大数据-Zookeeper 安装步骤(亲测保成功)
🐶第 2 章 Zookeeper 本地安装步骤
1. 上传到hadoop01上面的apps包下面
[root@hadoop01 current]# cd /opt/apps
2. 解压该文件
tar -zxvf zookeeper-3.4.6.tar.gz
3. 配置服务器编号
在/opt/apps/zookeeper-3.4.6/这个目录下创建 zkData
# 以后zkData就是我们存储数据的目录
[root@hadoop01 apps]# cd zookeeper-3.4.6/
[root@hadoop01 apps]# mkdir zkData
4. 在/opt/apps/zookeeper-3.4.6/zkData 目录下创建一个 myid 的文件
[root@hadoop01 zookeeper-3.4.6]# cd zkData/
[root@hadoop01 zookeeper-3.4.6]# touch myid
5. 添加一个id,代表本地的id值
# myid代表zookeeper在集群中的排号
vi myid
1 #上下不要有空行
6. 重命名/opt/apps/zookeeper-3.4.6/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
# 配置文件模板
mv zoo_sample.cfg zoo.cfg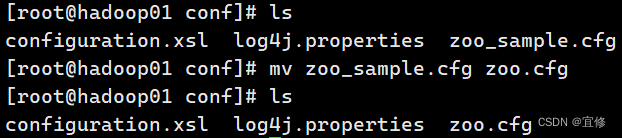
7. 打开 zoo.cfg 文件,修改数据存储路径配置,增加如下配置
vi zoo.cfg
dataDir=/opt/apps/zookeeper-3.4.6/zkData #修改数据存储路径配置,这里的路径即为刚刚创建zkData文件夹的路径
#增加如下配置(在最下面添加)
#######################cluster##########################
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
配置参数解读 server.A=B:C:D。
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 zkData目录下,这个文件里面有一个数据 就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比 较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
配置参数解读 Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
-
tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
-
initLimit = 10:LF初始通信时限 Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
-
syncLimit = 5:LF同步通信时限 Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死 掉,从服务器列表中删除Follwer。
-
dataDir:保存Zookeeper中的数据 注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
-
clientPort = 2181:客户端连接端口,通常不做修改
8. 拷贝配置好的 zookeeper 到其他机器上(在apps目录下分发)
scp -r zookeeper-3.4.6 hadoop02:$PWD
scp -r zookeeper-3.4.6 hadoop03:$PWD
9. 配置环境变量 vi /etc/profile
