(超详细)YOLOv5训练出结果,如何分析结果的性能分析
一、 confusion_matrix
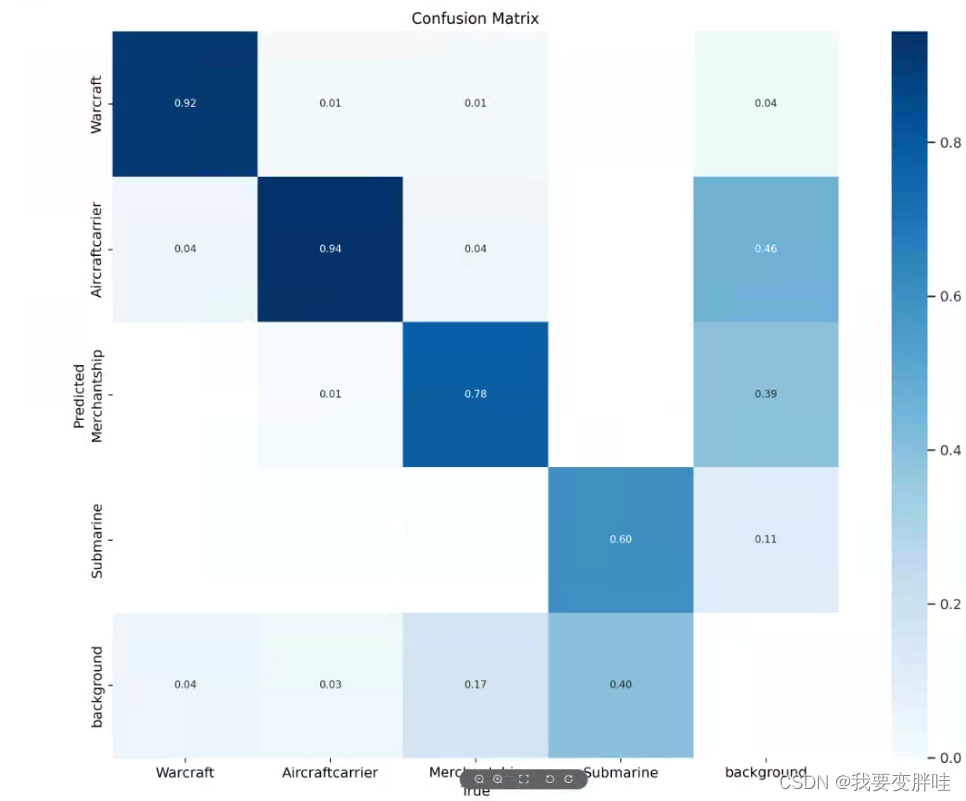
行是预测类别(y轴),列是真实类别(x轴);
矩阵中Aij的含义是:第j个类别被预测为第i个类别的概率;
二、P_curve
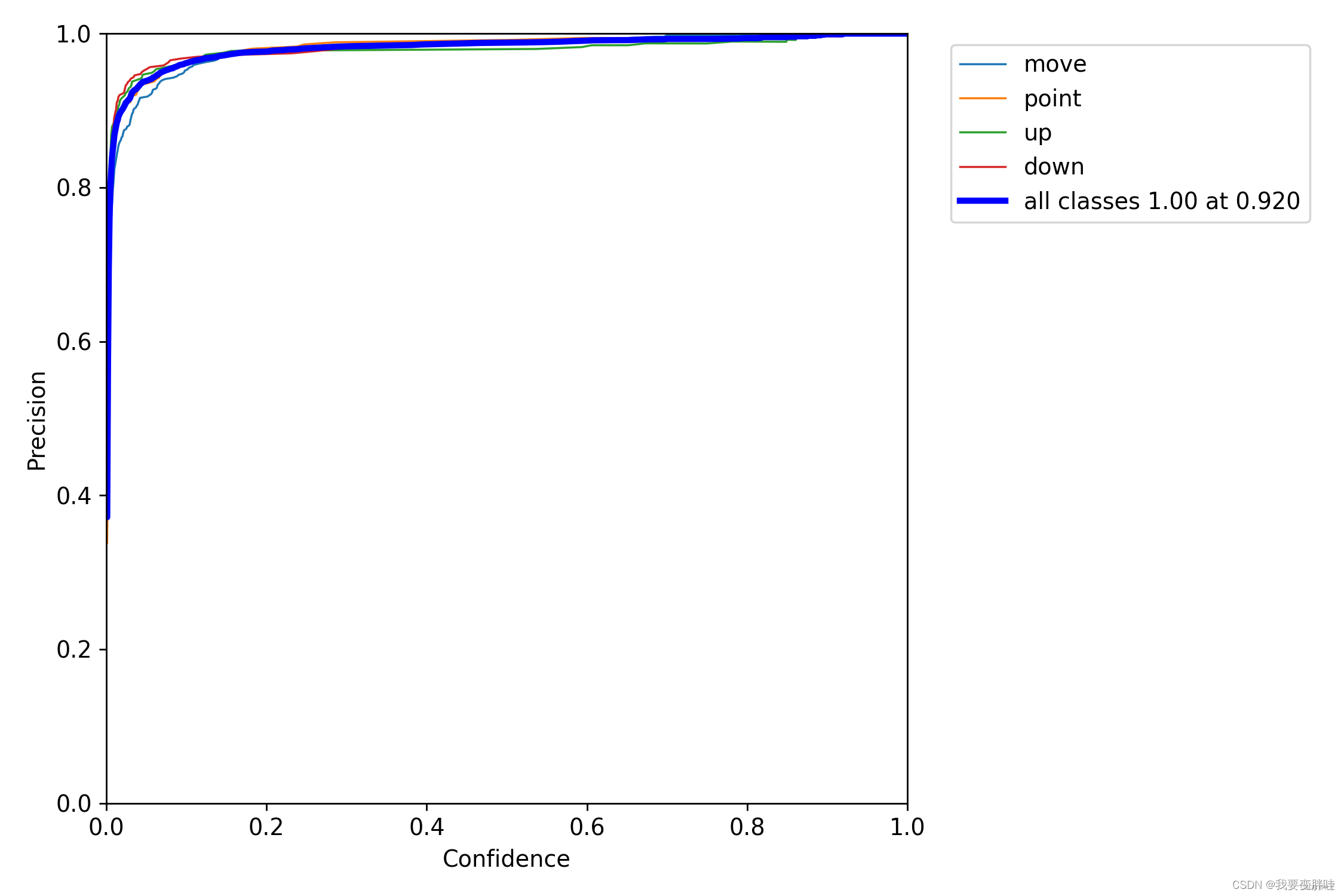
准确率和置信度的关系图。
