap/tun 对应的字符设备文件分别为:
3 VPN原理
- tun设备用于VPN, 前提是两端公网必须是通的, VPN的server端实质就是作为网关

# 创建tun设备并绑定网卡
ip tuntap add dev tun0 mod tun
ifconfig tun0 192.168.188.11 netmask 255.255.255.0
(六). tunnel
- Linux 原生支持多种三层tunnel(隧道),其底层实现原理都是基于
tun设备, 可以通过命令ip tunnel help查看 IP 隧道的相关操作
# 可以看到有5中隧道模式
ip tunnel help
ipip:即IPv4 in IPv4,在 IPv4 报文的基础上再封装一个 IPv4 报文GRE:即通用路由封装(Generic Routing Encapsulation),定义了在任意一种网络层协议上封装其他任意一种网络层协议的机制,IPv4 和 IPv6 都适用sit:和ipip类似,不同的是sit是用 IPv4 报文封装 IPv6 报文,即IPv6 over IPv4ISATAP:即站内自动隧道寻址协议(Intra-Site Automatic Tunnel Addressing Protocol),和sit类似,也是用于 IPv6 的隧道封装vti:即虚拟隧道接口(Virtual Tunnel Interface),是 cisco 提出的一种IPsec隧道技术
1. ipip 隧道
ipip需要内核模块ipip.ko的支持,用modprobe ipip加载
[root@xingguang ~]# modprobe ipip
[root@xingguang ~]# lsmod | grep ipip
ipip 13465 0
tunnel4 13252 1 ipip
ip_tunnel 25163 1 ipip

# 上图为ipip隧道网络拓扑, 这里先创建2个network namespace
ip netns add ns1
ip netns add ns2
# 创建2对veth pair,并将另一端挂在某个namespace下
ip link add v1 type veth peer name v1_p
ip link add v2 type veth peer name v2_p
ip link set v1 netns ns1
ip link set v2 netns ns2
# 分别给两对veth-pair端点配上ip并启用
ip addr add 10.10.10.1/24 dev v1_p
ip addr add 10.10.20.1/24 dev v2_p
ip link set v1_p up
ip link set v2_p up
# 给2个network namespace添加上ip信息,并启用
ip netns exec ns1 ip a add 10.10.10.2/24 dev v1
ip netns exec ns1 ip link set v1 up
ip netns exec ns2 ip a add 10.10.20.2/24 dev v1
ip netns exec ns2 ip link set v2 up
# Linux本身就是一台路由器,可以通过 echo 1 >>/proc/sys/net/ipv4/ip_forward 来临时打开,永久打开如下
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
# 修改完后生效
sysctl -p
# 新建路由信息,让v1_p和v1_p设备互通,
ip netns exec ns1 route add -net 10.10.20.0 netmask 255.255.255.0 gw 10.10.10.1
ip netns exec ns2 route add -net 10.10.10.0 netmask 255.255.255.0 gw 10.10.20.1
# 可以在ns1中ping下
ip netns exec ns1 ping 10.10.20.2
# ns1中创建tun设备,绑定ip地址,并设置为up状态, 然后还需要设置隧道端点,用 remote 和 local 表示,这是隧道外层IP,对应的还有隧道内层IP,用 ip addr xx peer xx 配置
ip netns exec ns1 ip tunnel add tun1 mode ipip remote 10.10.20.2 local 10.10.10.2
ip netns exec ns1 ip link set tun1 up
ip netns exec ns1 ip addr add 10.10.100.10 peer 10.10.200.10 dev tun1
# ns2中创建tun设备,绑定ip地址,并设置为up状态.....
ip netns exec ns1 ip tunnel add tun2 mode ipip remote 10.10.10.2 local 10.10.20.2
