第五课:MindSpore自动并行
文章目录
第五课:MindSpore自动并行
1、学习总结:
数据并行
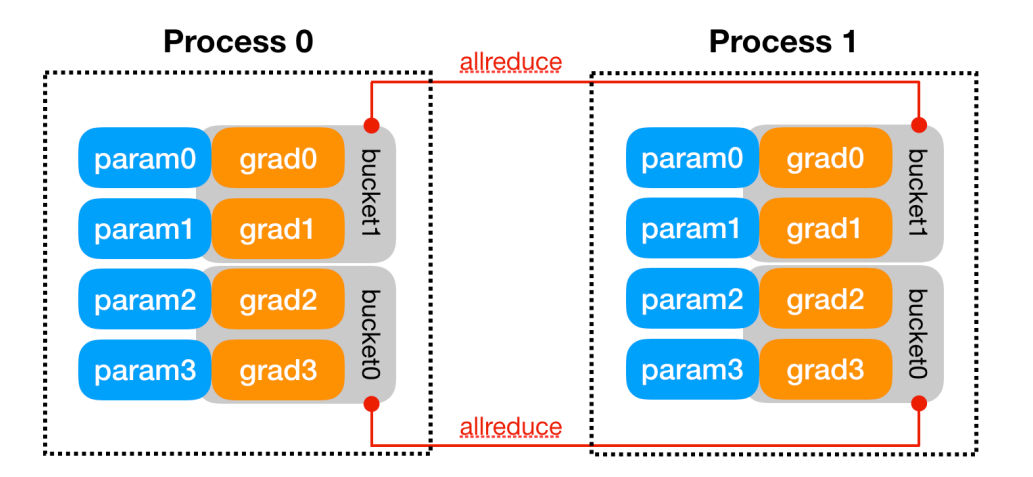
数据并行过程:
- 每一张卡上放置相同的模型参数、梯度、优化器状态
- 不同的卡送入不同的数据训练
- 反向传播获得梯度后,进行AllReduce
数据并行的问题:
- 要求单卡可以放下模型.
- 多卡训练时内存冗余
模型并行
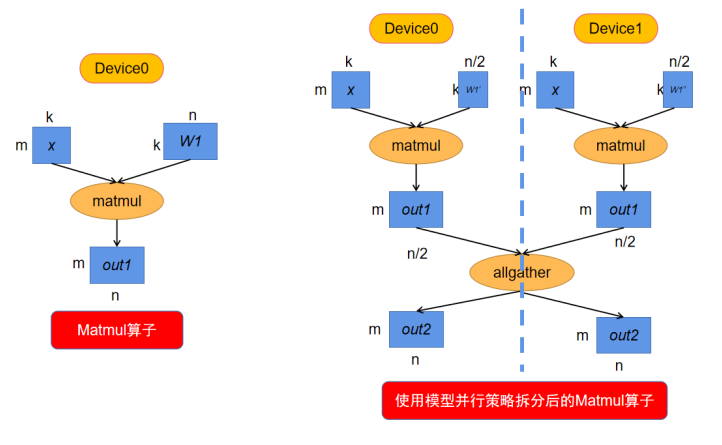
**模型并行是算子层面的并行,它利用某些算子的特性将算子拆分到多个设备上进行计算。**因此并不是网络中所有的算子都可以拆分计算,可以拆分的算子需满足如下特性:
- 可以并行计算的算子
- 算子其中一个输入来自于Parameter
MindSpore算子级并行
- MindSpore对每个算子独立建模,用户可以设置正向网络中每个算子的切分策略(对于未设置的算子,默认按数据并行进行切分)。
- 在构图阶段,框架将遍历正向图,根据算子的切分策略对每个算子及其输入张量进行切分建模,使得该算子的计算逻辑在切分前后保持数学等价。
- 框架内部使用Tensor Layout来表达输入输出张量在集群中的分布状态,Tensor Layout中包含了张量和设备间的映射关系,用户无需感知模型各切片在集群中如何分布,框架将自动调度分配。
- 框架还将遍历相邻算子间张量的Tensor Layout,如果前一个算子输出张量作为下一个算子的输入张量,且前一个算子输出张量的Tensor Layout与下一-个算子输入张量的Tensor Layout不同,则需要在两个算子之间进行张量重排布(Tensor Redistribution)
- 对于训练网络来说,框架处理完正向算子的分布式切分之后,依靠框架的自动微分能力,即能自动完成反向算子的分布式切分。
算子级并行示例

由于第一个算子输出的Tensor Layout是第零维切分到集群,而第二个算子要求第一个输入Tensor在集群上复制。**所以在图编译阶段,会自动识别两个算子输出/输入之间Tensor Layout的不同,从而自动推导出Tensor重排布的算法。**而这个例子所需要的Tensor重排布是一个AllGather算子(注: MindSpore的AllGather算子会自动把多个输入Tensor在第零维进行合并)
流水线并行
- 受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按stage进行切分,每个stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。
