LCD—液晶显示中英文
本节主要介绍以下内容:
字符编码
字模
各种模式的液晶显示字符实验
本节字符编码说明参考网站
字符编码及转换测试:导航菜单 - 千千秀字
Unicode官网:http://www.unicode.org。
一、字符编码
由于计算机只能识别0和1,文字也只能以0和1的形式在计算机里存储,所以我们需要对文字进行编码才能让计算机处理,编码的过程就是规定特定的01数字串来表示特定的文字,最简单的字符编码例子是ASCII码。
1.1 ASCII编码
在程序设计中使用ASCII编码表约定了一些控制字符、英文及数字。它们在存储器中,本质也是二进制数,只是我们约定这些二进制数可以表示某些特殊意义,如以ASCII编码解释数字“0x41”时,它表示英文字符“A”。
1.1.1 ASCII编码表
| 十进制 | 十六进制 | 缩写/字符 | 解释 |
| 0 | 0 | NUL(null) | 空字符 |
| 1 | 1 | SOH(start of headline) | 标题开始 |
| 2 | 2 | STX (start of text) | 正文开始 |
| 3 | 3 | ETX (end of text) | 正文结束 |
| 4 | 4 | EOT (end of transmission) | 传输结束 |
| 5 | 5 | ENQ (enquiry) | 请求 |
| 6 | 6 | ACK (acknowledge) | 收到通知 |
| 7 | 7 | BEL (bell) | 响铃 |
| 8 | 8 | BS (backspace) | 退格 |
| 9 | 9 | HT (horizontal tab) | 水平制表符 |
| 10 | 0A | LF (NL line feed, new line) | 换行键 |
| 11 | 0B | VT (vertical tab) | 垂直制表符 |
| 12 | 0C | FF (NP form feed, new page) | 换页键 |
| 13 | 0D | CR (carriage return) | 回车键 |
| 14 | 0E | SO (shift out) | 不用切换 |
| 15 | 0F | SI (shift in) | 启用切换 |
| 16 | 10 | DLE (data link escape) | 数据链路转义 |
| 17 | 11 | DC1 (device control 1) | 设备控制1 |
| 18 | 12 | DC2 (device control 2) | 设备控制2 |
| 19 | 13 | DC3 (device control 3) | 设备控制3 |
| 20 | 14 | DC4 (device control 4) | 设备控制4 |
| 21 | 15 | NAK (negative acknowledge) | 拒绝接收 |
| 22 | 16 | SYN (synchronous idle) | 同步空闲 |
| 23 | 17 | ETB (end of trans. block) | 传输块结束 |
| 24 | 18 | CAN (cancel) | 取消 |
| 25 | 19 | EM (end of medium) | 介质中断 |
| 26 | 1A | SUB (substitute) | 替补 |
| 27 | 1B | ESC (escape) | 换码(溢出) |
| 28 | 1C | FS (file separator) | 文件分割符 |
| 29 | 1D | GS (group separator) | 分组符 |
| 30 | 1E | RS (record separator) | 记录分离符 |
| 31 | 1F | US (unit separator) | 单元分隔符 |
| 十进制 | 十六进制 | 缩写/字符 | 解释 |
| 0 | 0 | NUL(null) | 空字符 |
| 1 | 1 | SOH(start of headline) | 标题开始 |
| 2 | 2 | STX (start of text) | 正文开始 |
| 3 | 3 | ETX (end of text) | 正文结束 |
| 4 | 4 | EOT (end of transmission) | 传输结束 |
| 5 | 5 | ENQ (enquiry) | 请求 |
| 6 | 6 | ACK (acknowledge) | 收到通知 |
| 7 | 7 | BEL (bell) | 响铃 |
| 8 | 8 | BS (backspace) | 退格 |
| 9 | 9 | HT (horizontal tab) | 水平制表符 |
| 10 | 0A | LF (NL line feed, new line) | 换行键 |
