【Python爬虫】基础知识一遍过 | 第一个爬虫程序
文章目录

🌺入门须知
Python 爬虫是指使用 Python 编程语言编写的程序,用于自动化地从互联网上获取数据。爬虫可以模拟人类在网页上的操作,例如通过发送 HTTP 请求获取网页内容、解析网页结构、提取所需数据等。
Python 爬虫通常用于以下场景:
- 数据采集和分析:爬虫可以帮助收集大量的数据,并进行必要的清洗和处理,以便进一步的数据分析和应用。
- 网络监测和信息抓取:爬虫可以定期检查网站内容的变化,抓取最新的信息,如新闻、价格、股票数据等。
- 网络搜索和索引:爬虫可以帮助搜索引擎发现并索引互联网上的网页内容,使用户能够进行全文搜索。
- 自动化测试:爬虫可以模拟用户在网页上的操作,例如填写表单、点击按钮等,以进行自动化的功能测试。
Python 爬虫通常使用第三方库来实现核心功能,如 urllib、requests 用于发送 HTTP 请求,BeautifulSoup、lxml 用于解析和处理网页内容,Scrapy 用于构建高效的爬虫系统等。
需要注意的是,在使用爬虫时,应遵守相关的法律法规,遵循网站的使用政策,并尊重他人的隐私和知识产权。避免对目标网站造成过大的访问压力,以及爬取敏感信息或违反隐私的内容。
?urllib.request
urllib.request 是 Python 标准库中的模块,用于处理网络请求。它提供了一个简单而强大的接口,用于发送 HTTP 请求、处理响应、下载文件等操作。通过 urllib.request 模块,你可以实现从指定 URL 获取网页内容、发送 POST 或 GET 请求、设置请求头部信息等。
🎈Get请求
import urllib.request
# Get请求
response=urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode('utf-8')) # 对获取到的网页源码进行utf-8进行解码
运行后发现
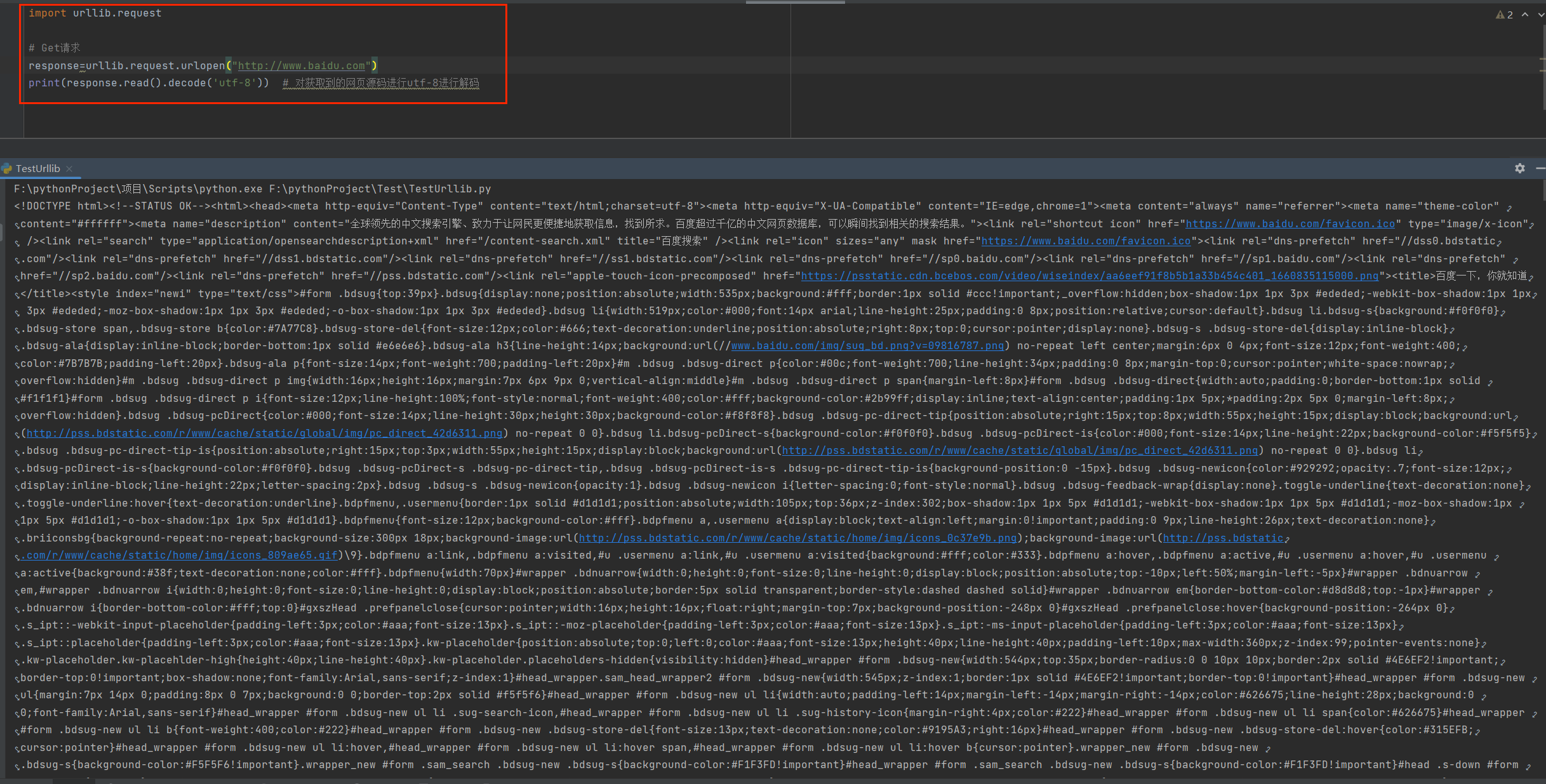
我们把控制台的数据进行复制,粘贴到文本文件里面,并且把文本文件的后缀改为.html

打开这个demo
发现出现了百度官网