- 流水线(Pipeline) 并行是将神经网络中的算子切分成多个阶段(Stage) ,再把阶段映射到不同的设备上,使得不同设备去计算神经网络的不同部分。
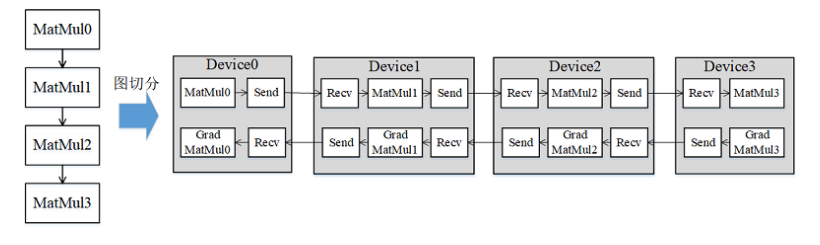
GPipe和Micro batch
**简单地将模型切分到多设备上并不会带来性能的提升,因为模型的线性结构到时同一时刻只有一台设备在工作,而其它设备在等待,造成了资源的浪费。**为了提升效率,流水线并行进一步将小批次(MiniBatch)切分成更细粒度的微批次(MicroBatch),在微批次中采用流水线式的执行序,从而达到提升效率的目的。
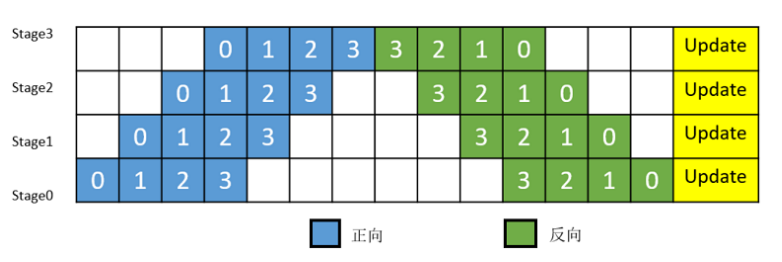
1F1B
**MindSpore的流水线并行实现中对执行序进行了调整,来达到更优的内存管理。**如图3所示,在编号为0的MicroBatch的正向执行完后立即执行其反向,这样做使得编号为0的MicroBatch的中间结果的内存得以更早地(相较于上图)释放,进而确保内存使用的峰值比上图的方式更低。
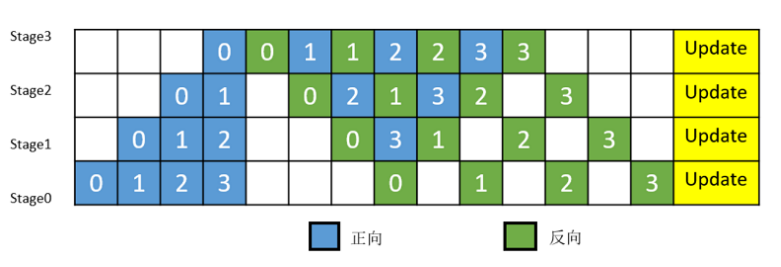
流水线并行示例
- 流水线并行需要用户去定义并行的策略,通过调用pipeline_ stage接口来指定每个layer要在哪个stage上去执行。
- pipeline_ stage接口的粒度为Cell。所有包含训练参数的Cell都需要配置pipeline_ stage,并且pipeline_ stage要按照网络执行的先后顺序,从小到大进行配置。
class ResNet(nn.Cell):
"""ResNet"""
def __init__(self, block, num_classes=100, batch_size=32):
"""init"""
super(ResNet, self).__init__()
self.batch_size = batch_size
self.num_classes = num_classes
self.head = Head()
self.layer1 = MakeLayer0(block, in_channels=64, out_channels=256, stride=1)
self.layer2 = MakeLayer1(block, in_channels=256, out_channels=512, stride=2)
self.layer3 = MakeLayer2(block, in_channels=512, out_channels=1024, stride=2)
