Linux汇编语言编程-机器语言
机器语言是处理器看到的语言。 在获取-执行周期【fetch-execute cycle?】中获取的字节是机器码的字节。汇编语言可以定义为一种使程序员能够控制机器码的语言。汇编语言指定机器码。如果不熟悉机器语言,汇编语言的这一特性是不明显的。本章介绍 x86 机器码的主要特征。
将汇编代码转换为机器码的过程称为汇编【assembling】。 以汇编语言作为输入,并产生机器语言作为输出的程序称为汇编程序【assembler】。 它类似于编译器,但它在较低级别上运行。
相反,将机器码转换为汇编语言的过程称为反汇编【unassembling】。 执行此操作的程序称为反汇编程序【unassembler】。
Assembling Simple Programs
要讲述 x86 处理器机器码的整个故事,涉及到许多棘手的细节。 然而,在第 4.3 节到第 4.5 节中使用的所有编号的程序中,为 x86 汇编语言的子集指定机器码是很容易的。 表 5.1 给出了这部分 x86 汇编语言的编码【Coding】。 大多数机器码以十六进制给出,但某些字节必须以二进制给出。 字节数从 1 到 6 不等。 例如,表的第一行显示的??MOV reg,reg? 的代码是一个双字节代码【two-byte code】,其中第一个以十六进制给出,第二个以二进制给出。 以二进制给出的字节是包含寄存器代码【?register codes 】的字节。 S S S 在二进制编码中表示源寄存器的三位代码。 D D D 表示目标寄存器的三位代码。 寄存器代码【register codes】在下面有给出。 命令中出现的每个“imm” 会指定四个附加字节,这些字节必须由程序员提供。 示例如下。 根据表 5.1,程序 5.1 可以按如下方式进行机器码汇编/机器码组装【machine assembled】:
Table?5.1.?Some 32-Bit Machine Coding
| First Byte | Second Byte | 4 More | ||
|---|---|---|---|---|
MOV | reg, reg | 89 | 1 1 S S S D D D | |
MOV | reg, imm | 1 0 1 1 1 D D D | ___ | |
ADD | reg, reg | 01 | 1 1 S S S D D D | |
ADD | reg, imm | 81 | 1 1 0 0 0 D D D[1] | ___ |
SUB | reg, reg | 29 | 1 1 S S S D D D | |
SUB | reg, imm | 81 | 1 1 1 0 1 D D D[1] | ___ |
INC | reg | 0 1 0 0 0 D D D | ||
DEC | reg | 0 1 0 0 1 D D D | ||
IN | EAX, [DX] | ED | ||
OUT | [DX], EAX | EF | ||
RET | C3 | |||
JMP | imm | E9 | ___ | |
JZ | imm | 0F | 84 | ___ |
JNZ | imm | 0F | 85 | ___ |
JS | imm | 0F | 88 | ___ |
JNS | imm | 0F | 89 | ___ |
| 3-Bit Register Codes | |||
|---|---|---|---|
| EAX | 000 | ESP | 100 |
| ECX | 001 | EBP | 101 |
| EDX | 010 | ESI | 110 |
| EBX | 011 | EDI | 111 |
Register Codes
第一个命令的第一个字节,即 BA ,使用 MOV reg,imm? 给出的 1011 1DDD 代码【code】进行编码【encoded】。 DDD 占位用 EDX 的寄存器代码 010 填充,其结果是二进制代码 1011 1010 或十六进制代码 BA。
第二个?MOV?命令,即?MOV ECX,EAX?被编码为89 C1,它是使用图表中的?MOV reg,reg?进行的编码,其中第二个字节按照规范被指定为?11 SSS DDD。,而EAX 是源寄存器,其代码为 000。ECX 是目标寄存器,其代码为 001,结果第二个字节为 11 000 001,即 C1。
Example?5.1.?