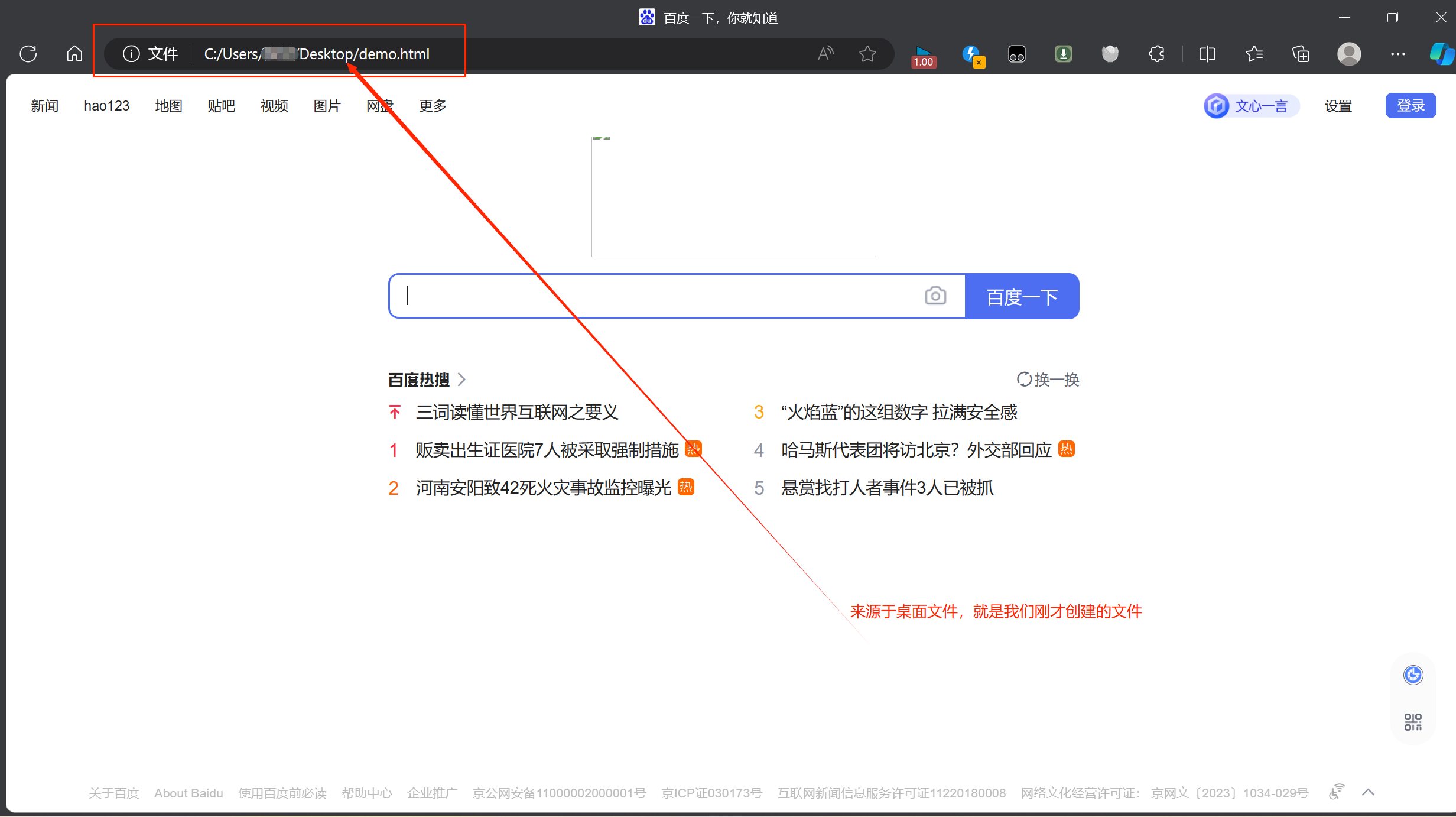
🎈Post请求
我们采用http://httpbin.org/这个网站来测试Post请求
下面是操作步骤
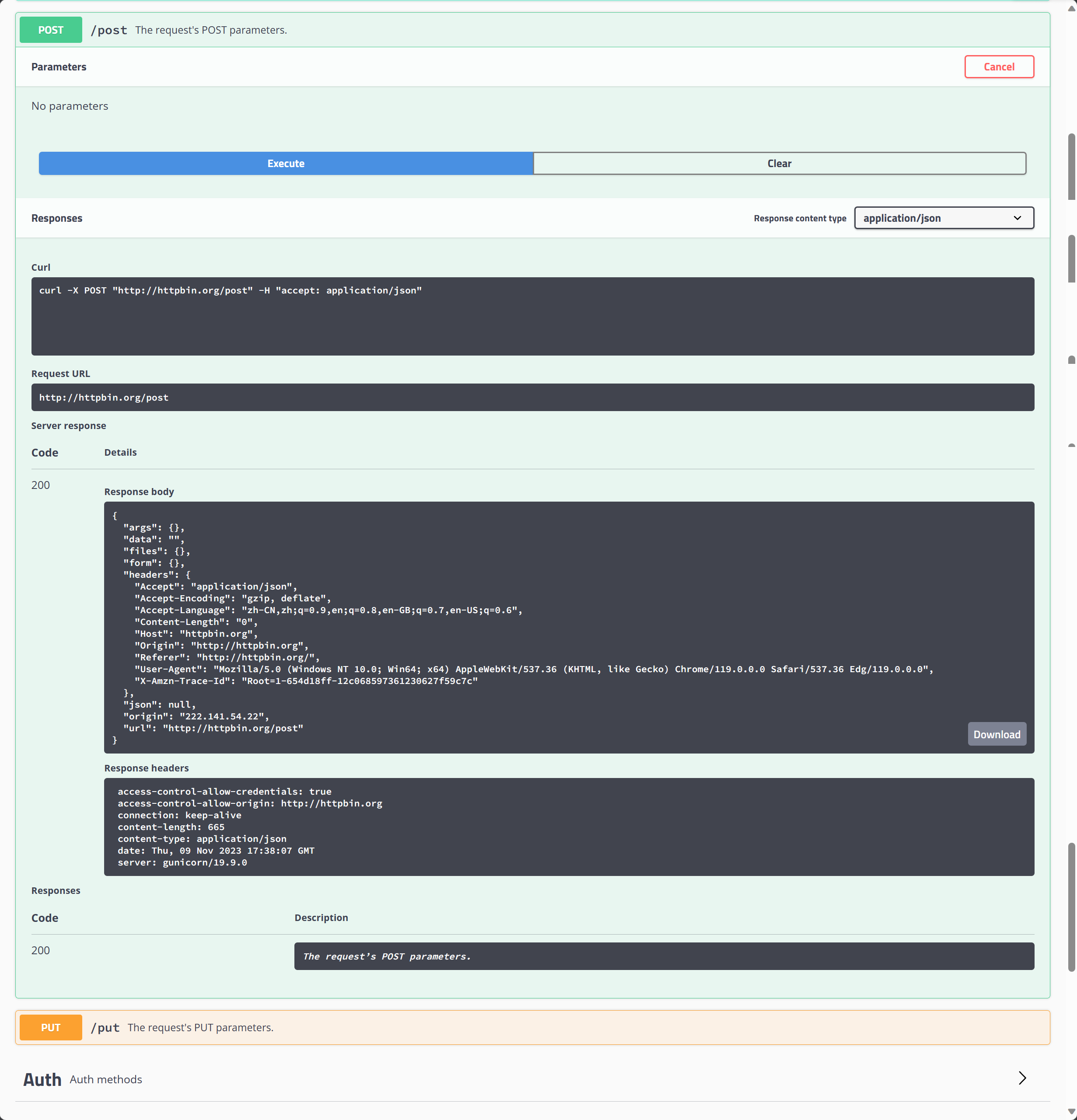
我们在pycharm中执行下面的代码
import urllib.request
import urllib.parse
data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
reponse=urllib.request.urlopen("http://httpbin.org/post",data= data)
print(reponse.read().decode("utf-8"))
运行后发现
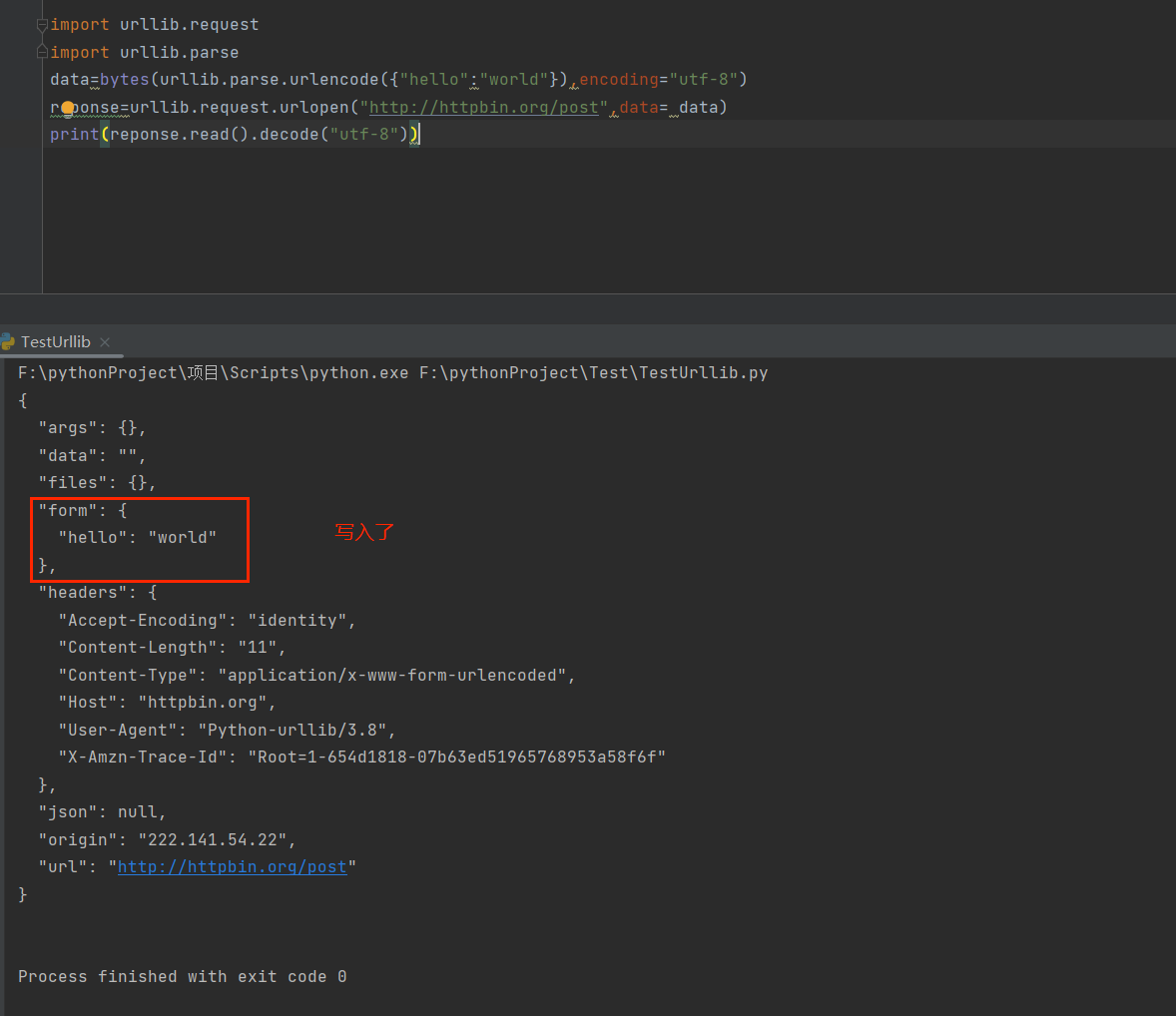
运行结果中写入了我们在代码中设置的"hello world"
同理,Get请求也可以使用这个网站来测试
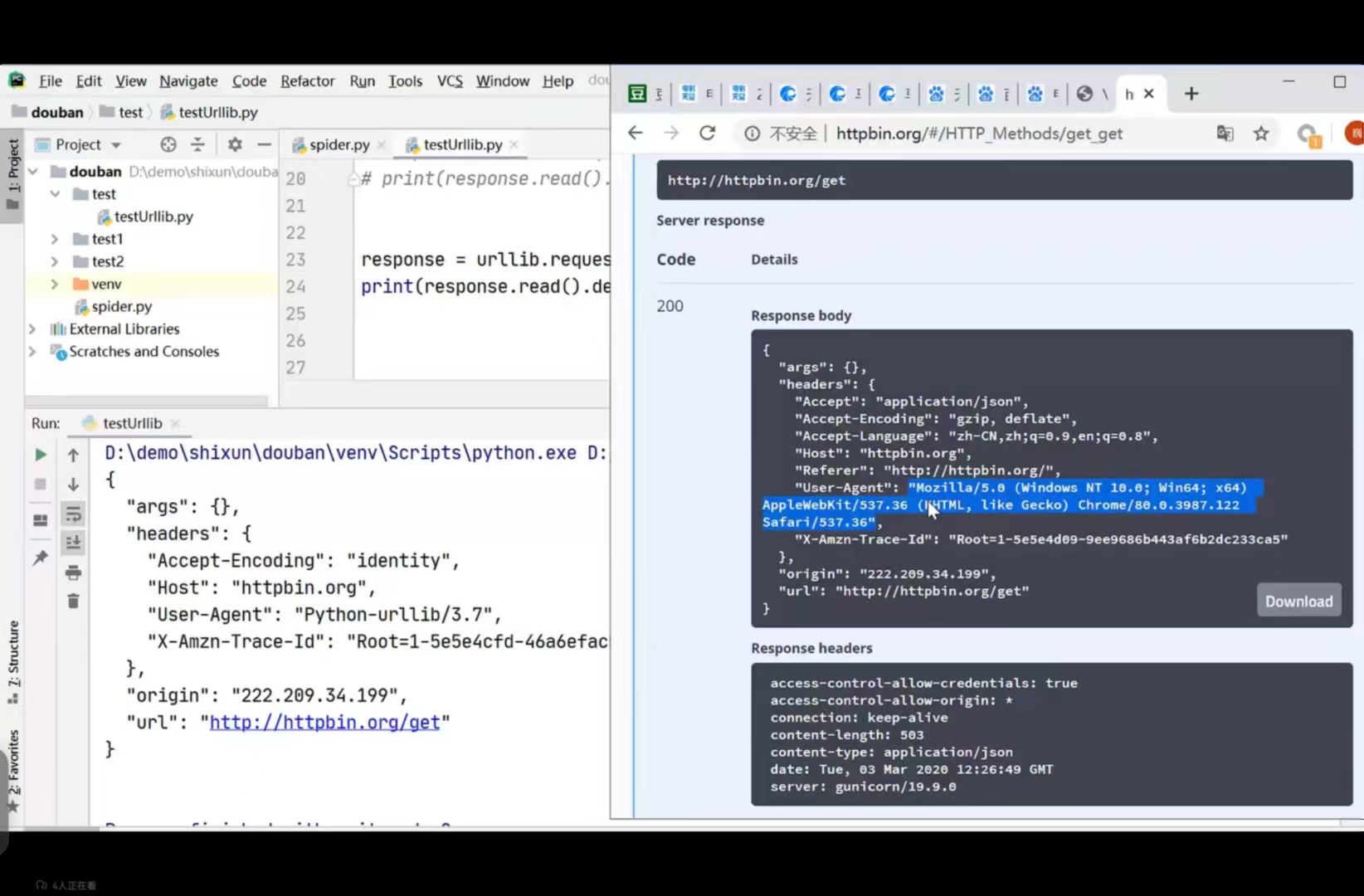
🛸下载
