(2024,SPARC,细粒度序列损失,文本标记和语言分组的视觉嵌入)提高图像文本预训练的细粒度理解
Improving fine-grained understanding in image-text pre-training
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
我们介绍稀疏细粒度对比对齐(SPARse Fine-grained Contrastive Alignment,SPARC),这是一种从图像-文本对中预训练更细粒度多模态表示的简单方法。鉴于多个图像补丁通常对应单个词语,我们建议为每个标题中的每个文本标记学习图像补丁的分组。为了实现这一点,我们使用图像补丁和文本标记之间的稀疏相似度度量,计算每个标记的语言分组的视觉嵌入,作为补丁的加权平均值。然后,通过仅依赖于个别样本而不需要其他批次样本作为负样本的细粒度序列损失,对文本标记和语言分组的视觉嵌入进行对比。这使得能够以计算成本低廉的方式学习更详细的信息。SPARC 将这个细粒度损失与全局图像和文本嵌入之间的对比损失相结合,以学习同时编码全局和局部信息的表示。我们对我们提出的方法进行了彻底的评估,并在图像级任务(依赖于粗粒度信息,例如分类)以及依赖于细粒度信息的区域级任务(例如检索、目标检测和分割)上展示了改进的性能。此外,SPARC 提高了模型的忠实度和基础视觉语言模型的标题生成。

1. 简介
在这项工作中,我们提出了稀疏细粒度对比对齐(SPARse Fine-grained Contrastive Alignment,SPARC),这是一种用于多模态预训练的新颖目标,旨在学习同时编码粗粒度/全局和细粒度/局部信息的表示。我们建议通过学习以非监督方式聚合与标题中的单个单词相对应的图像补丁,构建语言分组的视觉嵌入;这是因为通常一个单词在标题中对应多个图像补丁:
- 作为第一步,SPARC 计算个别图像-文本对的补丁和标记嵌入之间的相似性,并在结果相似性矩阵中施加稀疏性。这种稀疏化仅允许将最相关的图像补丁归因于个别标记。
- 接下来,如图 1 所示,对于每个文本标记,我们计算相应的语言分组视觉嵌入,作为补丁嵌入的对齐加权和,其中对齐权重是从稀疏相似性矩阵中计算得到的。通过优化个别标记与其相应语言分组视觉嵌入之间的相似性以及与所有其他语言分组视觉嵌入的不相似性,语言分组视觉嵌入与同一图像-文本对中的标记嵌入进行对比。
SPARC 将产生的细粒度/局部对比损失与图像和文本嵌入之间的全局对比损失相结合,使其能够在学到的表示中同时编码全局和局部信息。??
