复现PointNet++(语义分割网络):Windows + PyTorch + S3DIS语义分割 + 代码
发布时间:2024年01月17日
一、平台
Windows 10
GPU RTX 3090 + CUDA 11.1 + cudnn 8.9.6
Python 3.9
Torch 1.9.1 + cu111
所用的原始代码:https://github.com/yanx27/Pointnet_Pointnet2_pytorch
二、数据
Stanford3dDataset_v1.2_Aligned_Version
三、代码
分享给有需要的人,代码质量勿喷。
对源代码进行了简化和注释。
分割结果保存成txt,或者利用 laspy 生成点云。
别问为啥在C盘,问就是2T的三星980Pro
3.1 文件组织结构
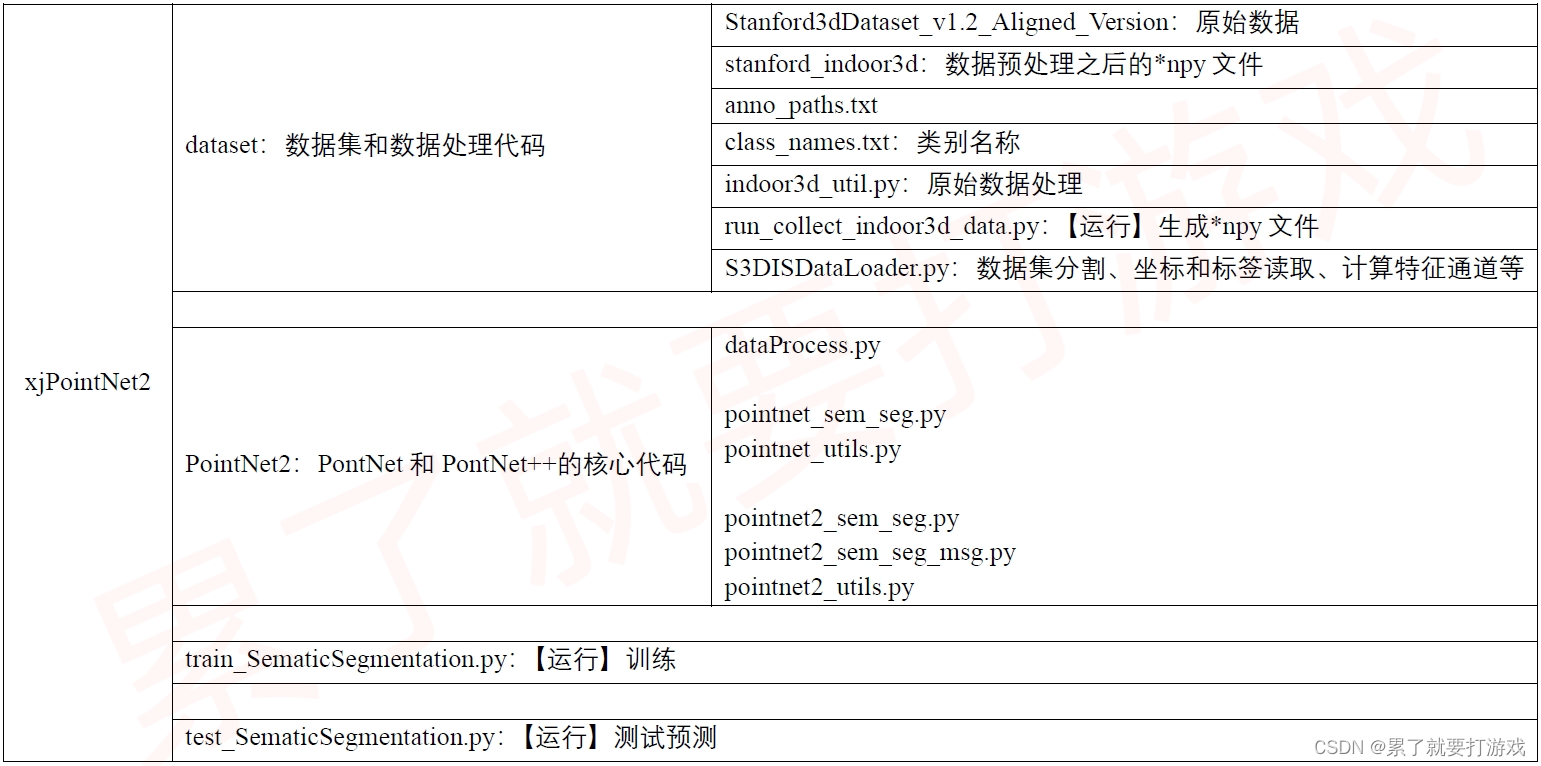
3.2 数据预处理
3.2.1 run_collect_indoor3d_data.py 生成*.npy文件
改了路径
3.2.2 indoor3d_util.py
改了路径
3.2.3 S3DISDataLoader.py
改了路径
3.3 训练?train_SematicSegmentation.py
# 参考
# https://github.com/yanx27/Pointnet_Pointnet2_pytorch
# 先在Terminal运行:python -m visdom.server
# 再运行本文件
import argparse
import os
# import datetime
import logging
import importlib
import shutil
from tqdm import tqdm
import numpy as np
import time
import visdom
import torch
import warnings
warnings.filterwarnings('ignore')
from dataset.S3DISDataLoader import S3DISDataset
from PointNet2 import dataProcess
# PointNet
from PointNet2.pointnet_sem_seg import get_model as PNss
from PointNet2.pointnet_sem_seg import get_loss as PNloss
# PointNet++
from PointNet2.pointnet2_sem_seg import get_model as PN2SS
from PointNet2.pointnet2_sem_seg import get_loss as PN2loss
# True为PointNet++
PN2bool = True
# PN2bool = False
# 当前文件的路径
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
# 训练输出模型的路径: PointNet
dirModel1 = ROOT_DIR + '/trainModel/pointnet_model'
if not os.path.exists(dirModel1):
os.makedirs(dirModel1)
# 训练输出模型的路径
dirModel2 = ROOT_DIR + '/trainModel/PointNet2_model'
if not os.path.exists(dirModel2):
os.makedirs(dirModel2)
# 日志的路径
pathLog = os.path.join(ROOT_DIR, 'LOG_train.txt')
# 数据集的路径
pathDataset = os.path.join(ROOT_DIR, 'dataset/stanford_indoor3d/')
# 分类的类别
classNumber = 13
classes = ['ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door', 'table', 'chair', 'sofa', 'bookcase',
'board', 'clutter']
class2label = {cls: i for i, cls in enumerate(classes)}
seg_classes = class2label
seg_label_to_cat = {}
for i, cat in enumerate(seg_classes.keys()):
