Scrapy使用案例——爬取豆瓣Top 250电影数据
文章目录

什么是Scrapy?
Scrapy是一个基于Python的强大的开源网络爬虫框架,用于从网站上抓取信息。它提供了广泛的功能,使得爬取和分析数据变得相对容易。Scrapy的特点包括:
- 强大的数据提取工具,支持XPath和CSS选择器。
- 简化的HTTP请求和响应处理。
- 可配置的下载中间件,用于处理不同类型的请求。
- 数据存储支持,包括JSON、CSV、XML等。
- 并发请求管理,提高效率。
创建Scrapy项目
要使用Scrapy来爬取网站,首先需要创建一个Scrapy项目。下面是创建一个名为douban_top250的Scrapy项目的步骤:
- 打开终端,导航到您想要创建项目的目录,并运行以下命令:
scrapy startproject douban_top250
- 进入项目目录:
cd douban_top250
- 创建一个用于爬取电影信息的Spider:
scrapy genspider douban_movie douban.com
现在,项目的基本结构已经创建,包括爬虫(Spider)模板文件。
编写Scrapy Spider
Spider是Scrapy项目中负责定义如何抓取信息的部分。需要编辑Spider文件,以指定要爬取的URL、如何处理响应和如何提取数据。
以下是一个示例Spider代码:
import scrapy
from douban_top250.items import DoubanTop250Item
class DoubanMovieSpider(scrapy.Spider):
name = 'douban_movie' # Spider的名称
allowed_domains = ['douban.com'] # 允许爬取的域名
start_urls = ['https://movie.douban.com/top250'] # 起始URL
def parse(self, response):
for movie in response.css('ol.grid_view li'):
item = DoubanTop250Item() # 创建一个DoubanTop250Item对象用于存储数据
item['rank'] = movie.css('em::text').get() # 提取电影排名
item['title'] = movie.css('.title::text').get() # 提取电影标题
item['rating'] = movie.css('.rating_num::text').get() # 提取电影评分
item['link'] = movie.css('a::attr(href)').get() # 提取电影链接
yield item # 返回Item以供后续处理
next_page = response.css('.next a::attr(href)').get() # 提取下一页的链接
if next_page is not None:
yield response.follow(next_page, self.parse) # 继续爬取下一页
在这个Spider中,指定了Spider的名称(name)、允许的域名(allowed_domains)、起始URL(start_urls)以及如何解析响应的方法(parse)。使用CSS选择器来提取排名、标题、评分和链接等信息,并将它们保存到一个自定义的Item类中。
创建Item类
在Scrapy中,Item是用来定义要提取的数据结构的类。在的项目中,创建了一个DoubanTop250Item类,用于定义电影信息的数据结构。以下是Item类的代码:
import scrapy
class DoubanTop250Item(scrapy.Item):
rank = scrapy.Field()
title = scrapy.Field()
rating = scrapy.Field()
link = scrapy.Field()
在这个类中,定义了四个字段:排名(rank)、标题(title)、评分(rating)和链接(link)。这些字段将用于存储从网页上提取的数据。
配置数据存储
Scrapy允许您配置不同的数据存储选项,包括JSON、CSV、XML等格式。我选择将数据保存为JSON文件。
在项目的设置中,配置了FEEDS设置,以指定JSON文件的保存位置和格式:
FEEDS = {
'douban_top250.json': {