通过其设计选择,SPARC 解决了几种现有方法在学习带有更细粒度信息的图像表示方面的一些缺点:
首先,有几种方法(Huang等,2021;Mukhoti等,2023;Yao等,2021)学习具有细粒度损失的表示,该损失计算 batch 中所有图像补丁嵌入和所有文本标记嵌入之间的相似性。这种方法在计算和内存上都非常密集,不适用于大 batch(这对于获得对比方法的良好性能是必要的(Jia等,2021;Radford等,2021;Zhai等,2023b))。
另一方面,SPARC 在个别图像-文本对的级别上对比补丁和标记嵌入,并且不使用 batch 中的其他示例来计算相似性矩阵,从而导致更有利的计算和内存占用,并更容易扩展到大 batch。
其次,为了学习图像补丁和文本标记之间的软对应关系,先前的工作(Huang等,2021;Mukhoti等,2023;Wang等,2022)通常依赖于构建跨模态加权表示,其中权重计算为通过补丁和标记嵌入相似性进行的 softmax。 softmax 的胜者通吃动态强烈偏向于个别文本标记和图像补丁之间的一对一映射,这通常不符合底层数据。例如,在一张狗的图像中,“dog” 的标记嵌入应与所有对应于图像中的狗的补丁嵌入匹配,而不仅仅是一个/少数个。此外,从梯度流的角度来看,softmax 可能存在问题(Hoffmann等,2023;Shen等,2023;Zhai等,2023a),因为它倾向于导致低熵分布,其中,softmax 饱和,因此其雅可比矩阵消失(Hoffmann等,2023)。有关更详细的解释,请参见附录A。
另一方面,SPARC 在计算对齐权重时不使用 softmax,这使其能够学习个别标记与相应图像补丁之间的灵活一对多匹配,并避免 softmax 的胜者通吃动态。
第三,有几种方法是从对比预训练的视觉语言模型(Mukhoti等,2023)或从预训练的语言模型(Huang等,2021;Wang等,2022)开始的。此外,现有的细粒度目标是在不同社区中开发的(即医学(Huang等,2021;Wang等,2022)与通用视觉(Mukhoti等,2023;Yao等,2021)),利用不同类型和大小的数据集、架构和预训练设置。这使得难以比较不同方法并评估使用个别细粒度目标的好处。
2. 稀疏细粒度对比对齐
设
![]()
为图像-文本对的小批量数据。令 𝑓_𝑣(·) 为图像编码器,𝑓_𝑡(·) 为文本编码器,𝑔_𝑣(·) 和 𝑔_𝑡(·) 为线性适配器。对于图像 𝒙^𝑣_i,我们将相应的图像补丁表示为
![]()