意思就是,当我设置置信度为某一数值的时候,各个类别识别的准确率。可以看到,当置信度越大的时候,类别检测的越准确。这也很好理解,只有confidence很大,才被判断是某一类别。但也很好想到,这样的话,会漏检一些置信度低的类别。
三、R_curve
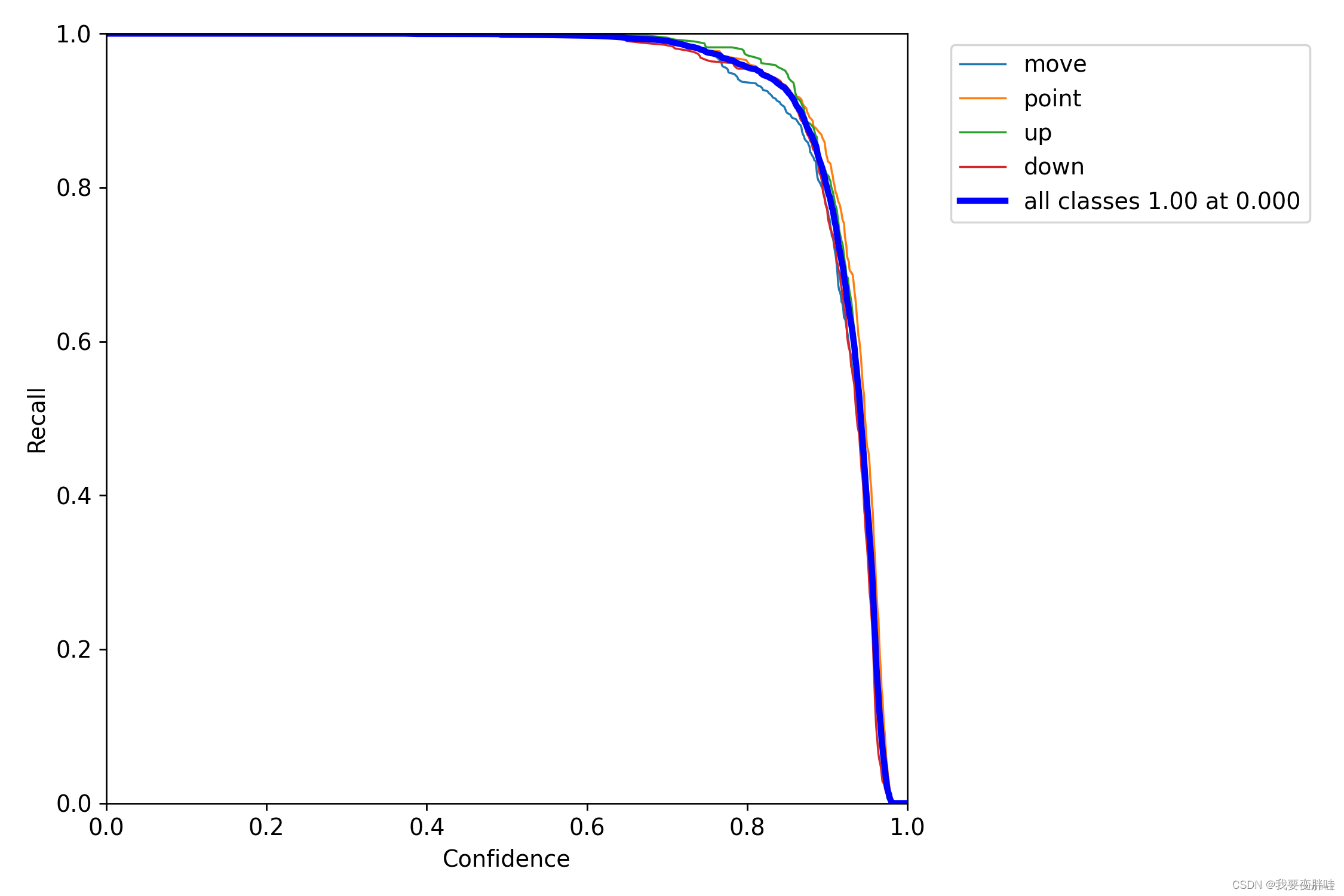
召回率(查全率)和置信度的关系图。
意思就是,当我设置置信度为某一数值的时候,各个类别查全的概率。可以看到,当置信度越小的时候,类别检测的越全面。
