基于单目成像的目标定位
? ? ?基于单目成像的目标定位算法有很多,具体的选择取决于应用场景、精度要求、计算资源等因素。以下是一些常见的单目成像目标定位算法:
- 特征点匹配与三角测量:
- SIFT(Scale-Invariant Feature Transform)和 SURF(Speeded Up Robust Features): 这些特征提取算法可以提取图像中的关键点,并生成描述符,用于匹配不同图像中的对应点。通过匹配的特征点,可以使用三角测量等方法计算目标的三维坐标。
- 基于模板匹配的方法:
- 模板匹配算法: 使用预先定义的目标模板,在图像中寻找与模板最相似的区域。常见的方法包括归一化互相关(Normalized Cross-Correlation)。
- 直线和角点检测:
- Hough变换: 用于检测图像中的直线或者角点。通过检测目标边缘的直线,可以估计目标的位置。
- 角点检测算法: 如Shi-Tomasi角点检测算法和Harris角点检测算法,用于检测图像中的角点。
- 基于深度学习的方法:
- 神经网络模型: 使用卷积神经网络(CNN)进行目标检测和定位。常见的架构包括YOLO(You Only Look Once)、Faster R-CNN等。
- 单目深度估计: 利用深度学习模型估计图像中每个像素的深度信息,从而实现目标的三维定位。
- 基于几何形状的方法:
- 轮廓匹配: 利用目标的轮廓信息进行匹配。在一些场景中,目标的形状可能是唯一的标识符。
- 概率滤波器:
- 卡尔曼滤波器和粒子滤波器: 这些滤波器可以用于融合传感器测量值,提高目标位置估计的稳定性和精度。
- 深度学习与几何结合:
- 深度学习与几何结合: 结合深度学习方法和几何信息,可以通过学习场景的语义信息来提高目标定位的准确性。
在选择算法时,需要根据具体的应用场景、目标特性、实时性要求以及计算资源等方面进行权衡。同时,算法的性能也受到光照条件、噪声等环境因素的影响,因此可能需要根据具体情况进行调优。
基于深度学习的单目成像三维定位方法主要依赖于深度神经网络来从单张图像中直接预测目标的三维位置。以下是一个基于深度学习的单目成像三维定位的例子,其中使用的是深度学习模型中的单目深度估计。
单目深度估计模型
模型选择
使用预训练的单目深度估计模型,例如 Monocular Depth Estimation 模型。这类模型通常基于卷积神经网络(CNN)结构,例如 Monodepth2、Unsupervised Depth and Ego-Motion Learning (RAFT) 等。
数据准备
需要一个包含图像和对应深度信息的标定数据集。该数据集用于训练深度估计模型。深度信息可以通过激光雷达、RGB-D相机或者其他深度传感器获取。
模型训练
- 准备标签数据: 使用标定的深度数据作为监督信号,将深度图像作为目标,将RGB图像作为输入。标签数据可以通过配准深度传感器和相机得到。
- 模型训练: 使用准备好的标签数据对深度估计模型进行训练。训练过程中,模型会学习图像中每个像素点的深度信息。损失函数通常包括深度图像的差异,平滑项等。
- 迁移学习(可选): 如果没有足够的标定数据,可以使用在其他任务上预训练好的深度估计模型,然后通过迁移学习进行微调。
三维定位
目标检测与单目深度估计结合
- 目标检测: 使用目标检测模型(例如YOLO、Faster R-CNN等)来检测图像中的目标物体,并获取其二维边界框。