将图像补丁嵌入表示为 (𝒗_i1, 𝒗_i2, ... , 𝒗_iP),其中
![]()
P 表示图像补丁嵌入的数量。我们计算全局图像嵌入为
![]()
其中 ?_𝑣 是一个单一的非线性层,有助于编码不同粒度的信息。对应的文本 𝒙^𝑡_i,我们将标记表示为
![]()
其中 𝐿_i?是样本 𝑖 的标记数量。标记嵌入 (𝒕_i1, 𝒕_i2, ... , 𝒕_iL_i) 计算为
![]()
全局文本嵌入 -t_i 通过平均池化
![]()
并应用适配器 𝑔_𝑡 计算,即
![]()
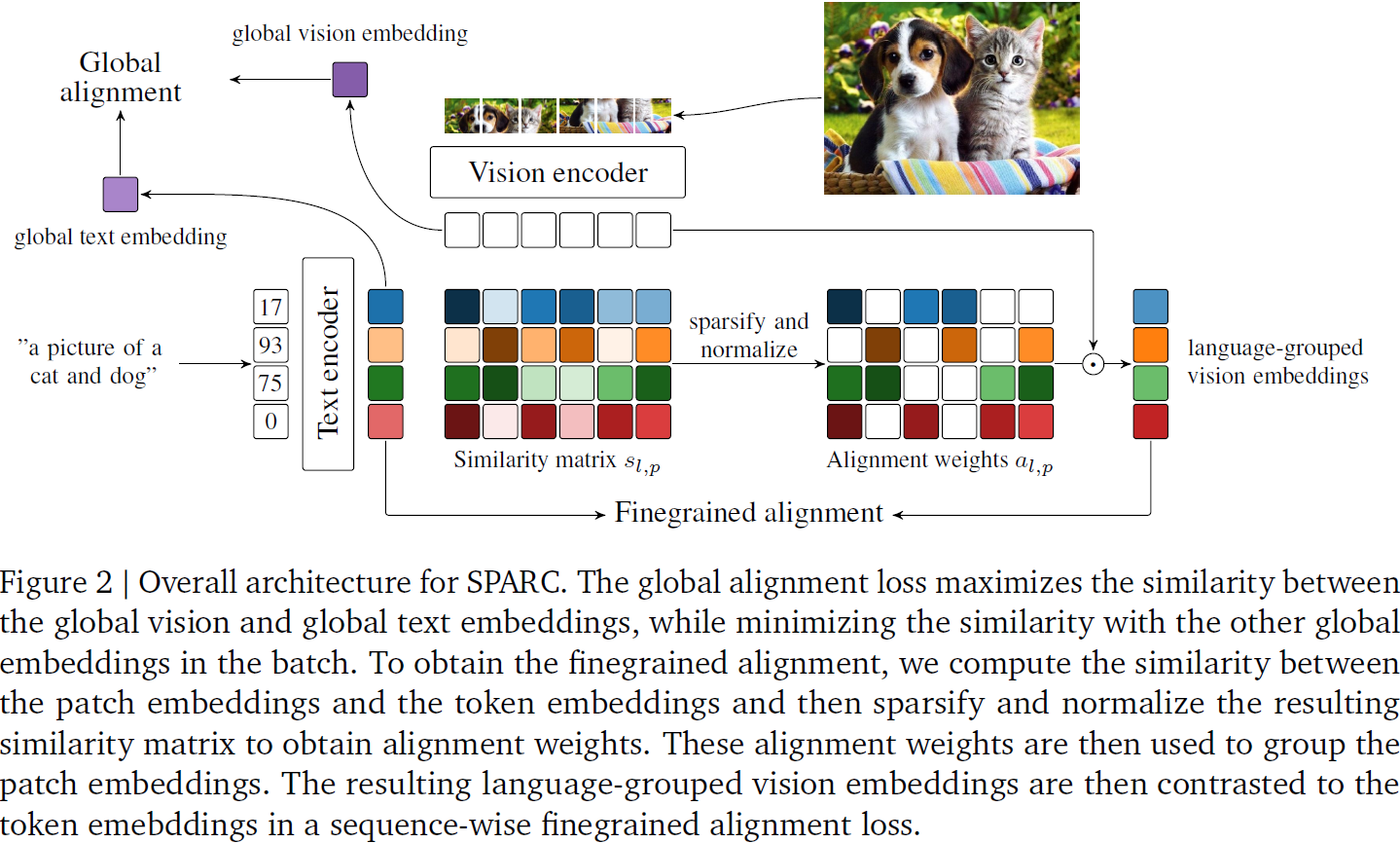
全局对齐:为了学习全局信息,SPARC 使用全局对比损失(Jia等,2021;Radford等,2021),该损失在全局图像(-𝒗)和全局文本嵌入(-𝒕)的级别操作。具体而言,我们通过最大化与相应文本和图像嵌入的相似性,同时最小化与批次中其他文本和图像嵌入的相似性,来学习图像和文本嵌入,即进行优化。

![]()
细粒度对齐:受到通常一个标题中多个图像补丁对应一个单词的观察的启发,我们提出学习对应于单个文本标记的补丁分组。具体而言,对于每个文本标记嵌入,我们学习一个相应的语言分组的视觉嵌入,作为在视觉领域中编码该标记的补丁的对齐加权组合。我们建议根据相应的图像-文本对的标记和补丁嵌入之间的相似性计算对齐权重。为了促进给定文本标记的适当补丁嵌入的分组,我们对相似性矩阵进行稀疏化和最小-最大归一化,以计算对齐权重。为了学习语言分组的视觉嵌入,我们提出了一个细粒度局部损失,该损失优化图像-文本对中个别标记嵌入与其相应语言分组的视觉嵌入之间的对齐。具体而言,我们提出了一个序列对比损失来优化 SPARC 内的这种细粒度对齐。通过优化这个损失(除了上面的全局对比损失之外),可以使学到的表示偏向于保留有关图像的详细信息(如标题所描述),而不仅仅是足以最小化全局对比损失的全局信息。
对于图像-文本对,让 𝑠_(i,𝑙𝑝) 表示文本标记嵌入 𝒕_(i,𝑙) 和图像补丁嵌入 𝒗_(i,p) 之间的相似性,即 𝑠_(i,𝑙𝑝) = 𝒕_(i,𝑙) · 𝒗_(i,p),其中 𝑠_(i,𝑙𝑝) ∈ ?^(𝐿×𝑅),· 是内积。为简化起见,我们以后省略示例索引 𝑖。为了获得对齐权重,对于每个标记?𝑗,我们首先使用最小-最大归一化跨列(即补丁)将 𝑠_𝑙𝑝 归一化到 [0, 1]:

我们对相似性矩阵
![]()
进行稀疏化,以便促进学习并鼓励每个标记与一些补丁对齐,即

其中 𝑃 是图像的补丁嵌入数量,𝜎 是稀疏性阈值。我们计算对齐权重如下:?