| 11 | 0B | VT (vertical tab) | 垂直制表符 |
| 12 | 0C | FF (NP form feed, new page) | 换页键 |
| 13 | 0D | CR (carriage return) | 回车键 |
| 14 | 0E | SO (shift out) | 不用切换 |
| 15 | 0F | SI (shift in) | 启用切换 |
| 16 | 10 | DLE (data link escape) | 数据链路转义 |
| 17 | 11 | DC1 (device control 1) | 设备控制1 |
| 18 | 12 | DC2 (device control 2) | 设备控制2 |
| 19 | 13 | DC3 (device control 3) | 设备控制3 |
| 20 | 14 | DC4 (device control 4) | 设备控制4 |
| 21 | 15 | NAK (negative acknowledge) | 拒绝接收 |
| 22 | 16 | SYN (synchronous idle) | 同步空闲 |
| 23 | 17 | ETB (end of trans. block) | 传输块结束 |
| 24 | 18 | CAN (cancel) | 取消 |
| 25 | 19 | EM (end of medium) | 介质中断 |
| 26 | 1A | SUB (substitute) | 替补 |
| 27 | 1B | ESC (escape) | 换码(溢出) |
| 28 | 1C | FS (file separator) | 文件分割符 |
| 29 | 1D | GS (group separator) | 分组符 |
| 30 | 1E | RS (record separator) | 记录分离符 |
| 31 | 1F | US (unit separator) | 单元分隔符 |
| 54 | 36 | 6 | 102 | 66 | f | |
| 55 | 37 | 7 | 103 | 67 | g | |
| 56 | 38 | 8 | 104 | 68 | h | |
| 57 | 39 | 9 | 105 | 69 | i | |
| 58 | 3A | : | 106 | 6A | j | |
| 59 | 3B | ; | 107 | 6B | k | |
| 60 | 3C | <? | 108 | 6C | l | |
| 61 | 3D | = | 109 | 6D | m | |
| 62 | 3E | >? | 110 | 6E | n | |
| 63 | 3F | ? | 111 | 6F | o | |
| 64 | 40 | @ | 112 | 70 | p | |
| 65 | 41 | A | 113 | 71 | q | |
| 66 | 42 | B | 114 | 72 | r | |
| 67 | 43 | C | 115 | 73 | s | |
| 68 | 44 | D | 116 | 74 | t | |
| 69 | 45 | E | 117 | 75 | u | |
| 70 | 46 | F | 118 | 76 | v | |
| 71 | 47 | G | 119 | 77 | w | |
| 72 | 48 | H | 120 | 78 | x | |
| 73 | 49 | I | 121 | 79 | y | |
| 74 | 4A | J | 122 | 7A | z | |
| 75 | 4B | K | 123 | 7B | { | |
| 76 | 4C | L | 124 | 7C | | | |
| 77 | 4D | M | 125 | 7D | } | |
| 78 | 4E | N | 126 | 7E | ~ | |
| 79 | 4F | O | 127 | 7F | DEL (delete) 删除 |
ASCII码表分为两部分,第一部分是控制字符或通讯专用字符,它们的数字编码从0~31,它们并没有特定的图形显示,但会根据不同的应用程序,而对文本显示有不同的影响。ASCII码的第二部分包括空格、阿拉伯数字、标点符号、大小写英文字母以及“DEL(删除控制)”,这部分符号的数字编码从32~127,除最后一个DEL符号外,都能以图形的方式来表示,它们属于传统文字书写系统的一部分。
后来,计算机引进到其它国家的时候,由于他们使用的不是英语,他们使用的字母在ASCII码表中没有定义,所以他们采用127号之后的位来表示这些新的字母,还加入了各种形状,一直编号到255。从128到255这些字符被称为ASCII扩展字符集。至此基本存储单位Byte(char)能表示的编号都被用完了。
