C语言--单链表的创建及使用详解
C语言--单链表的创建及使用详解
1. 单链表定义
单链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
每个节点只能访问其后继节点,而无法访问前驱节点。链表的头节点是第一个节点,尾节点是最后一个节点,尾节点的指针指向空值。
1.1 工作原理
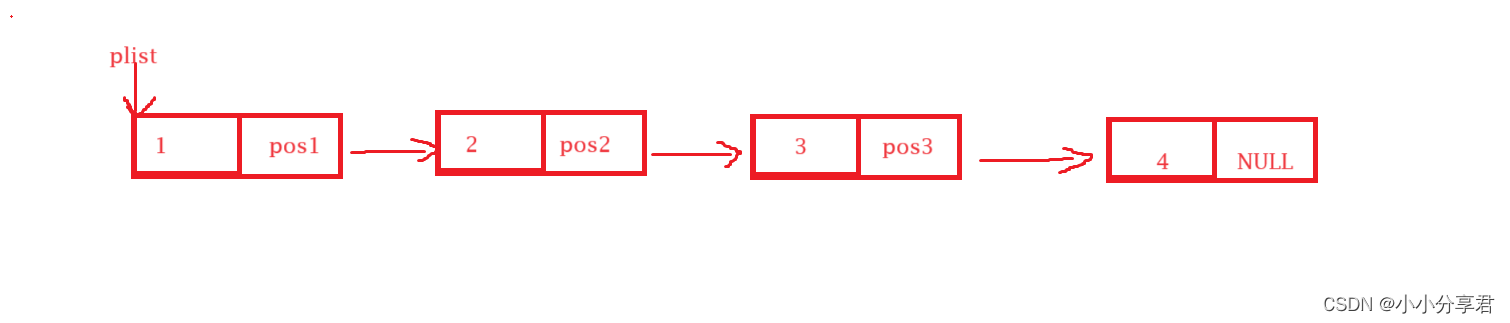
其工作原理如下图,它每个模块有两个部分组成,前面存放数据,最后存放下一个数据的地址。当我们想要访问下一个节点中的数据的时候,只需要通过前一个数据存放的下一个数据的地址就可以直接进行访问数据。
在数单链表的最前端有一个 plist 的指针,它会一直记录着链表第一个数据的地址,当我们想要访问链表中的数据的时候,只要通过 plist 就可以成功进入到链表当中。而刚开始创建链表的时候,头数据不存在,因而创建的 plist 要初始化为NULL,形式如下:
SLTNode* plist = NULL; //plist为头数据的地址
1.2 优点
与顺序表相比,单链表内存空间利用率更高,单向链表的每个节点只需要存储数据和指向下一个节点的指针,不需要预先分配固定大小的内存空间,因此可以灵活地利用内存空间,避免了顺序表需要预留固定大小的问题。
2. 单链表的创建
2.1 文件创建
为方便代码管理,将文件内容分为三个文件来共同组成单链表,如下:
test.c //用于?件中单链表的逻辑测试
SList.c //?件中写单链表中函数的实现等
SList.h //?件中写单链表需要的数据类型和函数声明等
为了方便后期对单链表中数据及数据类型的修正,可以将数据类型等信息进行宏定义,如下所示:
typedef int SLTDataType;//定义数据类型
struct SListNode//创建单链表
{
SLTDataType data;//保存数据
struct SListNode* next;//指向下一个数据的位置
};
typedef struct SListNode SLTNode;//定义结构体名称
SLTNode* plist = NULL;//plist为头数据的地址
在数据放入创建的链表之前,单链表的所有内容为空,在物理意义上是不存在的,其首地址的数据地址是不存在的,只有当放入数据之后,才会存在地址。因而,头数据的地址的创建如下所示:
SLTNode* plist = NULL;//plist为头数据的地址
2.2 节点创建
如果要插入数据,要么首先要开辟一块新的链表数据块,也就是创建一个结构体类型的数据,用一个 newnode 的指针保存其起始位置的地址,其指向下一个数据的指针置空,此时只是创建,并无下一个数据的链接。

代码实现如下:
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* newcode = (SLTNode*)malloc(sizeof(SLTNode));
