多模态情感分析——基于CMU-MOSI和CMU-MOSEI数据集(文末获取源码)
在本篇中,将介绍六种典型的多模态情感分析方法,用到的数据集是CMU-MOSI和CMU-MOSEI,六种方法如下:AEF(基于GRU和MLP进行早期融合)、AEFT(基于Transformer和MLP进行早期融合)、ALF(基于GRU和MLP进行后期融合)、ALFT(基于Transformer和MLP进行后期融合)、ALRF(基于模态特定因子的高效低秩多模态融合)、ATF(基于张量融合网络)。文末附下载链接,下面一起来看看吧!
1.融合方式简介
(1)早期融合
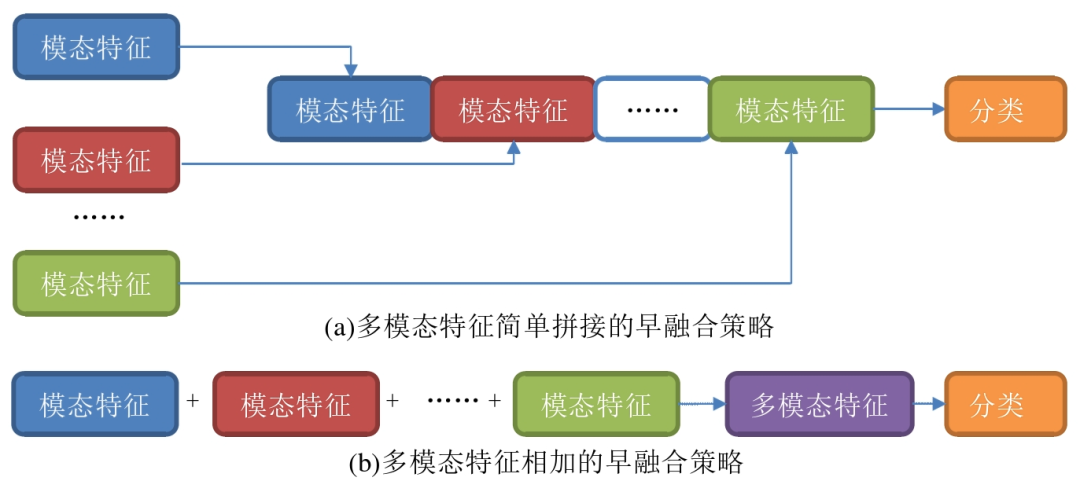
早融合策略(Early Fusion)是在特征层次进行融合的策略。在将特征输入的同时就将不同的模型特征进行融合。将多种模态的特征向量进行简单的拼接、相加或者相乘以及复合等操作,如图(a)是使用简单拼接的方式进行特征融合,而 (b)则是使用相加的方式将模态特征合并成一个多模态特征。最后,将早融合后得到 的特征输入到分类器中进行情感分类。
(2)后期融合
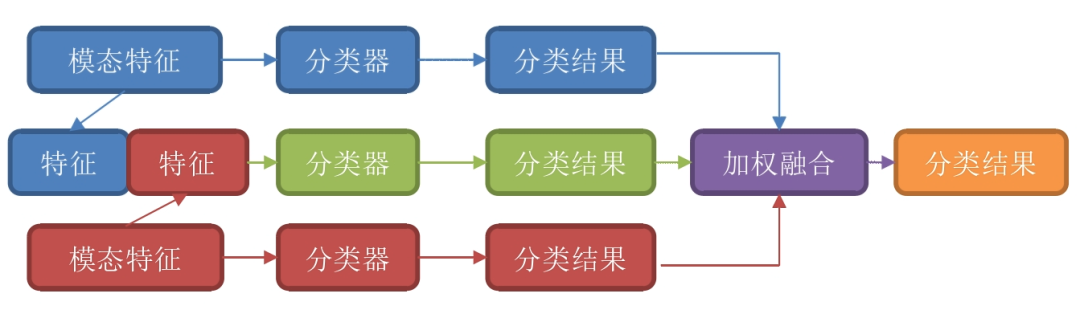
后期融合是在决策层次进行特征融合的策略。顾名思义,就是将每种 模态进行单独训练,充分捕获每种模态的特征里的情感信息,将每个模态的局部情感分类结 果进行特征融合,从而再得出最终的分类结果,如图所示。

(3)混合级融合
综合了早融合策略和晚融合策略, 取两者的优点并且互补了两者的不足。其运作形式一般如图所示。首先,采用早融合策略 将各模态特征进行拼接,然后将拼接的特征输入分类器中,并且每个模态的特征也单独输入 分类器中,最终得到所有组合的分类结果,并将所有分类结果进行晚融合策略。
2.源码方法介绍
(1)AEF:基于GRU网络和多层感知机进行早期融合。
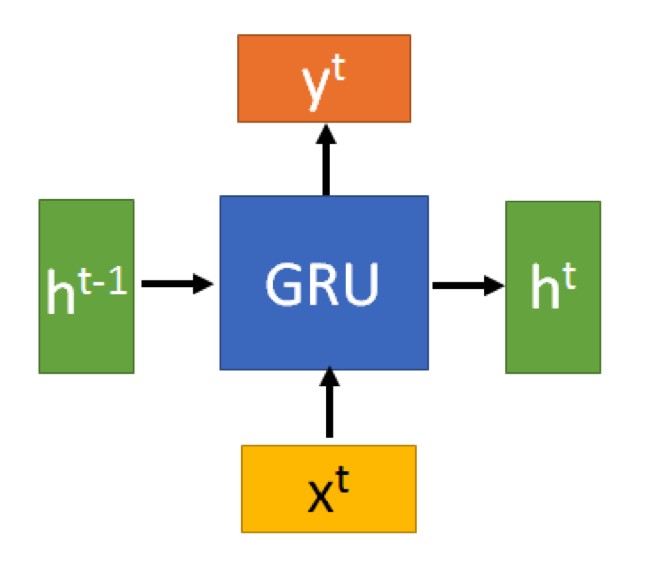
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,与LSTM的作用类似,不过比LSTM简单,容易进行训练。
(2)AEFT:基于GRU网络和多层感知机进行后期融合。
不再多说,和AEF的不同之处在于融合方式。
(3)ALF:基于Transformer网络和多层感知机(MLP)进行早期融合。