seg_label_to_cat[i] = cat
# 日志和输出
def log_string(str):
logger.info(str)
print(str)
def inplace_relu(m):
classname = m.__class__.__name__
if classname.find('ReLU') != -1:
m.inplace=True
def parse_args():
parser = argparse.ArgumentParser('Model')
parser.add_argument('--pnModel', type=bool, default=True, help='True = PointNet++;False = PointNet')
parser.add_argument('--batch_size', type=int, default=32, help='Batch Size during training [default: 32]')
parser.add_argument('--epoch', default=320, type=int, help='Epoch to run [default: 32]')
parser.add_argument('--learning_rate', default=0.001, type=float, help='Initial learning rate [default: 0.001]')
parser.add_argument('--GPU', type=str, default='0', help='GPU to use [default: GPU 0]')
parser.add_argument('--optimizer', type=str, default='Adam', help='Adam or SGD [default: Adam]')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='weight decay [default: 1e-4]')
parser.add_argument('--npoint', type=int, default=4096, help='Point Number [default: 4096]')
parser.add_argument('--step_size', type=int, default=10, help='Decay step for lr decay [default: every 10 epochs]')
parser.add_argument('--lr_decay', type=float, default=0.7, help='Decay rate for lr decay [default: 0.7]')
parser.add_argument('--test_area', type=int, default=5, help='Which area to use for test, option: 1-6 [default: 5]')
return parser.parse_args()
if __name__ == '__main__':
# python -m visdom.server
visdomTL = visdom.Visdom()
visdomTLwindow = visdomTL.line([0], [0], opts=dict(title='train_loss'))
visdomVL = visdom.Visdom()
visdomVLwindow = visdomVL.line([0], [0], opts=dict(title='validate_loss'))
visdomTVL = visdom.Visdom(env='PointNet++')
# region 创建日志文件
logger = logging.getLogger("train")
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler(pathLog)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
#endregion
#region 超参数
args = parse_args()
args.pnModel = PN2bool
log_string('------------ hyper-parameter ------------')
log_string(args)
