ModelNet数据集下载及预处理
ModelNet数据集下载
ModelNet数据集是一个广泛用于三维形状识别和理解的大规模数据集。该数据集由麻省理工学院(MIT)的计算机科学与人工智能实验室(CSAIL)创建,并在2013年发布。
ModelNet数据集包含了各种不同类别的三维模型。这些模型来自于多个来源,包括Google 3D Warehouse、Trimble 3D Warehouse和部分自定义模型。数据集中的模型涵盖了常见的物体类别,如桌子、椅子、床、沙发、书架、显示器等,总共包含了40个不同的类别。
ModelNet数据集提供了两个版本:ModelNet10和ModelNet40。ModelNet10包含了每个类别约3991个三维模型,而ModelNet40则包含了每个类别约9843个三维模型。每个模型均以OFF格式(包含顶点和面片信息)存储,并且具有统一的尺寸和方向。
你可以在麻省理工的官网上下载数据集
但是我自己在进行下载时出现了点击下载地址没有反应的情况

你可以通过按F12来找到他后台的下载地址
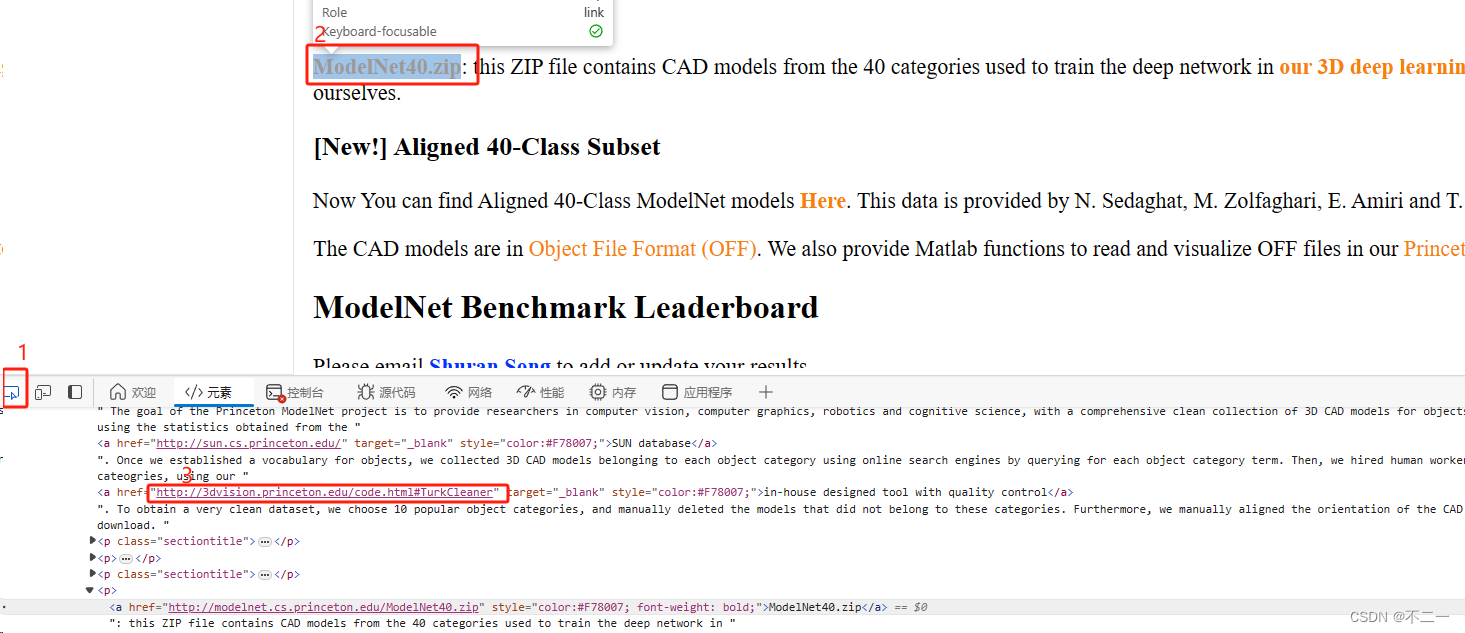
- 先点击1的图标
- 将鼠标挪到2点击这个下载地址
- 你可以从下面找到一个下载网址,你能通过打开这个网址来进行下载
对下载数据的预处理
原始的下载数据
这里以modelNet10为例介绍,一共有十种类别

你可以看到所有的数据都是.off格式
以下是文件的举例,来自官方文档
OFF
8 6 0
-0.500000 -0.500000 0.500000
0.500000 -0.500000 0.500000
-0.500000 0.500000 0.500000
0.500000 0.500000 0.500000
-0.500000 0.500000 -0.500000
0.500000 0.500000 -0.500000
-0.500000 -0.500000 -0.500000
0.500000 -0.500000 -0.500000
4 0 1 3 2
4 2 3 5 4
4 4 5 7 6
4 6 7 1 0
4 1 7 5 3
4 6 0 2 4
OFF为文档的开始 第二行中8 为定点数 ,6 为面数,0为边数(可以被忽略所以这里为0)。
之后的8行为顶点的三维坐标 ,然后6行为面,例如4 0 1 3 2,4为确定该面的点数,0 1 3 2 为顶点的坐标
你也可以直接在cloudcompare中将这个文件打开
例如desk_0001.off