🎈下载网页
import urllib.request
url_page='http://www.baidu.com'
urllib.request.urlretrieve(url_page,'baidu.html')
运行后发现,出现了baidu.html这个文件
我们运行里面的代码,就出现了百度网页
🎈下载图片
import urllib.request
url_img='https://tse2-mm.cn.bing.net/th/id/OIP-C.EDJ9xoErBbZqK2tExVoJfAHaHY?pid=ImgDet&rs=1'
urllib.request.urlretrieve(url=url_img,filename='python.jpg')
运行后发现,出现了图片
打开图片后发现,成功了
🎈下载视频
我们首先打开一个视频,需要找到这个视频的src
我们打开后,找到某一个界面,然后暂停
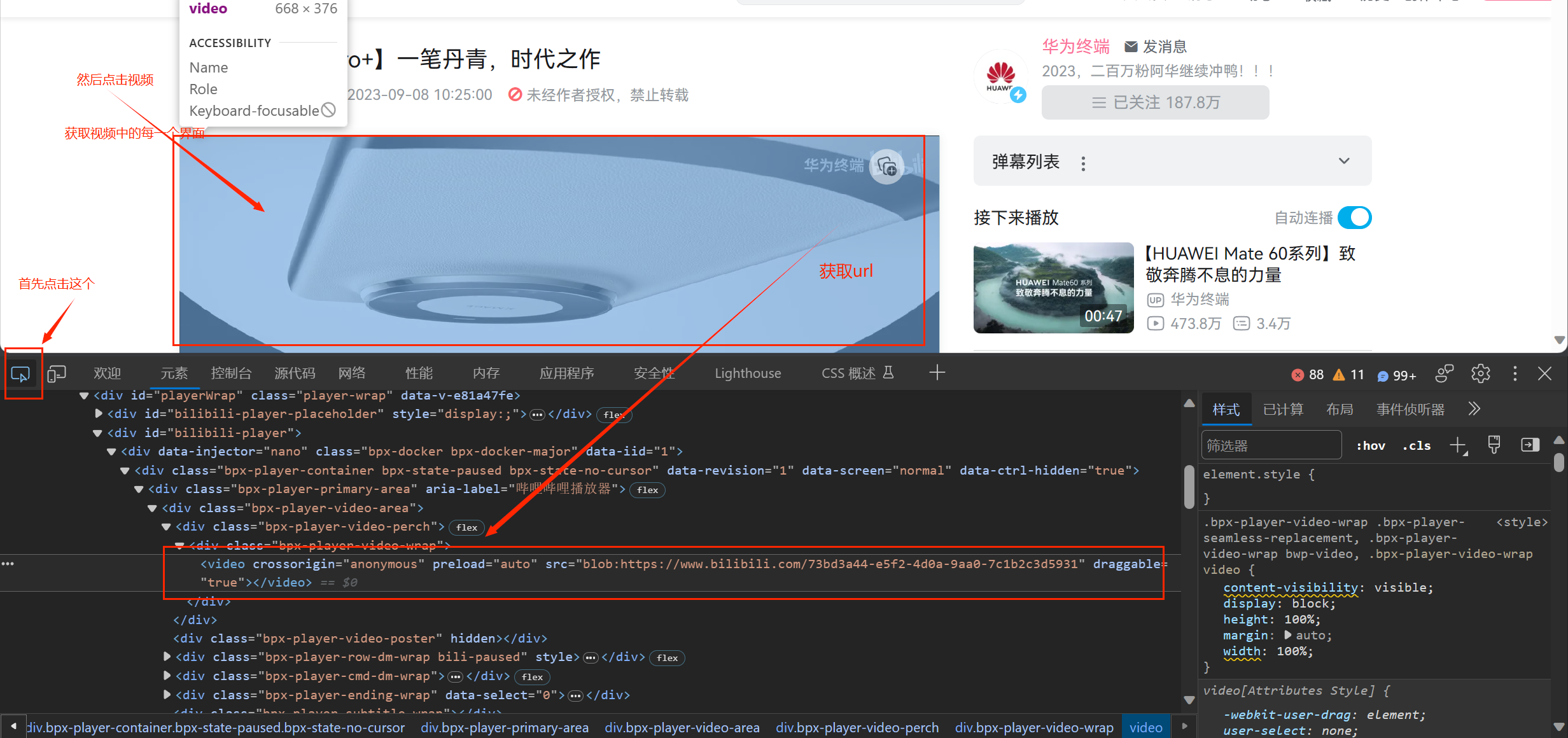
src:blob:https://www.bilibili.com/73bd3a44-e5f2-4d0a-9aa0-7c1b2c3d5931