# 指定GPU
os.environ["CUDA_VISIBLE_DEVICES"] = args.GPU
pointNumber = args.npoint
batchSize = args.batch_size
#endregion
# region dataset
# train data
trainData = S3DISDataset(split='train',
data_root=pathDataset, num_point=pointNumber,
test_area=args.test_area, block_size=1.0, sample_rate=1.0, transform=None)
trainDataLoader = torch.utils.data.DataLoader(trainData, batch_size=batchSize, shuffle=True, num_workers=0,
pin_memory=True, drop_last=True,
worker_init_fn=lambda x: np.random.seed(x + int(time.time())))
# Validation data
testData = S3DISDataset(split='test',
data_root=pathDataset, num_point=pointNumber,
test_area=args.test_area, block_size=1.0, sample_rate=1.0, transform=None)
testDataLoader = torch.utils.data.DataLoader(testData, batch_size=batchSize, shuffle=False, num_workers=0,
pin_memory=True, drop_last=True)
log_string("The number of training data is: %d" % len(trainData))
log_string("The number of validation data is: %d" % len(testData))
weights = torch.Tensor(trainData.labelweights).cuda()
#endregion
# region loading model:使用预训练模型或新训练
modelSS = ''
criterion = ''
if PN2bool:
modelSS = PN2SS(classNumber).cuda()
criterion = PN2loss().cuda()
modelSS.apply(inplace_relu)
else:
modelSS = PNss(classNumber).cuda()
criterion = PNloss().cuda()
modelSS.apply(inplace_relu)
# 权重初始化
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv2d') != -1:
torch.nn.init.xavier_normal_(m.weight.data)
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find('Linear') != -1:
torch.nn.init.xavier_normal_(m.weight.data)
torch.nn.init.constant_(m.bias.data, 0.0)
try:
path_premodel = ''
if PN2bool:
path_premodel = os.path.join(dirModel2, 'best_model_S3DIS.pth')
else:
path_premodel = os.path.join(dirModel1, 'best_model_S3DIS.pth')
checkpoint = torch.load(path_premodel)
start_epoch = checkpoint['epoch']
# print('pretrain epoch = '+str(start_epoch))
modelSS.load_state_dict(checkpoint['model_state_dict'])
log_string('!!!!!!!!!! Use pretrain model')
except:
log_string('...... starting new training ......')