ip netns exec ns1 ip link set tun2 up
ip netns exec ns1 ip addr add 10.10.200.10 peer 10.10.100.10 dev tun2

- IPIP隧道通信过程: 首先使用 ping 命令构建一个 ICMP 请求包,ICMP 包封装在 IP 包中,源IP地址为
tun1(10.10.100.10),目标IP地址为tun2(10.10.200.10), 由于 tun1 和 tun2 不在同一网段,所以会查路由表,当通过ip tunnel命令建立ipip隧道之后,会自动生成一条路由,如下,表明去往目的地10.10.200.10的路由直接从 tun1 出去 - 由于配置了隧道端点,数据包出了 tun1,到达 v1,根据
ipip隧道的配置,会封装上一层新的 IP 报头 ,源目的 IP 地址分别为v1(10.10.10.2)和v2(10.10.20.2), v1 和 v2 同样不在一个网段,同样查路由表(刚才新建了路由信息),发现去往10.10.20.0网段可以从10.10.10.1网关发出去 - Linux 打开了
ip_forward,相当于一台路由器,10.10.10.0和10.10.20.0是两条直连路由,所以直接查表转发,从 ns1 过渡到 ns2 - 数据包到达 ns2 的 v2,解封装数据包,发现内层 IP 报文的目的 IP 地址是
10.10.200.10,这正是自己配置的ipip隧道的 tun2 地址,于是就将报文交给 tun2 设备, 至此,tun1 的 ping 请求包就成功到达 tun2 - 由于 ICMP 报文的传输特性,有去必有回,所以 ns2 上会构造 ICMP 响应包,并根据以上相同步骤封装和解封装数据包,直至到达 tun1,整个 ping 过程完成
# ip tunnel命令建立 ipip 隧道后,会创建的路由信息
[root@xingguang ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1
10.10.200.10 0.0.0.0 255.255.255.255 UH 0 0 0 tun1
(七). 隧道网络: VXLAN
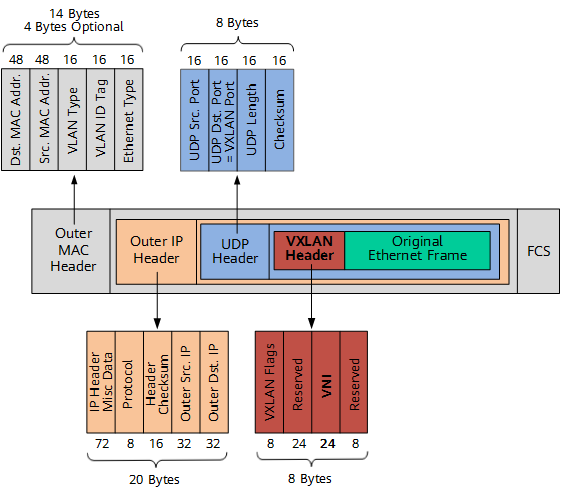
- VXLAN (Virtual eXtensible Local Area Network, 也就是是虚拟扩展局域网), 采用在源网络设备与目的网络设备之间建立一条逻辑VXLAN隧道,采用MAC in UDP(User Datagram Protocol)封装方式, 是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一, 是将L2的以太帧封装到UDP报文(即L2 over L4, UDP是位于L4中的)中,并在L3中传输(组播中的ARP协议) 是一种overlay(覆盖网络), 通过三层的网络搭建虚拟的二层网络, VXLAN是在底层underlay(物理网络, 底层物理网络是三层网络)之上使用的隧道技术, 依托UDP层构建的overlay的逻辑网络, 也就是将二层报文用三层协议进行封装, 可对二层网络在三层范围进行扩展
- VXLAN本质上在两台交换机之间构建了一条穿越基础IP网络的虚拟隧道,将IP基础网络虚拟成一个巨型二层交换机(可以识别数据中的MAC地址,根据MAC地址进行转发),即大二层网络, VXLAN 是用
VTEP(VXLAN Tunnel Endpoints) 将二层以太网帧封装在UDP中,一个VTEP可以被一个物理机上的所有 VM(或容器)共用,一个物理机对应一个VTEP。从交换机的角度来看,只是不同的VTEP之间在传递UDP数据,只需要记录与物理机数量相当的 MAC 地址表条目就可以了,一切又回到了和从前一样, VLAN tag 总共有 4 个字节, 其中有12 bit用来标识不同的二层网络(即LAN ID),故而最多只能支持2的12次方 ,即4096个子网的划分, 而 VXLAN 的报文 Header 预留了24 bit来标识不同的二层网络(即VNI,VXLAN Network Identifier),即 3 个字节,可以支持 2的24次方个子网- VTEP: VXLAN网络每个端点都有VTEP设备, 该设备负责VXLAN协议报文的封包和解包, VTEP可以是网络设备(比如交换机),也可以是一台机器(比如虚拟机集群中的宿主机)
- VNI是VXLAN 网络标识符,存在于VTEP设备通信报文头部中(VXLAN header), VNI是一种类似于VLAN ID的用户标识,一个VNI代表了一个租户,属于不同VNI的虚拟机之间不能直接进行二层通信, 它是 VTEP 设备识别某个数据帧是不是应该归自己处理的重要标识, VXLAN报文封装时,给VNI分配了24比特的长度空间,使其可以支持海量租户的隔离
