MySQL性能调优---BKA
1.BKA原理介绍
????????MySQL 5.6版本开始增加了提高表join性能的Batched Key Access (BKA)算法。BKA是对于多表join语句,当MySQL使用索引访问第二个join表的时候,使用一个join buffer来收集第一个操作对象生成的相关列值。BKA构建好key后,批量传给引擎层做索引查找。key是通过MRR接口提交给引擎的,这样,MRR使得查询更有效率。
????????如果外部表扫描的是主键,那么表中的记录访问都是比较有序的,但是如果联接的列是非主键索引,那么对于表中记录的访问可能就是非常离散的。因此对于非主键索引的联接,Batched Key Access Join算法将能极大提高SQL的执行效率。BKA算法支持内连接,外连接和半连接操作,包括嵌套外连接。
Batched Key Access Join算法工作步骤
????????1) 将外部表中相关的列放入Join Buffer中。
????????2) 批量的将Key(索引键值)发送到Multi-Range Read(MRR)接口。
????????3) Multi-Range Read(MRR)通过收到的Key,根据其对应的ROWID进行排序,然后再进行数据的读取操作。
4) 返回结果集给客户端。
2.如何打开BKA
要使用BKA,调整系统参数optimizer_switch的值

设置打开optimizer_switch中batched_key_access这个值
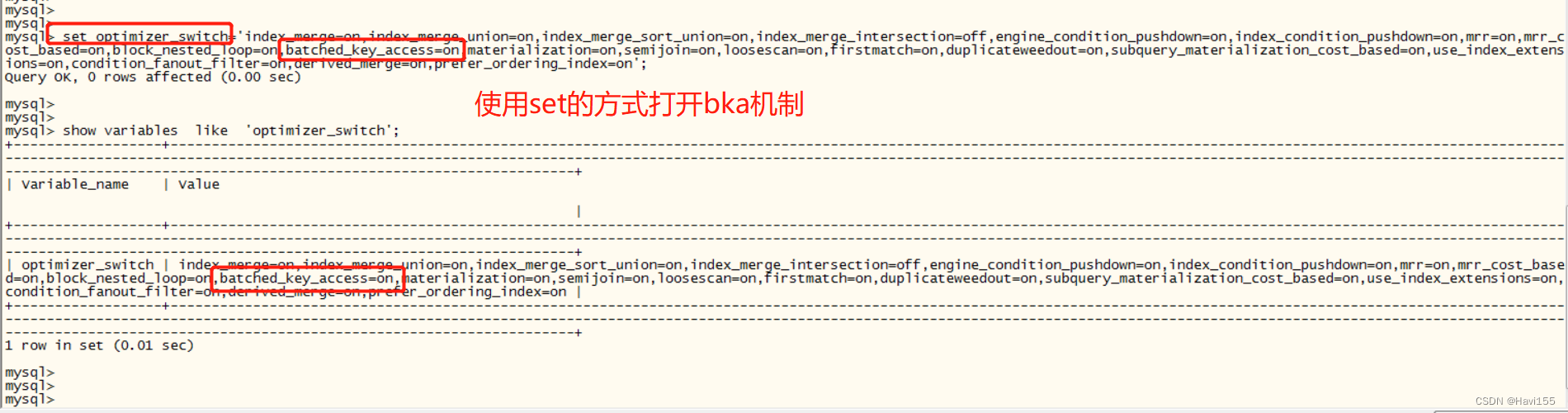
在EXPLAIN输出中,当Extra值包含Using join buffer(Batched Key Access),表示使用BKA。