1.2. GB2312标准
我国首先定义的是GB2312标准。它把ASCII码表127号之后的扩展字符集直接取消掉,并规定小于127的编码按原来ASCII标准解释字符。当2个大于127的字符连在一起时,就表示1个汉字,第1个字节使用 (0xA1-0xFE) 编码,第2个字节使用(0xA1-0xFE)编码,这样的编码组合起来可以表示了7000多个符号,其中包含6763个汉字。在这些编码里,我们还把数学符号、罗马字母、日文假名等都编进表中,就连原来在ASCII里原本就有的数字、标点以及字母也重新编了2个字节长的编码,这就是平时在输入法里可切换的“全角”字符,而标准的ASCII码表中127号以下的就被称为“半角”字符。
下表说明了GB2312是如何兼容ASCII码的,当我们设定系统使用GB2312标准的时候,它遇到一个字符串时,会按字节检测字符值的大小,若遇到连续两个字节的数值都大于127时就把这两个连续的字节合在一起,用GB2312解码,若遇到的数值小于127,就直接用ASCII把它解码。
| 第1字节 | 第2字节 | 表示的字符 | 说明 |
| 0x68 | 0x69 | (hi) | 两个字节的值都小于127(0x7F), 使用ASCII解码 |
| 0xB0 | 0xA1 | (啊) | 两个字节的值都大于127(0x7F), 使用GB2312解码 |
区位码

在GB2312编码的实际使用中,有时会用到区位码的概念。GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。而区位码实际是GB2312编码的内部形式,它规定对收录的每个字符采用两个字节表示,第一个字节为“高字节”,对应94个区;第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。为兼容ASCII码,区号和位号分别加上0xA0偏移就得到GB2312编码。在区位码上加上0xA0偏移,可求得GB2312编码范围:0xA1A1-0xFEFE,其中汉字的编码范围为0xB0A1-0xF7FE,第一字节0xB0-0xF7(对应区号:16-87),第二个字节0xA1-0xFE(对应位号:01-94)。?
例如,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601,加上0xA0偏移,其GB2312编码为0xB0A1。其中区位码为0101的码位表示的是“空格”符。
1.3. GBK编码
据统计,GB2312编码中表示的6763个汉字已经覆盖中国大陆99.75%的使用率,单看这个数字已经很令人满意了,但是不能因为那些文字不常用就不让它进入信息时代,而且生僻字在人名、文言文中的出现频率是非常高的。
?为此我们在GB2312标准的基础上又增加了14240个新汉字(包括所有后面介绍的Big5中的所有汉字)和符号,这个方案被称为GBK标准。增加这么多字符,按照GB2312原来的格式来编码,2个字节已经存储不下,我们的程序员修改了一下格式,不再要求第2个字节的编码值必须大于127,只要第1个字节大于127就表示这是一个汉字的开始,这样就做到兼容ASCII和GB2312标准了。
说明了GBK是如何兼容ASCII和GB2312标准的,当我们设定系统使用GBK标准的时候,它按顺序遍历字符串,按字节检测字符值的大小,若遇到一个字符的值大于127时,就再读取它后面的一个字符,把这两个字符值合在一起,用GBK解码,解码完后,再读取第3个字符,重新开始以上过程,若该字符值小于127,则直接用ASCII解码。
| 第1字节 | 第2字节 | 第3字节 | 表示的字符 | 说明 |
| 0x68(<7F) | 0xB0(>7F) | 0xA1(>7F) | (h啊) | 第1个字节小于127,使用ASCII解码, 每2个字节大于127,直接使用GBK解码 ,兼容GB2312 |
| 0xB0(>7F) | 0xA1(>7F) | 0x68(<7F) | (啊h) | 第1个字节大于127,直接使用GBK码 解释,第3个字节小于127,使用ASCII 解码 |
| 0xB0(>7F) | 0x56(<7F) | 0x68(<7F) | (癡h) | 第1个字节大于127,第2个字节虽然小 于127,直接使用GBK解码,第3个字节 小于127,使用ASCII解码 |
1.4. GB18030
随着计算机技术的普及,我们后来又在GBK的标准上不断扩展字符,这些标准被称为GB18030,如GB18030-2000、GB18030-2005等(“-”号后面的数字是制定标准时的年号),GB18030的编码使用4个字节,它利用前面标准中的第2个字节未使用的“0x30-0x39”编码表示扩充四字节的后缀,兼容GBK、GB2312及ASCII标准。
GB18030-2000主要在GBK基础上增加了“CJK(中日韩)统一汉字扩充A”的汉字。加上前面GBK的内容,GB18030-2000一共规定了27533个汉字(包括部首、部件等)的编码,还有一些常用非汉字符号。