Label Source Code Address Machine Code
MOV EDX, 0 0 BA 00
2 00 00
4 00
IN EAX, [DX] 5 ED
MOV ECX, EAX 6 89 C1
IN EAX, [DX] 8 ED
MOV EDX, EAX 9 89 C2
ORD SUB EAX, ECX B 29 C8
JZ GCD D 0F 84
F 11 00
11 00 00
JNS NXT 13 0F 89
15 04 00
17 00 00
MOV EAX, ECX 19 89 C8
MOV ECX, EDX 1B 89 D1
NXT MOV EDX, EAX 1D 89 C2
JMP ORD 1F E9 E7
21 FF FF
23 FF
GCD MOV EAX, EDX 24 89 D0
MOV EDX, 1 26 BA 01
28 00 00
2A 00
OUT [DX], EAX 2B EF
RET 2C C3Little Endian Immediate Codes
该程序中的第一个和最后一个 MOV 命令都包含立即值【immediate values】。 它们都将四字节值存储在四字节寄存器中。 请注意,在最后一个 MOV 命令中,四字节立即值 00000001H 存储为 01 00 00 00。
Relative Jumps
在可行的情况下,x86 处理器使用的跳转编码使用相对地址而不是绝对地址。 该程序中的所有跳转指令都将跳转编码【encode】为相对跳转。 绝对跳转【absolute jump】将指定一个实际地址【actual address】作为跳转目标,而相对编码【relative encoding】则指定从下一条指令的开头开始要跳转的字节数。 该值可以被解释为一个有符号的数字,对于向后跳转来说是一个负值。 处理器【processor】将编码值【encoded value】与下一条指令的地址相加,以获得要跳转到的指令的地址。 例如,?JMP NXT?指令有一个小端编码 4; 从 ?MOV EAX, ECX?开始的字节 89 算起 4 个字节,就到了 ?MOV EDX, EAX?开始的字节 89 。 该命令是 JMP NXT 的目标。 ?JMP ORD? 指令包含相对跳转值 FFFFFFE7H = ?25。 从 ?MOV EAX, EDX?开始的字节 89 开始向后数 25 个字节,得到字节 29 ,即 ?SUB EAX,ECX?代码的第一个字节。
Short Jumps
尽管值 17、4 和 -25 很容易适合一字节有符号范围,但程序中的相对跳转值均以四个字节进行编码。 有一些替代编码可用于节省单字节跳转的空间。 这些跳跃称为短跳【short jumps】。 例如,?JNS NXT? 指令的短跳【short jump】编码为 79 04。条件短跳【conditional short jumps】的机器码可以通过去掉字节?OF 并从第二个字节中减去 10H 获得。 ?JMP? 命令的短代码是 EB。 在 Edlinas 中,可以使用 s 键将长跳【long jump】转换为短跳【short jump】。 在 NASM 中,朴素的 JMP??指令总是意味着短跳转【short jump】。 无法以单字节编码的 ?JMP 指令会收到错误消息。 要指定使用较长编码的跳转,请使用 JMP NEAR?。 在当前上下文中,“远【far】”跳转似乎比“短【near】”跳转更有意义,但远跳实际上指的是使用绝对编码【absolute encoding】的跳转,如第 12 章所示。
