7个Pandas绘图函数助力数据可视化
大家好,在使用Pandas分析数据时,会使用Pandas函数来过滤和转换列,连接多个数据帧中的数据等操作。但是,生成图表将数据在数据帧中可视化,通常比仅仅查看数字更有帮助。
Pandas具有几个绘图函数,可以使用它们快速轻松地实现数据可视化,文中将介绍这些函数。
一、创建Pandas数据帧
首先创建一个用于分析的示例数据帧,将数据帧命名为df_employees,其中包含员工记录。我们将使用Faker和NumPy的随机模块来填充数据帧,生成200条记录。
注意:如果开发环境中没有安装Faker,请使用pip安装:pip install Faker。
运行以下代码片段来创建df_employees,并向其中填充记录:
import?pandas?as?pd
from?faker?import?Faker
import?numpy?as?np
#?实例化Faker对象
fake?=?Faker()
Faker.seed(27)
#?为员工创建一个数据帧
num_employees?=?200
departments?=?['Engineering',?'Finance',?'HR',?'Marketing',?'Sales',?'IT']
years_with_company?=?np.random.randint(1,?10,?size=num_employees)
salary?=?40000?+?2000?*?years_with_company?*?np.random.randn()
employee_data?=?{
?'EmployeeID':?np.arange(1,?num_employees?+?1),
?'FirstName':?[fake.first_name()?for?_?in?range(num_employees)],
?'LastName':?[fake.last_name()?for?_?in?range(num_employees)],
?'Age':?np.random.randint(22,?60,?size=num_employees),
?'Department':?[fake.random_element(departments)?for?_?in?range(num_employees)],
?'Salary':?np.round(salary),
?'YearsWithCompany':?years_with_company
}
df_employees?=?pd.DataFrame(employee_data)
#?显示数据帧的头部
df_employees.head(10)
设置种子以便重现结果,所以每次运行此代码,都会得到相同的记录。
以下是数据帧的前几条记录:
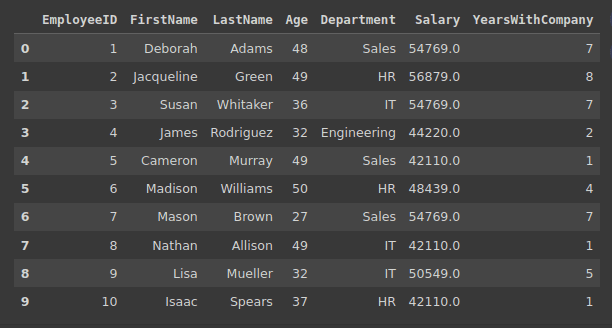
df_employees.head(10)的输出结果
二、Pandas绘图函数
1. 散点图
散点图通常用于了解数据集中任意两个变量之间的关系。对于df_employees数据帧,让我们创建一个散点图来可视化员工年龄和工资之间的关系。这将帮助大家了解员工年龄和工资之间是否存在一定的相关性。
要绘制散点图,可以使用plot.scatter(),如下所示:
#?散点图:年龄与工资