对数据进行处理
我直接将点云数据进行采样以后另存为.xyz文件(每个文件只存储了点的xyz坐标,如果你想获取分类的标签可以直接从文件名上面获取)并按照原始摆放顺序存储,利用open3d库进行处理
注释写的比较详细,希望你能够看懂
point_cloud = sample_points_from_off(old_path, 10000) 我选择每个点云图像都采样10000个点你可以更改自由更改为你想要的顺序
import os
from tqdm import tqdm
import open3d as o3d
# 对off点云数据进行采样
def sample_points_from_off(off_file, num_points):
# 读取OFF文件
mesh = o3d.io.read_triangle_mesh(off_file)
# 将OFF文件转换为点云
point_cloud = mesh.sample_points_uniformly(num_points)
return point_cloud
# 文件夹路径
path = 'ModelNet10\ModelNet10'
folder_path =[]
# 获取每一个类别的名称
for item in os.listdir(path):
if not '.' in item:
folder_path.append(os.path.join(path, item))
# 获取文件名
def get_file_name(path):
return path.split('\\')[-1].split('.')[0]
# 遍历所有文件夹
for file in folder_path:
# 获得完整的训练集和测试集文件路径
train_file = os.path.join(file, 'train')
test_file = os.path.join(file, 'test')
# 对训练集和测试集进行处理
for filepath in [train_file, test_file]:
# 获取该文件夹下的所有文件名
filenames = os.listdir(filepath)
# 处理每个文件(点云)
for filename in tqdm(filenames):
# 获取点云文件的完整地址
old_path = os.path.join(filepath, filename)
# 如果文件名以.开头,则跳过(这里假设以.开头的文件是无效文件)
if(filename.startswith('.')):
continue
# 读取点云数据
point_cloud = sample_points_from_off(old_path, 10000)
# 生成新的文件名(将原文件名的扩展名改为.xyz)
name = get_file_name(old_path) + '.xyz'
# 新的文件的地址
new_path = os.path.join('new'+old_path).replace(get_file_name(old_path) + '.off', name)
# 创建新的文件夹(如果不存在)
new_folder = os.path.join(*new_path.split('\\')[:-1])+'\\'
os.makedirs(new_folder, exist_ok=True)
# 保存新的点云文件
o3d.io.write_point_cloud(new_path, point_cloud)
这是我的文件结构

这里处理后的文件结构,保持了文件的名字和存储结构

这是利用cloudcompare打开的desk_0001.xyz,只存储了点的三维坐标

这是以上程序的多进程版本
由于数据量比较多(如果你还想用在modelnet40上),一下是多进程版本,速度会非常快
import os
from tqdm import tqdm
import open3d as o3d
from concurrent.futures import ProcessPoolExecutor
# 对off点云数据进行采样
def sample_points_from_off(off_file, num_points):
# 读取OFF文件
mesh = o3d.io.read_triangle_mesh(off_file)
# 将OFF文件转换为点云
point_cloud = mesh.sample_points_uniformly(num_points)
return point_cloud
# 获取文件名
def get_file_name(path):
return path.split('\\')[-1].split('.')[0]
# 定义一个函数,用来处理单个文件
def process_file(filepath):
filenames = os.listdir(filepath)
for filename in tqdm(filenames):
old_path = os.path.join(filepath, filename)
# 如果文件名以.开头,则跳过(这里假设以.开头的文件是无效文件)
if filename.startswith('.'):
continue
# 读取点云数据
point_cloud = sample_points_from_off(old_path, 10000)
# 生成新的文件名(将原文件名的扩展名改为.xyz)
name = os.path.splitext(filename)[0] + '.xyz'
# new_path = os.path.join('new', os.path.dirname(old_path), name)
# 新的文件的地址
new_path = os.path.join('new'+old_path).replace(get_file_name(old_path) + '.off', name)
# 创建新的文件夹(如果不存在)
new_folder = os.path.dirname(new_path)
os.makedirs(new_folder, exist_ok=True)
# 保存新的点云文件
o3d.io.write_point_cloud(new_path, point_cloud)
# 遍历文件夹中的文件
def process_files_in_folder(folder_path):
with ProcessPoolExecutor() as executor:
for file in folder_path:
# 对训练集和测试集进行处理
train_file = os.path.join(file, 'train')
test_file = os.path.join(file, 'test')
# 使用多进程处理每个文件(点云)
executor.submit(process_file, train_file)
executor.submit(process_file, test_file)
if __name__ == '__main__':
# 文件夹路径
path = 'ModelNet10\ModelNet10'
folder_path =[]
# 获取每一个类别的名称
for item in os.listdir(path):
if not '.' in item:
folder_path.append(os.path.join(path, item))
# 运行任务
process_files_in_folder(folder_path)
如果你想运用在modelnet上可能需要一点点更改(目前我还没下载modelnet40数据)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 技术型企业如何选择安全、性价比高的FTP替代方案?
- MySql数据库对接Orcal数据库,需要考虑的前提问题
- 【linux学习笔记】目录与文件
- Linux粘滞位的理解,什么是粘滞位?
- Java复习_2
- Camtasia2024国产简单易用的高清录屏和视频编辑软件
- overleaf 加载pdf格式的矢量图时,visio 图片保存为pdf格式,如何确保pdf页面大小和图片一致
- 【一步一步学】ROS 的SSTP 介绍与应用
- 智能对话意图分析服务接口
- postman win7 低版本 postman7.0.9win64 postman7.0.9win32