3.4 SYNCHRONIZATION AND TRANSPARENT SCALABILITY
到目前为止,我们已经讨论了如何启动内核以通过线程网格执行,以及如何将线程映射到数据结构的一部分。然而,我们尚未提出任何方法来协调多个线程的执行。我们现在将研究一个基本的协调机制。CUDA允许同一块中的线程通过使用屏障同步函数__syncthreads()来协调其活动。请注意,“__“由两个字符组成。**当线程调用__syncthreads()时,它将保持在调用位置,直到块中的每个线程到达该位置。**此过程确保块中的所有线程在进入下一阶段之前都已完成内核执行的一个阶段。
屏障同步是协调并行活动的一种简单而流行的方法。在现实生活中,我们经常使用屏障同步来协调多人的并行活动。为了说明,假设四个朋友开车去购物中心。他们都可以去不同的商店买自己的衣服。这是一个平行的活动,比他们都作为一个团体并按顺序访问所有感兴趣的商店要有效得多。然而,在他们离开商场之前,需要屏障同步。他们必须等到四个朋友都回到车上才能离开。那些比别人先完成的人需要等待那些稍后完成的人。如果没有屏障同步,当汽车离开时,一个或多个人可能会被留在商场里,这可能会严重损害他们的友谊!
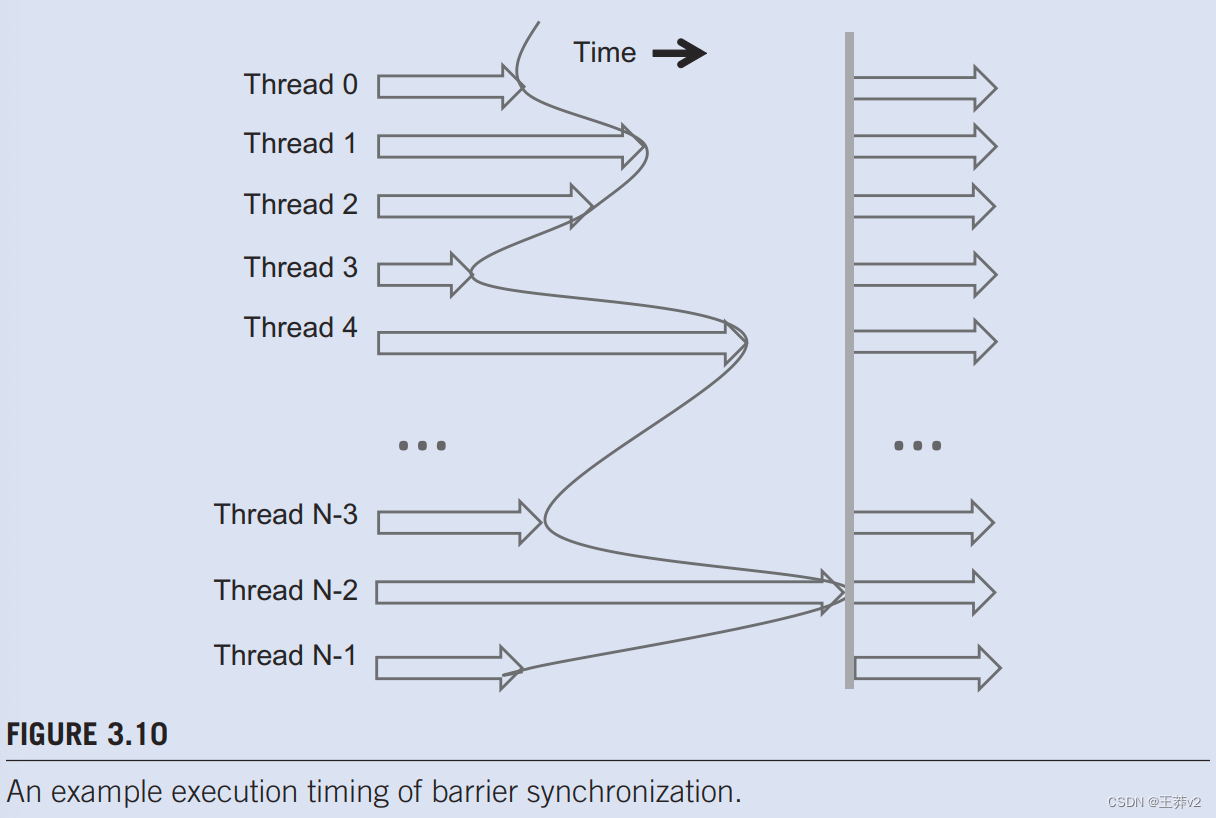
图3.10说明了屏障同步的执行。块中有N个线程。时间从左到右。有些线程很早就到达了屏障同步语句,有些则很晚才到达。早到障碍物的人会等待那些晚到的人。当最新的到达障碍物时,每个人都可以继续执行。有了屏障同步,*没有人被抛在后面。”
在CUDA中,__syncthreads()语句(如果存在)必须由块中的所有线程执行。当__syncthread()语句放置在if语句中时,块中的所有线程或没有线程执行包含__syncthreads()的路径。对于if-then-else语句,如果每个路径都有_syncthreads()语句,则块中的所有线程要么执行then-path,要么所有线程都执行else-path。两个__syncthreads()是不同的屏障同步点。如果块中的一个线程执行然后路径,而另一个线程执行else路径,它们将在不同的屏障同步点等待。他们最终会永远等待对方。程序员有责任编写代码,以便满足这些要求。
