使用blip2进行图片输入文本输出
发布时间:2023年12月17日
多模态的重要模型blip2,官方提供模型可以直接用来图片生成文本
github地址:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
个人相当于跑了一下blip2的demo,记录下过程,供今后需要参考:
1、首先是环境安装,跟着官网走:https://github.com/salesforce/LAVIS/tree/7f00a0891b2890843f61c002a8e9532a40343648#installation

其中,salesforce-lavis我装的时候遇到了问题,可能是服务器网络问题,如果安装有问题,可以尝试pypi下载压缩包进行安装:
pypi网址:https://pypi.org/project/salesforce-lavis/
安装命令:
pip install salesforce-lavis-1.0.2.tar.gz
期间如果提示缺什么库,按要求装上就可以了
我装的版本:
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.1 -c pytorch
pip install salesforce-lavis
cd /.../.../LAVIS-main/
pip install -e .
pip install accelerate
期间碰到了transformer的问题,从transformer库导入有问题,我降低了版本,我目前的版本是
transformer==4.35.2
环境装完后,需要下载blip2的模型:
网址:https://huggingface.co/models?other=blip-2
一般是下载上面这个模型,也有其他的可以下载,
具体网址:https://huggingface.co/Salesforce/blip2-opt-2.7b/tree/main
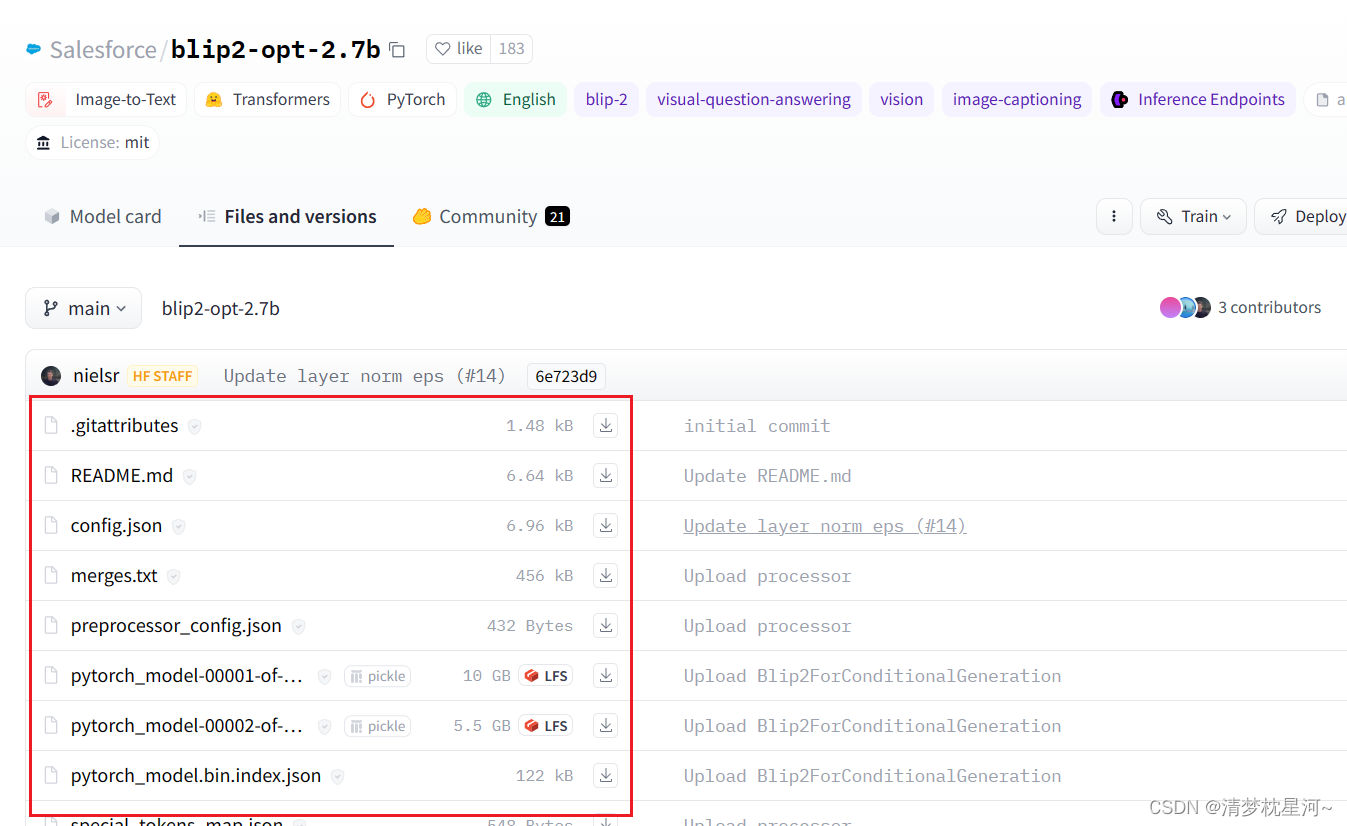
把上面页面中的所有文件下载下来,放到blip2的工作空间中
然后就可以跑官方提供的demo了。
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("my_blip2/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"my_blip2/blip2-opt-2.7b", torch_dtype=torch.float16
)
model.to(device)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
上面的image可以换成自己的图片:
imgfile = '../../xxx.jpg'
image= Image.open(imgfile).convert('RGB')
或者根据个人需求改成批量化生成文本的代码也可以
文章来源:https://blog.csdn.net/qq_44442727/article/details/135016054
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Zblog主题模板:极致·自适应万能主题 下载站主题 自带下载工具箱
- 【极光系列】Windows安装Mysql8.0版本
- OpenCV-Python(23):傅里叶变换
- 【TC3xx芯片】TC3xx芯片电源管理系统PMS详解
- Java面试题46-55
- 队列及其操作(c++题解)
- 【代码随想录03】203.移除链表元素 707.设计链表 206. 反转链表
- 项目总结报告
- 「Verilog学习笔记」可置位计数器
- 如何在Go中使用模板