四、PR_curve
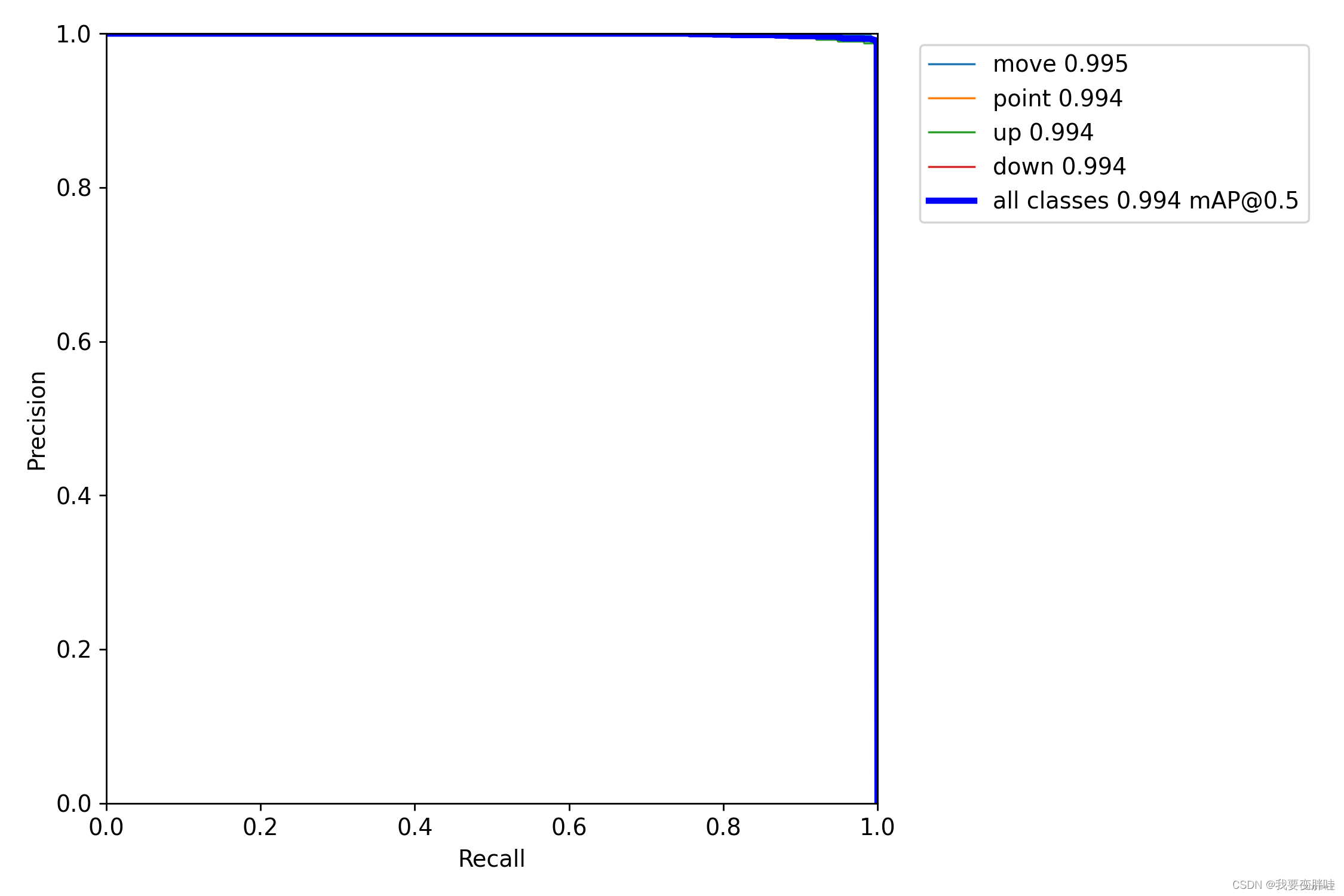
mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看到:精度越高,召回率越低。
但我们希望我们的网络,在准确率很高的前提下,尽可能的检测到全部的类别。所以希望我们的曲线接近(1,1)点,即希望mAP曲线的面积尽可能接近1。
五、 F1_curve
