AI大模型
目录
前言
AI零基础直播公开课,了解一下。
AGI通用人工智能
query
chatmind.tech




找一下这篇论文,了解一下

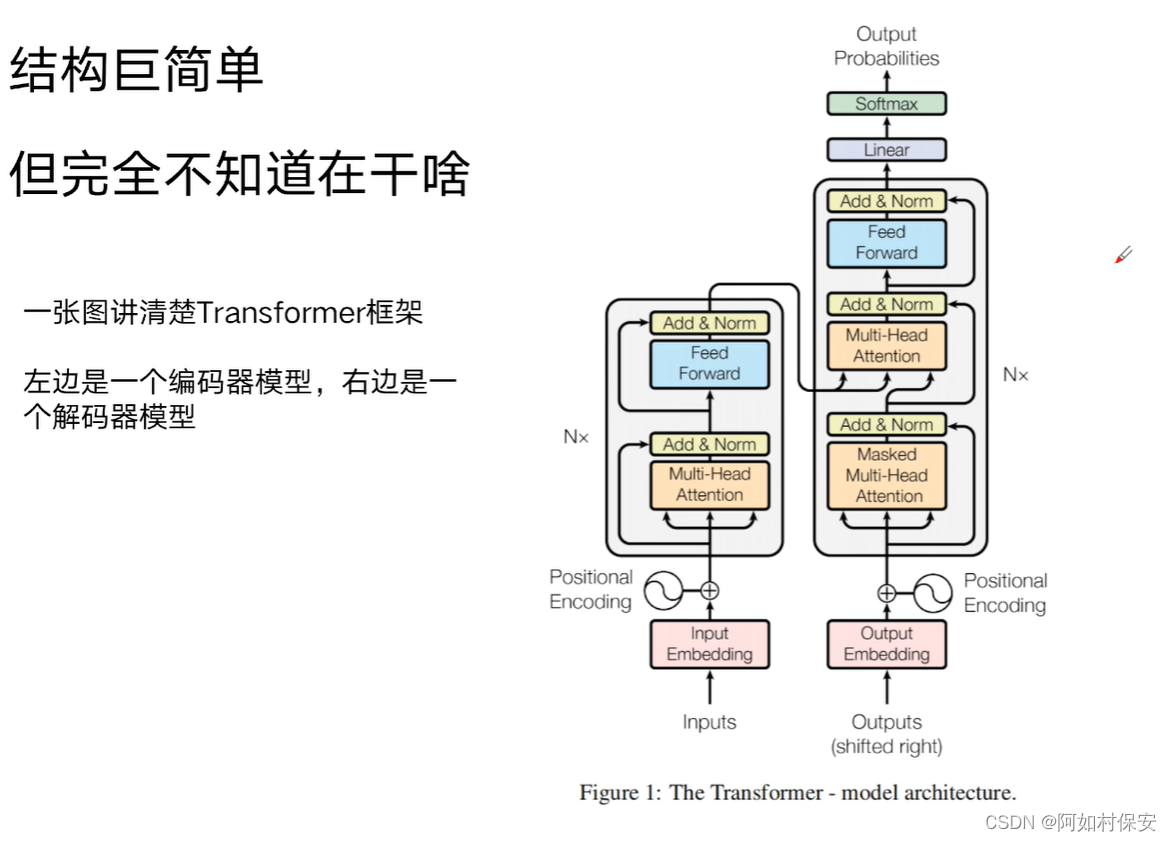
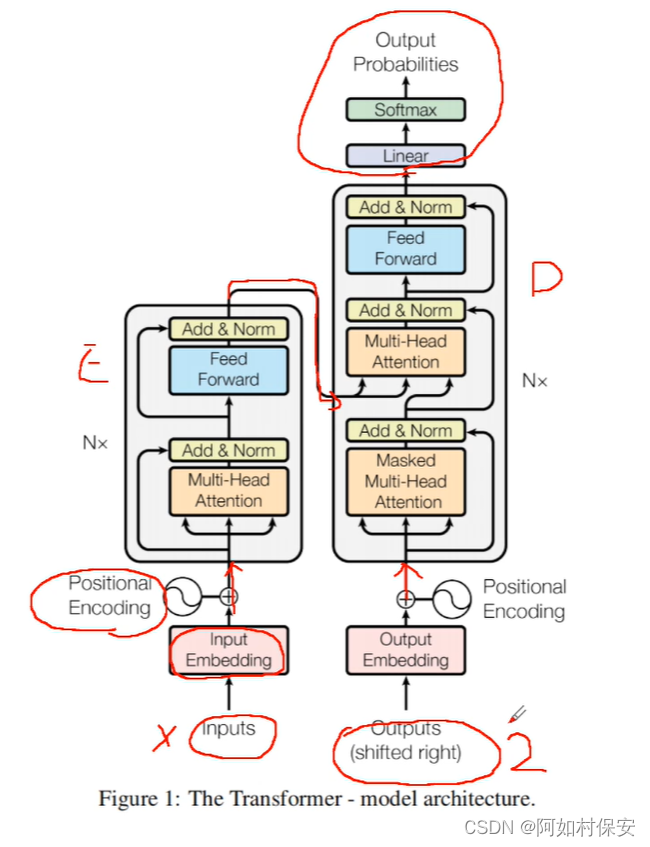
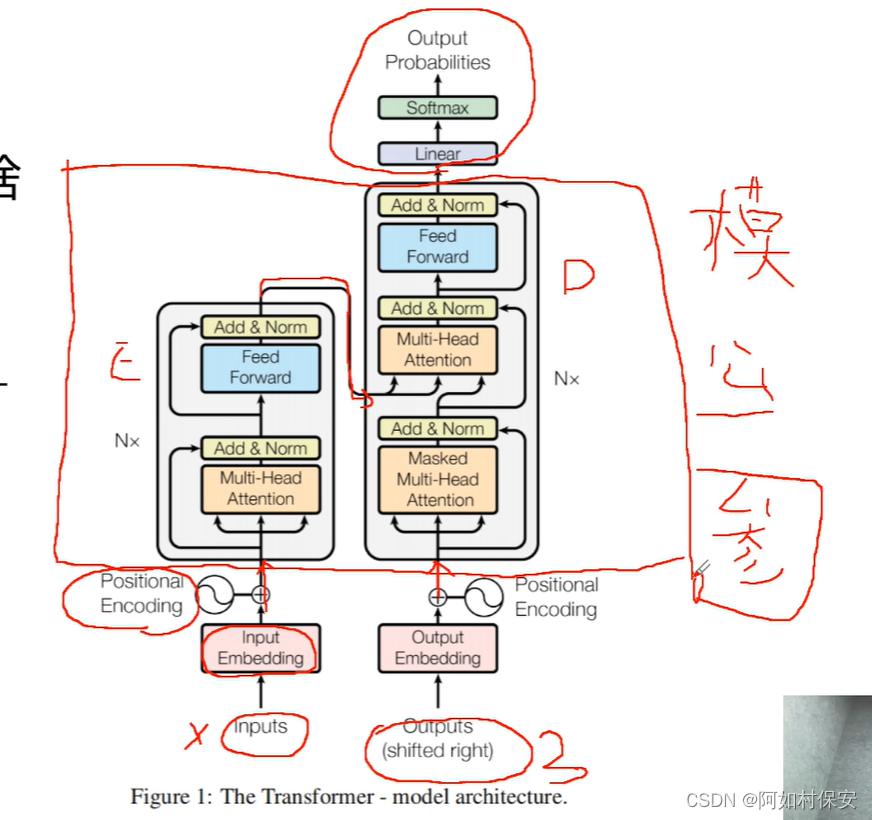
E为编码器,D为解码器
所谓大模型也就是编码器-解码器。
模型里会有一些公式和参数,厉害的模型是参数比较靠谱。
所谓的机器学习训练模型就是去调整参数(这里之前我好像弄过一个预测模型,确实如此)。
