每天五分钟计算机视觉:揭秘迁移学习
发布时间:2024年01月03日
本文重点
随着人工智能的迅速发展,深度学习已经成为了许多领域的关键技术。然而,深度学习模型的训练需要大量的标注数据,这在很多情况下是不现实的。迁移学习作为一种有效的方法,可以在已有的数据和模型上进行训练,然后将其应用于新的任务。这种方法大大降低了对新任务的数据需求,提高了模型的泛化能力。本文将详细介绍迁移学习的原理、应用和未来发展。
迁移学习的基本原理
迁移学习是一种将在一个任务上学到的知识应用于另一个任务的方法。其核心思想是利用已经训练好的模型作为基础,通过微调来适应新的任务。这种方法的关键在于找到源任务和目标任务之间的相似性,以便将知识从一个任务迁移到另一个任务。迁移学习的成功与否,很大程度上取决于特征表示的学习和知识的有效转移。
如何使用
如何使用迁移学习呢?当我们已经拥有了一个别人已经开源的神经网络的架构以及权重参数,我们可以根据我们自身问题的数据量的不同,从而进行不同的选择。
比如,我们要建立一个分类器,输入一幅图片,模型可以识别出这张图片是猫、狗、鸡
在实际的使用过程中,我们一般去掉已经训练好网络最后的这个 Softmax 层,创建你自己的 Softmax 单元,用来输出猫、狗、鸡三个类别。
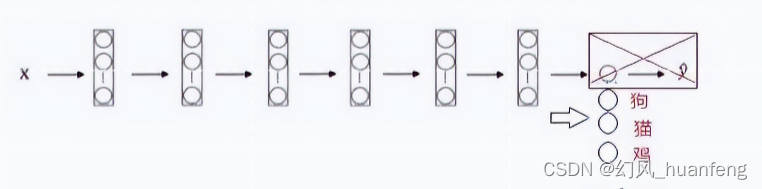
就网络而言,我们可以把所有的层看作是冻结的,你冻结网络中所有层的参数,就是说这些前面的网络层不再训练了,你只需要训练和你的 Softmax 层有关的参数。这个 Softmax 层有三种可能的输出,猫、狗、鸡
迁移学习的应用
文章来源:https://blog.csdn.net/huanfeng_AI/article/details/135374748
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 设计模式之模板方法
- Octomap使用记录
- 【算法题】51. N 皇后
- 数据结构(chapter Two -01)
- 教育科学杂志教育科学杂志社教育科学编辑部2023年第12期部分目录
- 带你学C语言-指针(4)
- 【分布式技术专题】「分析Web服务器架构」Tomcat服务器的运行架构和LVS负载均衡的运行机制(修订版)
- 中央集成式架构量产时代,openVOC方案将引发软件开发模式变革
- yum仓库以及NFS共享
- 4. Prism系列之事件