**同步的能力还对块内的线程施加了执行约束。这些线程应彼此在时间上非常接近地执行,以避免等待时间过长。**事实上,人们需要确保障碍同步所涉及的所有线程都能获得必要的资源,以最终到达障碍。否则,一个从未到达障碍同步点的线程可能会导致其他人永远等待。CUDA运行时系统通过将执行资源作为单元分配给块中的所有线程来满足此约束。只有当运行时系统保护了所需的所有资源时,块才能开始执行块中的所有线程完成执行。当一个块的线程被分配给执行资源时,同一块中的所有其他线程也会被分配给同一资源。此条件确保了块中所有线程的时间接近,并防止屏障同步期间的等待时间过长或不确定。
这导致我们在CUDA屏障同步设计方面进行了重要的权衡。通过不允许不同块中的线程相互执行屏障同步,CUDA运行时系统可以按任何相对顺序执行块,因为它们都不需要相互等待。这种灵活性实现了可扩展的实现,如图3.11所示,时间从上到下。在一个只有少数执行资源的低成本系统中,人们可以同时执行少量块,在图3.11的左侧被描绘成一次执行两个块。在具有更多执行资源的高端实现中,可以同时执行大量块,在图3.11的右侧一次显示为四个块。
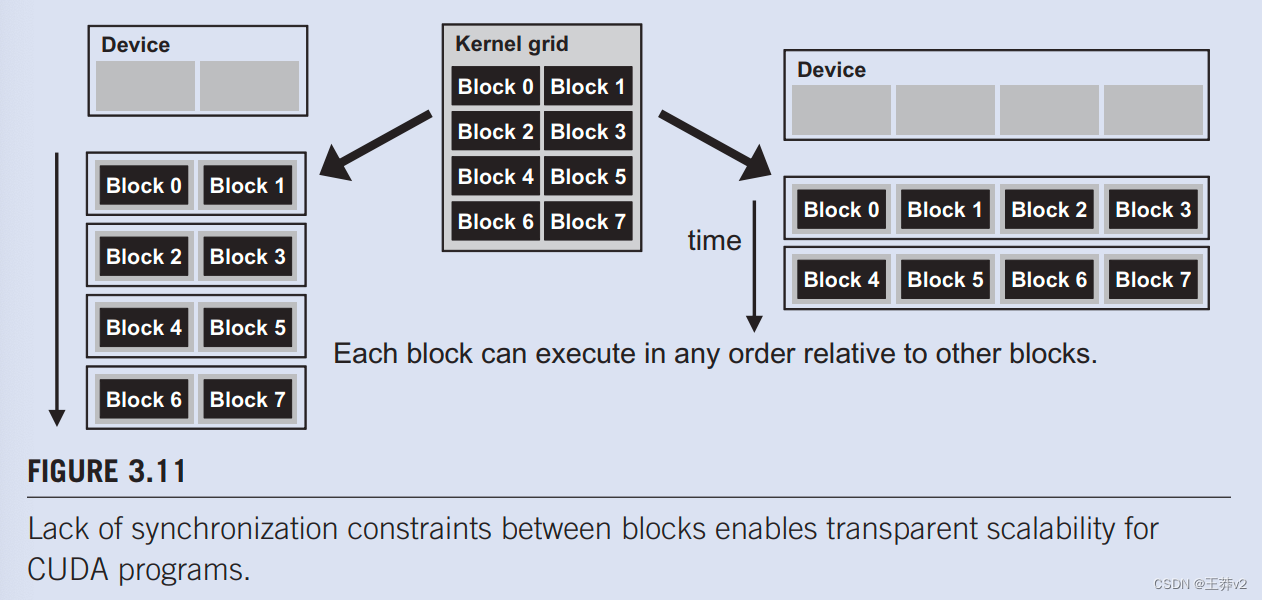
能够在广泛的速度范围内执行相同的应用程序代码,允许根据特定细分市场的成本、功率和pertormance要求生产广泛的实现。例如,移动处理器可能会以极低的功耗缓慢执行应用程序,而桌面处理器可能会以更高的速度但更高的功耗执行相同的应用程序。两者都执行完全相同的应用程序,不更改代码。在具有不同执行资源数量的硬件上执行相同应用程序代码的能力被称为透明可扩展性。这一特点减轻了应用程序开发人员的负担,并提高了应用程序的可用性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!