? GB18030-2005的主要特点是在GB18030-2000基础上增加了“CJK(中日韩)统一汉字扩充B”的汉字。增加了42711个汉字和多种我国少数民族文字的编码(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)。加上前面GB18030-2000的内容,一共收录了70244个汉字。
1.5 各个标准的对比说明
GB2312、GBK及GB18030是汉字的国家标准编码,新版向下兼容旧版,各个标准简要说明见下表,目前比较流行的是GBK编码,因为每个汉字只占用2个字节,而且它编码的字符已经能满足大部分的需求,但国家要求一些产品必须支持GB18030标准。

1.6. Big5编码
在台湾、香港等地区,使用较多的是Big5编码,它的主要特点是收录了繁体字。而从GBK编码开始,已经把Big5中的所有汉字收录进编码了。即对于汉字部分,GBK是Big5的超集,Big5能表示的汉字,在GBK都能找到那些字相应的编码,但他们的编码是不一样的,两个标准不兼容,如GBK中的“啊”字编码是“0xB0A1”,而Big5标准中的编码为“0xB0DA”。
主要做嵌入式的同学学习到这就可以了,因为我们平时用的主要就是GB2312/GBK.
1.7 Unicode字符集和编码
由于各个国家或地区都根据使用自己的文字系统制定标准,同一个编码在不同的标准里表示不一样的字符,各个标准互不兼容,而又没有一个标准能够囊括所有的字符,即无法用一个标准表达所有字符。国际标准化组织(ISO)为解决这一问题,它舍弃了地区性的方案,重新给全球上所有文化使用的字母和符号进行编号,对每个字符指定一个唯一的编号(ASCII中原有的字符编号不变),这些字符的号码从0x000000到0x10FFFF,该编号集被称为Universal Multiple-Octet Coded Character Set,简称UCS,也被称为Unicode。最新版的Unicode标准还包含了表情符号(聊天软件中的部分emoji表情),可访问Unicode官网了解:http://www.unicode.org。
? Unicode字符集只是对字符进行编号,但具体怎么对每个字符进行编码,Unicode并没指定,因此也衍生出了如下几种unicode编码方案(Unicode Transformation Format)。
1.7.1 UTF-32
对Unicode字符集编码,最自然的就是UTF-32方式了。编码时,它直接对Unicode字符集里的每个字符都用4字节来表示,转换方式很简单,直接将字符对应的编号数字转换为4字节的二进制数。
? 由于UTF-32把每个字符都用要4字节来存储,因此UTF-32不兼容ASCII编码,也就是说ASCII编码的文件用UTF-32标准来打开会成为乱码。
| 字符 | GBK编码 | Unicode编号 | UTF-32编码 |
| A | 0x41 | 0x0000 0041 | 大端格式0x0000 0041 |
| 啊 | 0xB0A1 | 0x0000 554A | 大端格式0x0000 554A |
对UTF-32数据进行解码的时候,以4个字节为单位进行解析即可,根据编码可直接找到Unicode字符集中对应编号的字符。
? UTF-32的优点是编码简单,解码也很方便,读取编码的时候每次都直接读4个字节,不需要加其它的判断。它的缺点是浪费存储空间,大量常用字符的编号只需要2个字节就能表示。其次,在存储的时候需要指定字节顺序,是高位字节存储在前(大端格式),还是低位字节存储在前(小端格式)。
1.7.2 UTF-16
针对UTF-32的缺点,人们改进出了UTF-16的编码方式,它采用2字节或4字节的变长编码方式(UTF-32定长为4字节)。对Unicode字符编号在0到65535的统一用2个字节来表示,将每个字符的编号转换为2字节的二进制数,即从0x0000到0xFFFF。而由于Unicode字符集在0xD800-0xDBFF这个区间是没有表示任何字符的,所以UTF-16就利用这段空间,对Unicode中编号超出0xFFFF的字符,利用它们的编号做某种运算与该空间建立映射关系,从而利用该空间表示4字节扩展,感兴趣的读者可查阅相关资料了解具体的映射过程。
| 字符 | GB18030编码 | Unicode编号 | UTF-16编码 |
| A | 0x41 | 0x0000 0041 | 大端格式0x0041 |
| 啊 | 0xB0A1 | 0x0000 554A | 大端格式0x554A |
| 𧗌 | 0x9735 F832 | 0x0002 75CC | 大端格式0xD85D DDCC |
注:𧗌 五笔:TLHH(不支持GB18030码的输入法无法找到该字,感兴趣可搜索它的Unicode编号找到)?
