BMTrain来高效训练预训练模型-大模型的福音
一.背景知识
在2018年,预训练语言模型技术的出现成为人工智能领域一场革命性的变革。研究表明,通过增加模型参数量和训练数据规模,可以有效提升语言模型的性能,因此十亿、百亿甚至千亿级大模型的探索成为业界的热门话题。这一趋势引起了国内外研究机构与互联网企业之间激烈的竞争,推动着模型规模与性能不断突破新的高度。除了像Google、OpenAI等国际知名机构之外,近年来国内相关的研究机构和公司也迅速崛起,形成了大模型的研究与应用热潮,将人工智能带入了所谓的“大模型时代”。
在这个新时代中,大模型的崛起不仅仅改变了人工智能的发展路径,也在全球范围内掀起了技术创新和应用实践的热潮。国际间涌现出了一系列具有重要影响力的预训练语言模型,如BERT和GPT系列,它们在自然语言处理任务上表现出色。在国内,一些研究机构和企业积极响应,投入大量资源进行模型研发,取得了显著的成果。
这种激烈的竞争和不断扩展的模型规模使得人工智能的发展进入一个更为挑战和创新的时代。大模型不仅在语言理解、生成等自然语言处理领域取得了重大突破,还为计算机视觉、语音识别等其他领域的发展奠定了基础。然而,随之而来的挑战也不可忽视,如对计算资源的巨大需求、模型的可解释性问题等,都需要研究者和企业共同努力解决。
总体而言,这个“大模型时代”为人工智能的发展注入了强劲动力,同时也提出了一系列新问题需要我们深入思考和解决。如何平衡模型性能和可解释性,如何更有效地利用大规模数据和计算资源,将是人工智能领域未来面临的重要议题。
二.BMTrain
下面是清华大学提供的BMTrain的流程图
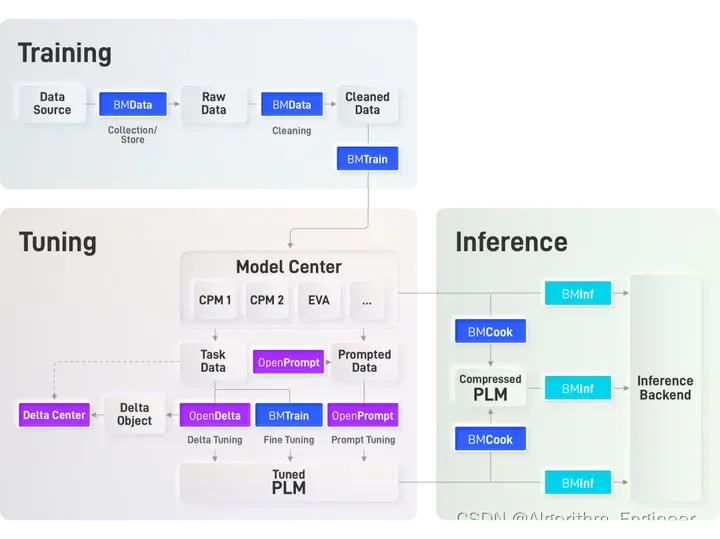
在 OpenBMB 全流程加速工具框架中,BMTrain作为解决大模型训练难题的重要组成部分,其设计追求以下特点:
高效性(Efficiency): BMTrain致力于提高大模型训练的效率,通过优化算法和并行计算,以最小的时间完成模型训练任务。
可扩展性(Scalability): BMTrain被设计为具有良好的可扩展性,能够有效地适应不同规模和复杂度的模型训练。无论是小规模研究任务还是大规模产业应用,都能够灵活运用。
灵活性(Flexibility): BMTrain提供灵活的配置选项和参数调整,以满足不同场景下的需求。用户可以根据实际情况进行定制,以获得最佳的性能和效果。
分布式训练支持(Distributed Training): 为了应对大规模模型和大量数据的训练需求,BMTrain支持分布式训练,充分利用集群计算资源,提高训练速度和吞吐量。