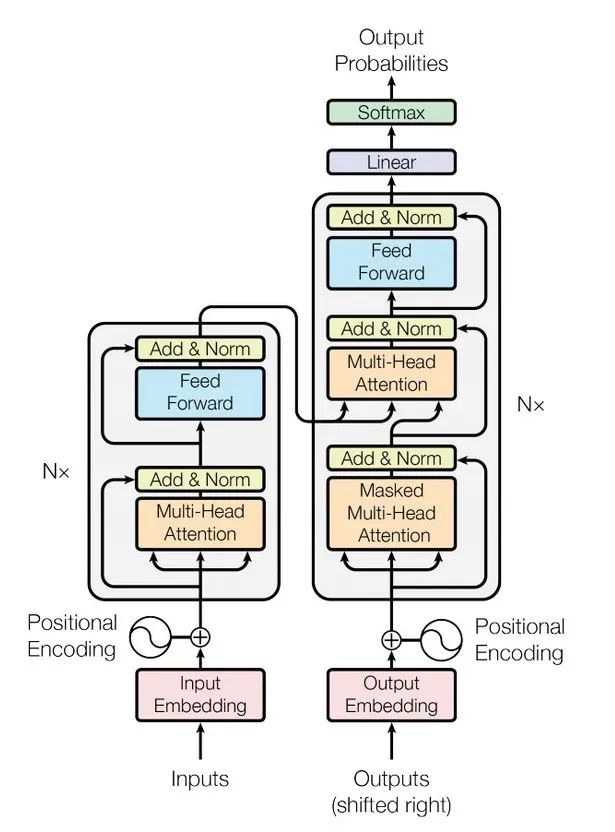
Transformer是一个利用注意力机制来提高模型训练速度的模型。基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。
(4)ALFT:基于Transformer网络和多层感知机(MLP)进行后期融合。
不再多说,和ALF的不同之处在于融合方式。
(5)ATF:基于基于张量融合网络进行融合。
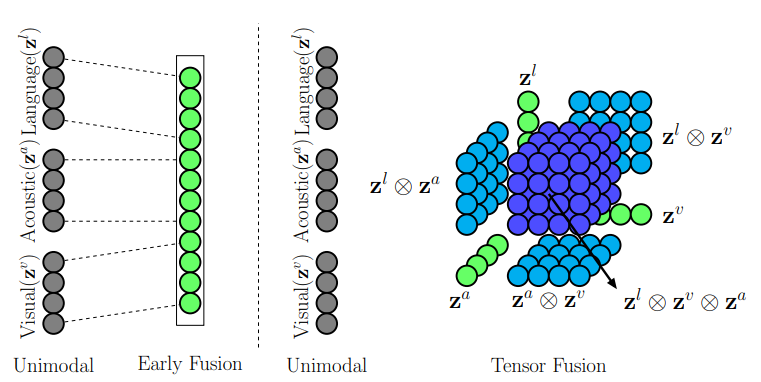
在早期的多模态融合中,主要采用在输入层面简单连接多模态特征的方式,然而这种方法未能有效地捕捉模态内部特征。而后期融合则涉及到独立训练单模态分类器并进行决策投票,然而这种方法并未有效地建模模态间的动态关系。在视频领域,由于口语表达的变化性、手势以及声音等因素,模态内动态很容易变得不稳定。为了解决这一问题,Zadeh等人在文章Tensor Fusion Network for Multimodal Sentiment Analysis提出了一种新的模型,即Tensor Fusion Network(张量融合网络,TFN)。TFN能够通过端到端学习的方式,全面地捕捉模态内和模态间的动态关系。该模型采用一种创新的多模态融合方法,即张量融合,以有效地建模模态间的动态。而模态内的动态则通过三个模态嵌入子网络进行建模。这一方法的创新之处在于它能够同时考虑到模态内部的特征动态和模态间的动态关系,从而提高了多模态情感分析的性能。TFN的引入为解决语音、手势和声音等复杂多模态场景下的动态不稳定性问题提供了一种强有力的解决方案。
(6)ALRF:基于模态特定因子的高效低秩多模态融合
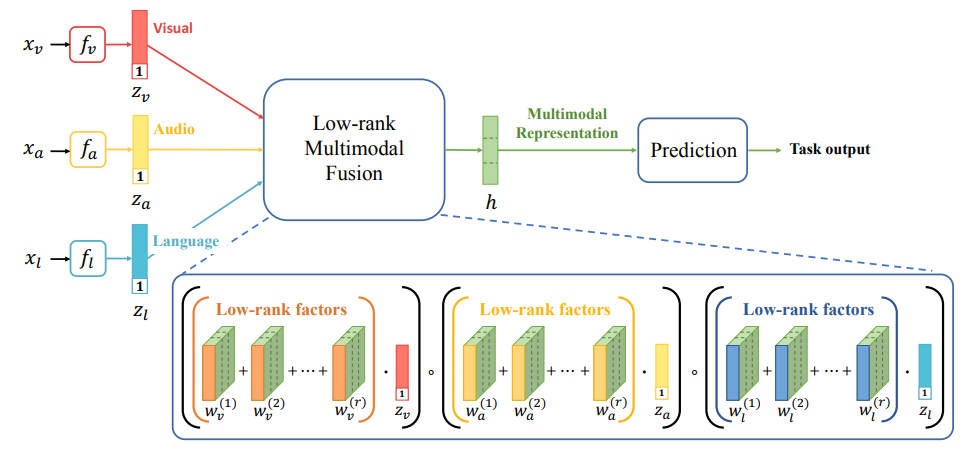
针对ATF输入tensor的变换,可能导致维度呈指数级增长,从而使计算复杂性大大提高。这对于模型的适用性构成了严重限制,尤其是在数据集涉及两个以上的模态时。因此,在“Efficient Low-rank Multimodal Fusion with Modality-Specific Factors,Liu and Shen, et. al”中,提出了一种低秩多模态融合的方法,旨在通过使用低秩权重张量来实现高效的多模态融合。该方法采用了基于模态特定因子的高效低秩多模态融合策略,通过将权重进行分解为低阶因子,从而有效减少了模型参数的数量。这种分解的实现依赖于低阶权重张量和输入张量的并行分解,为基于张量的融合提供了高效的手段。通过这种方法,可以在降低计算复杂性的同时,保持模型对多模态数据集的适应性。这种低秩多模态融合的手段为处理高维度数据提供了一种更为有效和可行的解决方案,为模型设计和应用提供了更灵活的选择。