由于大多数跳转不超过 128 字节,因此为它们使用特殊编码是有意义的。 8086 的指令集实际上只有条件跳转的简短版本。 标识长跳的码 OF 直到 80386 才出现。
Opcode Space
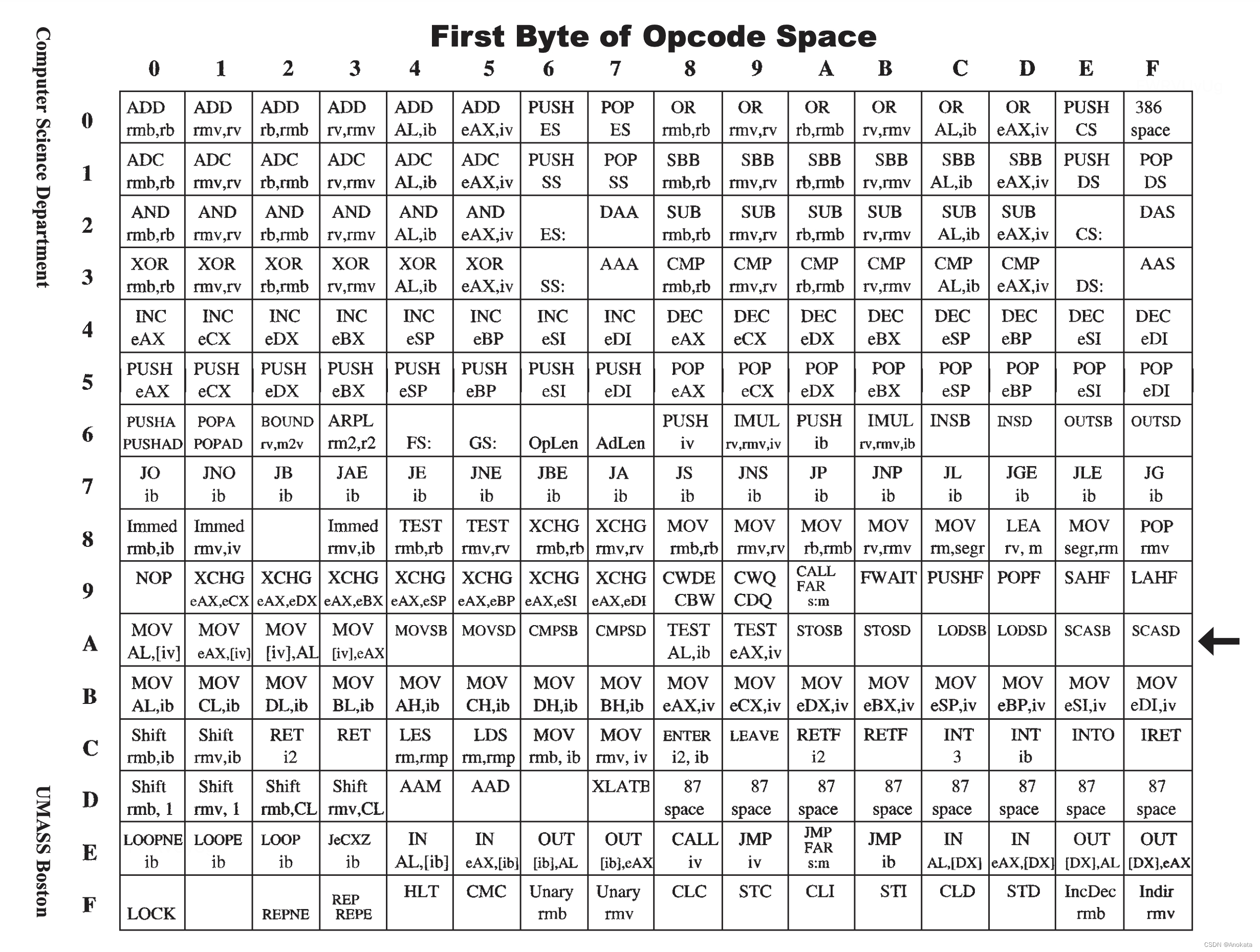
上一节中给出的机器码可用于汇编【assemble】各种简单的程序。 另一方面,总的来说,它们仅代表完整 x86 指令集的一小部分。 在本节中,概述了整个?x86 机器码集。 表 5.2 显示了机器码的第一个字节传达的信息。
表中的大多数条目都包含助记符【mnemonic】和操作数【operand】信息。 在少数情况下,此信息完整地指定出了两者。 例如,表中字节 EE 对应的条目:
OUT
[DX],AL在其他情况下,明确给出助记符,但使用字母的键【keys】来描述一类【class】允许的操作数。
- r 代表寄存器
- m 代表内存【memory】
- i 代表立即数
- b 代表字节【byte】
- 2 代表 2 字节
- v 表示 32 位或 16 位
- e在 32 位中表示 E ,在 16 位中消失
Stephen Morse 在其优秀著作 80386/387 Architecture 中使用了这些键【keys】。
考虑表中字节 03 处的条目:
ADD
rv,rmv由于第一个操作数的位置包含 rv,这表明第一个操作数必须是 16 位或 32 位寄存器。 由于第二个操作数位置包含 rmv,因此第二个操作数必须是 16 位或 32 位的寄存器或内存操作数。 由于 ?EDI? 和 EAX 是 32 位寄存器,我们看到?ADD EDI,EAX?是一个可以用第一个字节为 03 的代码【code】进行编码【encoded】的指令示例。另一个例子是 ADD EDI,[1234H]?。 由代码的第一个字节所传达的信息类型可以分为几种情况:
-
在少数情况下,这个单字节足以完整地指定一条指令。 例如,F4 指定暂停指令: HLT。
-
在许多其他情况下,虽然第一个字节足以确定要执行哪个操作,但它并不指定操作数。 在这些情况下,第二个字节通常足以承载操作数信息。 第二个字节称为 ModRM 字节。 例如,如果第一个字节是 89,则表中对应的条目是 ?
MOV rmv,rv??。 除了指定操作 MOV?之外,rmv、rv 这两个关于操作数的键【keys】还传达有关如何解释 ModRM 字节的信息。 -
也有一些情况,第一字节并不完全指定一个操作,而只是一个通用类型的操作,ModRM 字节用于完成操作的指定并携带操作数信息。 例如,如果第一个字节是 C1,则表中对应的条目是
Shift rmv,ib。 在这些情况下,ModRM 字节的完整解释需要移至表 5.3。 Shift 并不是助记符。 它只是表 5.3 的一个指针。 我们在表中通过字母是否全部大写来表明这一点。 -
如果第一个字节是 OF,那么就有了很多可能性。 OF 传达的信息参见表 5.4。
-
如果第一个字节在 D8-DF 范围内,则该命令是浮点命令。 本文不涉及这些命令。