硬件加速(Hardware Acceleration): BMTrain在设计上充分考虑硬件加速的利用,兼容多种硬件平台,例如GPU、TPU等,以提升训练速度。
模型压缩与量化(Model Compression and Quantization): 为了在硬件资源有限的情况下实现高效的训练,BMTrain支持模型压缩和量化技术,降低模型的存储和计算成本。
监控与调试(Monitoring and Debugging): BMTrain提供丰富的监控和调试工具,帮助用户实时监测训练过程中的性能、资源利用等关键指标,方便问题的排查和优化。
自动化(Automation): BMTrain设计注重自动化,通过智能的任务调度和资源管理,减轻用户的操作负担,提高训练任务的顺利进行。
同时,利用BMTrain构建了一系列大规模预训练语言模型,并将其集成到ModelCenter仓库中。这个整合了BMTrain与ModelCenter的系统构建了一个高效的分布式预训练框架,特别适用于任意Transformer结构。这一框架的独特之处在于,它能够在相对较少数量的GPU上进行训练,同时与PyTorch和Transformers库高度兼容,使得使用者几乎可以零成本学习和应用。目前表明已经在该框架下支持了多个常用的英文模型,如BERT、GPT、T5、RoBERTa等,以及中文模型,如CPM-1、CPM-2等。
这一整套框架的设计目标是提供一个强大而灵活的工具,使研究者和开发者能够在大规模预训练任务中取得更高的效率和性能。通过BMTrain的支持,能够在分布式环境中训练复杂的Transformer结构,使得这些模型能够更好地理解和处理自然语言的复杂性。在ModelCenter的仓库中,持续地更新并添加各种预训练模型,以满足不同任务和场景的需求。这包括了涵盖英文和中文的多语种模型,使得用户能够灵活选择和应用适合自己需求的模型。总体而言,通过BMTrain与ModelCenter的结合,提供了一个完整而高效的工具链,使得大规模预训练语言模型的研究和应用变得更加便捷和可行。同时,将继续推动框架的发展,以满足不断增长的需求和挑战。
参考连接
1.https://github.com/OpenBMB/BMTrain
2.https://github.com/OpenBMB/ModelCenter
贴合PyTorch使用习惯,上手门槛更低,仅需简单替换即可完成训练提速:
bmtrain.DistributedParameter替换torch.nn.Parameter
bmtrain.DistributedModule替换torch.nn.Module
bmtrain.CheckpointBlock替换torch.nn.ModuleList中的模块
三.效果拔群