- 大二层网络: 同一台二层交换机可以实现下挂服务器之间的二层通信,而且服务器从该二层交换机的一个端口迁移到另一个端口时,IP地址是可以保持不变的, 这样就可以满足容器网络的需求, VXLAN的设计理念和目标正是由此而来的
- 报文说明
- VXLAN的报文是MAC in UDP, 这就是在三层网络的基础上虚拟一个二层网络的由来, 原始二层以太帧(Original L2 Frame)报文经过
VTEP时候 - VXLAN Header, (VXLAN头部信息,8个字节),其中包含24比特的
VNI字段,用来定义VXLAN网络中不同的租户, 此外,还包含VXLAN Flags(8比特,取值为00001000)和两个保留字段(分别为24比特和8比特) - UDP Header, 那么
VXLAN Header和原始以太帧一起作为UDP的数据了, 这就是MAC in UDP的说法来源,UDP Header中,目的端口号VXLAN Port, 也就是接收方VTEP设备的端口, 源端口号(UDP Src. Port)是原始以太帧通过哈希算法计算后的值 - Outer IP Header(外层IP头), 其中,源IP地址(Outer Src. IP)为源容器所属VTEP的IP地址(容器是有自己独立的MAC地址和IP地址),目的IP地址(Outer Dst. IP)为目的容器(或VM)所属VTEP的IP地址
- Outer MAC Header(外层MAC头), 其中,源MAC地址(Src. MAC Addr.)为源容器所属VTEP的MAC地址,目的MAC地址(Dst. MAC Addr.), 为到达目的VTEP的路径中下一跳设备的MAC地址
- 对端VTEP接收到VXLAN报文后(Outer IP Header和Outer MAC Header指引对端是谁), 拆除
UDP Header, 就会根据VXLAN头部的VNI把原始报文发送到目的容器
- VXLAN的报文是MAC in UDP, 这就是在三层网络的基础上虚拟一个二层网络的由来, 原始二层以太帧(Original L2 Frame)报文经过
- FCS 帧尾, 数据链路层协定数据单元的尾部栏位
1. 网络结构层级
- 二层、三层网络是按照逻辑拓扑结构进行的分类,并不是说ISO七层模型中的数据链路层和网络层,而是指核心层,汇聚层和接入层,这三层都部署的就是三层网络结构,二层网络结构没有汇聚层
- 只有核心层和接入层的二层网络结构模式运行简便,交换机根据MAC地址表进行数据包的转发,有则转发,无则泛洪,即将数据包广播发送到所有端口,如果目的终端收到给出回应,那么交换机就可以将该MAC地址添加到地址表中,这是交换机对MAC地址进行建立的过程, 但这样频繁的对未知的MAC目标的数据包进行广播,在大规模的网络架构中形成的网络风暴是非常庞大的,这也很大程度上限制了二层网络规模的扩大,因此二层网络的组网能力非常有限,所以一般只是用来搭建小局域网
- 三层网络则需要通过IP路由实现跨网段的通讯,可以跨多个冲突域, 只要是三层可达的网络, (也就是能够通过IP互相通信), 就能部署VXLAN
- 核心层是整个网络的支撑脊梁和数据传输通道,重要性不言而喻,因此在整个三层网络结构中,核心层的设备要求是最高的,必须配备高性能的数据冗余转接设备和防止负载过剩的均衡负载的设备,以降低各核心层交换机所需承载的数据量。(网络的高速交换主干)
- 汇聚层是连接网络的核心层和各个接入的应用层,在两层之间承担“媒介传输”的作用。汇聚层应该具备以下功能:实施安全功能(划分 VLAN和配置 ACL)、工作组整体接入功能、虚拟网络过滤功能。因此,汇聚层设备应采用三层交换机。(提供基于策略的连接)
- 接入层的面向对象主要是终端客户,为终端客户提供接入功能
2. VXLAN通信过程

- 当处于同一个VXLAN的两台虚拟终VM(或容器)的时候, 发送方给接收方发送数据帧,因为数据发送方是一层一层封装的, 当到达L2的时候, 报文数据就有
DATA、传输层头部信息 、IP Header、MAC Header, 这里将这些原始报文信息用Original L2 Frame表示- 问题一: 原始数据报文中
IP Header是已经知道的, 但是MAC Header的目的MAC地址是不知道的, 需要VXLAN的机制来实现ARP(地址解析, 根据IP来获得MAC)的功能
- 问题一: 原始数据报文中
- 这时发送方连接的VTEP设备收到了数据帧,通过查找发送方所在的VXLAN以及接收方所连接的VTEP设备,将该
Original L2 Frame报文增加VXLAN Header、UDP Header、Outer IP Header、Outer MAC Header报文(VXLAN网络特性, 会封装报文), 会根据Outer IP Header、Outer MAC Header报文来确定源和目的VTEP设备的IP地址和MAC地址, 根据UDP Header来确定源和目的VTEP设备端口, 从而准确发送给目的VTEP设备- :