newcode->data = x;
newcode->next = NULL;
return newcode;
}
先用 malloc 开辟一个结构体类型的空间,用 newnode 来接收其起始位置,之后将需要保存的数据放到newnode 的 data 当中,next 置空,然后再返回 newnode 的地址,这样,一个链表块就创建完毕。
需要注意的是,因为我们要返回的是 newnode 的地址,因而创建的开辟函数的数据类型是 SLTNode* 类型,即结构体指针类型。
2.3 链表显示
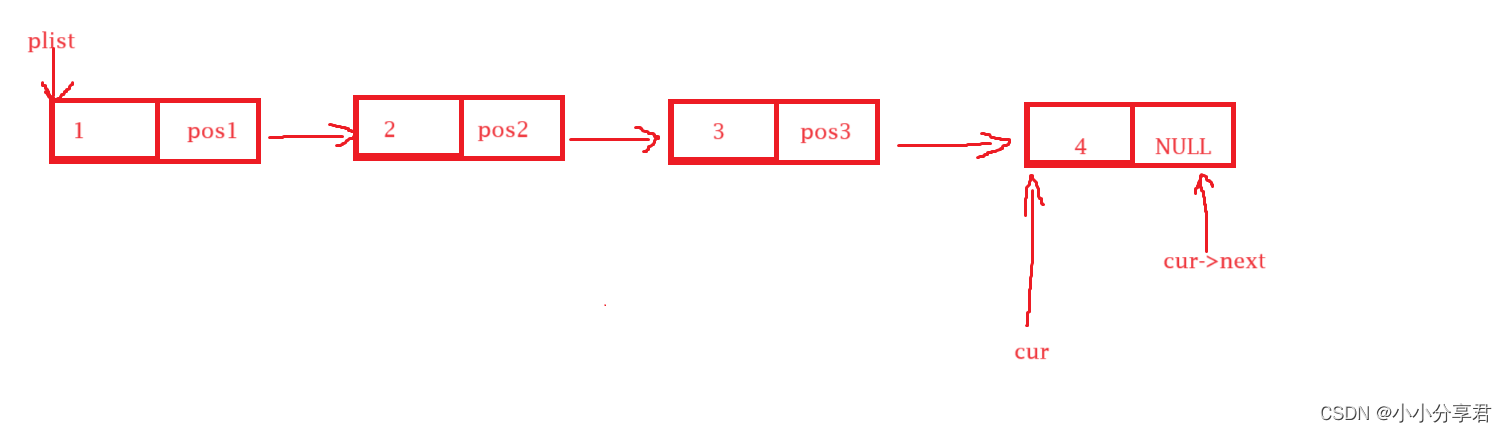
用形参 phead 来接收整个链表的头地址 plist 的值,通过 phead 来访问显示链表中的数据。
代码如下:
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
注意以下几点:
- 创建临时变量 cur 接收 phead 的地址(也可以直接通过 phead 进行操作)
- 因为最后一个数据的指针是置空的,因而结束的标志是访问的数据块里面 next 指向的地址为NULL。
- cur 通过将自己的地址改为 cur 里面 next 里面保存的地址来达到指向下一个数据的目的。
- 最后最好打印一个 NULL,避免链表为空时,什么都不执行,不好判断是否出错。
3. 链表操作
3.1 尾插
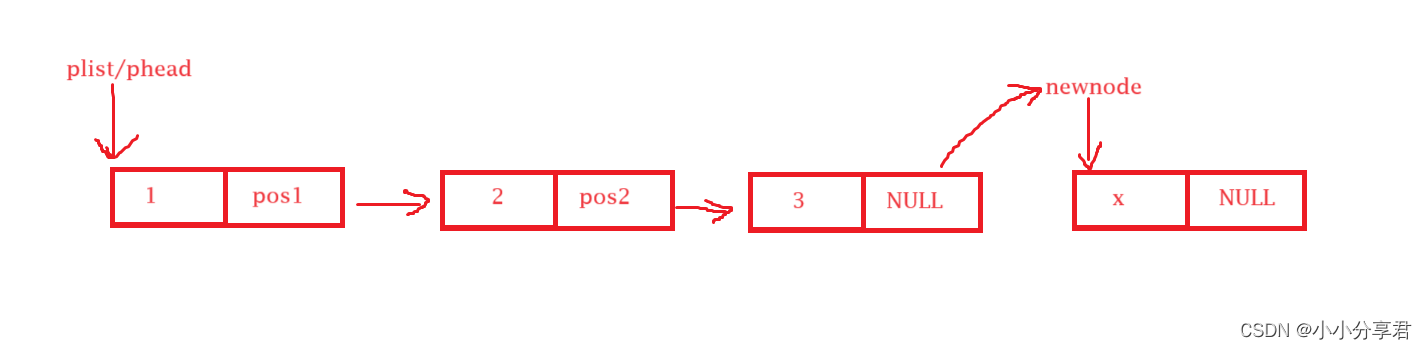
在链表尾部插入一个数据块时,要先找到最后一个数据块,然后将最后一个数据块的 next 由置空改为指向新创建的数据块的首地址,如图所示。
代码如下:
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newcode=BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newcode;
}
else
{
//找尾节点的指针
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
//尾节点,链接新节点
tail->next = newcode;
}
}
注意以下几点:
- 函数的变量一定要将链表的首地址的地址传递过去,也就是
SLTNode** pphead是二级指针,不再是直接使用 phead 这个一级指针。因为当链表为空的时候,往链表里面放数据之后,链表首地址 plist 应该改为指向新数据的首地址,而不再应该是被置空。而函数中是对形参 phead 进行操作,出函数之后,phead 的内容将被清除,实参 pliast 将依然指向NULL。如果不考虑数据为空的情况,那依然可以只传递 phead 过去,只对其所指的内容进行修改。以上情况适用于后面的其他操作。- 创建临时变量 newnode 来接收新开辟的数据块的起始地址.