start_epoch = 0
modelSS = modelSS.apply(weights_init)
#endregion
# start_epoch = 0
# modelSS = modelSS.apply(weights_init)
#region 训练的参数和选项
if args.optimizer == 'Adam':
optimizer = torch.optim.Adam(
modelSS.parameters(),
lr=args.learning_rate,
betas=(0.9, 0.999),
eps=1e-08,
weight_decay=args.decay_rate
)
else:
optimizer = torch.optim.SGD(modelSS.parameters(), lr=args.learning_rate, momentum=0.9)
def bn_momentum_adjust(m, momentum):
if isinstance(m, torch.nn.BatchNorm2d) or isinstance(m, torch.nn.BatchNorm1d):
m.momentum = momentum
LEARNING_RATE_CLIP = 1e-5
MOMENTUM_ORIGINAL = 0.1
MOMENTUM_DECCAY = 0.5
MOMENTUM_DECCAY_STEP = args.step_size
global_epoch = 0
best_iou = 0
#endregion
for epoch in range(start_epoch, args.epoch):
# region Train on chopped scenes
log_string('****** Epoch %d (%d/%s) ******' % (global_epoch + 1, epoch + 1, args.epoch))
lr = max(args.learning_rate * (args.lr_decay ** (epoch // args.step_size)), LEARNING_RATE_CLIP)
log_string('Learning rate:%f' % lr)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
momentum = MOMENTUM_ORIGINAL * (MOMENTUM_DECCAY ** (epoch // MOMENTUM_DECCAY_STEP))
if momentum < 0.01:
momentum = 0.01
log_string('BN momentum updated to: %f' % momentum)
modelSS = modelSS.apply(lambda x: bn_momentum_adjust(x, momentum))
modelSS = modelSS.train()
#endregion
# region 训练
num_batches = len(trainDataLoader)
total_correct = 0
total_seen = 0
loss_sum = 0
for i, (points, target) in tqdm(enumerate(trainDataLoader), total=len(trainDataLoader), smoothing=0.9):
# 梯度归零
optimizer.zero_grad()
# xyzL
points = points.data.numpy() # ndarray = bs,4096,9(xyz rgb nxnynz)
points[:, :, :3] = dataProcess.rotate_point_cloud_z(points[:, :, :3]) ## 数据处理的操作
points = torch.Tensor(points) # tensor = bs,4096,9
points, target = points.float().cuda(), target.long().cuda()
points = points.transpose(2, 1) # tensor = bs,9,4096
# 预测结果
seg_pred, trans_feat = modelSS(points) # tensor = bs,4096,13 # tensor = bs,512,16
seg_pred = seg_pred.contiguous().view(-1, classNumber) # tensor = (bs*4096=)点数量,13
# 真实标签
batch_label = target.view(-1, 1)[:, 0].cpu().data.numpy() # ndarray = (bs*4096=)点数量
target = target.view(-1, 1)[:, 0] # tensor = (bs*4096=)点数量
# loss
loss = criterion(seg_pred, target, trans_feat, weights)
loss.backward()
# 优化器来更新模型的参数
optimizer.step()
pred_choice = seg_pred.cpu().data.max(1)[1].numpy() # ndarray = (bs*4096=)点数量
correct = np.sum(pred_choice == batch_label) # 预测正确的点数量
total_correct += correct
total_seen += (batchSize * pointNumber)
loss_sum += loss
log_string('Training mean loss: %f' % (loss_sum / num_batches))
log_string('Training accuracy: %f' % (total_correct / float(total_seen)))
# draw
trainLoss = (loss_sum.item()) / num_batches
visdomTL.line([trainLoss], [epoch+1], win=visdomTLwindow, update='append')
#endregion
# region 保存模型
if epoch % 1 == 0:
modelpath=''
if PN2bool:
modelpath = os.path.join(dirModel2, 'model' + str(epoch + 1) + '_S3DIS.pth')
else:
modelpath = os.path.join(dirModel1, 'model' + str(epoch + 1) + '_S3DIS.pth')
state = {
'epoch': epoch,
'model_state_dict': modelSS.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
torch.save(state, modelpath)
logger.info('Save model...'+modelpath)
#endregion
# region Evaluate on chopped scenes
with torch.no_grad():
num_batches = len(testDataLoader)
total_correct = 0
total_seen = 0
loss_sum = 0
labelweights = np.zeros(classNumber)
total_seen_class = [0 for _ in range(classNumber)]
