Python 利用pandas对数据进行特定排序
背景
小编最近在处理hive表存储大小时,需要对每个表的大小进行排序,因通过 hadoop fs -du -s -h /path/table 命令获取的数据表大小,其结果是展示为人能直观理解的大小,例如 1.1T、1.9G、49.6M 等,如果想对这些表根据存储大小进行降序排列,利用pandas应该如何做呢?
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
import pandas as pd
print(pd.__version__)
#2.1.0
测试数据
这里仅列举10行数据,进行演示,小编真实的hive表有几万个
函数概述
在pandas对数据进行排序主要使用 pandas.DataFrame.sort_values 方法
DataFrame.sort_values(by, *,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last',
ignore_index=False,
key=None)
参数解释:
-
by :str or list of str
用于排序的单个字段 或 多个字段组成的列表 -
axis:“{0 or ‘index’, 1 or ‘columns’}”, default 0
排序时的轴向,0 表示行向排序(一行一行排序),1表示列向排序(一列一列排序),默认是 0,也就是Excel中经常使用的排序 -
ascending:bool or list of bool, default True
升序、降序,默认是升序,也就是True,如果是False,则是降序
注意:该参数需要和 上面的by参数要相对应 -
inplace:bool, default False
是否原地更新排序的数据,默认是False,表示调用该方法后,会返回一个新的数据框 -
kind:{‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’}, default ‘quicksort’
进行排序时,指定的排序算法,默认是quicksort,快速排序算法 -
na_position:{‘first’, ‘last’}, default ‘last’
在排序的数据中,指定NaN的排序位置,默认是排在最后 -
ignore_index:bool, default False
是否要忽略数据的索引,默认是 Fasle,不忽略,使用数据原本的索引 -
key:callable, optional
排序之前使用的函数,该函数需要是矢量化的,也就是传入参数是Series,返回的结果也需要为Series,该函数会逐个用在被排序的字段上

官方文档:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html
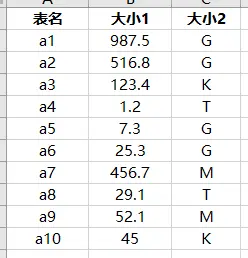
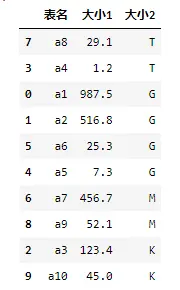
完整案例
import pandas as pd
data=pd.read_excel('排序数据.xlsx',sheet_name='排序')
key_type={'T':1,'G':2,'M':3,'K':4}
data.sort_values(by=['大小2','大小1'],
ascending=[True,False],
key=lambda col: col.map(key_type) if col.name=='大小2' else col
)
历史相关文章
- Python pandas 2.0 初探
- Python pandas.str.replace 不起作用
- Python数据处理中 pd.concat 与 pd.merge 区别
- 对比Excel,利用pandas进行数据分析各种用法
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- R3 下屏蔽 Windows 睡眠:拦截 Winlogon 调用(二)
- linux RCU 使用实例
- 什么是迁移学习(Transfer Learning)?定义,优势,方法
- LeetCode刷题--- 最大子数组和
- 多维表格产品vika多维表、Flowus、Wolai体验记录
- python爬虫实战入门总结及反反爬虫的补充
- 数据结构之单调栈、单调队列
- 深入Python Loguru:优雅的日志记录与分析
- 【扩散模型】9、Imagen | 借用语言模型的能力来实现文生图(NIPS2022 Oral)
- 【XR806开发板试用】单总线协议驱动DHT11温湿度传感器