-
还有一些前缀字节【prefix bytes】用于修改后续命令【subsequent commands】。在表 5.2 中,前缀字节(例如 LOCK 前缀 F0)显示为底部看护【bottom-sitters】。
以下各节将一一处理这些不同的情况。
Table?5.2.?First Byte of Opcode Space
The ModRM Byte
当第一个字节不能携带操作数信息时,ModRM 字节用于携带操作数信息。 ModRM 字节由三部分组成。
| Mod | R | M | |||||
|---|---|---|---|---|---|---|---|
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
-
位 7 和 6 是 Mod 位。 当 Mod 位为 11 时,M 部分的位指定寄存器。 否则,M 部分的位用于内存编码。
-
位 5、4 和 3 是 R(或寄存器【register】)位,通常使用斜杠符号 /r 来指定。
-
位 2、1 和 0 是 M(或内存【memory】)位,用于指定或帮助指定内存位置(Mod 位为 11 时除外)。
rv,rmv Coding
表 5-1 中字节 03 处的条目为:
ADD
rv,rmv我们可以使用这个条目来组装?ADD EDI,EAX?命令。 ?ADD EDI,EAX? 命令需要 ModRM 字节。 第二个操作数位置中的 m 不仅指定第二个操作数可以是内存操作数【memory operand】,而且还指定它必须被编码在 ModRM 字节的 M 位中。 由于第二个操作数是寄存器?EAX,因此?EAX 的位代码 000 占据 ModRM 字节中的 M 位。 由于我们对?M 部分的位【bits】使用的是寄存器,因此这两个 Mod 位必须为 11。第一个操作数(由?r 所示它必然是寄存器)因此被编码在 ModRM 字节的 R 位中。 EDI 是第一个操作数,其代码为 111。因此 ModRM 字节为:
| Mod | R | M | |||||
|---|---|---|---|---|---|---|---|
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
1111 1000 = F8H
将 03 与 ModRM 字节组合生成 ?ADD EDI,EAX?的代码 03 F8。
如果在此代码中我们将两个 Mod 位从 11 更改为 00,我们将会得到 ?ADD EDI,[EAX]?的代码。 这里 M 位用于实际的内存操作数【memory operand】(译注:EAX 寄存器里的值,存储的是内存地址,[] 在这里是一个解引用,类似于C语言里的 * )。 代码 01 和 10 用于编码立即数位移【immediate displacements】,例如 ?ADD EDI,[EAX + 5],其中位移【displacement】分别为 ib 或 iv 类型。 因此,?ADD EDI,[EAX + 5]?的代码是03 78 05(Mod 位用的是 01)。?ADD EDI,[EAX + 87654321H]?的代码是03 B8 21 43 65 87(Mod 位用的是 10)。但是,如果统一执行此编码,则在编码空间中就没有在第 6 章第 6.2.3 节中将会看到的复杂格式的空间了。为了腾出空间对这些格式进行编码,ESP 寄存器的代码被删除了,以提供转义到编码空间的另一个字节(称为 SIB 字节)中。
