(2023,控制解缠,特征合并,LLM,DDIM)Make-A-Storyboard:具有解缠和合并控制的故事板通用框架
Make-A-Storyboard: A General Framework for Storyboard?with Disentangled and Merged Control
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
故事可视化旨在生成与故事提示相一致的图像,通过角色和场景之间的视觉一致性反映故事书的连贯性。然而,当前的方法完全集中于角色,忽视了上下文相关场景之间的视觉一致性,导致独立的角色图像而缺乏图像间的一致性。为了解决这个问题,我们提出了一种名为 Storyboard 的故事可视化新呈现形式,灵感来自电影制作,如图 1 所示。具体而言,Storyboard 将故事逐一展开为场景的视觉表示 [24]。在 Storyboard 的每个场景中,角色在同一位置进行活动,需要视觉上一致的场景和角色。对于 Storyboard,我们设计了一个通用框架,称为 Make-A-Storyboard,它对上下文相关角色和场景的一致性进行解耦控制,然后将它们合并以形成和谐的图像。广泛的实验证明了:1)有效性。该方法在故事对齐、角色一致性和场景相关性方面的有效性;2)泛化性。我们的方法可以无缝集成到主流的图像定制方法中,赋予它们故事可视化的能力。


1. 方法
我们提出了一种名为 Storyboard 的故事可视化的新表现形式。Storyboard 涉及以逐场景的形式将给定的故事进行可视化。在每个场景中,合成的图像应保持场景和角色的一致性。为了实现这一点,我们设计了一个通用的框架,如图 2 所示,称为 Make-A-Storyboard。
1.1 上下文提示处理
如图 2 左侧所示,我们使用了一个 LLM 来处理考虑句子之间上下文相关性的故事提示。首先,LLM 根据给定的主题编写故事,然后将故事分为 N 个离散的句子,表示为 T。
然后,我们使 LLM 能够根据上下文关系在不同句子之间识别描述相同场景和角色的状语和主语(adverbials and subjects)。 对于场景,我们假设当故事没有明确改变场景或使用代词(pronouns)指代先前提到的场景时,故事会在相同的场景中继续。根据这些假设,LLM 基于上下文将句子划分为场景集,并添加一个新的标记嵌入 V*_s,用于表示当前集的具体场景概念。 然后在每个场景中,我们识别角色。代词被映射到具体的角色名称,并引入 V*_c 表示其概念。通过对句子进行上述处理步骤,我们可以获得修饰符故事句子 T*。
最后,由于在处理冗长和文学提示时观察到了当前 T2I 模型的质量下降,我们实施了一个重写过程。具体而言,我们使用 LLM 简化每个句子的表达,同时将其分为两个不同的组成部分:T*_s 和 T*_c。T*_s 是一个地点状语,表示先前获得的场景信息。而 T*_c 表示以主谓宾形式呈现的叙述内容。 同时,我们还获得了没有新标记的原始提示 T_s 和 T_c。
1.2 解耦概念控制
为了保持角色之间的视觉一致性和场景的上下文相关性,一种直接的方法涉及使用具有微调多个概念能力的图像定制方法,例如 Custom Diffusion [23]。然而,如图 4 所示,当前的定制方法在同时处理角色和场景时导致了视觉特征的纠缠。因此,我们解耦角色和场景的视觉概念控制,如图 2 所示。
具体而言,给定场景和角色参考图像,我们首先通过图像定制模型分别微调参数。我们得到用于角色的具体 U-net 参数 θ_c 和用于场景的参数 θ_s,以及它们的修饰向量嵌入 V*_c 和 V*_s。在正式的表示中,角色微调可以表示为:

其中 X_c 表示参考角色。场景的微调遵循相同的方案。
鉴于 θ_c 具备了关于角色视觉概念的知识,我们可以把提示 T*_c 引导的角色的最终的潜在特征 x^c_0 的分布表示为:

场景生成的过程是类似的。

1.3 对扩散中特征合并的观察
考虑到已解耦控制的场景和角色,我们应该将它们合并成一个和谐的图像,同时保留它们学到的视觉概念。然而,简单地剪切和粘贴潜在编码 x^c_0 和 x^s_0 导致了明显的不连贯效果。为了解决这个问题,我们对 StableDiffusion 中的合并现象进行了重要观察:在去噪过程中,从像素到噪声融合两个图像的潜在特征导致了从完全视觉一致的图像到完全语义引导的图像的渐变过渡,如图 3 所示。
具体而言,利用 Stable Diffusion,我们通过为角色和场景使用不同的提示 P_c 和 P_s 分别生成前景角色图像和背景场景图像。然后,在 DDIM 去噪过程的某个中间步骤,我们在角色掩模的引导下将角色特征与场景特征合并。然后,我们使用合并提示 P = P_c + P_s 来控制后续的 DDIM 去噪步骤。通过这种方式,生成的图像与在像素空间直接拼贴获得的图像有所不同,产生了明显的整合过程。
一方面,当合并过程靠近像素侧时,合并提示 P 提供的指导有限。因此,合并的图像分别与原始角色和场景表现出良好的视觉一致性。然而,在像素侧附近,高频信息如边缘已经基本确定,去噪过程主要集中在低频信息,如纹理和颜色。这导致在有效地将场景和角色整合成一个和谐图像方面存在挑战——具有一个生硬的边缘。如图 3 中的视觉结果所验证,角色和场景与原始图像相似,但松鼠和企鹅都漂浮在背景中。
另一方面,当合并过程非常靠近噪声侧时,它可以近似为两个高斯噪声分布的叠加,合并的特征仍然遵循高斯分布。这样,合并过程近似于由合并提示 P 引导的新 T2I 合成,导致对原始图像的视觉信息的最小保留。然而,合并过程越靠近噪声侧,合并特征就越不确定。因此,角色和场景的高频信息和语义将更好地被提示整合和控制,有助于与提示进行语义对齐。
因此,为了在与角色和场景图像的视觉一致性和语义对齐之间取得平衡,我们将去噪过程的中间阶段作为合并阶段。
1.4 平衡感知合并
受到前述观察的启发,我们进行平衡感知合并(Balance-Aware Merge),对场景和角色特征进行合并,以在去噪过程中平衡视觉一致性和语义引导。
为了合并前景和背景,我们采用强大的分割模型 Grounded-Segment-Anything [22, 29],表示为 SAM(·),以获得前景的掩模。具体而言,我们首先取先前生成的角色潜在特征 x^c_0,并通过 VAE 解码器 D(·) 进行处理,得到像素空间图像 D(x^c_0),这旨在促进后续的分割。随后,我们利用 T_sam 通过?Grounded-Segment-Anything 来获得掩模,然后调整其大小以适应潜在特征的比例。T_sam 由叙述内容 T_c 中的主语和谓语组成,确保叙述故事中的对象不会丢失。获得掩模的过程可以形式化为:
![]()
最后,在去噪步骤中间,我们执行合并并根据以下方程得到合并后的潜在特征 x_λ。
![]()
其中,参数 λ 代表合并的?DDIM 步骤。
在前景背景合并之后,根据我们在观察中使用的方法,在未经微调的提示 T 和 U-net 的指导下继续进行后续的 DDIM 过程将导致角色和场景的显著视觉语义偏移。因此,在 DDIM 的后续去噪过程中,同时控制角色和场景概念的精细调整至关重要。然而,大量实验证明当前的图像定制方法在同时控制这两个概念时无法保持高质量和解耦。
交替控制。为了防止视觉信息的混淆,我们提出了交替控制方法,完全解耦场景和角色的生成。具体而言,我们通过交替添加训练好的场景嵌入 V*_s 和精细调整的角色嵌入 V*_c 来控制去噪过程。例如,使用以下提示进行交替:“A cat is eating a cake in V*_s garden” 和 “A V*_c cat is eating a cake in garden”。此外,除了交替使用相应的嵌入之外,我们还交替使用相应的精细调整 U-net。x_0 分布的正式表示如下:
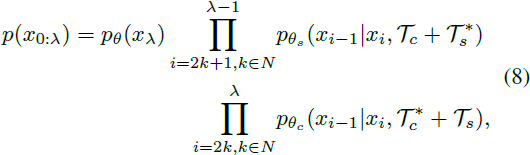
其中,T_c 和 T_s 分别表示地点状语和叙述内容,而 T*_c 和 T*_s 表示相应修饰符嵌入的整合。θ_c 和 θ_s 分别表示角色和场景的网络参数。?
2. 结果