df_employees.plot.scatter(x='Age',?y='Salary',?title='Scatter?Plot:?Age?vs?Salary',?xlabel='Age',?ylabel='Salary',?grid=True)
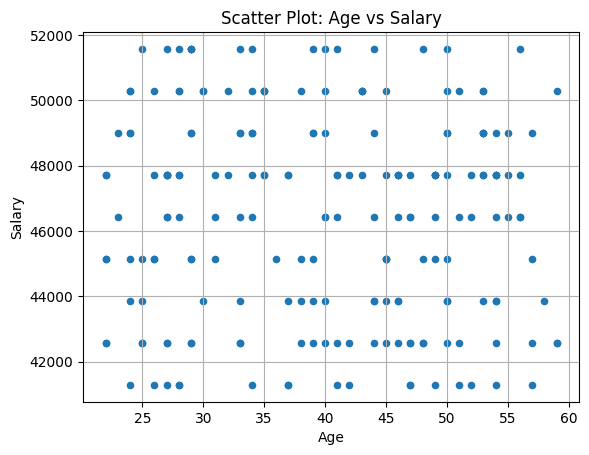
对于此示例数据帧,并未看到员工年龄和工资之间的任何相关性。
2. 折线图
折线图适用于识别连续变量(通常是时间或类似刻度)上的趋势和模式。
在创建df_employees数据帧时,已经定义了员工在公司工作年限与工资之间的线性关系,观察一下显示工作年限与平均工资变化的折线图。
按工作年限分组找到平均工资,然后使用plot.line()绘制折线图:
#?折线图:平均工资随工作年限的变化趋势
average_salary_by_experience?=?df_employees.groupby('YearsWithCompany')['Salary'].mean()
df_employees['AverageSalaryByExperience']?=?df_employees['YearsWithCompany'].map(average_salary_by_experience)
df_employees.plot.line(x='YearsWithCompany',?y='AverageSalaryByExperience',?marker='o',?linestyle='-',?title='Average?Salary?Trend?Over?Years?of?Experience',?xlabel='Years?With?Company',?ylabel='Average?Salary',?legend=False,?grid=True)
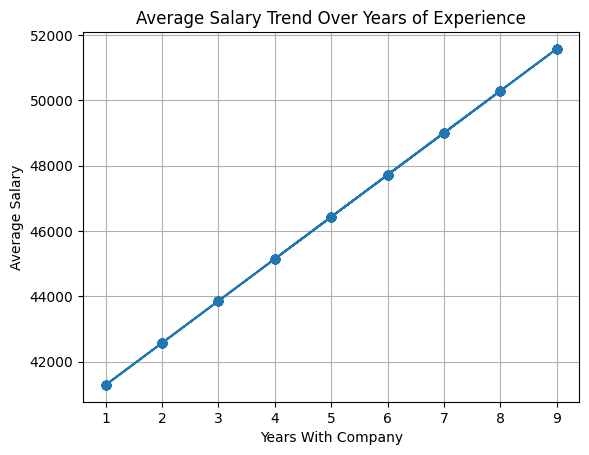
由于选择使用员工在公司工作年限的线性关系来填充薪资字段,因此可以清晰地看到折线图反映了这一点。
3. 直方图
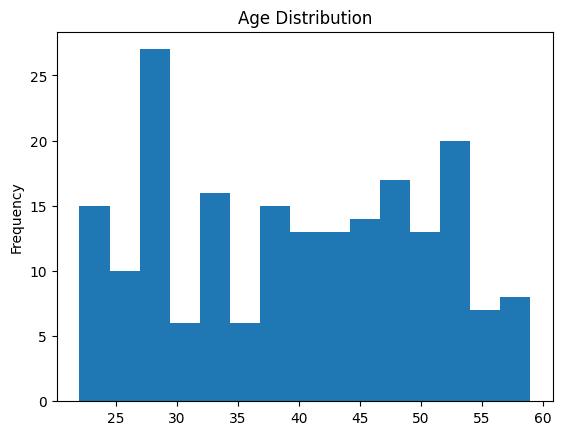
可以使用直方图来可视化连续变量的分布情况,方法是将数值划分成区间或分段,并显示每个分段中的数据点数量。
使用plot.hist()绘制直方图来了解员工年龄的分布情况,如下所示:
#?直方图:年龄分布
df_employees['Age'].plot.hist(title='Age?Distribution',?bins=15)
4. 箱形图
箱形图有助于了解变量的分布、扩散情况,并用于识别异常值。创建一个箱形图,比较不同部门间的工资分布情况,从而对组织部的工资分布情况进行高层次的比较。
箱形图还有助于确定薪资范围以及每个部门的有用信息,如中位数薪资和潜在的异常值等。
在这里,使用根据“部门(Department)”分组的“薪资(Salary)”列来绘制箱形图:
#?箱形图:按部门分列的薪金分布情况
df_employees.boxplot(column='Salary',?by='Department',?grid=True,?vert=False)
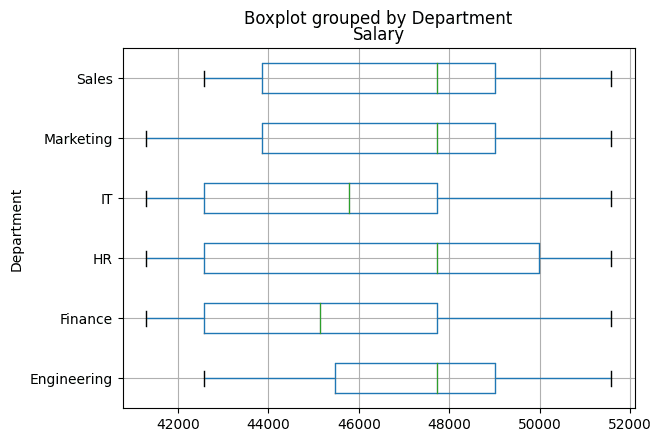
从箱线图中,可以看到某些部门的薪资分布比其他部门更广泛。
5. 条形图
如果想要了解变量在出现频率方面的分布情况,可以使用条形图。
使用plot.bar()绘制一个条形图来可视化员工数量:
#?条形图:按部门的员工数量