UDP Header中最重要的是VTEP设备的端口, 源端口是由系统生成并管理的, 目的端口是IANA(Internet Assigned Numbers Authority, 互联网号码分配局)分配的4789固定端口 - 问题二:
Outer IP Header中VTEP设备源地址可以用很简单的方式确定, 目的地址是VM(或容器)所在宿主机VTEP的IP地址,却需要由某种方式来确定 - 问题三: 如果
UDP Header中的VNI也是动态感知的, 该怎么获取VNI信息
- :
- 目的VTEP设备接收到报文后,此时报文只有
Original L2 Frame、VXLAN Header, 这时目的VTEP设备会检查VXLAN Header报文中的VNI信息, 以及Original L2 Frame中的MAC Header中源和目的MAC地址, 从而确认接收方VM(或容器)与本VTEP设备相连后,拆除VXLAN Header,将Original L2 Frame交给接收方VM(或容器) - 接收方VM(或容器)收到数据帧,传输完成,整个数据传输过程就完成了, 但是上面的三个问题如何实现,就成为了VXLAN所要解决的问题, 也就是MAC, VTEP IP和VNI
3. VXLAN网络创建
(1). 点对点VXLAN
- 点对点实际用处不大,做原理的引入
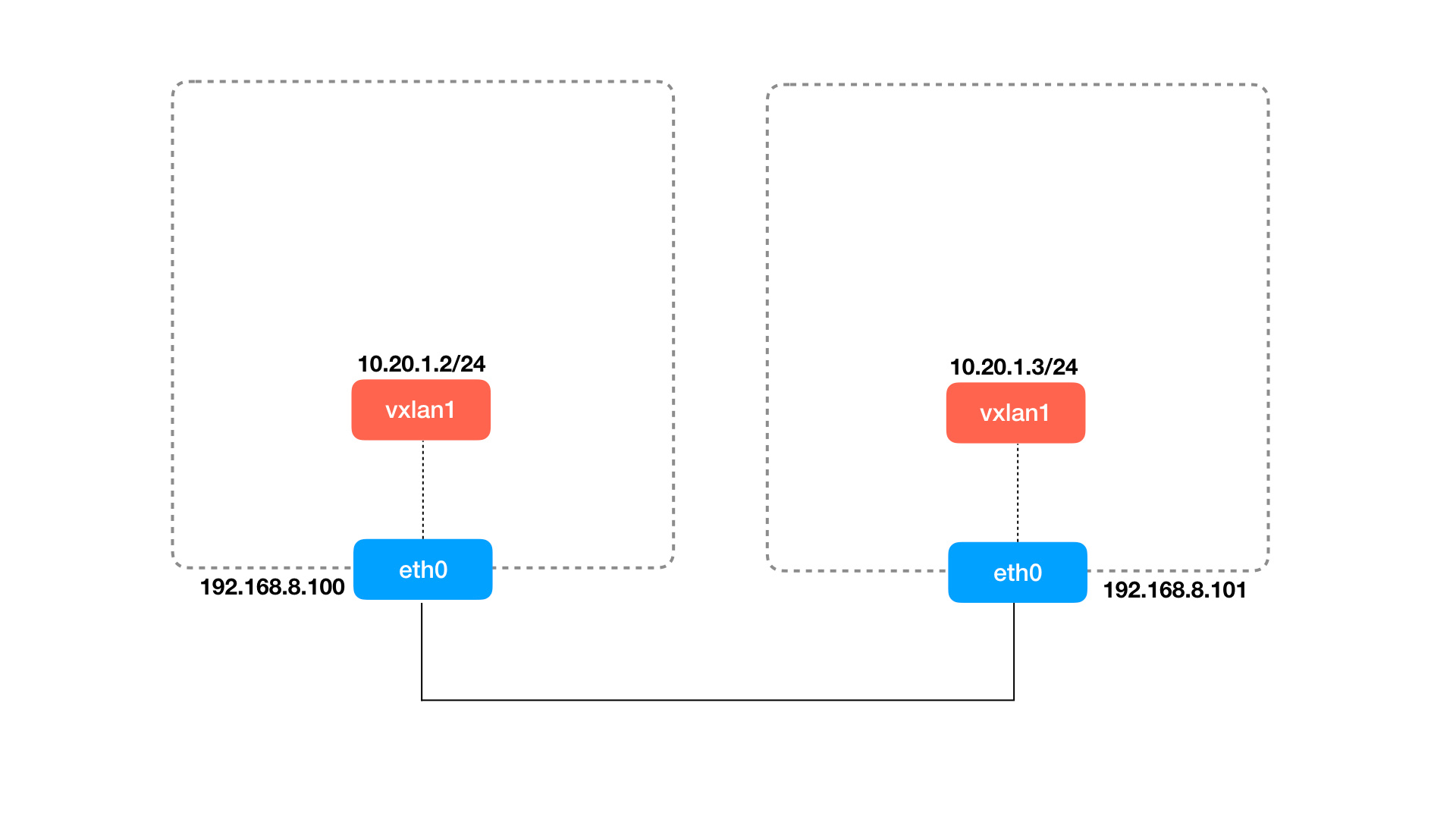
# 创建vxlan1设备,也可以说成创建VTEP设备
[root@xingguang ~]# ip link add vxlan1 type vxlan id 4 dstport 4789 remote 192.168.8.101 local 192.168.8.100 dev eth0
# 查看vxlan1信息
[root@xingguang ~]# ip -d link show vxlan1
26: vxlan1: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6a:46:a4:02:08:64 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 4 group 239.1.1.1 dev eth0 srcport 0 0 dstport 4789 ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# 如果要删除使用通用的删除接口方式
[root@xingguang ~]# ip link delete vxlan1
# 为vxlan1网卡配置IP地址,并改为UP状态
ip addr add 10.20.1.2/24 dev vxlan1
ip link set vxlan1 up
# 上面2步执行成功后,路由表多了下面的内容, 所有目的地址是10.20.1.0/24网段的包要经过vxlan1转发
[root@xingguang ~]# ip route
10.20.1.0/24 dev vxlan1 proto kernel scope link src 10.20.1.2
# 同时,vxlan1 fdb表项中的内容, 这个表项的意思是说,默认的而 vtep 对端地址为 192.168.8.101,换句话说,如果接收到的报文添加上 vxlan 头部之后都会发到 192.168.8.101
[root@xingguang ~]# bridge fdb
00:00:00:00:00:00 dev vxlan1 dst 192.168.8.101 via enp0s8 self permanent
# 同时在另外一台服务器192.168.8.101上也进行相同的配置,要保证VNI也是相同的也是4,dstport相同也是4789,并修改vtep的地址和remote IP地址到相应的值,然后测试两台vtep是否通, 在192.168.8.100上ping
[root@xingguang ~]# ping 10.20.1.3
- 上面这条命令创建一个名字为
vxlan1,类型为vxlan的网络 interface,后面是 vxlan interface 需要的参数:- dev eth0意思是当节点用于VTEP通信的网卡设备,用来获取VTEP IP地址, 注意这个参数和
local参数含义是相同的,二选一即可 - id 4是指定 VNI 的值,这个值可以在 1 到 2^24 之间
- dstport 4789是指vtep 通信的端口,如果不指定Linux 默认使用 8472(为了保持兼容,默认值一直没有更改),而 IANA 分配的端口是 4789,所以我们这里显式指定了它的值
- remote 192.168.8.101表示对方 vtep 的地址,类似于点对点协议
- local 192.168.8.100表示当前节点 vtep 要使用的 IP 地址