rmv.rv Coding
当 ?rmv?和?rv?键颠倒时,三位代码【three-bit codes】就会发生颠倒。 举个例子,假设我们要汇编指令 ?MOV EDI, EAX。表中字节 8B 的条目匹配并且可以使用与?ADD EDI, EAX? 代码相同的 ModRM 字节进行编码。 但表中的字节 89 的条目也匹配:
MOV
rmv,rv使用该条目,我们注意到第一个操作数可以是寄存器并且被编码在 M 位中。 因此,EDI 代码进入最低有效位。 第二个操作数 EAX 编码在 R 位中。
| Mod | R | M | |||||
|---|---|---|---|---|---|---|---|
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
1100 0111 = C7H
因此,使用表 5.2 中的字节?89 的条目,我们获得 ?MOV EDI,EAX?的编码为?89 C7。?
Nonregister R Bits
在某些情况下,第一个字节不足以指定操作,但 ModRM 字节的 R 位用于完成指定。 表 5.3 列出了这些情况。 SUB ECX, 32? 就是一个例子。 表 5.2 中字节 83 的条目是:
Immed
rmv,ib由于表 5.3 中标记为“Immed”的行在 /r = /5 下有一个 ?SUB?,我们了解到指令匹配如下编码:
SUB
rmv,ib可以使用 83 作为第一个字节并使用 101 (即 5,前面讲过,首字节只使用83,不足以完全指定操作,需要 R 位来协助)作为 ModRM 字节的 R 位进行编码。 由于第一个操作数 ECX 不是内存,因此 Mod 位必须为 11,M 位将填充 ECX 的代码 001。 所以所需的 ModRM 字节是:
Table?5.3.?Instructions Specified by R Bits
| /r | /0 000 | /1 001 | /2 010 | /3 011 | /4 100 | /5 101 | /6 110 | /7 111 |
| Immed | ADD | OR | ADC | SBB | AND | SUB | XOR | CMP |
| Shift | ROL | ROR | RCL | RCR | SHL | SHR | SAR | |
| Unary | TEST i | NOT | NEG | MUL | IMUL | DIV | IDIV | |
| IncDec | INC | DEC | ||||||
| Indir | INC | DEC | CALL m | CALL FAR m | JMP | JMP FAR | PUSH |
?
| Mod | R | M | |||||
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1110 1001 = E9H | |||||||
ib 代表立即字节。 因此 ?SUB ECX.32? 的代码是 83 E9 20。?