- 单目深度估计: 对于每个检测到的目标区域,使用训练好的单目深度估计模型来估计目标区域的深度信息。
- 三维坐标计算: 利用相机的内参矩阵和深度信息,将图像中的目标区域的二维坐标映射到相机坐标系中,并计算目标的三维坐标。
CRF单目深度估计算法:
CRF(Conditional Random Field,条件随机场)在单目深度估计中通常用于引入上下文信息,从而提高深度估计的准确性。CRF-based 单目深度估计算法通常结合了深度学习模型和条件随机场,利用图像的局部和全局一致性来调整深度估计的结果。
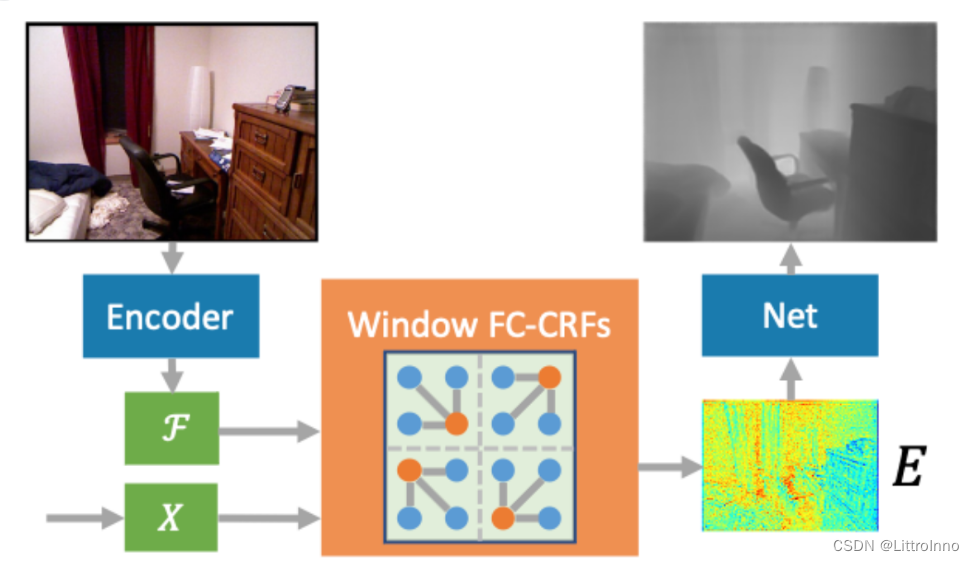
以下是一个简要的介绍:
1. 深度学习模型预测
首先,使用深度学习模型(如卷积神经网络)对输入图像进行单目深度估计。这个模型可以是已经预训练好的深度估计网络,如 Monodepth2 或者使用自定义网络结构。
2. 成本势能计算
对于深度估计结果,将每个像素处的深度值作为一个节点,构建一个无向图。然后,通过计算成本势能(potential energy)来衡量深度图的一致性。
成本势能通常考虑以下几个因素:
-
数据项(Data Term): 衡量深度图与输入图像的一致性。这可以通过像素级的差异度量,如均方差等,来表示。
-
平滑项(Smoothness Term): 衡量深度图中相邻像素深度之间的一致性。目的是使深度图在空间上更加平滑。
-
空间项(Spatial Term): 引入相邻像素之间的空间关系,考虑相邻像素之间的相似性。
3. CRF 模型构建
构建一个 CRF 模型,其中节点表示深度图中的像素,边表示像素之间的关系。CRF 模型定义了每个节点的势能(potential),即深度值的可能性。
4. 推断和优化
通过推断算法(如 Loopy Belief Propagation 或 Mean Field Inference),优化 CRF 模型中的势能,得到更加一致的深度图。这个过程通常涉及到最小化 CRF 模型中的能量函数。
5. 结果后处理
最后,可以对得到的深度图进行一些后处理操作,如去噪、边缘保持等,以获得更加准确和平滑的深度估计结果。
这样的 CRF-based 单目深度估计方法通过引入上下文信息和全局一致性,有助于减小深度估计中的局部误差,提高深度图的准确性。这种方法在复杂场景中,特别是存在纹理缺失或低纹理区域时,通常能取得较好的效果。然而,由于 CRF 的计算较为复杂,可能会增加计算负担。因此,在实际应用中,需要权衡算法的性能和计算效率。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 翻译: LLMs大语言模型影响到高工资的的白领知识工作者 加速各行各业的自动化潜力 Automation potential across sectors
- vivado 定义相对放置的宏
- Python - 字典4
- Python:五种算法RFO、GWO、DBO、HHO、SSA求解23个测试函数
- C++从零开始的打怪升级之路(day10)
- 初始JavaScript详解【精选】
- Linux的权限(2)
- git常用命令详解
- C单片机关键字extern、static 和 const
- 警惕黑客对网站根目录压缩文件进行暴力搜刮