然后编写代码
import urllib.request
url_video='blob:https://www.bilibili.com/73bd3a44-e5f2-4d0a-9aa0-7c1b2c3d5931'
urllib.request.urlretrieve(url_video,'huawei.mp4')
下载成功后,下载的视频自动保存到代码所在的文件夹中了
?超时处理
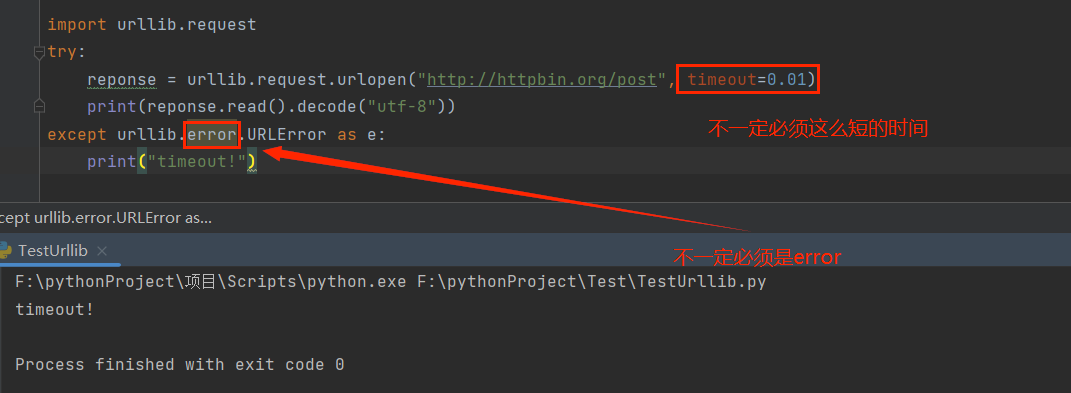
如果网速比较慢的话,就有可能发送请求超时的情况,下面我们来解决一下这种情况
import urllib.request
try:
reponse = urllib.request.urlopen("http://httpbin.org/post", timeout=0.01)
print(reponse.read().decode("utf-8"))
except urllib.error.URLError as e:
print("timeout!")