- vxlan1是VXLAN的接口, 也就是VTEP设备
- dev eth0意思是当节点用于VTEP通信的网卡设备,用来获取VTEP IP地址, 注意这个参数和
(2). 多播VXLAN
- 多播也叫组播, 多点广播或群播, 指把信息同时传递给一组目的地址。它使用策略是最高效的,因为消息在每条网络链路上只需传递一次,而且只有在链路分叉的时候,消息才会被复制, 它还常用来与RTP等音视频协议相结合, 组播报文的目的地址使用D类IP地址, D类地址不能出现在IP报文的源IP地址字段, 多播主要是通过ARP洪泛来学习MAC地址, 在overlay网络数量比较多时也会很麻烦,多播也会导致大量的无用报文在网络中出现
- ARP洪泛, 也就是在VXLAN子网广播ARP请求, 然后对应节点进行响应
- 如果VXLAN要使用多播模式,那么底层的网络结构需要支持多播的功能,幸运的是,
virtualbox本身就支持多播,不需要额外设置, 但是不是所有的网络都支持多播, 再加上多播方式带来的报文浪费,实际生产中VXLAN的多播模式也很少被采用 - 要组成同一个VXLAN网络,VTEP必须能感知到彼此的存在, 多播组本来的功能就是把网络中的某些节点组成一个虚拟的组,通过多播组成一个虚拟的整体, 所以VXLAN最初想到用多播来实现是很自然的事情
- 隧道网络发送报文最关键的是要知道对方容器的MAC地址及所在的宿主机的VTEP IP地址, 对 overlay 网络来说,它的网段范围是分布在多个主机上的,因此传统 ARP 报文的广播无法直接使用, 要想做到 overlay 网络的广播,必须把报文发送到所有VTEP在的节点,这才引入了多播

[root@xingguang ~]# ip link add vxlan1 type vxlan id 4 group 239.1.1.1 dstport 4789 dev eth0
# 查看vxlan1信息
[root@xingguang ~]# ip -d link show vxlan1
26: vxlan1: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6a:46:a4:02:08:64 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 4 group 239.1.1.1 dev eth0 srcport 0 0 dstport 4789 ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# 查看vxlan1的转发表,这个规则是在创建vxlan1接口就会自动创建,和点对点的VXLAN不一样, dst地址变成了多播地址239.1.1.1,而不是VTEP地址
[root@xingguang ~]# bridge fdb show dev vxlan1
00:00:00:00:00:00 dst 239.1.1.1 via eth0 self permanent
# 为vxlan1网卡配置IP地址,并改为UP状态
ip addr add 10.20.1.2/24 dev vxlan1
ip link set vxlan1 up
# 上面2步执行成功后,路由表多了下面的内容, 所有目的地址是10.20.1.0/24网段的包要经过vxlan1转发
[root@xingguang ~]# ip route
10.20.1.0/24 dev vxlan1 proto kernel scope link src 10.20.1.2
# 和点对点模式一样,对所有需要通信的服务器节点上进行以上配置,然后ping VTEP IP地址,验证是否可以互相通信
[root@xingguang ~]# ping 10.20.1.3
-
上面命令是多播模式的VXLAN, 创建一个vxlan1的interface, 它使用在eth0的多播组239.1.1.1, 初始化时没有转发表
- group 239.1.1.1表示把 VTEP设备加入到这个多播组
-
配置完成后, VTEP通过 IGMP(Internet Group Management Protocol, 因特网组管理协议,是TCP/IP协议族中负责IP组播成员管理的协议,用来在接收者和与其直接相邻的组播路由器之间建立、维护组播组成员关系) 加入同一个多播网络239.1.1.1
- 主机一(192.168.8.100)发送 ping 报文到 10.20.1.3,查看路由表,报文会从该主机的vxlan1发出去, 内核发现源地址和目的IP地址是在同一个局域网内,需要知道对方的MAC地址,而本地又没有缓存,故先发送一个ARP查询报文( ARP,即地址解析协议,根据IP地址解析为MAC地址的协议, 工作在L3网络层,)
