pytorch集智-5手写数字识别器-卷积神经网络
1 简介
简称:CNN,convolutional neural network
应用场景:图像识别与分类(CNN),看图说话(CNN+RNN)等
优越性:和多层感知机相比,cnn可以识别独特的模式,可以自动从数据中提取特征。一般机器学习需要特征工程,cnn可以自动识别,极大代替或取代了特征工程
和多层感知机原理不同点:层包含卷积层,池化层。但也是一种前馈神经网络
输入与输出:输入可为图像,输出为目标分类个数(比如图像目标分5类,则输出可定义有5个输出单元)
2 概念
用例子说明:识别图像里的数字是几,数字0-9,用cnn,则输出有10个单元,输入image为28x28像素彩色图片,每个像素为0-255的灰度值
2.1 识别手写数字流程简介

可简单理解为从一个图像提取出多个简单的小图像(因为要模式识别,多个模式,提取特征),然后从这些小图像输出预测
第一层卷积运算后,变成了28x28x4的结果,可以理解为4张28x28的图像
第二层池化运算后,变成了14x14x4的结果,可理解为4张14x14的图像(变小了)(卷积和池化运算原理后面说)
第二层卷积和池化类似,卷积后图像多了,池化后尺寸小了
第五层可理解为将第四层池化运算后的结果拉伸为1维向量(可以看成特征)
第六层为感知机的隐层,经过隐层计算得到输出。本例为分类问题,输出为各分类概率,加和为1
cnn和mlp(多层感知机)工作流程也一样,包括前馈运算和反馈学习阶段(比如梯度下降)。
2.2 卷积运算
卷积是数学概念,定义为一个卷积核函数在输入信号上序列化的积分计算,比较抽象,看个例子
卷积运算原理和人眼识别物体原理差不多。比如一个图片有很多物品,目标找到图片中所有的鞋子,人眼判断会经历这些流程:1扫描图片:需要看完整个图片,才能知道有多少鞋子 2模式识别,人眼能看出鞋子是因为大脑知道鞋子长什么样,脑海会有一个关于鞋子的模板图案 3模式匹配:扫描图片过程,当看到和鞋子模式高度匹配的地方,就记下这个位置的下标。扫描完成后,所有下标所在位置大概率会有鞋子
卷积核可以看作上例中的鞋子模板,鞋子模板和原始图像匹配的结果叫特征图,是一个二维的灰度图,再看个书里的例子
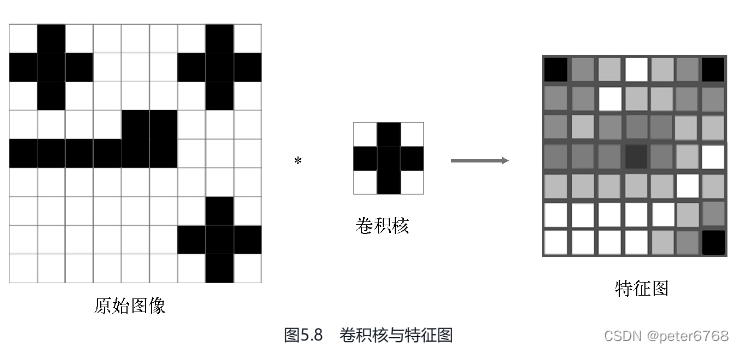
2.2.1 数学上的卷积运算
接上图,用一个卷积核扫描完原始图像一遍,即可看作完成一次卷积运算
卷积运算结果是特征图尺寸会比原始图像尺寸小,如果不像让特征图尺寸变化,可以在原始图像四周加padding(边距)
可以用多个卷积核(多个模式)对原始图像识别,对应会有数量和卷积核数量相等的特征图生成
卷积运算会越来越小,是因为特征图有一定尺寸,经过卷积运算就会减小
卷积运算越来越厚是因为模式(或特征,或卷积核)越来越多,比如需要从图像识别出多个类别的有用信息
2.3 池化运算
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Unity中Shader URP最简Shader框架(ShaderGraph 转 URP Shader)
- Redis缓存常见问题:缓存穿透、缓存击穿与缓存雪崩详解
- ubuntu图形化登录默认只有guest session账号解决方法
- 如何优雅的实现前端国际化?
- LeetCode 2807. 在链表中插入最大公约数
- three.js学习笔记 day1-2
- 【java爬虫】首页显示沪深300指数走势图以及前后端整合部署方法
- Android移动端超分辨率调研(未完成 目前自用)
- 浏览器缓存相关面试题一网打尽,理论结合实践,用代码学习缓存问题,建议关注+收藏,(含项目源代码)
- 算法学习系列(十二):区间合并