'format': 'json',
'encoding': 'utf-8',
},
}
这将数据以JSON格式保存到名为douban_top250.json的文件中。
运行Scrapy爬虫
一旦编写好Spider和Item类,并配置好数据存储选项,就可以运行Scrapy爬虫来抓取豆瓣Top 250电影数据了。运行以下命令:
scrapy crawl douban_movie
Scrapy将开始访问豆瓣电影网站的页面,抓取数据并保存为JSON文件。
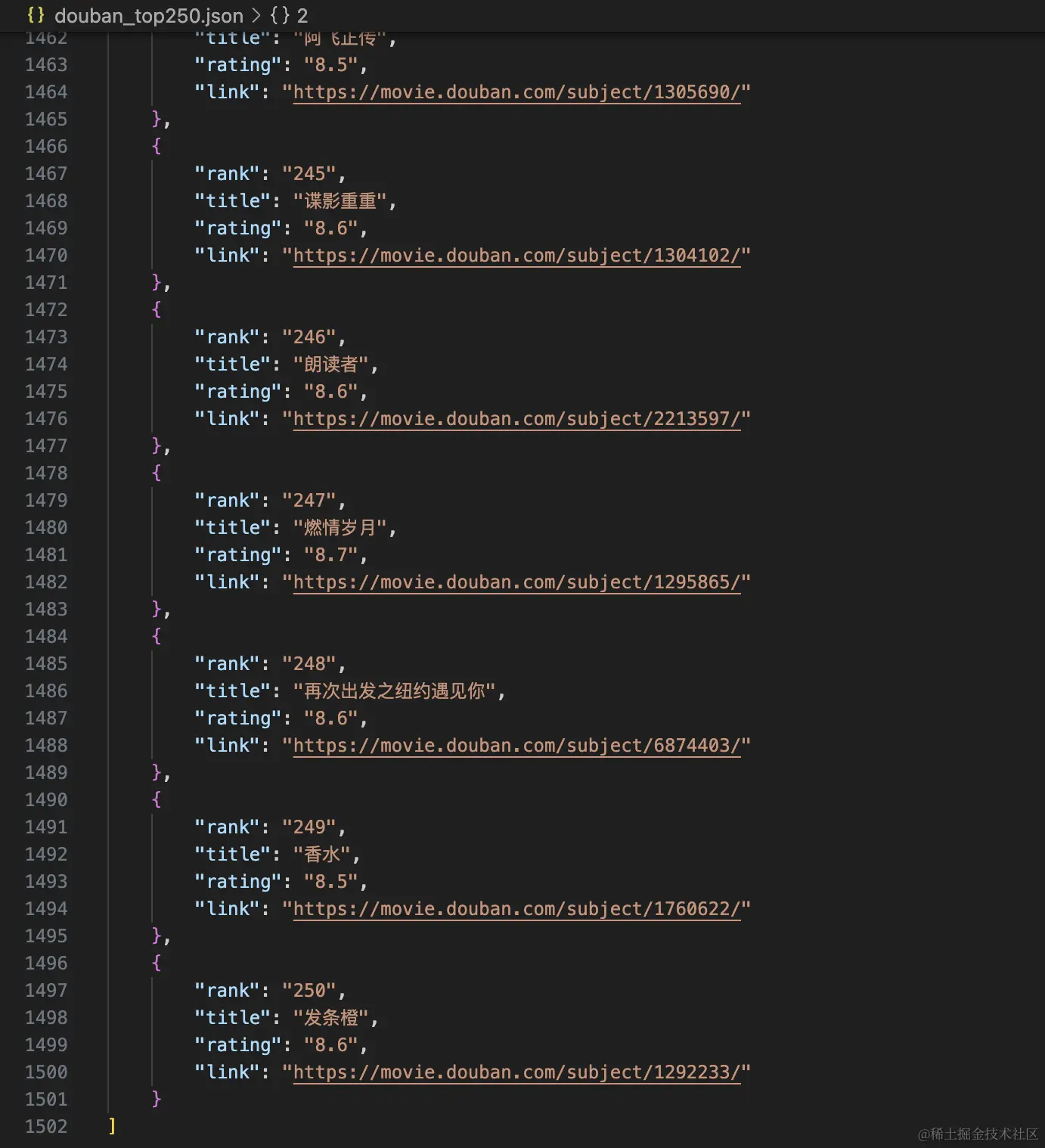
拿到的数据如图:
处理常见问题
在爬取网站数据时,可能会遇到各种常见问题,如请求限制、页面解析问题和网络连接问题。以下是一些处理这些问题的一般指导:
-
请求限制:如果您遇到HTTP状态码403(禁止访问)或其他请求限制问题,可以尝试设置合适的User-Agent、使用IP代理、限制请求速度以及尊重网站的robots.txt规则。
本次遇到的问题:
DEBUG: Crawled (403) <GET https://movie.douban.com/top250> (referer: None)解决方案: User-Agent设置:尝试在Scrapy中设置一个常见的浏览器User-Agent,以使请求看起来更像是由浏览器发出的。这可以通过在Spider中添加
USER_AGENT设置来完成,如下:USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' -
页面解析问题:在编写Spider时,确保您的选择器和规则正确。经常检查网站的HTML结构,以适应可能的更改。
-
网络连接问题:网络连接问题可能会导致请求超时或失败。确保您
的网络连接稳定,使用合理的超时设置,以及适当处理连接异常。
结论
使用Scrapy爬取豆瓣Top 250电影数据是一个很好的示例,展示了如何创建一个功能强大的网络爬虫,用于从网站上抓取数据。在本文中,涵盖了创建Scrapy项目、编写Spider、数据提取、保存为JSON文件以及处理常见问题的方方面面。Scrapy为爬虫开发者提供了强大的工具,使得数据抓取变得更容易。
源码已上传到Github:[github.com/SteamPunkMa…]
Python技术资源分享
小编是一名Python开发工程师,自己整理了一套 【最新的Python系统学习教程】,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。
保存图片微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

如果你是准备学习Python或者正在学习,下面这些你应该能用得上:
1、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

2、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

3、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

4、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

5、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。

6、Python副业兼职与全职路线

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉CSDN大礼包:《Python入门资料&实战源码&安装工具】免费领取(安全链接,放心点击)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 求解建公路问题
- Python学习从0到1 day1 你好 Python
- 深入解析 YAML 配置文件:从语法到最佳实践
- FXCM福汇官网:深入解析BOLL指标的喇叭口形态及含义
- 对世界做好了准备了吗?
- Zookeeper 分布式服务协调治理框架介绍入门
- 谷歌Gemini模型,碾压GPT-4!
- 怎么在PDF添加文本框?6种快速向PDF添加文字教程
- SpringBoot 全局异常统一处理(AOP):@RestControllerAdvice + @ExceptionHandler + @ResponseStatus
- 深入探讨生产环境中秒杀接口并发量剧增、负载过高的情况该如何应对?