GPT3.5有1750亿个参数。
Google这篇论文很好:
????????1.它的编码器和解码器的结构让事情变简单了,参数变少。里面有个K矩阵,二维数组,类似于空间字典的作用。
????????2.它的注意力机制,也就是权重问题,V矩阵,数值记录权重。这里的多投自注意力机制,也就是机器自己学习找到语义。
很多人工智能工程师更多是处理某些特定场景,距离agi也就是通用性的AI。
CV已死?算法工程师很多时候是给机器做助理工作的,比如视觉工程师,先预处理,边缘提取等等,就是给机器找权重,自注意力机制(transformer的基础)能跨语言到视觉等的多模态,提取比较重要的东西,所以视觉工程师可能会更早的失业。


技术分层:
1、指令工程,总结和大模型对话的讨论方法;AI编程,AI自动化测试
2、向量数据库,向量检索,autoGPT,github copolit等,场景比较广泛
3、fine-tune,自有数据对模型进行精调,比较难。
下面是fine-tune的原理图(来源于ChatGPT3.5论文)
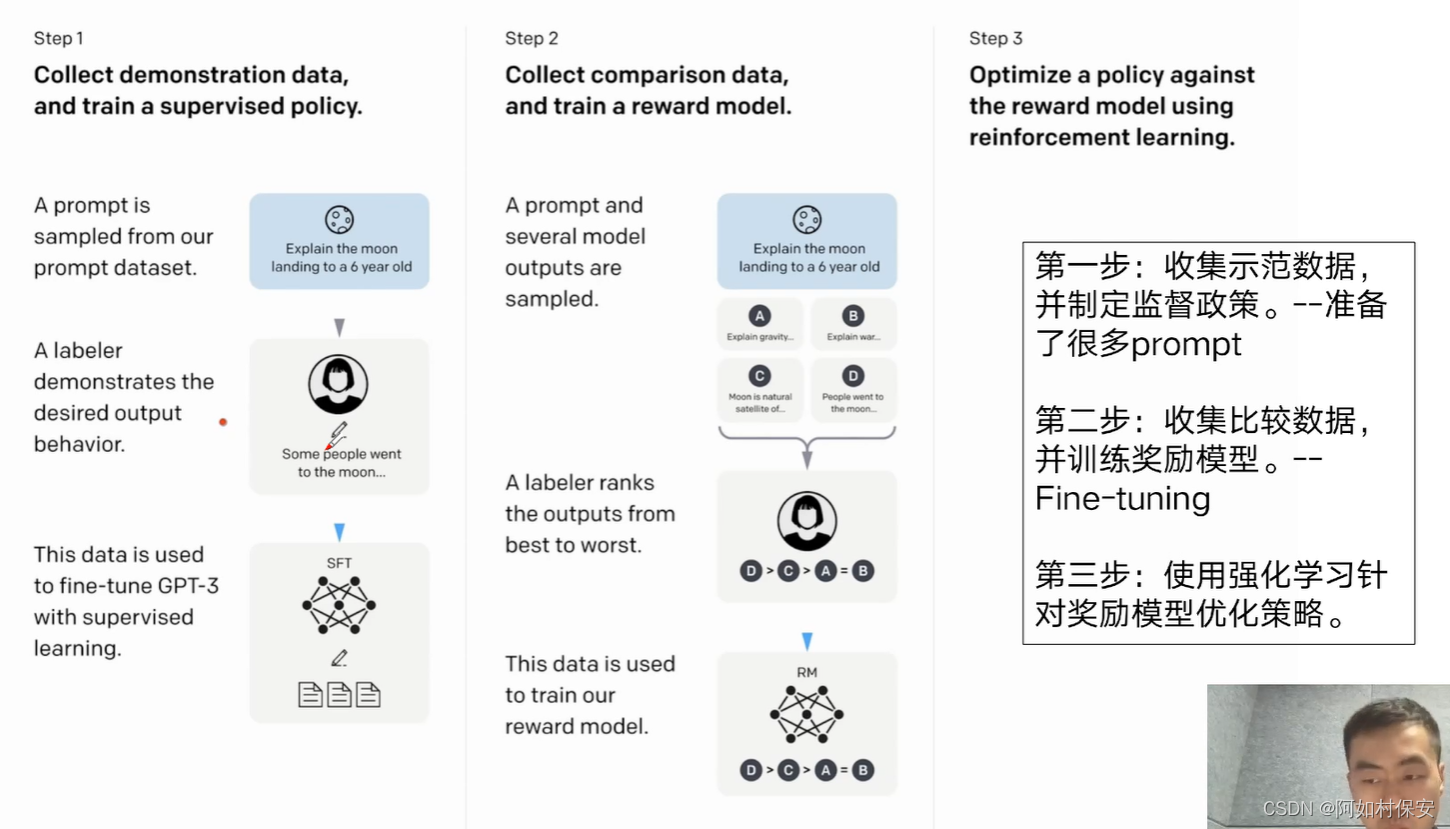
第一步,雇了很多标注师,一问一答,进行模型精调(参数精调),教授知识。
第二步和第三步反复循环,调教“大脑”。RLHF,强化学习,人类反馈(human feelback这个很重要)。