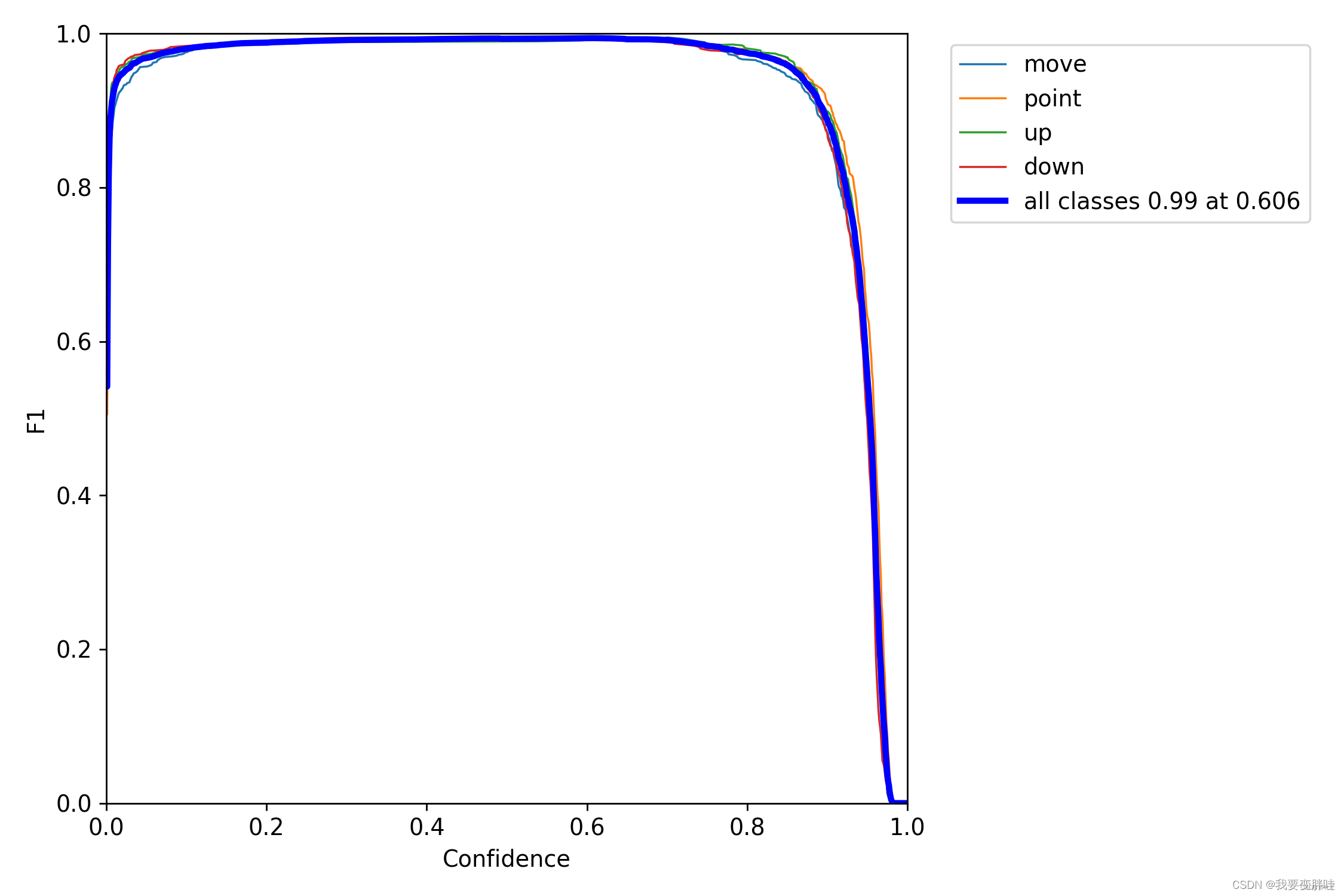
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差。
六、labels.jpg
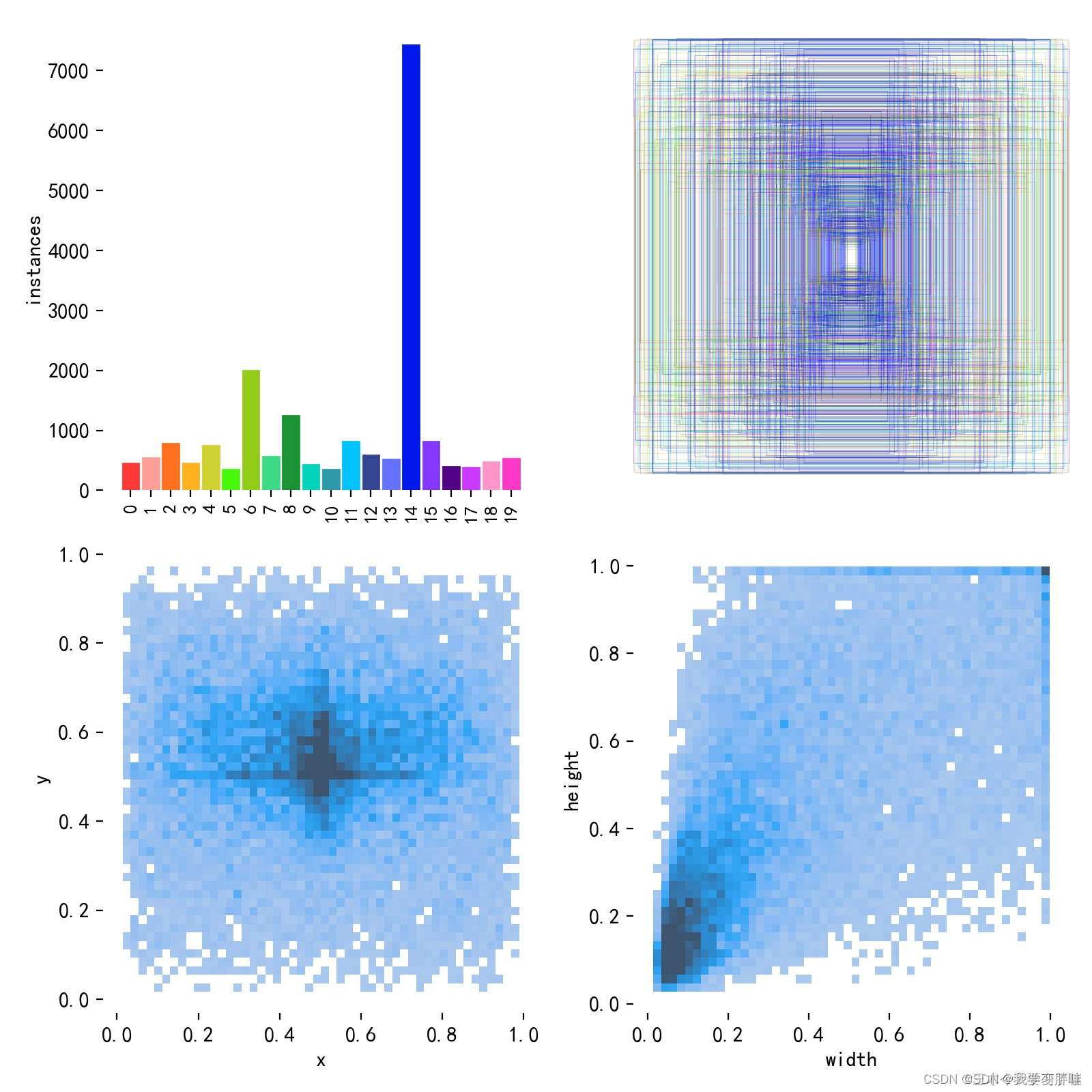
第一个图是训练集得数据量,每个类别有多少个;
第二个图是框的尺寸和数量;
第三个图是中心点相对于整幅图的位置;