- 当链表为空的时候,此时链表的头位置也为空,此时只需要直接将 newnode 的地址传递给整个链表的起始地址 plist 即可,即传递给 *pphead.
- 通过和链表显示一样的操作找到尾节点,将尾节点的 next 指向 newnode 便可以完成链接。
3.2 头插
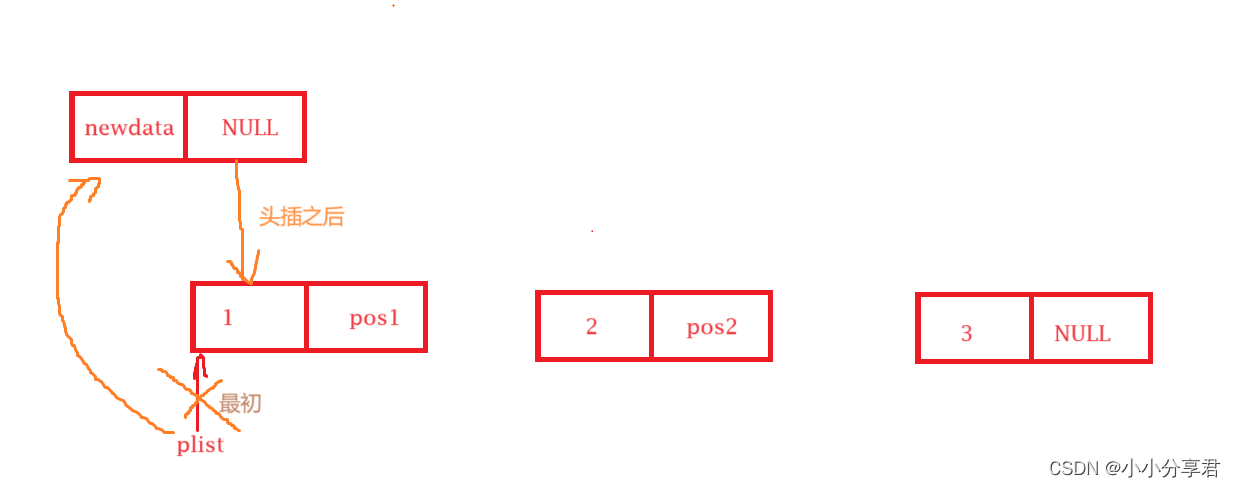
头插只需要将整个链表的头地址改为新的数据块的地址,再将数据块的 next 指向之前的头地址,便可以完成链接,需要注意与尾插的注意一相同的问题即可,如下同。
代码如下:
void SListPushFont(SLTNode** pphead, SLTDataType x)
{
SLTNode* newcode = BuySListNode(x);
newcode->next = *pphead;
*pphead = newcode;
}
3.3 尾删
删除尾部数据块 tail 时,需要先找到倒数第二的数据块的地址 prev ,将倒数第二的数据块 prev 的 next 置空,然后将最后一个数据块 tail 释放掉,过程如下图:
void SListPophBack(SLTNode** pphead)
{
//1、空的时候
if (*pphead == NULL)
{
return;
}
//2、只有一个节点
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//3、一个以上的节点
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
注意以下几点:
- 当链表为空的时候,直接返回,不做任何操作。
- 当判断链表只有一个节点的时候,直接释放链表数据,然后置空。
- 当链表有多个数据的时候,找到倒数第二个数据,改变链接,释放最后一个数据。
- 注意与头插注意一相同的问题。
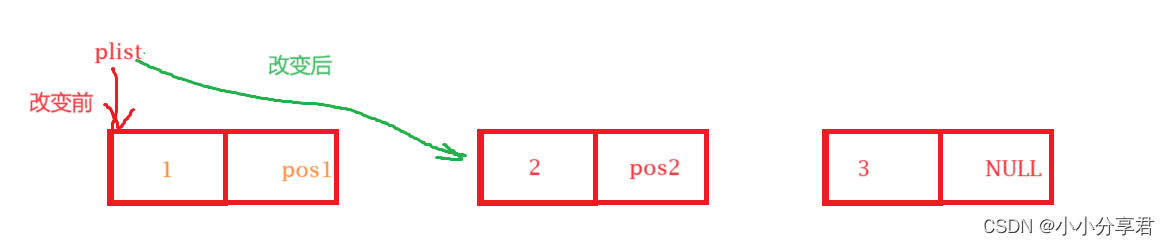
3.4 头删
头部删除只需要将整个链表首地址改为第一块数据块指向的 next 即可,仍旧需要主要传值问题。
代码如下:
void SListPopFront(SLTNode** pphead)
{
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
3.5 指定数据寻找
寻找指定的数据时,我们只是对数据进行查阅,不会更改首地址 plist 的地址,因而只需要使用phead 进行操作。从第一个数据开始寻找,如果找到了,就返回数据的地址,如果到尾了仍旧没有,则直接返回NULL,表示所寻找的数据不存在。
代码如下:
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
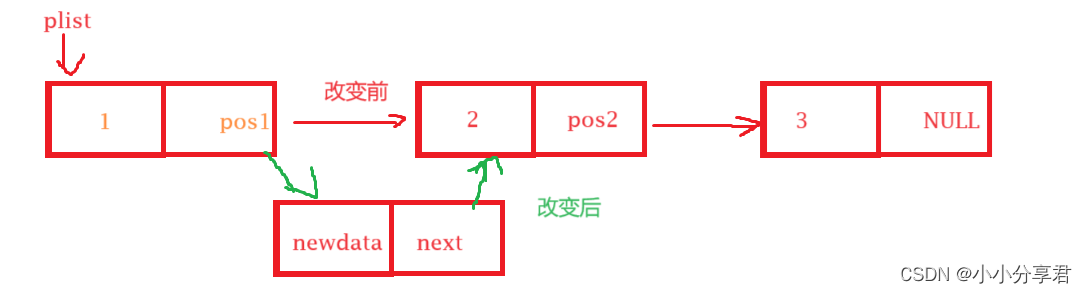
3.6 指定位置前插入
在指定位置 pos 前面插入一个数据,需要把指定数据的位置地址传进去。考虑到链表可能为空的情况,因而要使用二级指针 pphead 。用 prev 来寻找指定位置 pos 的前一个节点,找到之后,将 prev 的 next 指向新开辟的 newnode ,将 newnode 的 next 指向 pos ,这样就i完成了链接,如下图。
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
if (pos ==* pphead)
{
SListPushFont(pphead,x);
}
else
{
SLTNode* newcode = BuySListNode(x);
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newcode;