total_correct_class = [0 for _ in range(classNumber)]
total_iou_deno_class = [0 for _ in range(classNumber)]
modelSS = modelSS.eval()
log_string('****** Epoch Evaluation %d (%d/%s) ******' % (global_epoch + 1, epoch + 1, args.epoch))
for i, (points, target) in tqdm(enumerate(testDataLoader), total=len(testDataLoader), smoothing=0.9):
points = points.data.numpy() # ndarray = bs,4096,9
points = torch.Tensor(points) # tensor = bs,4096,9
points, target = points.float().cuda(), target.long().cuda() # tensor = bs,4096,9 # tensor = bs,4096
points = points.transpose(2, 1) # tensor = bs,9,4096
seg_pred, trans_feat = modelSS(points) # tensor = bs,4096,13 # tensor = bs,512,16
pred_val = seg_pred.contiguous().cpu().data.numpy() # ndarray = bs,4096,13
seg_pred = seg_pred.contiguous().view(-1, classNumber) # tensor = bs*4096,13
batch_label = target.cpu().data.numpy() # ndarray = bs,4096
target = target.view(-1, 1)[:, 0] # tensor = bs*4096
loss = criterion(seg_pred, target, trans_feat, weights)
loss_sum += loss
pred_val = np.argmax(pred_val, 2) # ndarray = bs,4096
correct = np.sum((pred_val == batch_label))
total_correct += correct
total_seen += (batchSize * pointNumber)
tmp, _ = np.histogram(batch_label, range(classNumber + 1))
labelweights += tmp
for l in range(classNumber):
total_seen_class[l] += np.sum((batch_label == l))
total_correct_class[l] += np.sum((pred_val == l) & (batch_label == l))
total_iou_deno_class[l] += np.sum(((pred_val == l) | (batch_label == l)))
labelweights = labelweights.astype(np.float32) / np.sum(labelweights.astype(np.float32))
mIoU = np.mean(np.array(total_correct_class) / (np.array(total_iou_deno_class, dtype=np.float64) + 1e-6))
log_string('eval mean loss: %f' % (loss_sum / float(num_batches)))
log_string('eval point avg class IoU: %f' % (mIoU))
log_string('eval point accuracy: %f' % (total_correct / float(total_seen)))
log_string('eval point avg class acc: %f' % (
np.mean(np.array(total_correct_class) / (np.array(total_seen_class, dtype=np.float64) + 1e-6))))
iou_per_class_str = '------- IoU --------\n'
for l in range(classNumber):
iou_per_class_str += 'class %s weight: %.3f, IoU: %.3f \n' % (
seg_label_to_cat[l] + ' ' * (14 - len(seg_label_to_cat[l])), labelweights[l - 1],
total_correct_class[l] / float(total_iou_deno_class[l]))
log_string(iou_per_class_str)
log_string('Eval mean loss: %f' % (loss_sum / num_batches))
log_string('Eval accuracy: %f' % (total_correct / float(total_seen)))
# draw
valLoss = (loss_sum.item()) / num_batches
visdomVL.line([valLoss], [epoch+1], win=visdomVLwindow, update='append')
# region 根据 mIoU确定最佳模型
if mIoU >= best_iou:
best_iou = mIoU
bestmodelpath = ''
if PN2bool:
bestmodelpath = os.path.join(dirModel2, 'best_model_S3DIS.pth')
else:
bestmodelpath = os.path.join(dirModel1, 'best_model_S3DIS.pth')
state = {
'epoch': epoch,
'class_avg_iou': mIoU,
'model_state_dict': modelSS.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
torch.save(state, bestmodelpath)
logger.info('Save best model......'+bestmodelpath)
log_string('Best mIoU: %f' % best_iou)
#endregion
#endregion
global_epoch += 1
# draw
visdomTVL.line(X=[epoch+1], Y=[trainLoss],name="train loss", win='line', update='append',
opts=dict(showlegend=True, markers=False,
title='PointNet++ train validate loss',
xlabel='epoch', ylabel='loss'))
visdomTVL.line(X=[epoch+1], Y=[valLoss], name="train loss", win='line', update='append')