UTF-16解码时,按两个字节去读取,如果这两个字节不在0xD800到0xDFFF范围内,那就是双字节编码的字符,以双字节进行解析,找到对应编号的字符。如果这两个字节在0xD800到 0xDFFF之间,那它就是四字节编码的字符,以四字节进行解析,找到对应编号的字符。
UTF-16编码的优点是相对UTF-32节约了存储空间,缺点是仍不兼容ASCII码,仍有大小端格式问题。
1.7.3 UTF-8
UTF-8是目前Unicode字符集中使用得最广的编码方式,目前大部分网页文件已使用UTF-8编码,如使用浏览器查看百度首页源文件,可以在前几行HTML代码中找到如下代码:
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
其中“charset”等号后面的“utf-8”即表示该网页字符的编码方式UTF-8。?
UTF-8也是一种变长的编码方式,它的编码有1、2、3、4字节长度的方式,每个Unicode字符根据自己的编号范围去进行对应的编码。它的编码符合以下规律:
- 对于UTF-8单字节的编码,该字节的第1位设为0(从左边数起第1位,即最高位),剩余的位用来写入字符的Unicode编号。即对于Unicode编号从0x0000 0000-0x0000 007F的字符,UTF-8编码只需要1个字节,因为这个范围Unicode编号的字符与ASCII码完全相同,所以UTF-8兼容了ASCII码表。
- 对于UTF-8使用N个字节的编码(N>1),第一个字节的前N位设为1,第N+1位设为0,后面字节的前两位都设为10,这N个字节的其余空位填充该字符的Unicode编号,高位用0补足。
| Unicode(16进制) | UTF-8(2进制) | ||||
| 编号范围 | 第一字节 | 第二字节 | 第三字节 | 第四字节 | 第五字节 |
| 00000000-0000007F | 0xxxxxxx | ||||
| 00000080-000007FF | 110xxxxx | 10xxxxxx | |||
| 00000800-0000FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | ||
| 00010000-0010FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| … | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
UTF-8解码的时候以字节为单位去看,如果第一个字节的bit位以0开头,那就是ASCII字符,以单字节进行解析。如果第一个字节的数据位以“110”开头,就按双字节进行解析,3、4字节的解析方法类似。
? UTF-8的优点是兼容了ASCII码,节约空间,且没有字节顺序的问题,它直接根据第1个字节前面数据位中连续的1个数决定后面有多少个字节。不过使用UTF-8编码汉字平均需要3个字节,比GBK编码要多一个字节。
二、什么是字模
有了编码,我们就能在计算机中处理、存储字符了,但是如果计算机处理完字符后直接以编码的形式输出,人类将难以识别。因此计算机与人交互时,一般会把字符转化成人类习惯的表现形式进行输出,如显示、打印的时候。
但是如果仅有字符编码,计算机还不知道该如何表达该字符,因为字符实际上是一个个独特的图形,计算机必须把字符编码转化成对应的字符图形人类才能正常识别,因此我们要给计算机提供字符的图形数据,这些数据就是字模,多个字模数据组成的文件也被称为字库。计算机显示字符时,根据字符编码与字模数据的映射关系找到它相应的字模数据,液晶屏根据字模数据显示该字符。