3.BKA调优案例
案例一:查询没有走BKA
分公司在全量平台提交了一个慢SQL

使用explain查看执行计划,两个表都是走了合适的索引,但是查询效率不是很高

查看这个引擎中BKA没有开启

打开BKA后重新查看执行计划,可以看到查询走了BKA算法
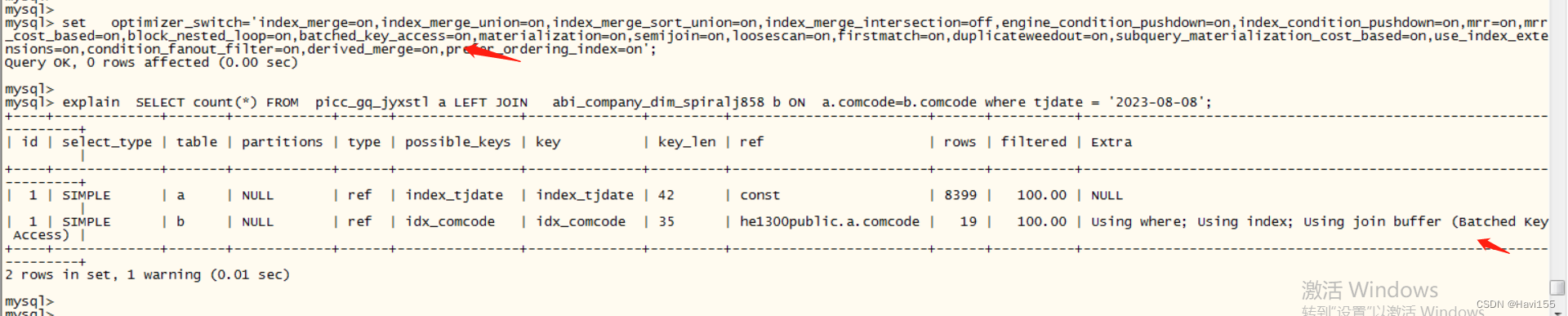
此时执行SQL可以秒回

案例二:查询没有走对BKA
另外一个分公司在全量平台提交的SQL,这里a表是驱动表,rows返回值很大。b表使用了BKA算法。虽然查询走了BKA算法,但是SQL执行效率还是很慢。

其中a表的数据量有3千多万条记录

查看两个表的索引信息,发现a表的queryno字段是主键字段,但是属于唯一索引的第二个字段,查询无法使用到这个索引。根据SQL中最左字段匹配原则,当表中有e、f两个字段组成的联合索引为c,只查询f字段的时候并不能用到c这个索引。
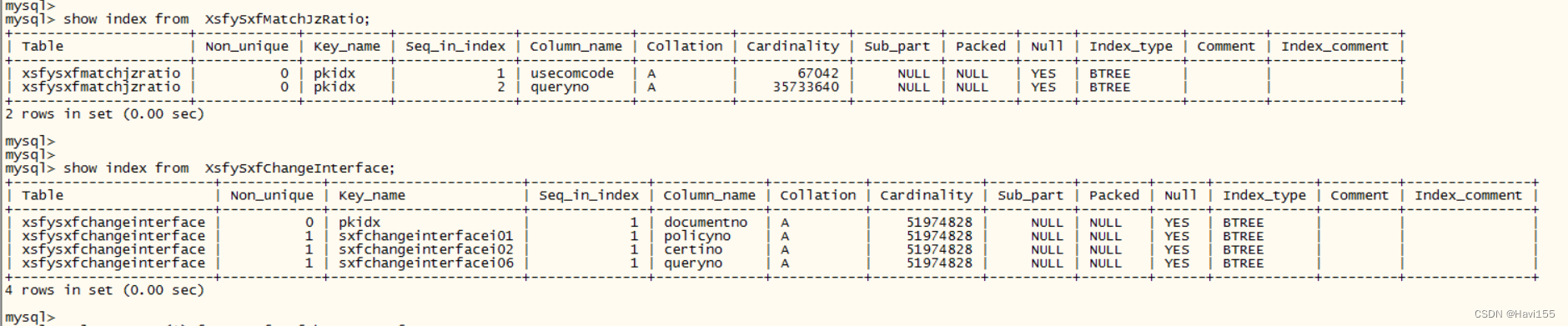
给a表单独创建queryno这个字段的索引

重新查看执行计划,此时b表变成驱动表,a表使用BKA算法。?

使用正确的查询计划之后,查询效率有明显提升。

4.总结
????????BKA 是一种用于 join?操作的算法,它在处理连接操作时使用了块状索引的优势。相对于传统的 Nested Loop Join 算法,BKA 能够减少磁盘 I/O 操作,提高查询性能。对于参与 JOIN 操作的表,确保适当的索引有助于优化 BKA 的性能。在连接字段上创建索引,特别是那些经常用于过滤和连接条件的字段。合理的索引设计可以减少数据库扫描的数据量,加快查询速度,使用BKA算法多表join时被join的表必须确保有索引。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!