其中 𝑎_𝑗𝑘 表示计算与标记 𝑗 对应的语言分组的视觉嵌入时,补丁 𝑘 的权重。注意,这种方法实现了一个灵活的映射,将一个标记与在视觉领域中编码该标记的任意多个补丁嵌入相匹配,例如,“dog” 对应的所有图像补丁都可以与 “dog” 标记编码匹配。对于每个标记 𝑡_𝑙,我们计算相应的语言分组的视觉嵌入 𝒄_𝑙,如下所示:?

作为补丁嵌入的对齐加权组合,其中 𝑅 是具有非零对齐权重的补丁数量。
为了学习细粒度信息,我们建议优化标记嵌入与其相应的语言分组的视觉嵌入之间的对齐。具体而言,我们提出了一个细粒度对比损失,该损失在每个图像-文本对的标记和补丁的序列级别操作,并且不需要来自其他图像-文本对的负样本。与之前的方法(Huang等,2021;Yao等,2021)相比,这极大地减少了计算和内存成本,因为这些方法需要整个批次的样本来计算其细粒度损失。SPARC 优化以下细粒度对齐对比损失:

其试图最大化每个标记嵌入与其相应的语言组的视觉嵌入之间的相似性,并最小化与序列中其他语言组的视觉嵌入的相似性,反之亦然。
总体目标:SPARC 的总体目标是全局对比损失和细粒度对齐对比损失的加权和:
![]()
其中 𝜆_𝑔 和 𝜆_𝑓 是超参数。我们在附录 C 中提供了 SPARC 的伪代码。