2.1 字模的构成
已知字模是图形数据,而图形在计算机中是由一个个像素点组成的,所以字模实质是一个个像素点数据。为方便处理,我们把字模定义成方块形的像素点阵,且每个像素点只有0和1这两种状态(可以理解为单色图像数据)。
下图两个宽、高为16x16的像素点阵组成的两个汉字图形,其中的黑色像素点即为文字的笔迹。计算机要表示这样的图形,只需使用16x16个二进制数据位,每个数据位记录一个像素点的状态,把黑色像素点以“1”表示,无色像素点以“0”表示即可。这样的一个汉字图形,使用16x16/8=32个字节来就可以记录下来。

?16x16的“字”的字模数据以C语言数组的方式表示,见下面的代码,在这样的字模中,以两个字节表示一行像素点,16行构成一个字模。

2.2 字模显示原理
如果使用LCD的画点函数,按位来扫描这些字模数据,把为1的位以黑色来显示(也可以使用其它颜色),为0的数据位以白色来显示,即可把整个点阵还原出来,显示在液晶屏上。
为方便讲解,编写一个使用串口printf利用字模打印字符到串口上位机的实验,
代码:
/*阴码*/
uint8_t test_modul[] =
{0x02,0x00,0x01,0x00,0x7F,0xFE,0x40,0x02,
0x80,0x04,0x1F,0xE0,0x00,0x40,0x00,0x80,
0x01,0x00,0xFF,0xFE,0x01,0x00,0x01,0x00,
0x01,0x00,0x01,0x00,0x05,0x00,0x02,0x00};/* 字 */
///*阳码*/
//uint8_t test_modul[] =
//{0xFD,0xFF,0xFE,0xFF,0x80,0x01,0xBF,0xFD,
// 0x7F,0xFB,0xE0,0x1F,0xFF,0xBF,0xFF,0x7F,
// 0xFE,0xFF,0x00,0x01,0xFE,0xFF,0xFE,0xFF,
//0xFE,0xFF,0xFE,0xFF,0xFA,0xFF,0xFD,0xFF}; /*"字",0*/
void Display_char_test(void)
{
uint8_t row_count,byte_count,bit_count;
for(row_count=0;row_count < 16;row_count++ )
{
printf("\n");
for(byte_count=0;byte_count<2;byte_count++)
{
for(bit_count=0;bit_count<8;bit_count++)
{
if(test_modul[row_count*2+byte_count] & (0x80>>bit_count) )
{
printf("*");
}
else
{
printf(" ");
}
}
}
}
}实验效果如下:

2.3??如何制作字模
为方便使用,需要制作所有常用字符的字模,如程序只需要英文显示,那就需要制作包含ASCII码表中所有字符的字模,如程序只需要使用一些常用汉字,则可以选择制作GB2312编码里所有字符的字模,而且希望字模数据与字符编码有固定的映射关系,以便我们在程序中使用字符编码作为索引,查找字模。
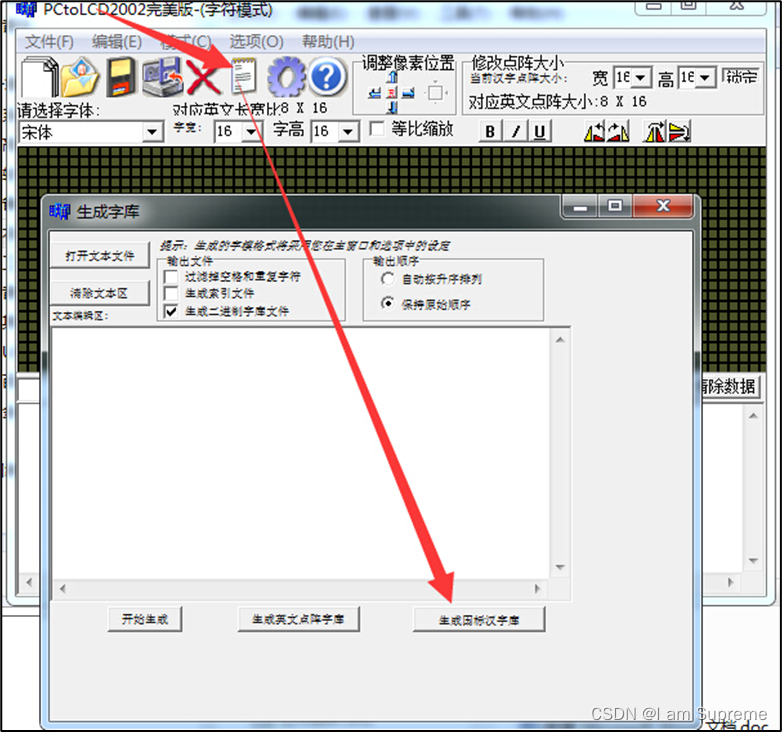
? 在网上搜索可找到一些制作字模的软件工具,可满足这些需求。在我们提供的《LCD—液晶显示汉字》的工程目录下提供了一个取模软件“PCtoLCD”,这里以它为例讲解如何制作字模,其它字模软件也是类似的。