如果某个界面超时,我们再单独处理这个界面就行了
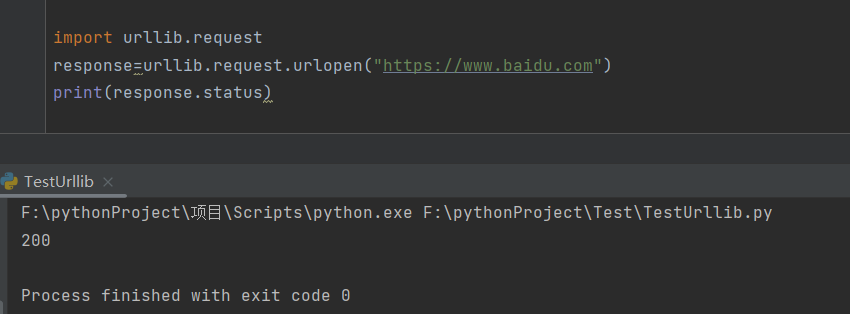
?查看状态码
import urllib.request
response=urllib.request.urlopen("https://www.baidu.com")
print(response.status)
?获取头部信息,状态码等内容
import urllib.request
response=urllib.request.urlopen("https://www.baidu.com")
print(response.getheaders())
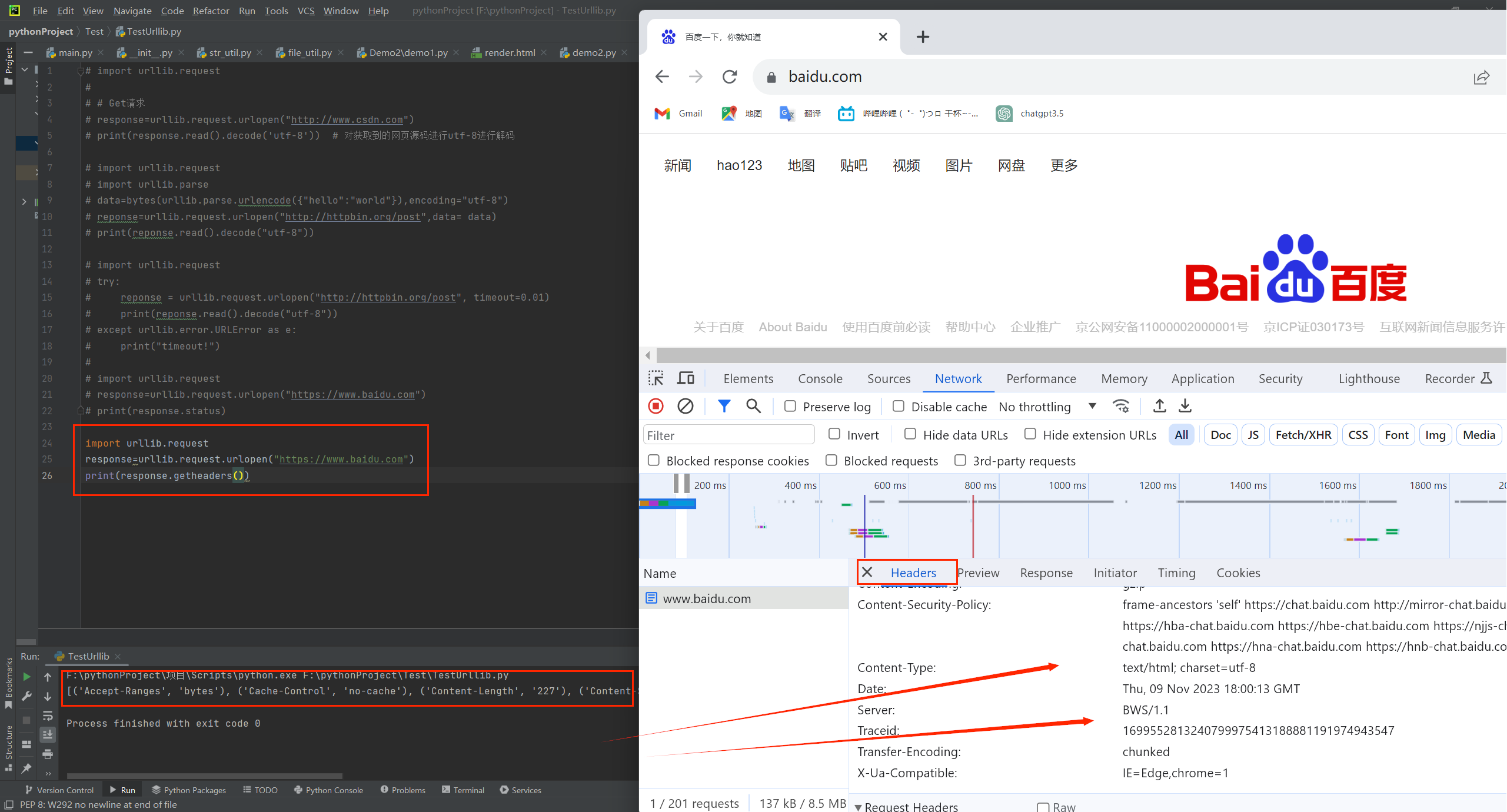
