李宏毅自注意力机制和Transformer详解笔记(未完待续)
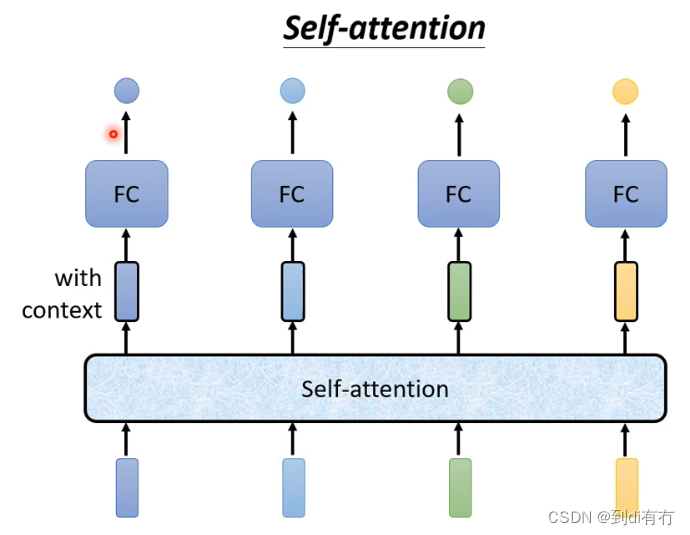
self-attention运作机制:self-attention会处理整个输入的序列,输入几个vector(最下方4个方格)同时就会输入几个vector(处理后带黑色边框的方格,此时新的vector是考虑整个序列信息得到的新vector),再把的到的新的vector输入到全连接神经网络,然后得到希望输出的东西,如此依赖全连接神经网络便是考虑了全局的信息,而不是部分或者某个窗口内的信息。self-attention可以用多次,即下发的网络结构
 关于self-attention最出名文章即Attention is all you need,本篇文章中谷歌提出Tansformer架构,Tansformer中最重要的model即self-attention
关于self-attention最出名文章即Attention is all you need,本篇文章中谷歌提出Tansformer架构,Tansformer中最重要的model即self-attention
self-attention运作方式
self-attention的输入是一串的vector,这些vector可能是整个网络的输入,也可能是某个隐藏层的输出,每个b向量都是考虑所有的a向量而生成的
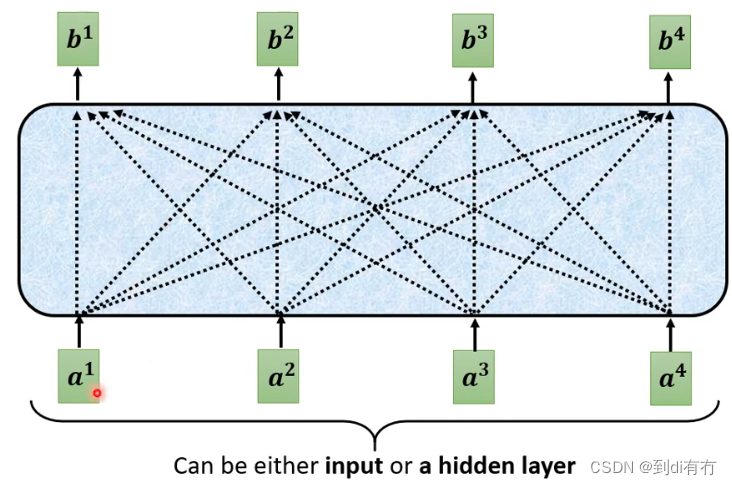
如何产生b1向量:(其他同理)
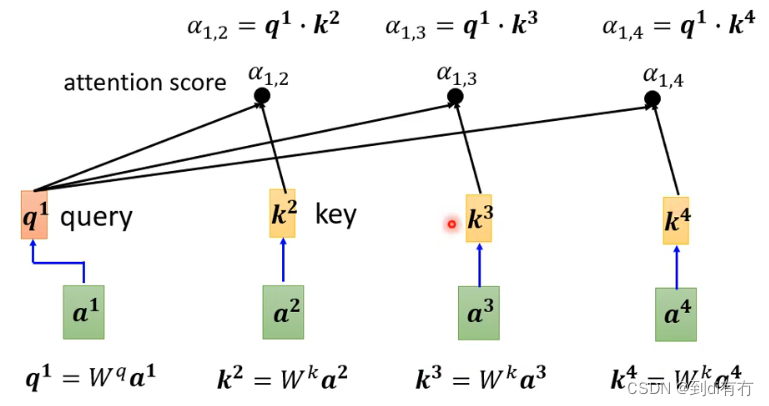
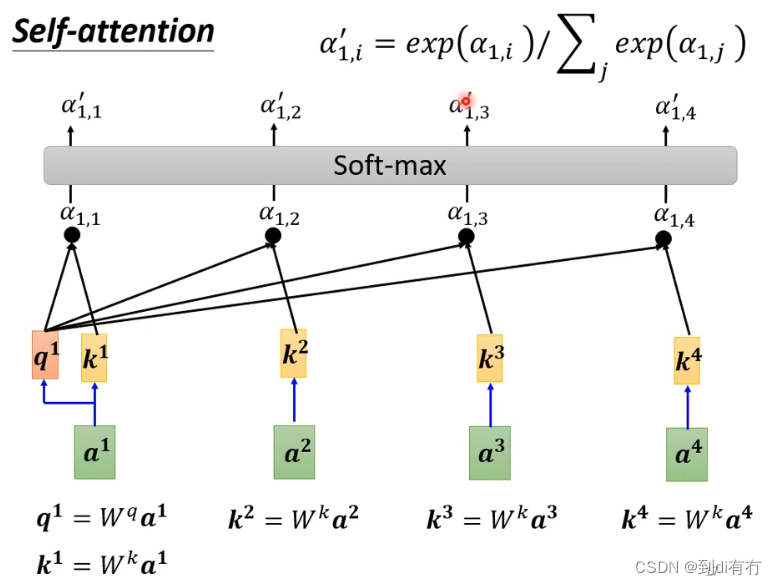
第一步:根据a1找出这些序列中(a1-a4)跟a1相关的向量,每个向量跟a1的关联程度使用数值α表示

如何决定两个向量的相关性呢,以a1与a4举例,通常使用一个函数直接计算出两个对应的α,有多种方法,法1(下图左):常见的方法是dot product(点积),两个向量分布乘以两个不同的矩阵(Wq,Wk),得到两个新的向量(q,k),再将q和k做点积便得到alpha。法2(下图右):在得到q与w后将两个向量串起来,通过激活函数,再通过一个转换得到α。后续讨论中均使用图左方法