midjourney可以试试。

之后试试二次开发哈哈哈哈。三万三千条rlhf就能做一轮fine-tune。
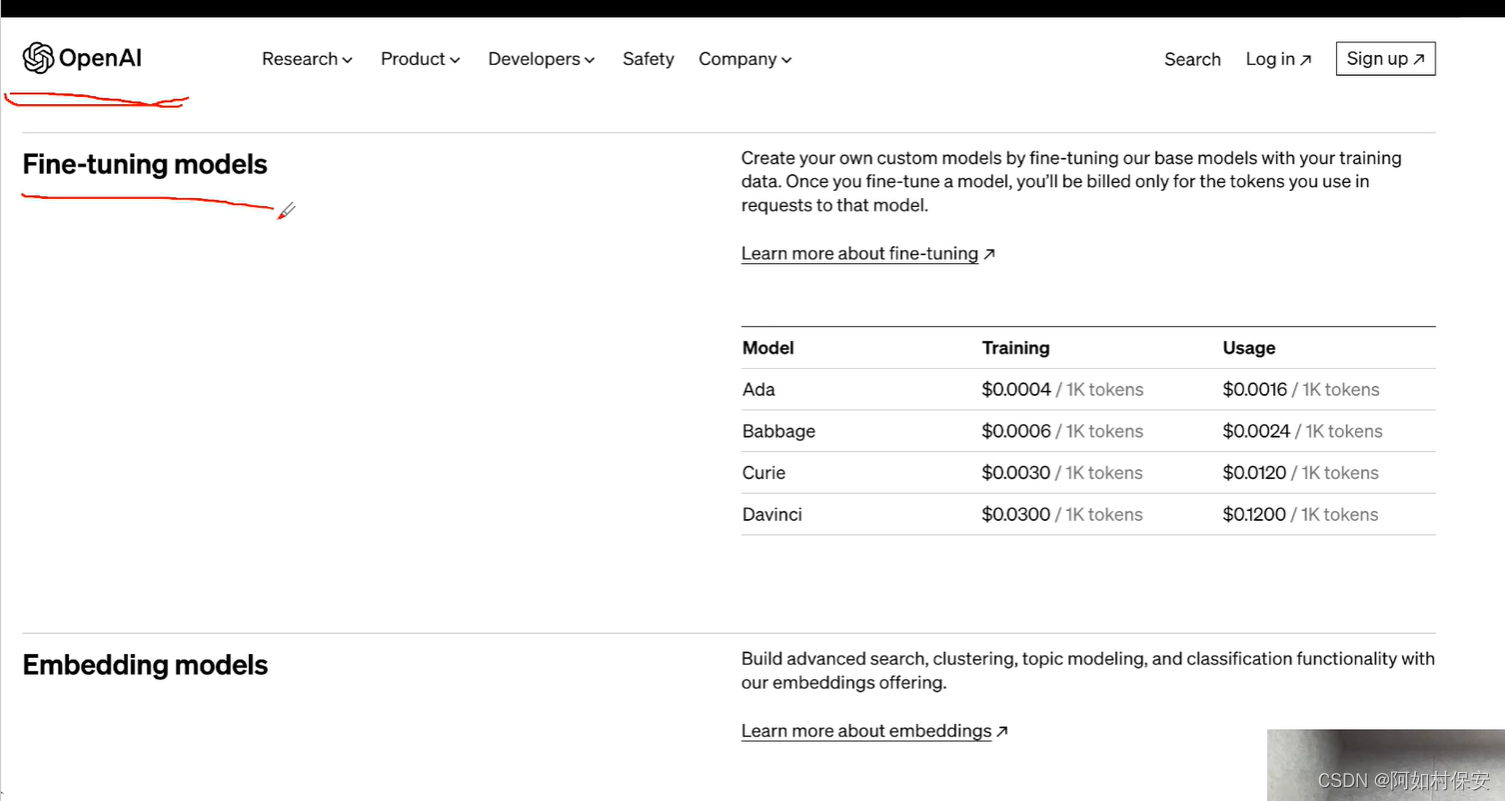
在openai上能直接做fine-tune。但是由于有墙,国内不会用这个。(还有数据泄露的风险)
可以选择一些开源的模型,智谱华章的ChatGLM还有Facebook的LLaMA 7B。
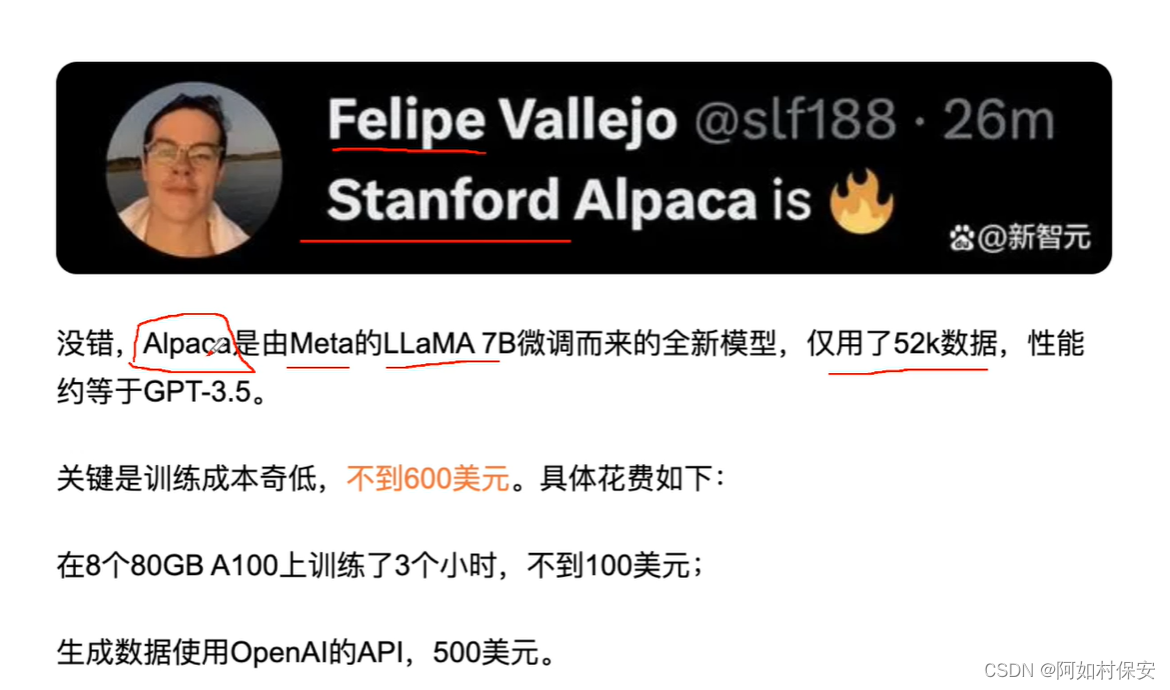
这个人的羊驼,他只用了70亿的参数。
可以用阿里云做二次开发。低成本且高效。
公司比较缺大模型产品方案,比较重要:
1、畅想的场景什么比较靠谱
2、靠谱的场景需要什么技术(上面说到的技术)
3、能实践的效果
4.成本
5.数据整理,什么好数据等数据过滤
6.需要什么框架进行fine-tune
7.需要几轮,多长时间
8.性能效果,最后效果
9.商业化,投产比。
总结
主要是想了解一下大模型。后续去GitHub上看看chatALL.ai吧,感兴趣就多去了解下大模型。还有一个重要收获是我现在正在搞CV啊,太难受了,太难受了,或许激光雷达或者GPSins方向是可以深耕的,加油吧,早日毕业。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!