获取到的内容和浏览器的一致
?拿到具体内容

🛸状态码为418(反爬虫机制)
比如这种情况
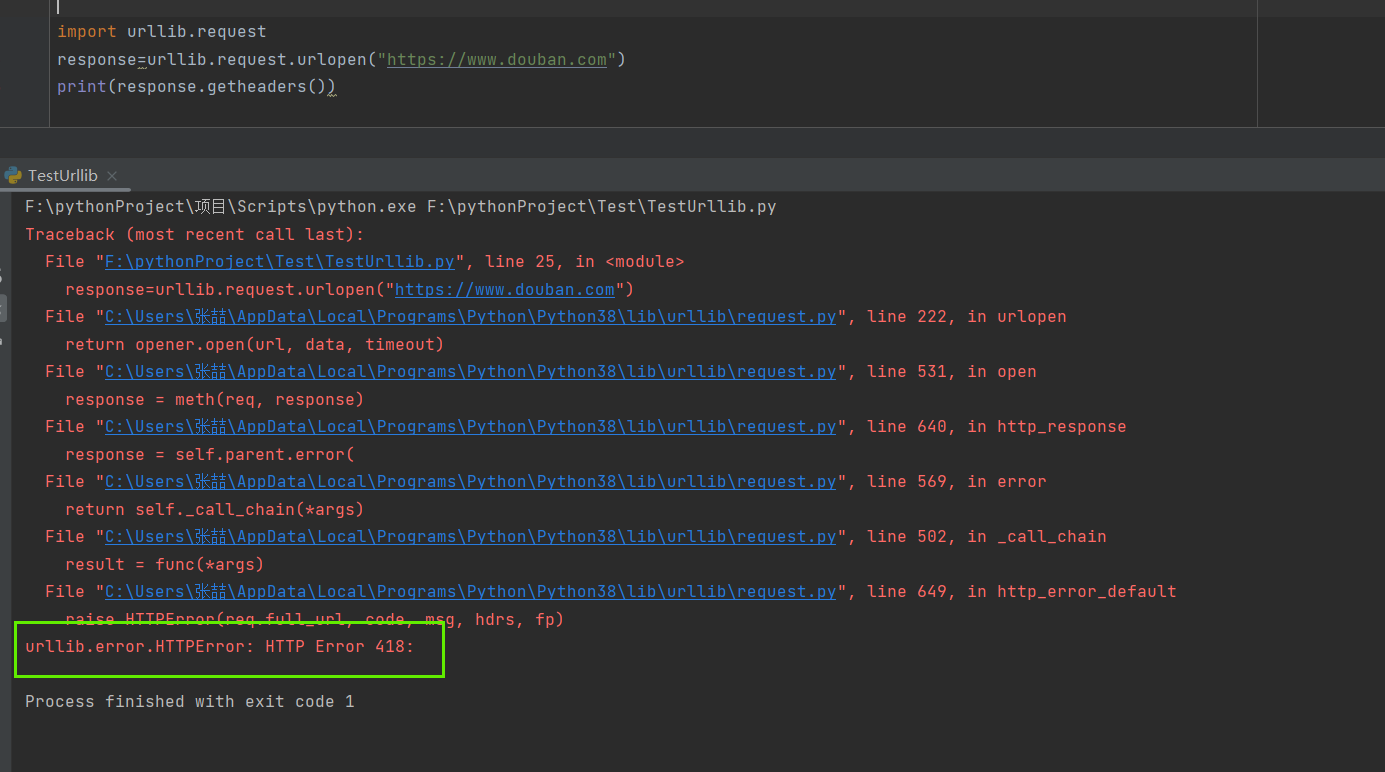
是因为网站设置了反爬虫机制,所以才会出现418
🏳??🌈如何避免反爬虫机制出现呢
避免反爬虫机制,就要让网站认为你不是在爬虫,认为你是一个浏览器,这样子就不会认为你在爬虫
下面是解决方法
我们随便进入一个网址,找到这段信息,复制下来,作为我们请求需要的头部信息
注意:这个要自己找,每个人的不一样
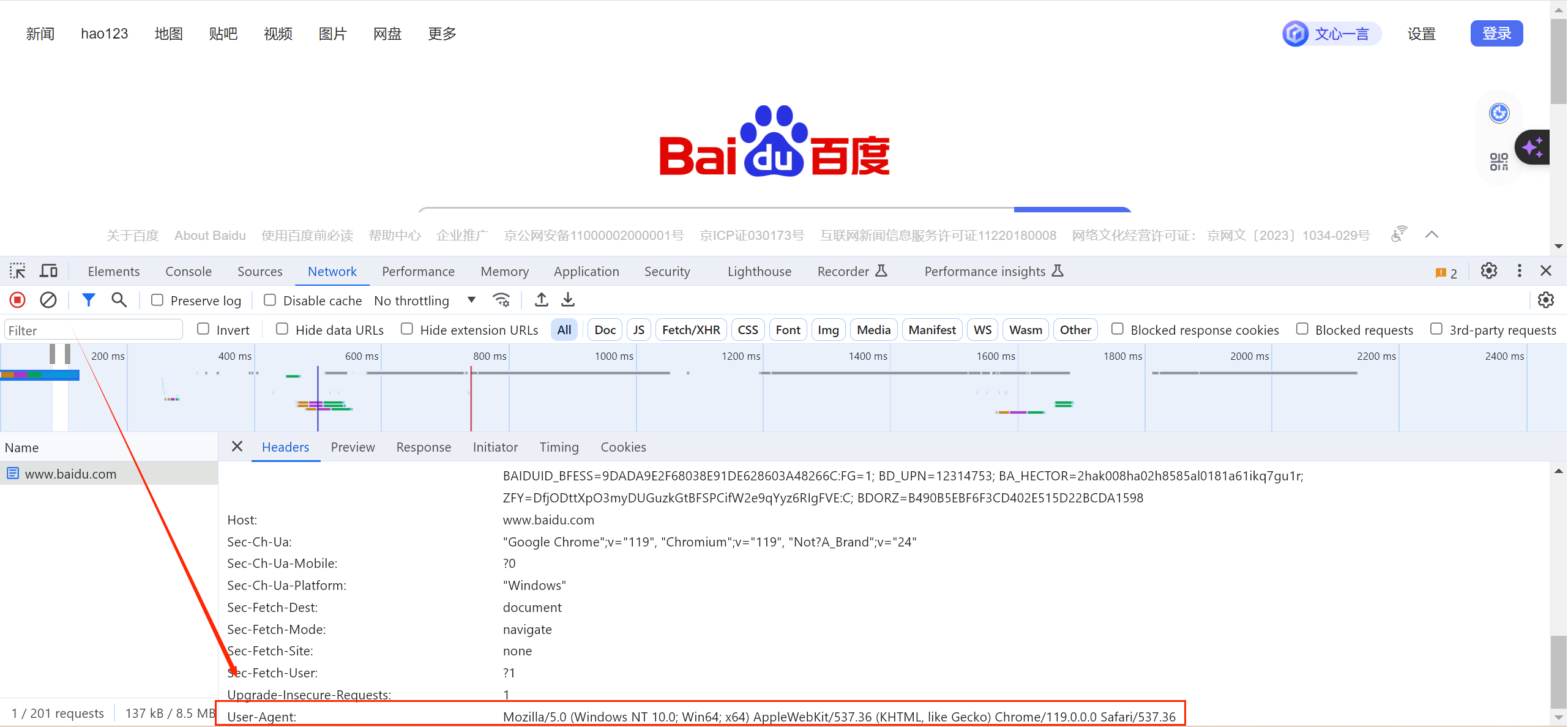
我们进行测试一下
🌹爬取网站
import urllib.request