newcode->next = pos;
}
}
使用案例:
SLTNode* pos = SListFind(plist, 3);
if (pos)
{
SListInsert(&plist, pos, 30);
}
SListPrint(plist);
3.7 指定位置删除
在指定位置 pos 前面插入一个数据,需要把指定数据的位置地址传进去。考虑到链表可能为空的情况,因而要使用二级指针 pphead 。如果第一个数据就是指定数据,则直接使用头删,如果不是,仍旧需要找到指定数据 pos 的前一个数据,将pos 前一个数据和 pos 的后一个数据链接起来,过程与指定位置插入相似。。
void SListErase(SLTNode** pphead, SLTNode* pos)
{
if (pos == *pphead)
{
SListPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
}
}
4. 单链表总内容
4.1 test.c文件
测试文件,可根据自己需要添加内容。
//test.c文件
#define _CRT_SECURE_NO_WARNINGS
#include "SList.h"
void TestSList1()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPophBack(&plist);
SListPopFront(&plist);
SListPushFont(&plist, 0);
SListPrint(plist);
}
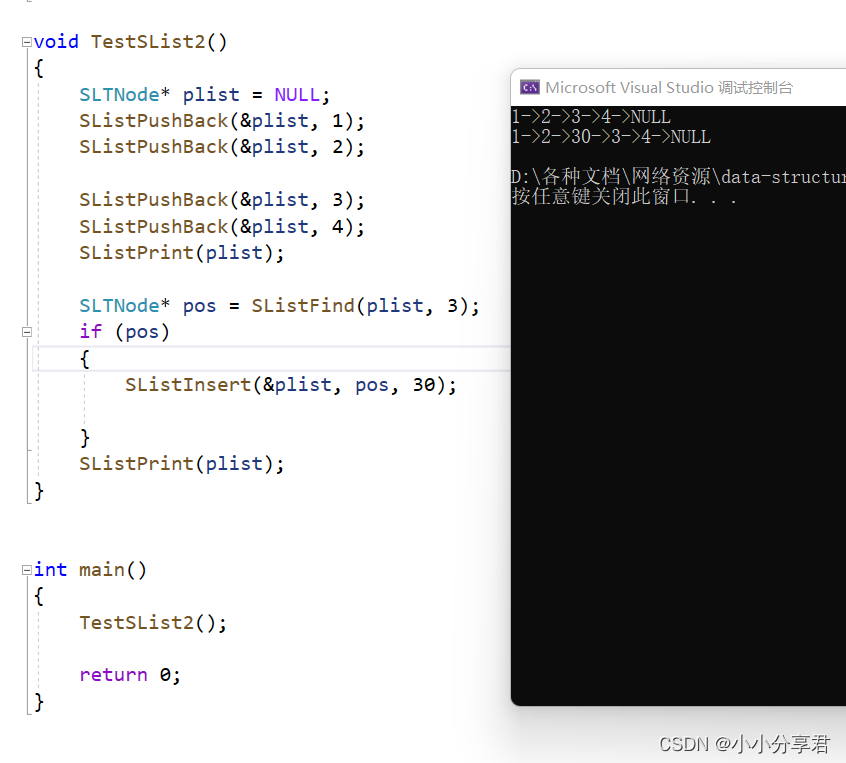
void TestSList2()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPrint(plist);
SLTNode* pos = SListFind(plist, 3);
if (pos)
{
SListInsert(&plist, pos, 30);
}
SListPrint(plist);
}
int main()
{
TestSList2();
return 0;
}
当前 test.c 文件演示效果:
4.2 SList.h文件
函数声明文件,用于结构体和宏定义。
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef int SLTDataType;
struct SListNode
{
SLTDataType data;
struct SListNode* next;
};
typedef struct SListNode SLTNode;
//不会改变链表的头指针,传一级指针
SLTNode* BuySListNode(SLTDataType x);
void SListPrint(SLTNode* phead);
//会改变链表的头指针,传二级指针
void SListPushBack(SLTNode** pphead, SLTDataType x);
void SListPushFont(SLTNode** pphead, SLTDataType x);
void SListPopFront(SLTNode** pphead);
void SListPophBack(SLTNode** pphead);
SLTNode* SListFind(SLTNode* phead, SLTDataType x);
//在pos的前面插入x
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//删除pos位置的值
void SListErase(SLTNode** pphead, SLTNode* pos);