386 Space (OF + …)
在 8086 上,字节 OF 编码为指令?POP CS。 但在后续处理器上,该指令被删除,以使 OF 代码可用于指令集中的显著扩展。 表 5.4 显示了被开辟的空间。 与表 5.2 一样,它显示了由单个字节传达的信息,在本例中为初始 OF 字节后面的字节。 表 5.4 中的一些指令首先出现在 80286、80486 或 Pentium 上,但大多数指令首先出现在 80386 上。80286 的大部分新指令都在表 5.2 中。
- 与表 5.2 一样,有时一个条目恰好指定一条指令。 例如,OF CA 是?
BSWAP EDX?指令的代码(Byte SWAP EDX 寄存器)。 - 有时需要 ModRM 字节来传送操作数信息。 前两个字节为 OF C1 的 ?
XADD指令就是一个例子。 - 有时,ModRM 字节用于指定操作。 例如,如果指令的前两个字节是OF 01,那么我们必须检查 ModRM 字节的 R 位来确定操作。 从表 5.5 中我们可以看出,如果 ModRM 字节中的寄存器位为 011,则该指令将是 ?
LIDT指令(加载中断描述符表)。
在8086计算机上,用于指令POP CS的字节码。在后续的处理器上,该指令被删除,以使OF代码可用于指令集中的显著扩展。表5.4显示了被打开的空间。与表5.2一样,它显示了单个字节所传递的信息,在本例中是初始OF字节后面的字节。表5.4中的一些指令首先出现在80286、80486或Pentium上,但大多数指令首先出现在80386上。80286的大部分新指令在表5.2中。
与表5.2一样,有时一个表项只指定一条指令。例如,OF CA是指令BSWAP EDX(字节交换EDX寄存器)的代码。
有时需要一个ModRM字节来传递操作数信息。前两个字节是C1的XADD指令就是一个例子。
Table?5.4.?386 Space
Table?5.5.?0F Instructions Specified by R Bits
| /r | /0 000 | /1 001 | /2 010 | /3 011 | /4 100 | /5 101 | /6 110 | /7 111 |
|---|---|---|---|---|---|---|---|---|
| LocalT | SLDT?rm2 | STR?rm2 | LLDT?rm2 | LTR?rm2 | VERR?rm2 | VERW?rm2 | ||
| GlobalT | SGDT?m6 | SIDT?m6 | LGDT?m6 | LIDT?m6 | SMWS?rm2 | LMSW?rm2 | ||
| Bits | BT?rmv,ib | BTS?rmv,ib | BTR?rmv,ib | BTC?rmv,ib |
注:一些代码引用了MMX指令。 这些指令在 Intel 书籍《MMX 技术完整指南》中进行了讨论。?
我们了解到与表 5.5 匹配的指令包含 80486、Pentium 和 MMX 指令以及 80386 指令。 例如,?XADD?和?BSWAP?指令首先出现在 80486 上,?CPUID?和?RDTSC?首先出现在 Pentium 上。
32-Bit vs. 16-Bit Code
至此,我们已经讨论了仅涉及 32 位通用寄存器的命令的机器代码。 现在我们准备考虑 16 位通用寄存器的编码。
?MOV ECX,EAX??命令,如第 5.1 节所述,可以编码为 89 C1。 对应的16位命令是?MOV CX,AX。 令人惊讶的是,这个命令的代码也是 89 C1! 80386 设计为对 16 位寄存器使用与 32 位寄存器相同的编码。 显然这有问题。 当处理器【processor】获取字节 89 C1 时,应执行哪条指令,MOV ECX,EAX? 还是 ?MOV CX,AX?? 碰巧的是,这个决定是基于处理器中的单个比特/位。 该位决定代码是否被解释为 32 位代码(在这种情况下 89 C1 表示 MOV ECX,EAX? )或 16 位代码(在这种情况下 89 C1 表示 ?MOV CX,AX?)。
当该位被设置时,并不意味着指令 ?MOV CX,AX? 不可用。 为了对 32 位编码假设错误的事实进行编码,使用了一个单字节前缀: 66。 因此,在 32 位代码中 66 89 C1 是 ?MOV CX,AX? 的代码。同样,?MOV ECX,EAX? 指令在 16 位代码中可用,它的代码是 66 89 C1,?这个前缀被称为操作数大小前缀【?operand size prefix】。 这意味着操作数大小不是默认大小。
通常,该位在运行 Linux 时设置,并在运行 DOS 时清除。 除非另有特别说明,本书中给出的代码假定处理器的位设置为 32 位默认值。 因此,89 C1 表示 ?MOV ECX,EAX?,66 89 C1 表示 ?MOV CX,AX?。?