- ARP 报文源 MAC 地址为主机一上vxlan1的 MAC 地址,目的 MAC 地址为225.225.225.225(广播地址), 并根据配置添加VNI=4的VXLAN Header, 因为不知道对端VTEP在哪台主机上,但是又配置了多播组, 根据配置, VTEP会向多播地址239.1.1.1发送多播报文, 所以多播组中所有的主机都会收到这个报文, 内核发现是VXLAN的报文, 就会根据VNI发送给对应的VTEP设备
- 此时报文到达了主机二上时, 主机二的VTEP拆掉
VXLAN Header, 取出真正的ARP请求报文, 同时VTEP会记录MAC地址和IP地址信息, 到FDB表(二层MAC地址表)中, 这便实现了一次学习的过程, 如果发现报文ARP不是发送给自己的, 则直接丢弃, 如果是, 则生成ARP应答报文 - 应答报文目的 MAC 地址是发送方VTEP的 MAC 地址,而且VTEP已经通过源报文学习到了VTEP所在主机的MAC地址,因此会直接单播发送给目的VTEP, 因此VTEP不需要多播发送,就能填充所有的头部信息
- 应答报文通过
underlay网络直接返回给发送方主机,发送方主机根据 VNI 把报文转发给 VTEP,VTEP解包取出 ARP 应答报文,添加 ARP 缓存中, 并根据报文学习到目的 VTEP所在的主机地址,添加到FDB表中 - VTEP双方(隧道网络双方)已经通过一次ARP报文, 知道了ICMP通信需要的所有信息,在这个过程中,一个VXLAN网络的ping报文要经历ARP寻址 + ICMP响应两个过程, 当然VTEP设备学习到对方的ARP地址后, 就可以免去ARP寻址过程, 所以后续 ICMP 的 ping 报文都是单播进行的
4. VXLAN + bridge
- 尽管上面的方法能够通过多播实现自动化的
overlay网络构建,但是通信的双方只有一个VTEP,在实际的生产中,每台主机上都有几十台甚至上百台的虚拟机或者容器需要通信,Linux网桥可以连接多快虚拟网卡, 因此能够把这些通信实体组织起来, 在 Linux 中把同一个网段的 interface 组织起来正是网桥(bridge,或者 switch,这两个名称等价)的功能,因此该如何用网桥把多个虚拟机或者容器放到同一个VXLAN Overlay 网络中?
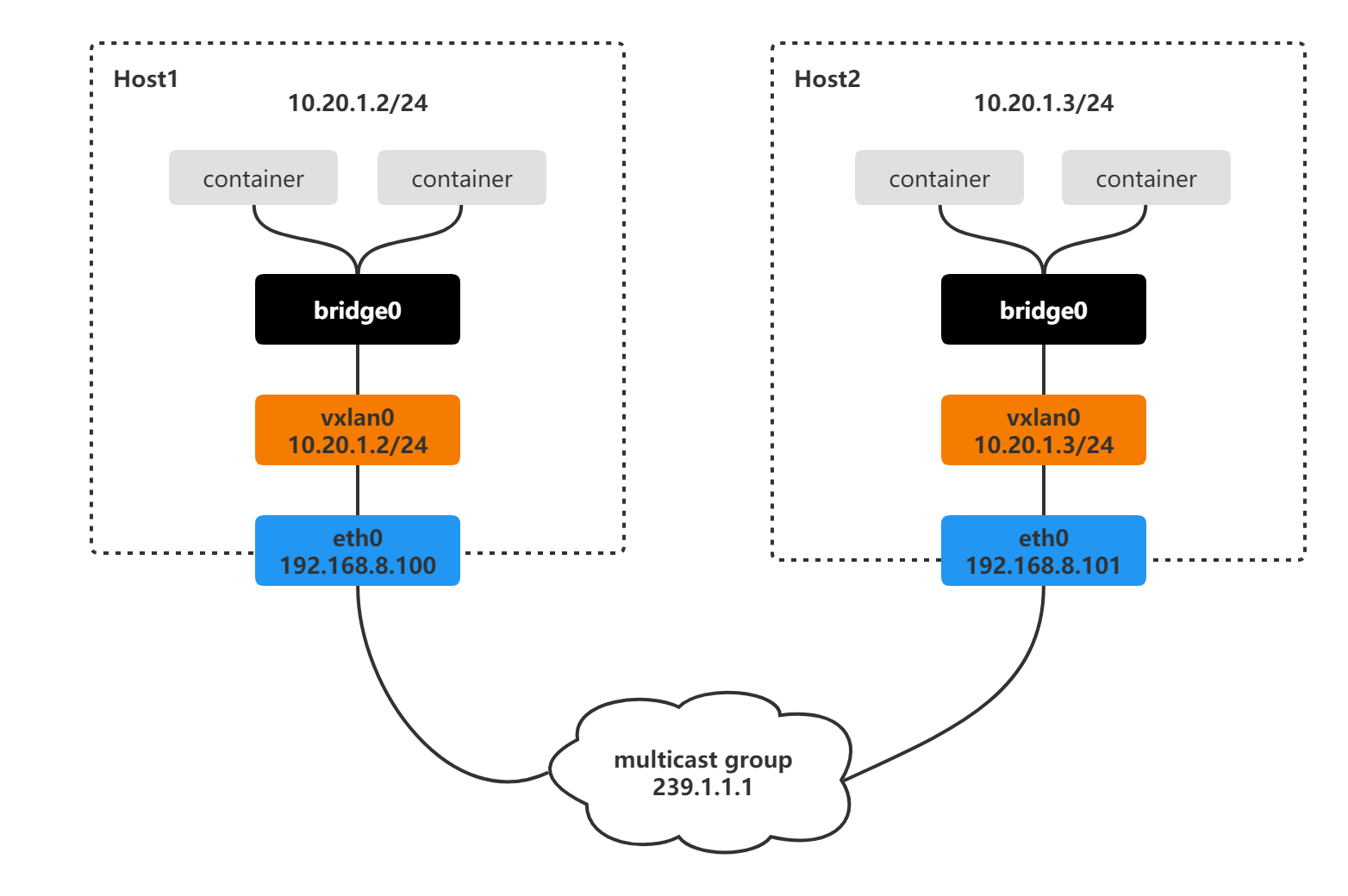
- 和前面的多播VXLAN差不多,只是多了一个网桥, 然后网桥连接同一个主机上不同容器的
veth pair的其中一端
# 前面的多播VXLAN创建过程略,创建bridge,up并绑定到bridge0上
ip link add bridge0 type bridge
ip link set vxlan0 master bridge0
ip link set vxlan0 up
ip link set bridge0 up
# 创建network namespace和一对veth pair, 并veth pair其中一端绑定到网桥,另一端放在network namespace并绑定IP地址(也是容器的IP地址)
ip netns add container1
ip link add veth0 type veth peer name veth1
ip link set dev veth0 master bridge0
ip link set dev veth0 up
# 配置容器内部的网络和IP
ip link set dev veth1 netns container1
ip netns exec container1 ip link set lo up
ip netns exec container1 ip link set veth1 name eth0
ip netns exec container1 ip addr add 10.20.1.2/24 dev eth0
ip netns exec container1 ip link set eth0 up
# 其他的host也用同样的方法配置VXLAN网络
- 所有主机配置完成后, 从10.20.1.2的容器ping 10.20.1.3, 整个通信过程和前面的过程类似, 只不过容器发出的ARP报文会先经过网桥,再转发给vxlan0, 然后在vxlan0处由Linux内核添加
VXLAN Header, 最后通过多播的方式查询通讯对端的MAC地址 - 逻辑上VXLAN网络下不通主机上的network namespace中的网卡被连接到了同一个网桥上,实现跨主机通信
5. FDB和ARP表
(1). 自维护VTEP组
- 隧道网络发送报文最关键的是要知道对方容器的MAC地址及所在的宿主机的VTEP IP地址, 对 overlay 网络来说,它的网段范围是分布在多个主机上的,传统 ARP 报文的广播无法直接使用, 要想做到 overlay 网络的广播,必须把报文发送到所有VTEP在的节点,但是如果能够事先知道MAC地址和VTEP IP信息,直接发送给对端VTEP, 是不是就可以不用多播了呢? 而且多播会浪费报文, 如果有一种方法能够不通过多播,能把 overlay 的广播报文发送给所有的 VTEP 主机的话,也能达到相同的功能, 当然在维护VTEP网络组之前,必须提前知道哪些VTEP要组成一个网络,以及这些VTEP在哪些主机上