在self-attention中,a1与a2,a3,a4分布计算相关性,把a1乘以wq得到q1(q有个名字叫query),a2乘以wk得到k2(k称之为key),然后q1与q2做点积得到α1,2(老师课程中说的是inner product,推测是口误了),α1,2称为a1与a2的attention score,a3与a4同理得到a1,3和a1,4,
通常在实操中a1也会跟自己算关联性得到α1,1,得到每个关联性后做一个softmax。操作方式:α做一个exp(α1,i),再除以 所有exp(α1,i)加和 做一个归一化(normalized),得到最终输出(α`1,i)。【不一定用softmax,也可以relu,其他的激活函数都行,可以多多尝试】
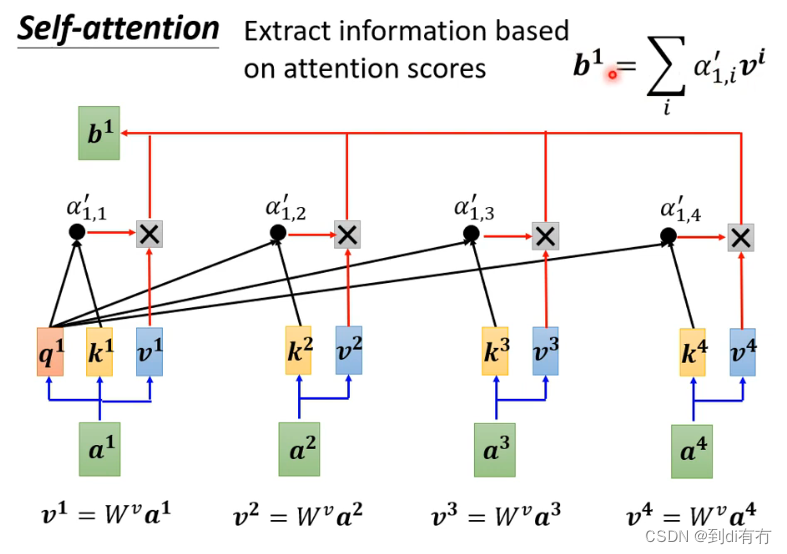
已经知道哪些向量和a1最相关,接下来要抽取相关的信息,抽取方式:将所有向量(a1-a4)乘以wv得到新的向量得到v1-v4,然后再将a1-a4分别乘以对应的α,然后再做一个加和。可以看到的是,对于关联性最高的向量,假设是a2,则得到的α也更大,最终结果b1也就更加多的包含v2的信息
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python | 六、哈希表 Hash Table(列表、集合、映射)
- 【Docker】数据卷挂载以及宿主机目录挂载的使用
- Smartbi获工信部旗下赛迪网“2023行业信息技术应用创新产品”奖
- Spring常用注解及模拟用户登录流程示例
- curl+postman 在java开发中的使用(提高效率)
- 使用vite搭建项目时,在启动vite后,浏览器显示页面:找不到localhost的网页
- kubelet源码学习(一):kubelet工作原理、kubelet启动过程
- 5G边缘网关如何助力打造隧道巡检机器人
- 签名不对,请检查包名是否与开放平台上填写的一致。微信分享 errorCode 为-6(方法有两种)
- 017-信息打点-语言框架&开发组件&FastJson&Shiro&Log4j&SpringBoot等