4.3 SList.c文件
函数定义文件,用于定义函数。
#define _CRT_SECURE_NO_WARNINGS
#include "SList.h"
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* newcode = (SLTNode*)malloc(sizeof(SLTNode));
newcode->data = x;
newcode->next = NULL;
return newcode;
}
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newcode=BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newcode;
}
else
{
//找尾节点的指针
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
//尾节点,链接新节点
tail->next = newcode;
}
}
void SListPushFont(SLTNode** pphead, SLTDataType x)
{
SLTNode* newcode = BuySListNode(x);
newcode->next = *pphead;
*pphead = newcode;
}
void SListPopFront(SLTNode** pphead)
{
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
void SListPophBack(SLTNode** pphead)
{
//1、空的时候
if (*pphead == NULL)
{
return;
}
//2、只有一个节点
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//3、一个以上的节点
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//在pos的前面插入x
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
if (pos ==* pphead)
{
SListPushFont(pphead,x);
}
else
{
SLTNode* newcode = BuySListNode(x);
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newcode;
newcode->next = pos;
}
}
//删除pos位置的值
void SListErase(SLTNode** pphead, SLTNode* pos)
{
if (pos == *pphead)
{
SListPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
}
}
好了,今天的分享就到这里了,欢迎大家留言评论。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为实例方法创建错误的引用(js的问题)
- 《 乱弹篇(三)》
- 阻抗继电器行业分析:全球市场规模约为7.3亿美元
- java使用websocket搭建客户端和服务端
- 插混、增程、纯电为什么说纯电是未来的趋势
- Keepalived实现nfs高可用
- C语言之指针
- 一键完成,批量转换HTML为PDF格式的方法,提升办公效率
- TCP/IP详解——POP3协议,SMTP协议
- ChatGPT报错:“Oops,Our systems are a bit busy at the moment…”,原因及处理?