第四个图是图中目标相对于整幅图的高宽比例;
七、labels_correlogram.jpg —— 体现中心点横纵坐标以及框的高宽间的关系
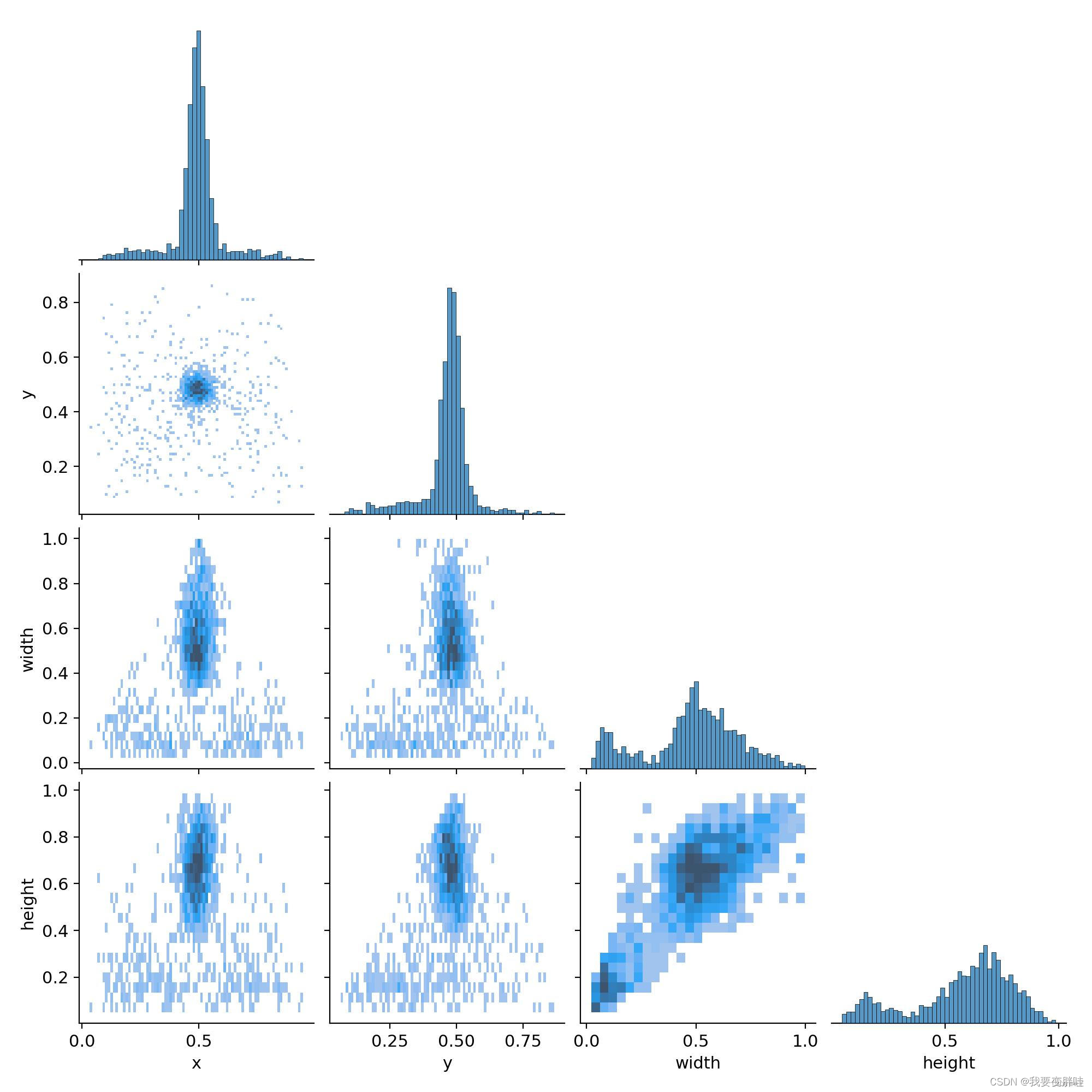
表示中心点坐标x和y,以及框的高宽间的关系。
每一行的最后一幅图代表的是x,y,宽和高的分布情况:
最上面的图(0,0)表明中心点横坐标x的分布情况,可以看到大部分集中在整幅图的中心位置;