log_string('-------------------------------------------------\n\n')3.4 预测测试?test_SematicSegmentation.py
# 参考
# https://github.com/yanx27/Pointnet_Pointnet2_pytorch
import argparse
import sys
import os
import numpy as np
import logging
from pathlib import Path
import importlib
from tqdm import tqdm
import torch
import warnings
warnings.filterwarnings('ignore')
from dataset.S3DISDataLoader import ScannetDatasetWholeScene
from dataset.indoor3d_util import g_label2color
# PointNet
from PointNet2.pointnet_sem_seg import get_model as PNss
# PointNet++
from PointNet2.pointnet2_sem_seg import get_model as PN2SS
PN2bool = True
# PN2bool = False
# region 函数:投票;日志输出;保存结果为las。
# 投票决定结果
def add_vote(vote_label_pool, point_idx, pred_label, weight):
B = pred_label.shape[0]
N = pred_label.shape[1]
for b in range(B):
for n in range(N):
if weight[b, n] != 0 and not np.isinf(weight[b, n]):
vote_label_pool[int(point_idx[b, n]), int(pred_label[b, n])] += 1
return vote_label_pool
# 日志
def log_string(str):
logger.info(str)
print(str)
# save to LAS
import laspy
def SaveResultLAS(newLasPath, point_np, rgb_np, label1, label2):
# data
newx = point_np[:, 0]
newy = point_np[:, 1]
newz = point_np[:, 2]
newred = rgb_np[:, 0]
newgreen = rgb_np[:, 1]
newblue = rgb_np[:, 2]
newclassification = label1
newuserdata = label2
minx = min(newx)
miny = min(newy)
minz = min(newz)
# create a new header
newheader = laspy.LasHeader(point_format=3, version="1.2")
newheader.scales = np.array([0.0001, 0.0001, 0.0001])
newheader.offsets = np.array([minx, miny, minz])
newheader.add_extra_dim(laspy.ExtraBytesParams(name="Classification", type=np.uint8))
newheader.add_extra_dim(laspy.ExtraBytesParams(name="UserData", type=np.uint8))
# create a Las
newlas = laspy.LasData(newheader)
newlas.x = newx
newlas.y = newy
newlas.z = newz
newlas.red = newred
newlas.green = newgreen
newlas.blue = newblue
newlas.Classification = newclassification
newlas.UserData = newuserdata
# write
newlas.write(newLasPath)
# 超参数
def parse_args():
parser = argparse.ArgumentParser('Model')
parser.add_argument('--pnModel', type=bool, default=True, help='True = PointNet++;False = PointNet')
parser.add_argument('--batch_size', type=int, default=32, help='batch size in testing [default: 32]')
parser.add_argument('--GPU', type=str, default='0', help='specify GPU device')
parser.add_argument('--num_point', type=int, default=4096, help='point number [default: 4096]')
parser.add_argument('--test_area', type=int, default=5, help='area for testing, option: 1-6 [default: 5]')
parser.add_argument('--num_votes', type=int, default=1,
help='aggregate segmentation scores with voting [default: 1]')
return parser.parse_args()
#endregion
# 当前文件的路径
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
# 模型的路径
pathTrainModel = os.path.join(ROOT_DIR, 'trainModel/pointnet_model')
if PN2bool:
pathTrainModel = os.path.join(ROOT_DIR, 'trainModel/PointNet2_model')
# 结果路径
visual_dir = ROOT_DIR + '/testResultPN/'
if PN2bool:
visual_dir = ROOT_DIR + '/testResultPN2/'
visual_dir = Path(visual_dir)
visual_dir.mkdir(exist_ok=True)
# 日志的路径
pathLog = os.path.join(ROOT_DIR, 'LOG_test_eval.txt')
# 数据集的路径
pathDataset = os.path.join(ROOT_DIR, 'dataset/stanford_indoor3d/')
# 分割类别排序
classNumber = 13
classes = ['ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door', 'table', 'chair', 'sofa', 'bookcase',
'board', 'clutter']
class2label = {cls: i for i, cls in enumerate(classes)}
