霍夫曼编码简介
本专栏目录:全球SAR卫星大盘点与回波数据处理专栏目录
算法科普:有趣的霍夫曼编码
前言
霍夫曼编码 ( Huffman coding ) 是一种可变长的前缀码。霍夫曼编码使用的算法是 David A. Huffman 还是在 MIT 的学生时提出的,并且在 1952 年发表了名为《 A Method for the Construction of Minimum-Redundancy Codes 》的文章。
编码这种编码的过程叫做霍夫曼编码,它是一种普遍的熵编码技术,包括用于无损数据压缩领域。
霍夫曼编码过程
霍夫曼编码使用一种特别的方法为信号源中的每个符号设定二进制码。出现频率更大的符号将获得更短的比特,出现频率更小的符号将被分配更长的比特,以此来提高数据压缩率,提高传输效率。
以字符串 ” ABAABACD “ 为例进行说明。
首先,按照字符出现的比例,从高往低对字符进行排序。

然后,按出现比例低的顺序查找两个字母。在这种情况下,它是 “ C ” 12.5% 和 “ D ” 12.5% 。
通过一条线连接两个字母拼构成一个树状结果。将两个字母合并为 “ C 或 D”,并将出现比率相加起来。

按照同样的操作,将合并后的 “ C 或 D ” 视为一个字符,重复相同的操作。