self.layer4 = MakeLayer3(block, in_channels=1024, out_channels=2048, stride=2)
self.pool = ops.ReduceMean(keep_dims=True)
self.squeeze = ops.Squeeze(axis=(2, 3))
self.fc = fc_with_initialize(512 * block.expansion, num_classes)
# 下面就是流水线并行的配置
self.head.pipeline_stage = 0
self.layer1.pipeline_stage = 0
self.layer2.pipeline_stage = 0
self.layer3.pipeline_stage = 1
self.layer4.pipeline_stage = 1
self.fc.pipeline_stage = 1
内存优化
重计算
在计算某些反向算子时,需要用到一些正向算子的计算结果,导致这些正向算子的计算结果需要驻留在内存中,直到依赖它们的反向算子计算完,这些正向算子的计算结果占用的内存才会被复用。这一现象推高了训练的内存峰值,在大规模网络模型中尤为显著。如:
- Dropout
- Activations
解决办法是通过时间换空间,为了降低内存峰值, 重计算技术可以不保存正向计算结果,让该内存可以被复用,然后在计算反向部分时,重新计算出正向结果。
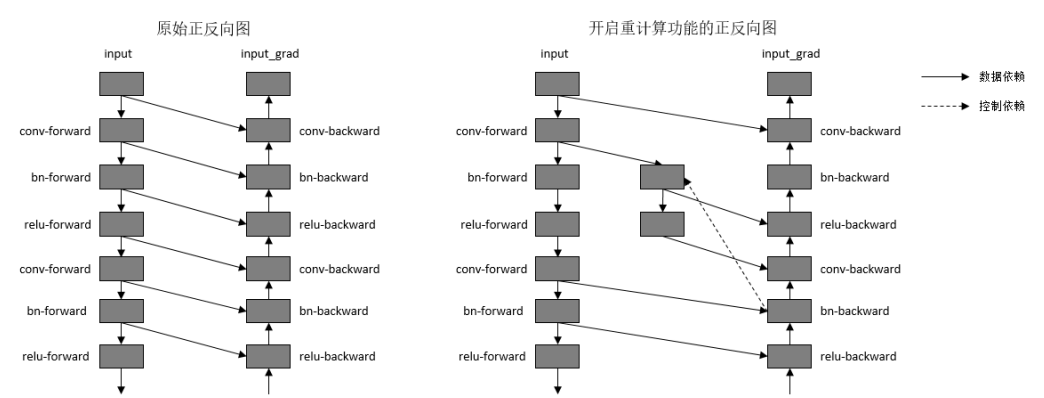
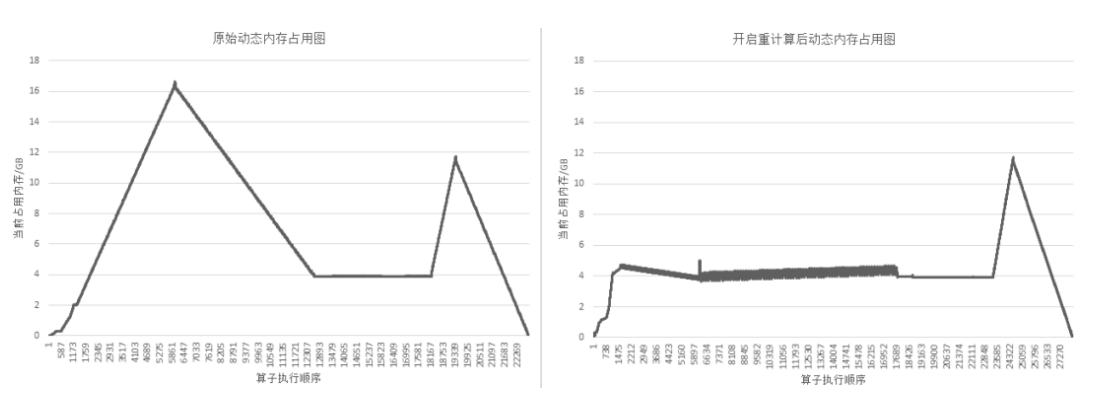
重计算效果
以GPT3模型为例,设置策略为对每层layer对应的Cell设置为重计算,然后每层layer的输出算子设置为非重计算。72层GPT3网络开启重计算的效果如下图所示:
 重计算使用方式
重计算使用方式
为了方便用户使用,MindSpore提供了针对单个算子和Cell设置的重计算接口。当用户调用Cell的重计算接口时,这个Cell里面的所有正向算子都会被设置为重计算。
class ResNet(nn.Cell):
"""ResNet"""
def __init__(self, block, num_classes=100, batch_size=32):
"""init"""
super(ResNet, self).__init__()
self.batch_size = batch_size
self.num_classes = num_classes
self.conv1 = conv7x7(3, 64, stride=2, padding=0)
self.bn1 = bn_with_initialize(64)