稀疏性阈值。我们选择稀疏性阈值 𝜎 等于 1/𝑃,其中 𝑃 是图像补丁的数量。这个选择是基于以下考虑:每个文本标记都应该至少对应一个图像补丁。由于我们使用最小-最大归一化,当所有补丁都同等相似时(补丁的数量保持不变),最小的相似性为 1/𝑃。请注意,这个阈值自然允许一个标记对应的补丁数量在图像内以及图像之间有很大的变化;这使得相同类别的对象(例如 “dogs”)能够在不同实例内和跨不同图像之间得到适当的表示,而不考虑它们的大小、尺度和形状的差异。还请注意,该阈值还允许将单个补丁与不同标记的相似性解耦,因为它允许在相似性矩阵的不同行中有不同数量的零条目;因此,一个补丁与一个标记的相似性与其与另一个标记的相似性无关,这在有更详细的标题(例如“large brown dog”)和/或一个单词由多个标记表示的情况下是有用的。
4. 实验

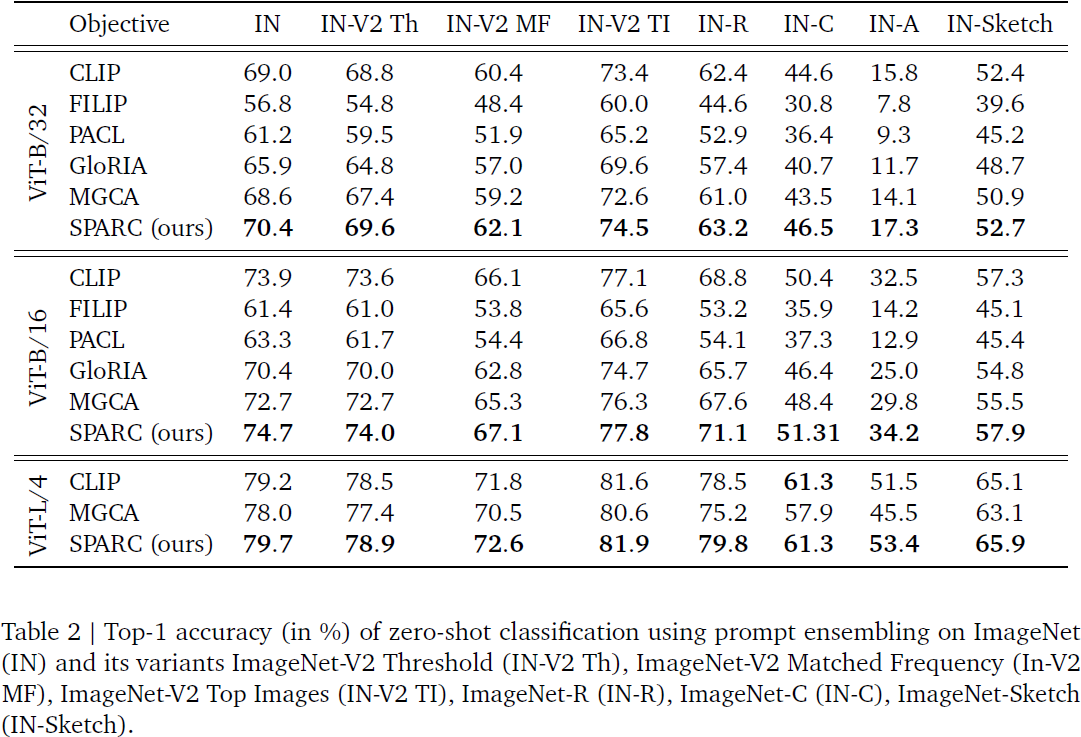


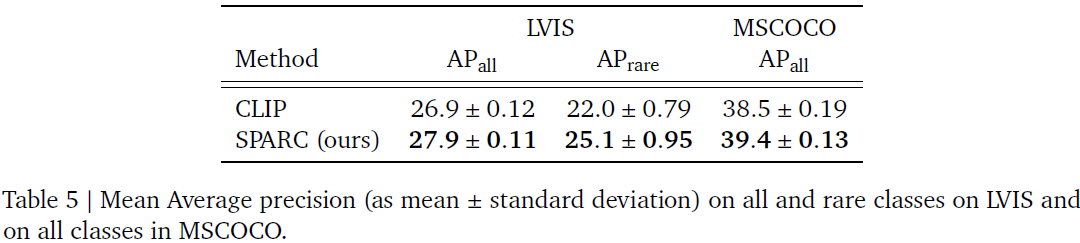




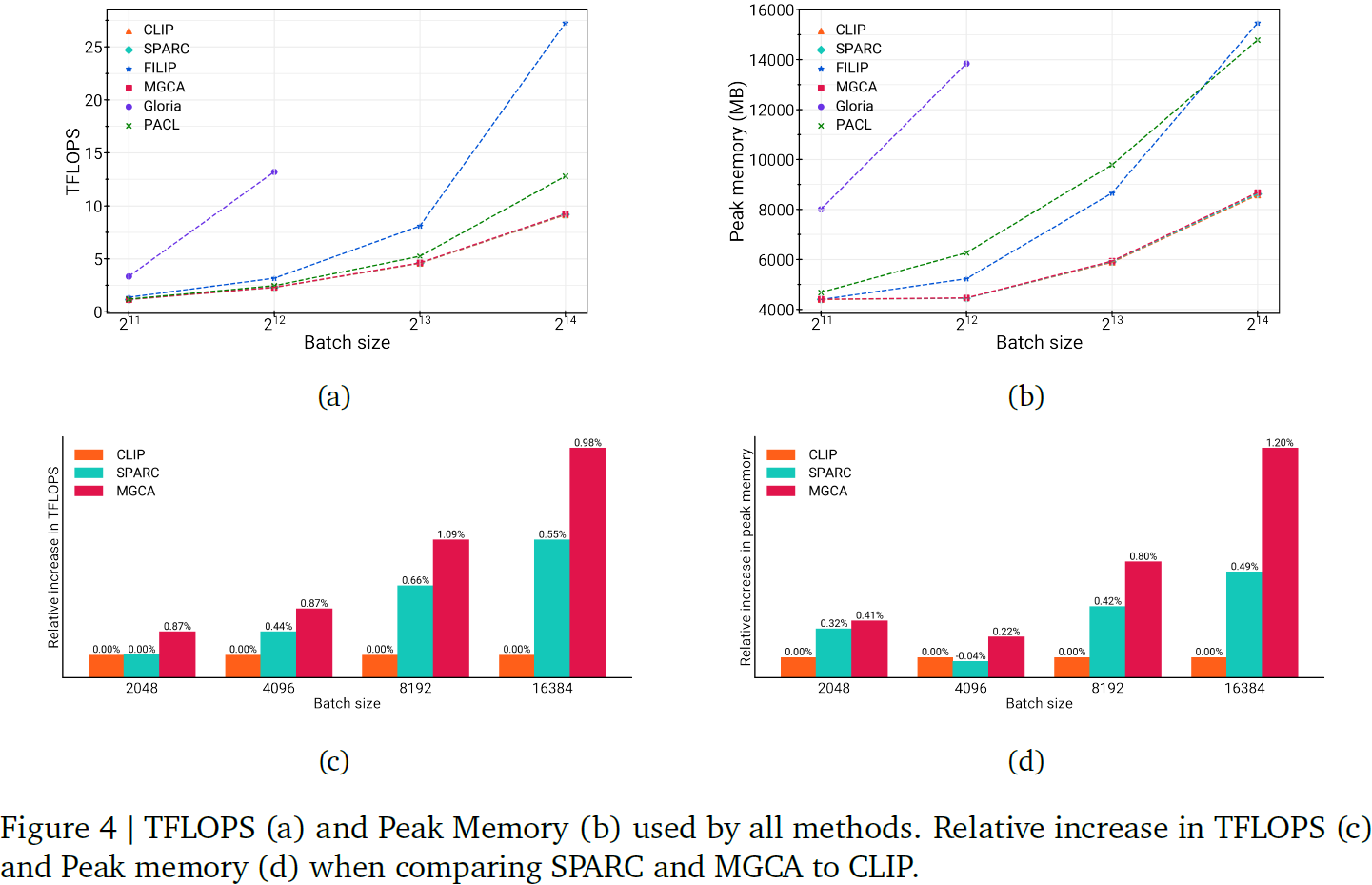
5. 讨论
虽然在 SPARC 中对相似性矩阵的简单稀疏化已经改善了性能,但我们认为探索不同的稀疏化方法和学习补丁分组可能会导致更具信息性的表示。此外,考虑到 SPARC 基于相关标题学习补丁分组,探索具有高度描述性标题的预训练数据是未来工作的另一有趣方向。此外,利用边界框和分割掩码(除了图像-文本对之外)将有助于学习补丁分组并提高学习效率,因为相似性矩阵可以根据这些信号进行预稀疏化。未来工作的另一个有趣方向是进一步探索 SPARC 编码器在多模态基础模型(例如 Flamingo(Alayrac等,2022)、BLIP(Li等,2022a)和 PALI(Chen等,2022))中的性能。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 遗传算法原理详细讲解(算法+Python源码)
- linux进程创建fork函数详解
- docker consul容器的自动发现与注册
- ResourceBundle使用详解
- springboot项目之微信小程序授权登陆
- 【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(1) - checkpoint配置及实现
- Android 实现跑马灯效果
- 理解 JavaScript 中构造函数、原型、实例、原型链之间的关系
- 【电路笔记】-超级电容器
- 2.1 关系模型的数据结构及形式化定义