说说你对数据结构的理解?有哪些?区别?
一、是什么
数据结构是计算机存储、组织数据的方式,是指相互之间存在一种或多种特定关系的数据元素的集合
前面讲到,一个程序 = 算法 + 数据结构,数据结构是实现算法的基础,选择合适的数据结构可以带来更高的运行或者存储效率
数据元素相互之间的关系称为结构,根据数据元素之间关系的不同特性,通常有如下四类基本的结构:
- 集合结构:该结构的数据元素间的关系是“属于同一个集合”
- 线性结构:该结构的数据元素之间存在着一对一的关系
- 树型结构:该结构的数据元素之间存在着一对多的关系
- 图形结构:该结构的数据元素之间存在着多对多的关系,也称网状结构
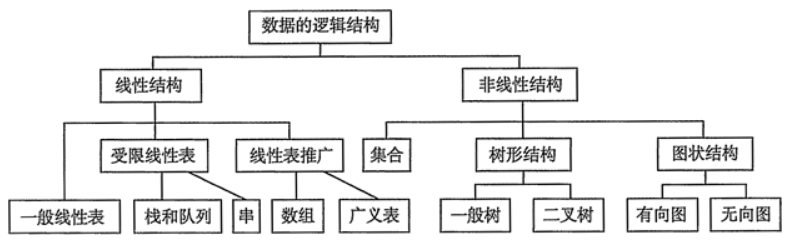
由于数据结构种类太多,逻辑结构可以再分成为:
- 线性结构:有序数据元素的集合,其中数据元素之间的关系是一对一的关系,除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的
- 非线性结构:各个数据元素不再保持在一个线性序列中,每个数据元素可能与零个或者多个其他数据元素发生关联
二、有哪些
常见的数据结构有如下:
- 数组
- 栈
- 队列
- 链表
- 树
- 图
- 堆
- 散列表
数组
在程序设计中,为了处理方便, 一般情况把具有相同类型的若干变量按有序的形式组织起来,这些按序排列的同类数据元素的集合称为数组
栈
一种特殊的线性表,只能在某一端插入和删除的特殊线性表,按照先进后出的特性存储数据
先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据
队列
跟栈基本一致,也是一种特殊的线性表,其特性是先进先出,只允许在表的前端进行删除操作,而在表的后端进行插入操作
链表
是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成
一般情况,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域
树
树是典型的非线性结构,在树的结构中,有且仅有一个根结点,该结点没有前驱结点。在树结构中的其他结点都有且仅有一个前驱结点,而且可以有两个以上的后继结点
图
一种非线性结构。在图结结构中,数据结点一般称为顶点,而边是顶点的有序偶对。如果两个顶点之间存在一条边,那么就表示这两个顶点具有相邻关系
堆
堆是一种特殊的树形数据结构,每个结点都有一个值,特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆
散列表
若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,不需比较便可直接取得所查记录
三、区别
上述的数据结构,之前的区别可以分成线性结构和非线性结构:
- 线性结构有:数组、栈、队列、链表等
- 非线性结构有:树、图、堆等
参考文献
- https://zh.wikipedia.org/wiki/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84
- https://baike.baidu.com/item/数据结构/1450
更多前端资源==> GitHub
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 这篇Java基础快速入门学习教程,让我至少少走3个月弯路
- LVS负载均衡器(DR模式)+nginx七层代理+tomcat多实例+php+mysql 实现负载均衡以及动静分离、数据库的调用!!!
- 一种简单实用的电压电平转换器1V~3.6V FXLP34P5X
- 天津大数据分析培训班 常见的大数据培训课程
- 【自动驾驶中的SLAM技术】第2讲:基础数学知识回顾
- 鸿蒙ArkTS语言介绍与TS基础法
- 数据结构链表完整实现(负完整代码)
- 【数模百科】一篇文章讲清楚层次分析法的原理和解法步骤
- Elasticsearch的使用总结
- linux文件目录权限