2.数据集介绍
(1)下载地址
https://multibench.readthedocs.io/en/latest/start/datadownload.html
(2)模态介绍
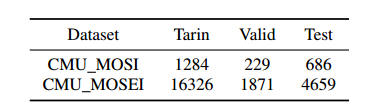
模态有3种(语言,视觉,声音),数据集使用的是已对齐原始raw数据特征。
(3)标签介绍
既有情感标注又有情绪标注。情感标注是对每句话的7分类的情感标注,作者还提供了了2/5/7分类的标注。情绪标注是包含高兴,悲伤,生气,恐惧,厌恶,惊讶六个方面的情绪标注。数据集是多标签特性,即每一个样本对应的情绪可能不止一种,对应情绪的强弱也不同,在[-3~3]之间。
(4)评价标准
平均绝对误差(MAE)、Pearson相关性(Corr)、二元精度(Acc-2)、F-Score(F1)和多级精度(Acc-7)范围从-3到3。对于除MAE以外的所有指标,相对较高的值表示较好的任务性能。本质上,提出了两种不同的方法来测量Acc-2和F1。在第一种,负类的标注范围为[-3,0),而非负类的标注范围为[0,3]。第二种,负类和正类的范围分别为[-3,0)和(0,3]。
2.代码示例
def init_argparse():
import argparse
parser = argparse.ArgumentParser(description="多模态情感分析")
parser.add_argument("--path", type=str, default='data/MOSI/mosi_raw.pkl', help="数据路径")
parser.add_argument("--fusion_method", type=str, default='ALFT', help="融合方法")
parser.add_argument("--epochs", type=int, default=100, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=128, help="训练时的批大小")