- Linux 的VXLAN模块也提供了这个功能,而且实现起来并不复杂, 创建VTEP interface的时候不使用
remote或者group参数就行
# 这个在192.168.8.100上创建
[root@xingguang ~]# ip link add vxlan0 type vxlan id 4 dstport 4789 dev eth0
- 这个VTEP interface创建的时候没有指定多播地址,当第一个 ARP 请求报文发送时它也不知道要发送给谁, 但是我们可以手动添加默认的 FDB 表项来告诉他, 这样的话,如果不知道对方 VTEP 的地址,就会往选择默认的表项,发到
192.168.8.101和192.168.8.102,相当于手动维护了一个 VTEP 的多播组, 在所有的节点的 VTEP 上更新对应的 FDB 表项,就能实现 overlay 网络的连通, 整个通信流程和多播模式相同,唯一的区别是,VTEP 第一次会给所有的组内成员发送单播报文,当然也只有一个 VTEP 会做出应答, 这个过程当然可以用一些自动化工具实现
[root@xingguang ~]# bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
[root@xingguang ~]# bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102
- 但是这个方案解决了在某些 underlay 网络中不能使用多播的问题,但是并没有解决多播的另外一个问题:每次要查找 MAC 地址要发送大量的无用报文,如果 VTEP 组节点数量很大,那么每次查询都发送 N 个报文,其中只有一个报文真正有用
(2). 自维护FDB表
- 自维护VTEP组, 还是产生大量的无用报文, 如果提前知道目的容器 MAC 地址和它所在主机的 IP 地址,也可以通过更新 FDB 表项来减少广播的报文数量
# 换成nolearning参数,这个参数告诉VTEP不要通过收到的报文学习FDB表内容,因为我们自己进行维护,添加规则
[root@xingguang ~]# ip link add vxlan0 type vxlan id 4 dstport 4789 dev nolearning
# 在原来基础上添加FDB规则, 说明: 52:5e:55:58:9a:ab这个MAC地址是对端192.168.8.101宿主机上的VTEP的mac地址,通过ip -d link show vxlan0 可获得, 其他同理
[root@xingguang ~]# bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
[root@xingguang ~]# bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102
[root@xingguang ~]# bridge fdb append 52:5e:55:58:9a:ab dev vxlan0 dst 192.168.8.101
[root@xingguang ~]# bridge fdb append d6:d9:cd:0a:a4:28 dev vxlan0 dst 192.168.8.102
(3). 自维护ARP表
- 除了维护 FDB 表,ARP表也是可以维护的, 如果能通过某个方式知道容器的 IP 和 MAC 地址对应关系,只要更新到每个节点,就能实现网络的连通, 但是这里有个问题,我们需要维护的是每个容器里面的 ARP 表项,因为最终通信的双方是容器。到每个容器里面(所有的 network namespace)去更新对应的 ARP表,是件工作量很大的事情,而且容器的创建和删除还是动态的,Linux 提供了一个解决方案,VTEP可以作为 ARP 代理,回复 ARP 请求,也就是说只要 VTEP interface 知道对应的
IP 和 MAC关系,在接收到容器发来的 ARP 请求时可以直接作出应答。这样的话,我们只需要更新 VTEP interface 上 ARP 表项就行了 - 配置完如下, 当容器要访问彼此,并且第一次发送 ARP 请求时,这个请求并不会发给所有的 VTEP,而是当前由当前 VTEP做出应答需要将报文发给谁,大大减少了网络上的报文
# 这条命令和上部分相比多了 proxy 参数,这个参数告诉 VTEP 承担 ARP 代理的功能, 如果收到 ARP 请求,如果自己知道结果就直接作出应答
[root@xingguang ~]# ip link add vxlan0 type vxlan id 4 dstport 4789 dev eth0 nolearning proxy