export ZOO_HOME=/opt/apps/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SH_HOME:$ZOO_HOME/binsource /etc/profile10. 分发环境变量
[root@hadoop01 zookeeper-3.4.6]# scp -r /etc/profile hadoop02:/etc
[root@hadoop01 zookeeper-3.4.6]# scp -r /etc/profile hadoop03:/etc11. 不要忘记修改在每台虚拟机中myid然后再启动
zookeeper的启动必须要在bin包下面
🐶第 3 章 Zookeeper 集群操作
1. 进入zookeeper-3.4.6目录下,启动zookeeper服务端:
bin/zkServer.sh start通过jps可以查看是否启动成功
[root@hadoop01 zookeeper-3.4.6]# jps
2. 查看状态
需要将上面的命令在每台服务器上开始,再查看状态
bin/zkServer.sh status可以看出该主机属于leader/follower


3. 一键启停脚本
#!/bin/bash
flag=$1
if [ $flag == "start" ]
then
for host in hadoop01 hadoop02 hadoop03
do
echo ********$host正在启动zk********
ssh $host "source /etc/profile;zkServer.sh start;exit"
done
elif [ $flag == "stop" ]
then
for host in hadoop01 hadoop02 hadoop03
do
echo ********$host正在关闭zk********
ssh $host "source /etc/profile;zkServer.sh stop;exit"
done
elif [ $flag == "status" ]
then
for host in hadoop01 hadoop02 hadoop03
do
echo ********$host的zk状态********
ssh $host "source /etc/profile;zkServer.sh status;exit"
done
fi4. 在mkdir目录下创建一个zookeeper-all.sh文件,将上述代码粘贴进去.再授予他全部权限
[root@hadoop01 scripterDir]# vi zookeeper-all.sh
[root@hadoop01 scripterDir]# chmod 777 zookeeper-all.sh5. 将其分发到其他服务器上
scp -r zookeeper-all.sh hadoop02:$PWD
scp -r zookeeper-all.sh hadoop03:$PWD
scp -r scripterDir hadoop03:$PWD6. 此时通过以下命令便可以一键启停了
一键开始
[root@hadoop01 scripterDir]# zookeeper-all.sh start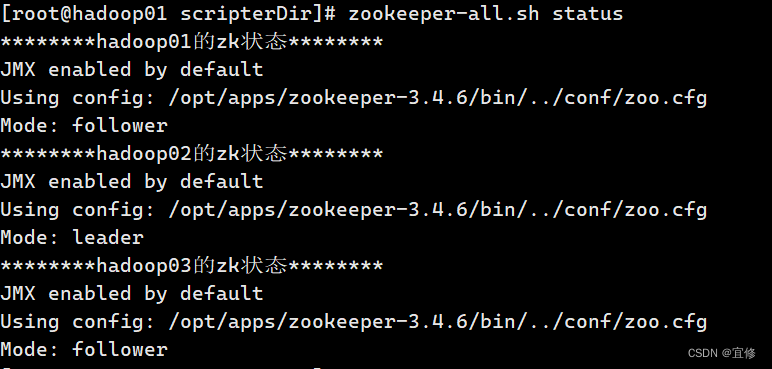
查看集群状态
[root@hadoop01 scripterDir]# zookeeper-all.sh status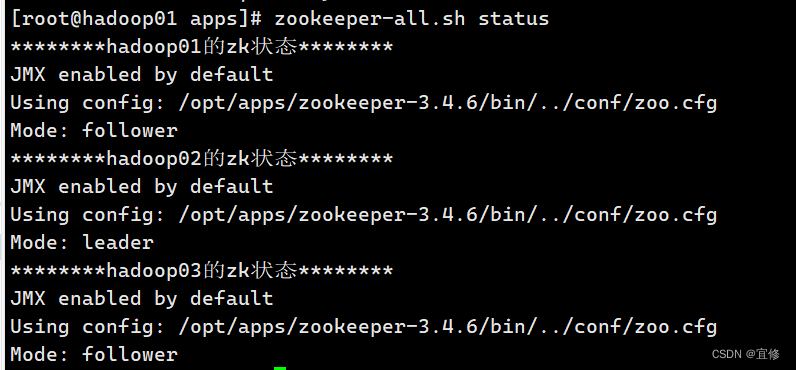
一键关闭
[root@hadoop01 scripterDir]# zookeeper-all.sh stop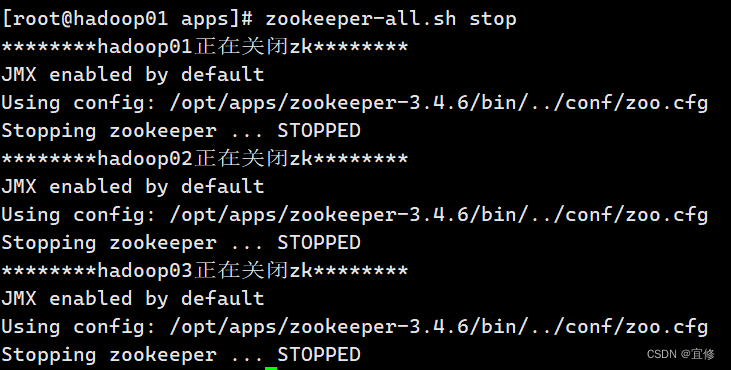
7. 启动客户端
zkCli.sh -server hadoop01:2181 
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!