seg_classes = class2label
seg_label_to_cat = {}
for i, cat in enumerate(seg_classes.keys()):
seg_label_to_cat[i] = cat
if __name__ == '__main__':
#region LOG info
logger = logging.getLogger("test_eval")
logger.setLevel(logging.INFO) #日志级别:DEBUG, INFO, WARNING, ERROR, 和 CRITICAL
file_handler = logging.FileHandler(pathLog)
file_handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
#endregion
#region 超参数
args = parse_args()
args.pnModel = PN2bool
log_string('--- hyper-parameter ---')
log_string(args)
os.environ["CUDA_VISIBLE_DEVICES"] = args.GPU
batchSize = args.batch_size
pointNumber = args.num_point
testArea = args.test_area
voteNumber = args.num_votes
#endregion
#region ---------- 加载语义分割的模型 ----------
log_string("---------- Loading sematic segmentation model ----------")
ssModel = ''
if PN2bool:
ssModel = PN2SS(classNumber).cuda()
else:
ssModel = PNss(classNumber).cuda()
path_model = os.path.join(pathTrainModel, 'best_model_S3DIS.pth')
checkpoint = torch.load(path_model)
ssModel.load_state_dict(checkpoint['model_state_dict'])
ssModel = ssModel.eval()
#endregion
# 模型推断(inference)或评估(evaluation)阶段,不需要计算梯度,而且关闭梯度计算可以显著减少内存占用,加速计算。
log_string('--- Evaluation whole scene')
with torch.no_grad():
# IOU 结果
total_seen_class = [0 for _ in range(classNumber)]
total_correct_class = [0 for _ in range(classNumber)]
total_iou_deno_class = [0 for _ in range(classNumber)]
# 测试区域的所有文件
testDataset = ScannetDatasetWholeScene(pathDataset, split='test', test_area=testArea, block_points=pointNumber)
scene_id_name = testDataset.file_list
scene_id_name = [x[:-4] for x in scene_id_name] # 名称(无扩展名)
testCount = len(scene_id_name)
testCount = 1
# 遍历需要预测的物体
for batch_idx in range(testCount):
log_string("Inference [%d/%d] %s ..." % (batch_idx + 1, testCount, scene_id_name[batch_idx]))
# 数据
whole_scene_data = testDataset.scene_points_list[batch_idx]
# 真值
whole_scene_label = testDataset.semantic_labels_list[batch_idx]
whole_scene_labelR = np.reshape(whole_scene_label, (whole_scene_label.size, 1))
# 预测标签
vote_label_pool = np.zeros((whole_scene_label.shape[0], classNumber))
# 同一物体多次预测
for _ in tqdm(range(voteNumber), total=voteNumber):
scene_data, scene_label, scene_smpw, scene_point_index = testDataset[batch_idx]
num_blocks = scene_data.shape[0]
s_batch_num = (num_blocks + batchSize - 1) // batchSize
batch_data = np.zeros((batchSize, pointNumber, 9))
batch_label = np.zeros((batchSize, pointNumber))
batch_point_index = np.zeros((batchSize, pointNumber))
batch_smpw = np.zeros((batchSize, pointNumber))
for sbatch in range(s_batch_num):
start_idx = sbatch * batchSize
end_idx = min((sbatch + 1) * batchSize, num_blocks)
real_batch_size = end_idx - start_idx
batch_data[0:real_batch_size, ...] = scene_data[start_idx:end_idx, ...]
batch_label[0:real_batch_size, ...] = scene_label[start_idx:end_idx, ...]
batch_point_index[0:real_batch_size, ...] = scene_point_index[start_idx:end_idx, ...]
batch_smpw[0:real_batch_size, ...] = scene_smpw[start_idx:end_idx, ...]
batch_data[:, :, 3:6] /= 1.0
torch_data = torch.Tensor(batch_data)
torch_data = torch_data.float().cuda()
torch_data = torch_data.transpose(2, 1)
seg_pred, _ = ssModel(torch_data)
batch_pred_label = seg_pred.contiguous().cpu().data.max(2)[1].numpy()
# 投票产生预测标签
vote_label_pool = add_vote(vote_label_pool, batch_point_index[0:real_batch_size, ...],
batch_pred_label[0:real_batch_size, ...],
batch_smpw[0:real_batch_size, ...])