self.relu = ops.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same")
self.layer1 = MakeLayer0(block, in_channels=64, out_channels=256, stride=1)
self.layer2 = MakeLayer1(block, in_channels=256, out_channels=512, stride=2)
self.layer3 = MakeLayer2(block, in_channels=512, out_channels=1024, stride=2)
self.layer4 = MakeLayer3(block, in_channels=1024, out_channels=2048, stride=2)
# 这里就是对每层进行重计算的方式
self.layer1.recompute()
self.layer2.recompute()
self.layer3.recompute()
self.layer4.recompute()
self.pool = ops.ReduceMean(keep_dims=True)
self.squeeze = ops.Squeeze(axis=(2, 3))
self.fc = fc_with_initialize(512 * block.expansion, num_classes)
优化器并行
-
在进行数据并行训练时,模型的参数更新部分在各卡间存在冗余计算,优化器并行通过将优化器的计算量分散到数据并行维度的卡上,在大规模网络上(比如Bert、 GPT) 可以有效减少内存消耗并提升网络性能。
-
传统的数据并行模式将模型参数在每台设备上都有保有副本,把训练数据切分,在每次迭代后利用通信算子同步梯度信息,最后通过优化器计算对参数进行更新。数据并行虽然能够有效提升训练吞吐量,但并没有最大限度地利用机器资源。其中优化器会引入冗余内存和计算,消除这些冗余是需关注的优化点。
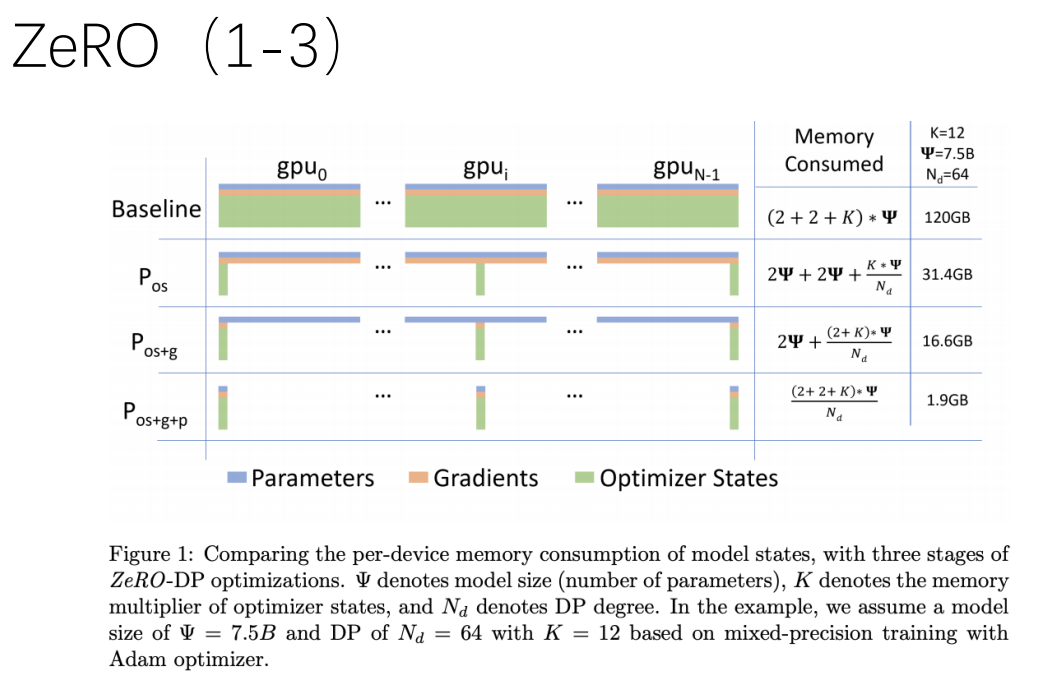
ZeRO (1-3)
- 优化器状态切分pos:切分优化器状态到各个计算卡中,在享有普通数据并行相同通信量的情况下,可降低4倍的内存占用
- 添加梯度切分pos+g:在pos的基础上,进一步将模型梯度切分到各个计算卡中,在享有与普通数据并行相同通信量的情况下,拥有8倍的内存降低能力
- 添加参数切分pos+g+p:在pos+g的基础上,将模型参数也切分到各个计算卡中,内存降低能力与并行数量成线性比例,通信量大约有50%的增长
参数分组(Weights Grouping)