parser.add_argument("--num_workers", type=int, default=0, help="子进程数量")
parser.add_argument("--data_type", type=str, default='mosi', help="要加载的数据类型")
parser.add_argument("--max_seq_len", type=int, default=50, help="最大序列长度")
parser.add_argument("--optimizer", type=str, default='AdamW', help="优化器")
parser.add_argument("--lr", type=float, default=0.001, help="学习率")
parser.add_argument("--weight_decay", type=float, default=1e-5, help="权重衰减")
parser.add_argument("--save", type=str, default='best.pt', help="权重保存名字")
parser.add_argument("--seed", type=int, default=1234, help="随机种子")
return parser3.运行结果
以CMU-MOSI为例,在测试集上的结果如下所示,需要注意的是,可自行研究修改参数进行实验,从而得到最佳结果:
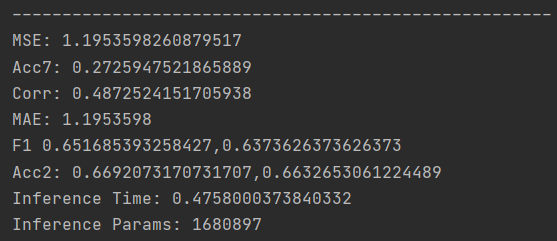
AEF 方法

AEFT方法
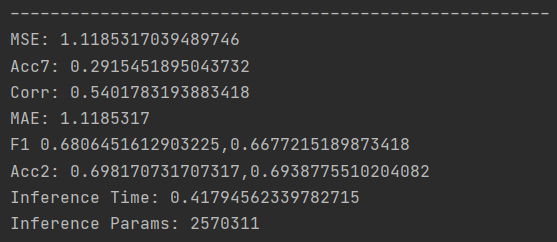
ALF方法
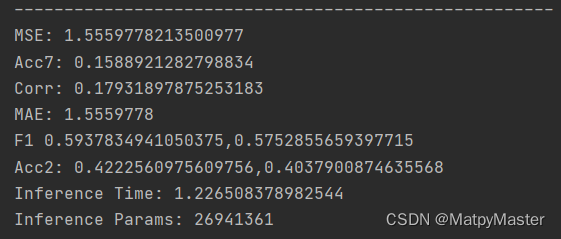
ALFT方法
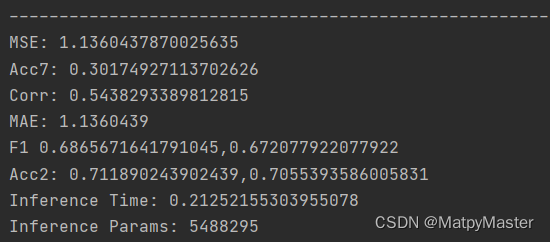
ATF方法
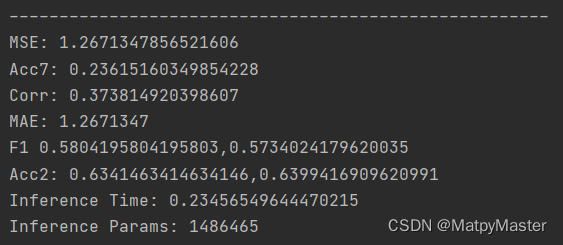
ALRF方法
4.完整代码及数据集获取
🌹🌹🌹🌹🌹🌹整理不易,谢谢支持🌹🌹🌹🌹🌹🌹
https://mp.weixin.qq.com/s/DDQ7xT7ZbQ7flX62CBVlDw
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!