- 配置字模格式,打开取模软件,点击“选项”菜单,会弹出一个对话框。

- 选项“点阵格式”中的阴、阳码是指字模点阵中有笔迹像素位的状态是“1”还是“0”,像我们前文介绍的那种就是阴码,反过来就是阳码。本工程中使用阴码。
- 选项“取模方式”是指字模图形的扫描方向,修改这部分的设置后,选项框的右侧会有相应的说明及动画显示,这里我们依然按前文介绍的字模类型,把它配置成“逐行式”
- 选项“每行显示的数据”里我们把点阵和索引都配置成16,设置这个点阵的像素大小为16x16。
- 字模选项的格式保持不变,设置完我们点击确定即可,字模选项的这些配置会影响到显示代码的编写方式。?
(阴码和阳码的区别,有笔记的地方是1? ?没有笔记地方1,是阳码)

- ?生成GB2312字模
配置完字模选项后,点击软件中的导入文本图标,会弹出一个“生成字库”的对话框,点击右下角的生成国标汉字库按钮即可生成包含了GB2312编码里所有字符的字模文件。
? 在《LCD—液晶显示汉字》的工程目录下的《GB2312_H1616.FON》是我们用这个取模软件生成的字模原文件,若不想自己制作字模,可直接使用该文件。
字模寻址公式
????????使用字模软件制作的字模数据一般会按照编码格式排列。如我们利用以上软件生成的字模文件《GB2312_H1616.FON》中的数据,是根据GB2312的区位码表的顺序存储的,它存储了区位码为0101-9494的字符,每个字模的大小为16x16/8=36字节。其中第一个字符“空格”的区位码为0101,它是首个字符,所以文件的前36字节存储的是它的字模数据;同理,36-72字节存储的则是0102字符“、”的字模数据。所以我们可以导出任意字符的寻址公式:
? Addr = (((CodeH-0xA0-1)*94) +(CodeL-0xA0-1))*16*16/8
????????其中CodeH和CodeL分别是GB2312编码的第一字节和第二字节;94是指一个区中有94个位(即94个字符)。公式的实质是根据字符的GB2312编码,求出区位码,然后区位码乘以每个字符占据的字节数,求出地址偏移。
????????上面生成的《GB2312_H1616.FON》文件的大小为576KB,比很多STM32芯片内部的所有FLASH空间都大,如果我们还是在程序中直接以C语言数组的方式存储字模数据,STM32芯片的程序空间会非常紧张,一般的做法是把字模数据存储到外部存储器,如SD卡或SPI-FLASH芯片,当需要显示某个字符时,控制器根据字符的编码算好字模的存储地址,再从存储器中读取,而FLASH芯片在生产前就固化好字模内容,然后直接把FLASH芯片贴到电路板上,作为整个系统的一部分。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- el-form 回车刷新的问题
- R语言【paleobioDB】——pbdb_occurrences():从PBDB获取多个化石记录号的基本信息
- 2023下半年软考中级——软件设计师通过感想总结(最新机考改革注意事项!!)
- 揭秘跨境电商ERP源码定制化需求及最佳实践
- Javascript中如何解决跨域?
- Windows 双网卡链路聚合解决方案
- Java中的观察者模式应用场景
- Spring框架XML配置文件中的<bean>标签的作用
- NLP基础——TF-IDF
- Python Django的学生选课管理系统,实现多用户登录注册,可选课可评课