将参数和梯度分组放到不同卡上更新,再通过通信广播操作在设备间共享更新后的权值。该方案的内存和性能收益取决于参数比例最大的group。当参数均匀划分时,理论上的正收益是N- 1/N的优化器运行时间和动态内存,以及N- 1/N的优化器状态参数内存大小,其中N表示设备数。而引入的负收益是共享网络权重时带来的通信时间。
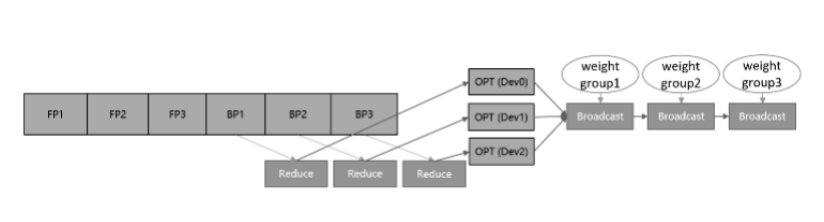
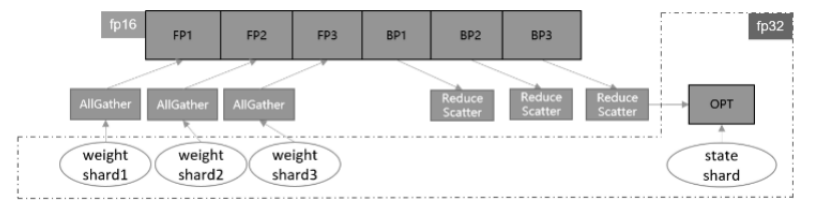
参数切分(Weights Sharding)
**对参数做层内划分,对每一个参数及梯度根据设备号取其对应切片,各自更新后再调用通信聚合操作在设备间共享参数。**这种方案的优点是天然支持负载均衡,即每张卡上参数量和计算量一致,缺点是对参数形状有整除设备数要求。该方案的理论收益与参数分组一致,为了扩大优势,框架做了如下几点改进。
- **对网络中的权重做切分,可以进一步减少静态内存。**但这也需要将迭代末尾的共享权重操作移动到下-轮迭代的正向启动前执行,保证进入正反向运算的依旧是原始张量形状。
- **优化器并行运算带来的主要负收益是共享权重的通信时间,如果我们能够将其减少或隐藏,就可以带来性能上的提升。**通信跨迭代执行的一个好处就是,可以通过对通信算子适当分组融合,将通信操作与正向网络交叠执行,从而尽可能隐藏通信耗时。通信耗时还与通信量有关,对于涉及混合精度的网络,如果能够使用fp16通信,通信量相比fp32将减少- -半

MindSpore分布式并行模式
-
数据并行:用户的网络参数规模在单卡上可以计算的情况下使用。这种模式会在每卡上复制相同的网络参数,训练时输入不同的训练数据,适合大部分用户使用。
-
半自动并行:用户的神经网络在单卡上无法计算,并且对切分的性能存在较大的需求。用户可以设置这种运行模式,手动指定每个算子的切分策略,达到较佳的训练性能。
-
自动并行:用户的神经网络在单卡上无法计算,但是不知道如何配置算子策略。用户启动这种模式,MindSpore会自动针对每个算子进行配置策略,适合想要并行训练但是不知道如何配置策略的用户。
-
混合并行:完全由用户自己设计并行训练的逻辑和实现,用户可以自己在网络中定义AllGather等通信算子。适合熟悉并行训练的用户。
课程ppt及代码地址
2、学习心得:
? 通过本次学习,更加熟悉了华为Mindspore这个国产深度学习框架,同时也对mindspore的各种并行策略有所了解,峰哥通过resnet50这个示例把各种并行策略实现都做了一个详细的讲解,还是比较印象深刻的,课后不懂的还可以再跑跑相关的代码示例,总之各种并行策略在代码上的实现方式还是挺简单的,基本就是一行代码就搞定了。
3、经验分享:
? 在启智openI上的npu跑时记得使用mindspore1.7的镜像,同时安装对应mindnlp的版本,不然可能会因为版本不兼容而报错。另外就是各种并行策略的代码都要跑一跑,结合视频去加深理解。
4、课程反馈:
? 本次课程中的代码串讲我觉得是做的最好的地方,没有照着ppt一直念,而是在jupyter lab上把代码和原理结合到一块进行讲解,让学习者对代码的理解更加深入。我觉得内容的最后可以稍微推荐一下与Mindspore大模型相关的套件,让学习者在相关套件上可以开发出更多好玩和有趣的东西!
5、使用MindSpore昇思的体验和反馈:
MindSpore昇思的优点和喜欢的方面:
- 灵活性和可扩展性: MindSpore提供了灵活的编程模型,支持静态计算图和动态计算图。这种设计使得它适用于多种类型的机器学习和深度学习任务,并且具有一定的可扩展性。
- 跨平台支持: MindSpore支持多种硬件平台,包括CPU、GPU和NPU等,这使得它具有在不同设备上运行的能力,并能充分利用各种硬件加速。
- 自动并行和分布式训练: MindSpore提供了自动并行和分布式训练的功能,使得用户可以更轻松地处理大规模数据和模型,并更高效地进行训练。
- 生态系统和社区支持: MindSpore致力于建立开放的生态系统,并鼓励社区贡献,这对于一个开源框架来说非常重要,能够帮助用户更好地学习和解决问题。
一些建议和改进方面:
- 文档和教程的改进: 文档和教程并不是很详细,希望能够提供更多实用的示例、详细的文档和教程,以帮助用户更快速地上手和解决问题。
- 更多的应用场景示例: 提供更多真实场景的示例代码和应用案例,可以帮助用户更好地了解如何在实际项目中应用MindSpore。
6、未来展望:
? 大模型的内容还是很多的,希望自己能坚持打卡,将后面的内容都学习完,并做出一些有趣好玩的东西来!最近准备尝试做做社区大模型相关的代码迁移+精度验证任务了,希望能够学以致用,提高自己的技术水平!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 探索Java中的Map:领略键值对的无限魅力
- 数据分析:小红书过节“仪式感”营销种草
- leetcode-82删除排序链表中的重复元素
- SpringBoot Redis入门(一)——redis、Lettuce、Redisson使用
- uniapp使用vue3语法利用uni.navigateTo跳转和接收参数
- VM虚拟机及WindowsServer2012安装及激活
- 【Leetcode 2866】美丽塔II —— 单调栈
- Git 的基本概念和使用方式
- 【Redis】更改redis中的value值
- 常见的数据结构