Table?5.6.?32- vs. 16-Bit Coding Example
| 32-Bit Code | 16-Bit Code | |
|---|---|---|
MOV ECX, EAX | 89 C1 | 66 89 Cl |
MOV CX, AX | 66 89 C1 | 89 C1 |
现在我们看到代码 89 C1 如何具有两种可能的含义之一,解释其中的 v 就很容易了:?
MOV
rmv,rv?
每个操作数标记中的 v 代表变量,其中变量指的是大小可以是 16 位或 32 位。 类似地,寄存器名称(例如 eAX)中的 e 表示在 32 位编码中预期为 EAX,而在 16 位编码中则预期为 AX。
The 8-Bit Registers
尽管 32 位和 16 位寄存器命令被迫共享操作码,但 8 位寄存器通常具有专用操作码。 例如,操作码 8A 指定八位?MOV?指令。 表 5.2 中 8A 的条目为 :
MOV
rb,rmb?rb 代表寄存器字节【register byte】,并在 ModRM 字节的寄存器位中进行编码。 rmb 代表寄存器或内存字节【?register?or?memory byte?】,并在 ModRM 字节的内存位中进行编码。 8A C1 是 ?MOV AL,CL?的代码。 表 5.7 列出了 8 位寄存器代码。 CL 的代码进入 M 位,AL 的代码进入 R 位。
Table?5.7.?Codes for 8-Bit Registers
| Codes for 8-Bit Registers | |||
|---|---|---|---|
| AL | 000 | AH | 100 |
| CL | 001 | CH | 101 |
| DL | 010 | DH | 110 |
| BL | 011 | BH | 111 |
| Mod | R | M | |||||
|---|---|---|---|---|---|---|---|
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
组合两个字节产生 8A C1。?
Linux?.0?Files
包含对 ?printf()?或?scanf() 等函数调用的 C 程序需要链接到这些函数的编译代码。 该代码存储在 ?libc.so?等库中。 一旦链接【linking】完成,程序就会变得更长。 为了检查程序的机器代码,在完成链接之前查看代码会更容易,因为代码要少得多。 该代码存储在文件扩展名为 .o 的对象模块【object modules】中。 DOS 中的类似文件是.OBJ 文件。 要指示 gnu C 编译器生成 .o 文件,可以使用 -c 开关。 命令:
linuxbox$ gcc -c mult.c该命令生成一个 mult.o 文件。 该文件包含程序的机器代码,以及允许链接器【linker】完成其工作的表【table】。
要检查目标代码文件,可以使用本书附带的 ob 程序(对象转储)或标准 Unix 实用程序 od 程序(八进制转储)。 要使 od 以十六进制显示,请使用开关 -tx 和 -Ax。
linuxbox$ od -tx -Ax mult.o如果使用 ob 则不需要开关:
linuxbox$ ob mult.o本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 小白进公司快速熟悉环境和代码的方法
- 想要透明拼接屏展现更加效果,视频源是技术活,尤其作为直播背景
- 客户需求分析常用的ChatGPT通用提示词模板
- 图像视图ImageView的说明和使用
- MirusBio RevIT?AAVEnhancer,助力于AAV病毒大规模生产
- dpkg:警告:无法找到软件包 XXXX 问题解决
- 萨科微宋仕强论道之华强北国际化(二十二)
- git简单介绍和操作
- 使用群晖docker将小爱音箱接入chatgpt
- Dcoker构建部署Java项目过程