在 “ A " “B” " C 或 D " 三个中,按照出现比例低的顺序查找两个字母。
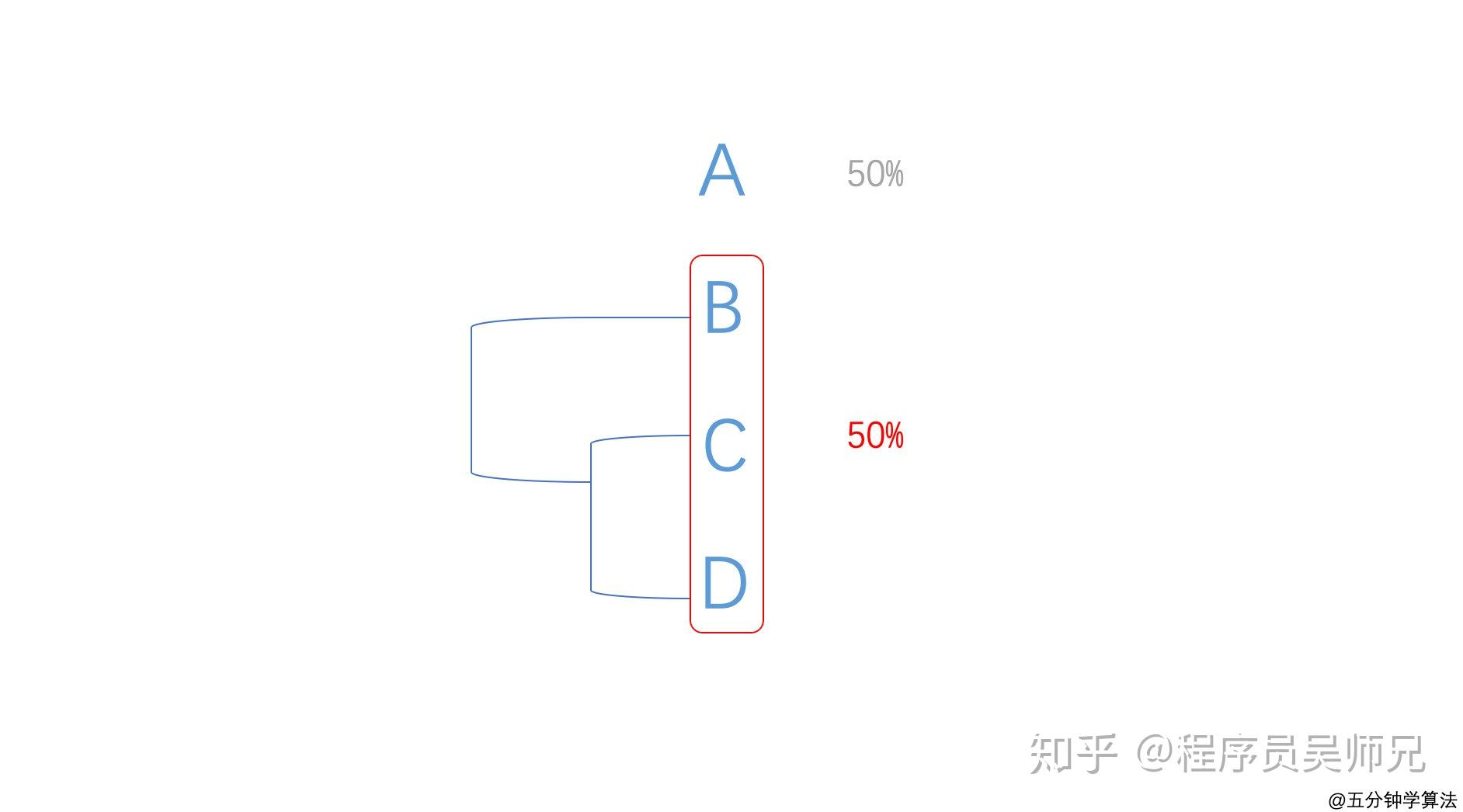
这样,所有的字母都变成了" A 或 B 或 C 或 D" ,出现的比率为 100% 。
图 4 就是霍夫曼编码的树结构。
接下来再次显示各个字母出现的比率,同时使用 0 和 1 进行编码,代码 0 和 1 分别分配给上下延伸的分支。
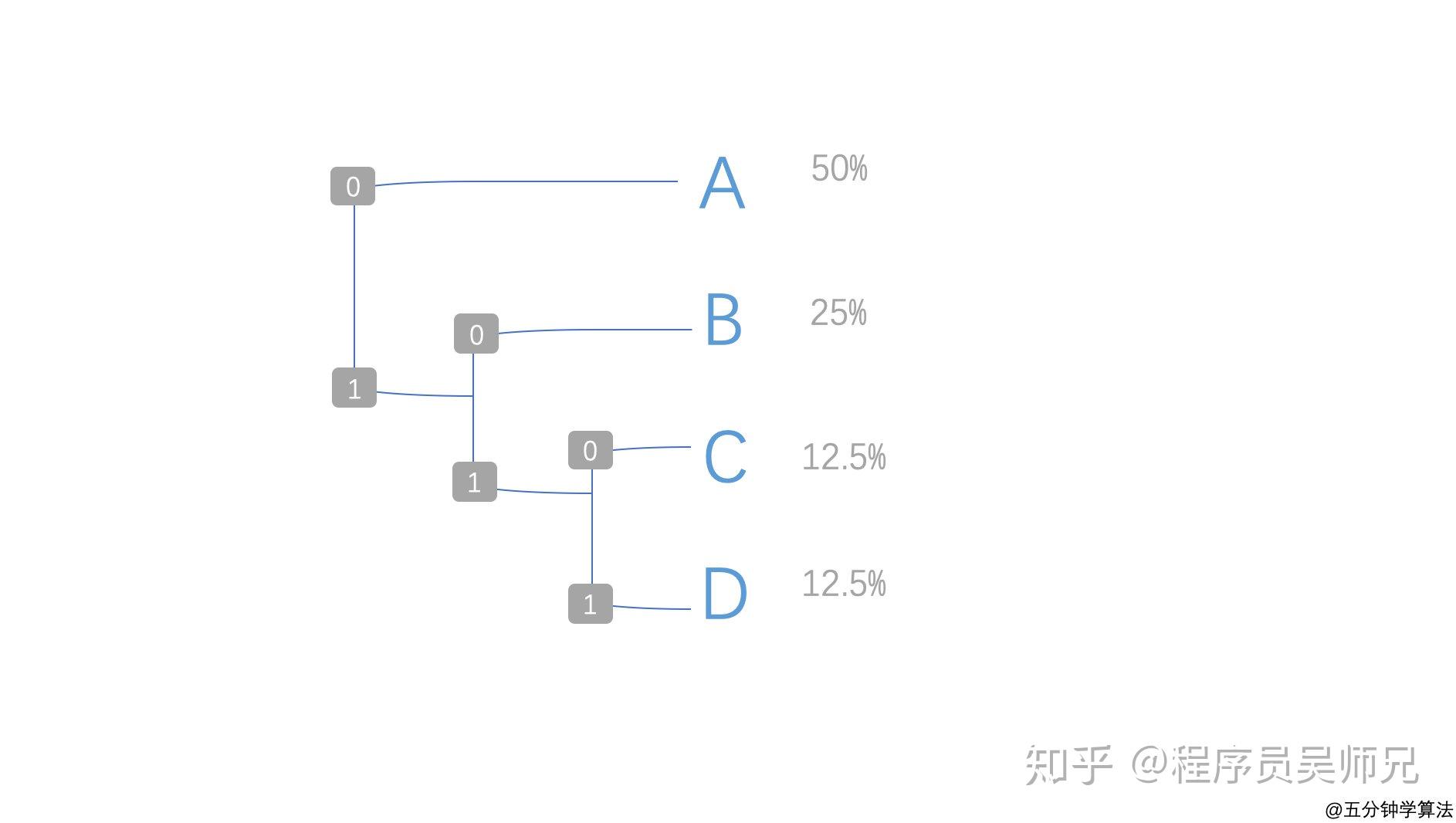
分配完毕后,从树的根部遍历每个字符并确定相应的代码。
- 在 ” A “ 的情况下,被分配的代码为 ” 0 “
- 在 ” B “ 的情况下,被分配的代码为 ” 10 “
- 在 ” C “ 的情况下,被分配的代码为 ” 110 “
- 在 ” D “ 的情况下,被分配的代码为 ” 111 “

就这样,通过这样的编码规则, ” ABAABACD “ 的二进制编码就变成了 ” 01000100110111 “,只需要 14 个比特就能表示,比单纯的使用 2 比特表示一个字符缩短了很多。
转载自:https://zhuanlan.zhihu.com/p/63362804
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!