与 SOTA 图像定制方法的定性比较。相较之下,我们的 Make-A-Storyboard 在确保文本对齐、场景一致性和角色一致性方面表现出色。
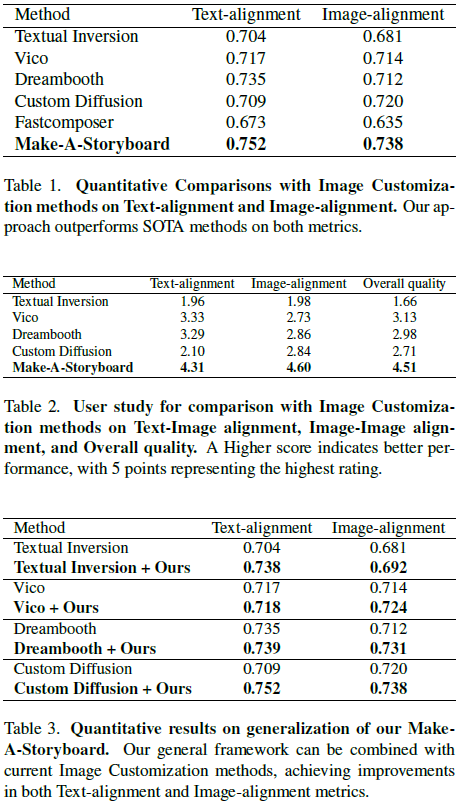
文本和图像对齐的评估指标是 CLIP。定量结果和人工评估显示 Make-A-Storyboard 表现出色。

定性比较 Make-A-Storyboard 的泛化能力。我们的方法可以无缝集成到图像定制方法中,从而显著增强了它们在同时控制场景和角色一致性方面的能力。

不同合并时间步 γ 的影响。在时间步为 120 时,合并的结果在视觉一致性和图像和谐之间进行权衡。?

交替控制的影响。与联合控制相比,交替控制确保了角色和场景的视觉一致性。?
S. 总结
S.1 主要贡献
当前故事画面生成方法完全集中于角色,忽视了上下文相关场景之间的视觉一致性,导致独立的角色图像而缺乏图像间的一致性。为解决这个问题,本文设计了一个通用框架 Make-A-Storyboard,它对上下文相关角色和场景的一致性进行解耦控制,然后将它们合并以形成和谐的图像。此外,使用平衡感知合并和交替控制提升生成性能。
S.2 方法
本文使用的架构如图 2 所示。
上下文提示处理。如图 2 左所示。
- 首先,LLM 根据给定的主题编写故事,然后将故事分为 N 个离散的句子。
- LLM 基于上下文将句子划分为场景集,并添加一个场景标记。 然后在每个场景中,用角色标记指代角色。
- 使用 LLM 简化每个句子的表达,同时将其分为两个不同的组成部分:表示场景的地点状语和以主谓宾形式呈现的叙述内容。
解耦概念控制:
- 对于给定图像定制模型,分别使用分别使用场景标记和角色标记微调 U-net 中与场景和角色有关的参数。
- 最终,分别使用地点状语和叙述内容引导场景和角色的生成。
特征合并。简单地剪切和粘贴场景和角色的潜在编码导致了明显的不连贯效果。本文使用如下方案来解决这个问题,
- 为角色和场景使用不同的提示分别生成前景角色图像和背景场景图像。
- 在 DDIM 去噪过程的某个中间步骤,在角色掩模的引导下将角色特征与场景特征合并。
- 使用场景和角色的合并提示来控制后续的 DDIM 去噪步骤。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!