url="https://www.douban.com"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
req=urllib.request.Request(url=url,headers=headers)
reponse=urllib.request.urlopen(req)
print(reponse.read().decode("utf-8"))
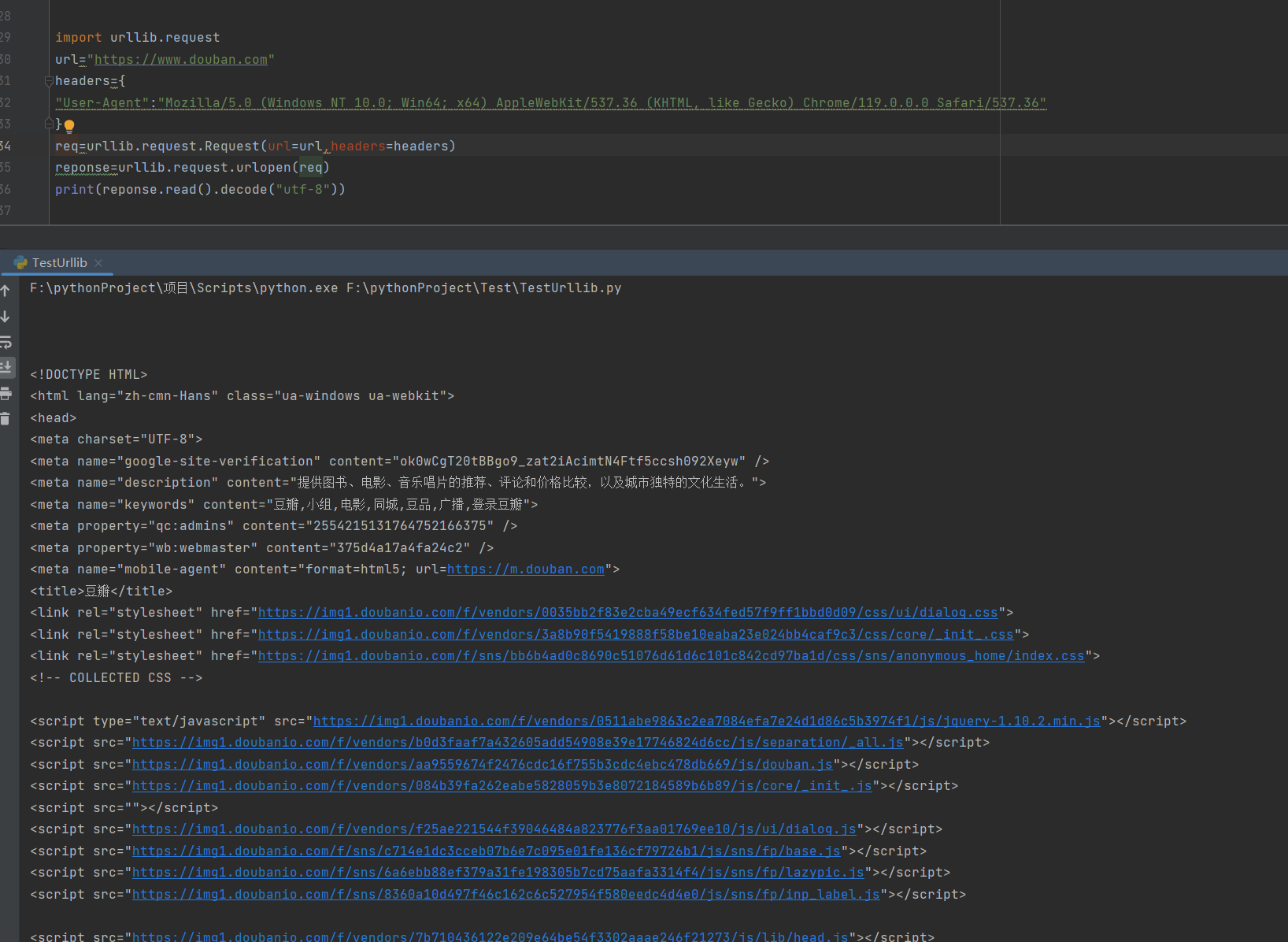
爬取成功了

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!