df_employees['Department'].value_counts().plot.bar(title='Employee?Count?by?Department')
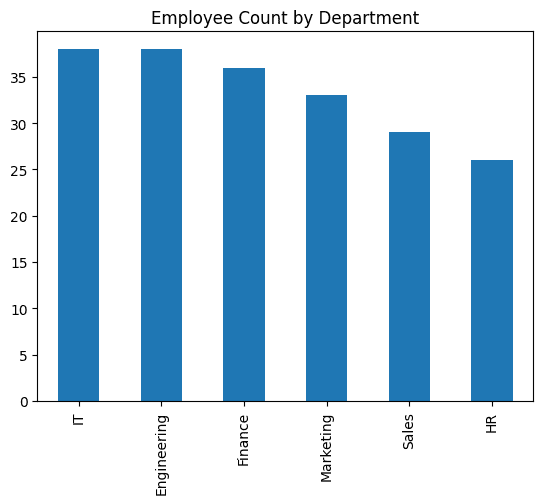
6. 面积图
面积图通常用于可视化在连续轴或分类轴上的累积分布变量。对于员工数据帧,可以绘制不同年龄组的累积薪资分布图。为了将员工映射到基于年龄组的区间中,需要使用pd.cut()。
然后通过“年龄组(AgeGroup)”对薪资进行累积求和,为了得到面积图,使用plot.area():
#?面积图:不同年龄组的累积薪资分布
df_employees['AgeGroup']?=?pd.cut(df_employees['Age'],?bins=[20,?30,?40,?50,?60],?labels=['20-29',?'30-39',?'40-49',?'50-59'])
cumulative_salary_by_age_group?=?df_employees.groupby('AgeGroup')['Salary'].cumsum()
df_employees['CumulativeSalaryByAgeGroup']?=?cumulative_salary_by_age_group
df_employees.plot.area(x='AgeGroup',?y='CumulativeSalaryByAgeGroup',?title='Cumulative?Salary?Distribution?Over?Age?Groups',?xlabel='Age?Group',?ylabel='Cumulative?Salary',?legend=False,?grid=True)
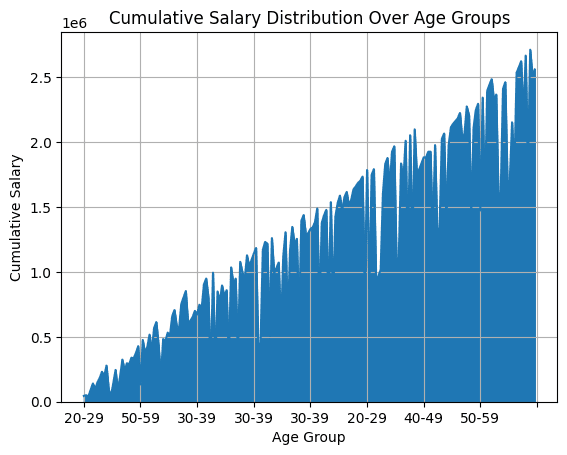
7. 饼图
饼图有助于可视化各个部门在整体组织中的薪资分布比例。
对于我们的示例,创建一个饼图来显示组织中各个部门的薪资分布是很有意义的。
通过部门对员工的薪资进行分组,然后使用plot.pie()来绘制饼图:
#?饼图:按部门划分的薪资分布
df_employees.groupby('Department')['Salary'].sum().plot.pie(title='Department-wise?Salary?Distribution',?autopct='%1.1f%%')
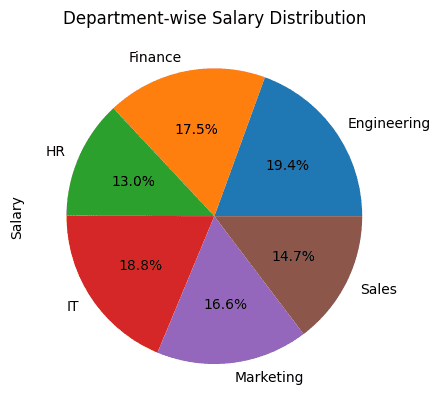
三、总结
以上就是本文介绍的7个用于快速数据可视化的Pandas绘图函数,也可以尝试使用matplotlib和seaborn生成更漂亮的图表。对于快速数据可视化,上述这些函数非常方便,实现过程较为轻松。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于PyQT5的行人识别系统,系统功能包含行人识别、行人追踪、行人轨迹绘制、行人动作识别、人群流量统计、人群密度估计、行人速度检测等
- MATLAB指令
- 学习redis有效期和数据类型
- 消息轮播通知栏实现
- 1月12日&1月15日代码随想录路经总和&从中序和后序遍历构造二叉树
- 王者荣耀与JavaScript策略模式,轻松掌握
- ArcGIS Pro SDK文件选择对话框
- ARMday7
- 基于JSP+Servlet+Mysql的学生宿舍管理系统(简单的增删改查)
- Numpy生成01和范围数组