# 和上面一样,需要手动更新FDB表
[root@xingguang ~]# bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
[root@xingguang ~]# bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102
[root@xingguang ~]# bridge fdb append 52:5e:55:58:9a:ab dev vxlan0 dst 192.168.8.101
[root@xingguang ~]# bridge fdb append d6:d9:cd:0a:a4:28 dev vxlan0 dst 192.168.8.102
# 还需要为 VTEP 添加 ARP 表项,所有要通信容器的 IP - MAC二元组都要加进去,这个在所有要通信的节点都需要加
[root@xingguang ~]# ip neigh add 10.20.1.2 lladdr 52:5e:55:58:9a:ab dev vxlan0
[root@xingguang ~]# ip neigh add 10.20.1.3 lladdr d6:d9:cd:0a:a4:28 dev vxlan0
(4). 动态FDB和ARP表
-
自维护ARP表, 虽然可以减少多余报文, 但还有问题: 为了能够让所有的容器正常工作,所有可能会通信的容器都必须提前添加到 ARP 和 FDB表项中, 但并不是网络上所有的容器都会互相通信,所以添加的有些表项(尤其是 ARP 表项)是用不到的
-
Linux 提供了另外一种方法,内核能够动态地通知节点要和哪个容器通信,应用程序可以订阅这些事件,如果内核发现需要的 ARP 或者 FDB 表项不存在,会发送事件给订阅的应用程序,这样应用程序从中心化的控制拿到这些信息来更新表项,做到更精确的控制, 要收到 L2(FDB )miss,必须要满足几个条件:
- 目的 MAC 地址未知,也就是没有对应的 FDB 表项
- FDB 中没有全零的表项,也就是说默认规则
- 目的 MAC 地址不是多播或者广播地址
# 每个宿主机都创建,l2miss:如果设备找不到 MAC 地址需要的 VTEP 地址,就发送通知事件, l3miss:如果设备找不到需要 IP 对应的 MAC 地址,就发送通知事件
[root@xingguang ~]# ip link add vxlan0 type vxlan id 4 dstport 4789 dev eth0 nolearning proxy l2miss l3miss
# ip monitor 命令能做到这点,监听某个 interface 的事件, 如果从当前节点容器中 ping 另外一个节点的容器,就先发生 l3 miss,这是 l3miss 的通知事件
[root@xingguang ~]# ip monitor all dev vxlan0
[nsid current]miss 10.20.1.3 STALE
# l3miss 是说这个 IP 地址,VTEP 不知道它对应的 MAC 地址,因此要手动添加 arp 记录, nud reachable 参数意思是,这条记录有一个超时时间,系统发现它无效一段时间会自动删除, 这样的好处是,不需要手动去删除它,删除后需要通信内核会再次发送通知事件, nud 是 Neighbour Unreachability Detection 的缩写, 当然根据需要这个参数也可以设置成其他值,比如 permanent,表示这个记录永远不会过时,系统不会检查它是否正确,也不会删除它,只有管理员也能对它进行修改
[root@xingguang ~]# ip neigh replace 10.20.1.3 lladdr b2:ee:aa:42:8b:0b dev vxlan0 nud reachable
# 这时候还是不能正常通信,接着会出现 l2miss 的通知事件, 这个事件是说不知道这个容器的 MAC 地址在哪个节点上,所以要手动添加 fdb 记录. 最后在通信的另一台机器上执行相应的操作,就会发现两者能 ping 通了
[root@xingguang ~]# ip monitor all dev vxlan0
[nsid current]miss lladdr b2:ee:aa:42:8b:0b STALE
[root@xingguang ~]# bridge fdb add b2:ee:aa:42:8b:0b dst 192.168.8.101 dev vxlan0
- 上面提出的所有方案中,其中手动的部分都可以使用程序来自动完成,需要的信息一般都是从集中式的控制中心获取的,这也是大多数基于 vxlan 的 SDN 网络的大致架构, 当然具体的实现不一定和某种方法相同,可能是上述方法的变形或者组合,但是设计思想都是一样的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!