BMTrain在大模型训练上效果出色,在不同规模的算力条件下均有较好的性能表现。
消费级算力(单卡2080Ti)
在消费级显卡2080Ti上,BMTrain可以实现BERT-Large的微调(3亿参数,样本长度 512)。
入门级算力(单卡V100)
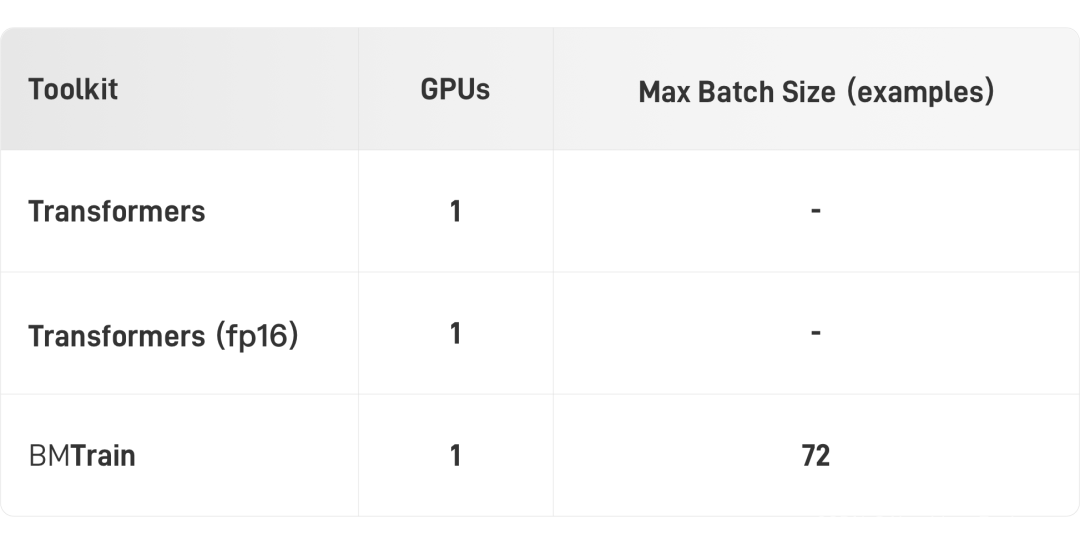
在入门级算力条件下(显卡为V100 32GB),BMTrain可以实现BERT-Large的高效训练(3亿参数,样本长度 512)。
中等算力(单机8卡A100)
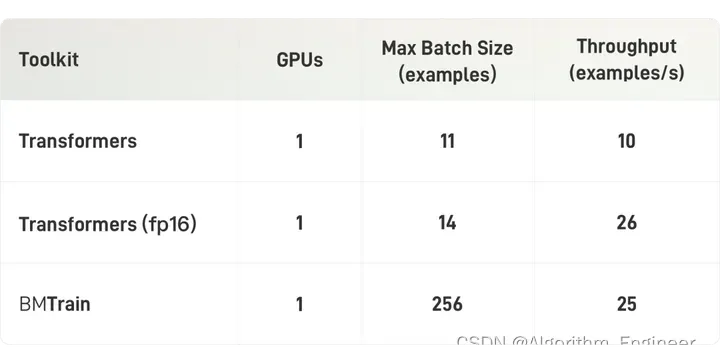
在中等规模算力条件下(显卡为A100 40GB,NVLink),BMTrain可以训练大规模的 GPT-13B (130亿参数,样本长度 512)。
高级算力(多机8卡A100)
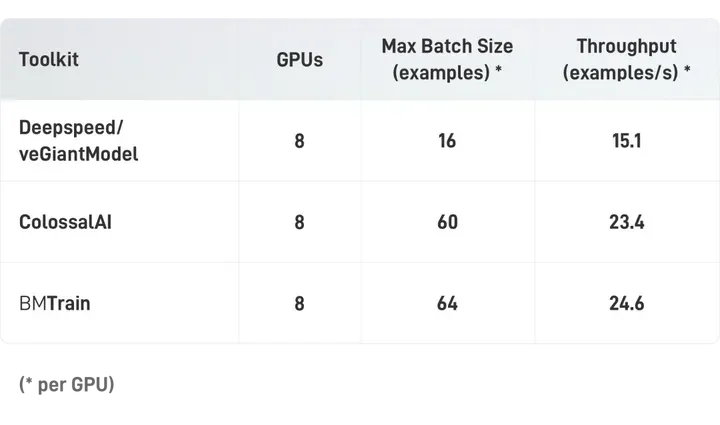
在较高规模算力条件下(显卡为A100 40GB,NVLink,400Gbps IB),BMTrain可以训练超大规模的 GPT-3(1750亿参数)。
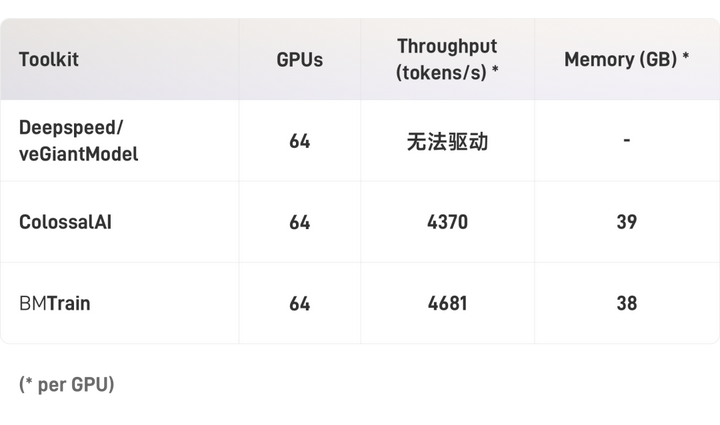
使用BMTrain或者ColossalAI,64卡A100跑完GPT-3的300B token大概需要2年,服务器与显卡租金大约900万左右。根据实验估算,使用128张A100时,单卡吞吐量可以提升2.5倍以上,6个月可以跑完GPT-3,服务器租金大约500万左右。虽然训练出GPT-3的成本依然高昂,但与GPT-3的1200万美元相比,成本仍然节约了90%以上。
四.上手教程
可以参考上述的github连接
BMTrain 和 ModelCenter 提供了丰富的文档,方便使用者快速上手,便捷地体验大模型的魅力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Sensor Demosaic IP 手册PG286笔记
- [LCTF 2018]bestphp‘s revenge
- 发包,对nginx的操作
- 【ARMv8M Cortex-M33 系列 7.2 -- HardFault 问题定位 1】
- Mockjs 增、删、改、查(分页、多条件查询)
- 不是 ES 用不起,而是 ClickHouse 更具“性价比”?
- 米贸搜|Facebook广告投放业务谁在做?
- 每日一练 | 华为认证真题练习Day153
- 标签正则化和硬标签、软标签、单标签、多标签
- Educational Codeforces Round 160 (Rated for Div. 2) A~C