(1,1)图表明中心点纵坐标y的分布情况,可以看到大部分集中在整幅图的中心位置;
(2,2)图表明框的宽的分布情况,可以看到大部分框的宽的大小大概是整幅图的宽的一半;
(3,3)图表明框的宽的分布情况,可以看到大部分框的高的大小超过整幅图的高的一半
而其他的图即是寻找这4个变量间的关系
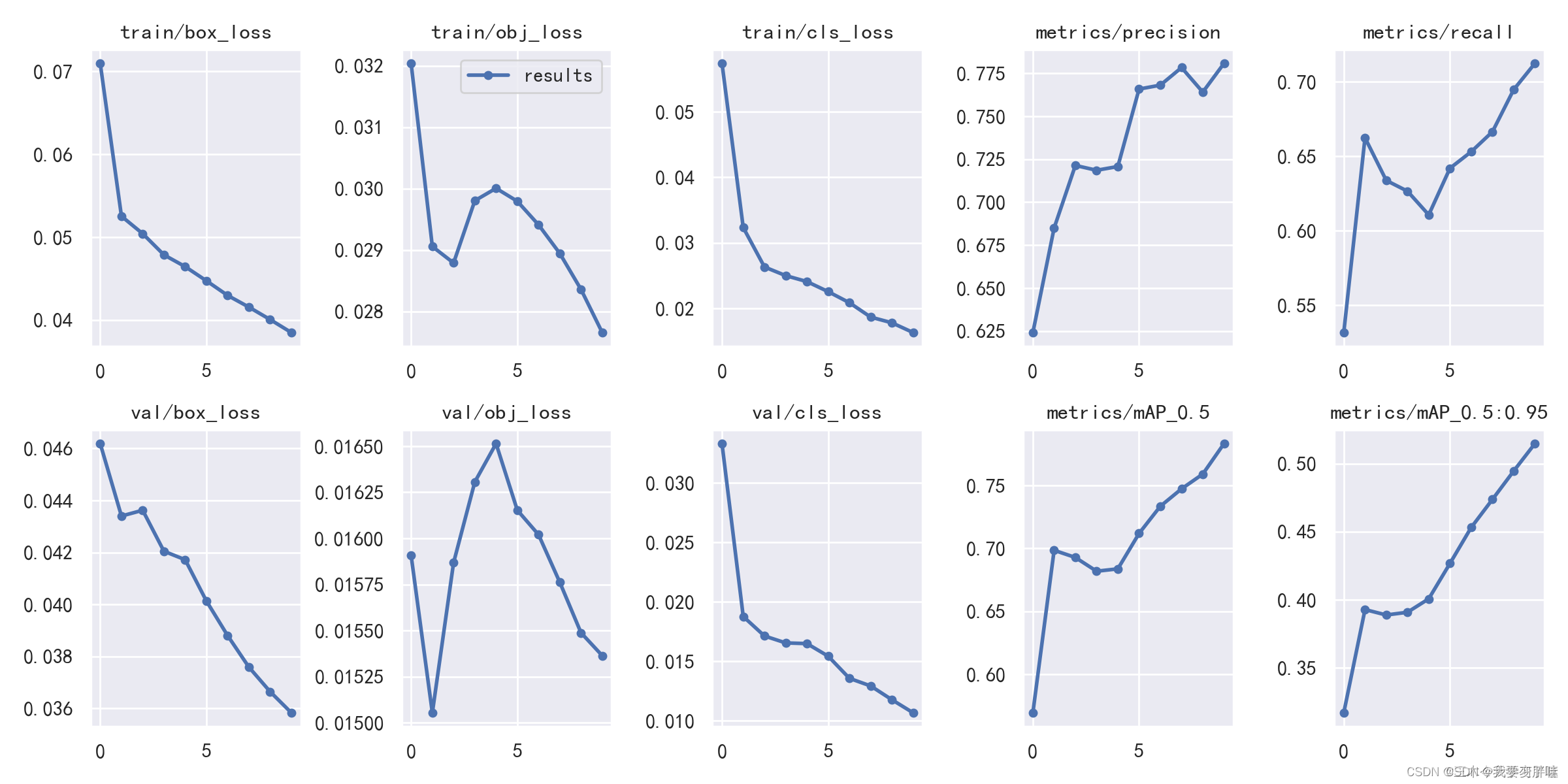
八、result.png —— 结果loss functions
🌳定位损失box_loss:
预测框与标定框之间的误差(CIoU),越小定位得越准;
🌳置信度损失obj_loss:
计算网络的置信度,越小判定为目标的能力越准;
🌳分类损失cls_loss:
计算锚框与对应的标定分类是否正确,越小分类得越准;
🌳mAP@0.5:0.95(mAP@[0.5:0.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP;
🌳mAP@0.5:
表示阈值大于0.5的平均mAP
十、result.csv
results.txt中最后三列是验证集结果,前面的是训练集结果,全部列分别是:
训练次数,GPU消耗,边界框损失,目标检测损失,分类损失,total,targets,图片大小,P,R,mAP@.5, mAP@.5:.95, 验证集val Box, 验证集val obj, 验证集val cls

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!