# region 保存预测的结果
# 预测标签
pred_label = np.argmax(vote_label_pool, 1)
pred_labelR = np.reshape(pred_label, (pred_label.size, 1))
# 点云-真值-预测标签
pcrgb_ll = np.hstack((whole_scene_data, whole_scene_labelR, pred_labelR))
# ---------- 保存成 txt ----------
pathTXT = os.path.join(visual_dir, scene_id_name[batch_idx] + '.txt')
np.savetxt(pathTXT, pcrgb_ll, fmt='%f', delimiter='\t')
log_string('save:' + pathTXT)
# ---------- 保存成 las ----------
pathLAS = os.path.join(visual_dir, scene_id_name[batch_idx] + '.las')
SaveResultLAS(pathLAS, pcrgb_ll[:,0:3], pcrgb_ll[:,3:6], pcrgb_ll[:,6], pcrgb_ll[:,7])
log_string('save:' + pathLAS)
# endregion
# IOU 临时结果
total_seen_class_tmp = [0 for _ in range(classNumber)]
total_correct_class_tmp = [0 for _ in range(classNumber)]
total_iou_deno_class_tmp = [0 for _ in range(classNumber)]
for l in range(classNumber):
total_seen_class_tmp[l] += np.sum((whole_scene_label == l))
total_correct_class_tmp[l] += np.sum((pred_label == l) & (whole_scene_label == l))
total_iou_deno_class_tmp[l] += np.sum(((pred_label == l) | (whole_scene_label == l)))
total_seen_class[l] += total_seen_class_tmp[l]
total_correct_class[l] += total_correct_class_tmp[l]
total_iou_deno_class[l] += total_iou_deno_class_tmp[l]
iou_map = np.array(total_correct_class_tmp) / (np.array(total_iou_deno_class_tmp, dtype=np.float64) + 1e-6)
print(iou_map)
arr = np.array(total_seen_class_tmp)
tmp_iou = np.mean(iou_map[arr != 0])
log_string('Mean IoU of %s: %.4f' % (scene_id_name[batch_idx], tmp_iou))
IoU = np.array(total_correct_class) / (np.array(total_iou_deno_class, dtype=np.float64) + 1e-6)
iou_per_class_str = '----- IoU -----\n'
for l in range(classNumber):
iou_per_class_str += 'class %s, IoU: %.3f \n' % (
seg_label_to_cat[l] + ' ' * (14 - len(seg_label_to_cat[l])),
total_correct_class[l] / float(total_iou_deno_class[l]))
log_string(iou_per_class_str)
log_string('eval point avg class IoU: %f' % np.mean(IoU))
log_string('eval whole scene point avg class acc: %f' % (
np.mean(np.array(total_correct_class) / (np.array(total_seen_class, dtype=np.float64) + 1e-6))))
log_string('eval whole scene point accuracy: %f' % (
np.sum(total_correct_class) / float(np.sum(total_seen_class) + 1e-6)))
log_string('--------------------------------------\n\n')
文章来源:https://blog.csdn.net/xinjiang666/article/details/135660104
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 探索雷盛537威士忌的魅力:从观色、闻香到品鉴
- 大创项目推荐 深度学习疲劳检测 驾驶行为检测 - python opencv cnn
- 【矩阵论】Chapter 9—广义逆矩阵知识点总结复习
- Sqoop安装与配置-shell脚本一键安装配置
- Android 车联网——CarUserService介绍(十三)
- 【Java基础_01】Java运行机制及运行过程
- 您的项目应该选用哪一种编程语言?深入对比PHP与Python
- Go 语言中并发的威力
- 基于单片机的室内空气质量检测系统设计与实现
- 监控oracle表空间是否超过80%