Kafka 消费者如何实现消费者组内分区平衡,Kafka常见面试问题
1、简介
????????一个消费者组中有多个consumer组成,一个topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。或者当某个消费者被移出消费者组,如何实现再平衡。本文将详细介绍。
2、消费者主要分区策略
????????Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。可以通过配置参数 partition.assignment.strategy,修改分区的分配策略。默认策略是 Range + CooperativeSticky。Kafka可以同时使用多个分区分配策略。
2.1、Range分区策略
????????Range 是对每个topic 而言的。首先对同一个topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。通过partitions数/consumer数来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费1 个分区。
????????例如,7/3 = 2 余1 ,除不尽,那么消费者C0 便会多消费1 个分区。8/3=2余2,除不尽,那么C0和C1分别多消费一个。
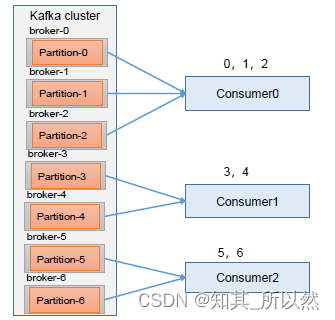
注意:如果只是针对1 个topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有N 多个topic,那么针对每个topic,消费者C0都将多消费1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费N 个分区。容易产生数据倾斜!
2.2、RoundRobin分区策略
????????RoundRobin 针对集群中所有Topic而言。RoundRobin 轮询分区策略,是把所有的partition 和所有的consumer 都列出来,然后按照hashcode 进行排序,最后通过轮询算法来分配partition 给到各个消费者。

?2.3、Sticky 分区策略
????????粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
2.4、CooperativeSticky 分区策略(2.4.0版本添加上的)
? ? ? ? 以上三种都会在 rebalance 的时候都会 stop the world,CooperativeSticky 分区策略在添加或者减少消费者的时候,只用调整的分区会暂停消费,不需要调整的分区可以继续消费。
3、Kafka 如何保证可靠消费
? ? ? ? 重复消费:已经消费了数据,但是offset 没提交(自动提交 offset 引起)。漏消费:先提交offset 后消费,有可能会造成数据的漏消费(设置 offset 为手动提交引起,,当offset被提交时,数据还在内存中未落盘,此时刚好消费者线程被kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。)。
? ? ? ? 如何保证消息可靠消费,使用消费者事务,Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质中(例如mysql中)。
4、如何解决消息积压问题
????????1)、如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数= 分区数。(两者缺一不可)
????????2)、如果是下游的数据处理不及时:提高每批次拉取的数量。通过设定?max.poll.records 参数实现,默认500条。
5、总结
? ? ? ? 本文介绍Kafka消费者如何进行消费分区分配,如何保证消息的可靠消费,同时说明消息积压常用的处理方式,帮助大家进一步了解Kafka如何实现消费者各种高端操作。
????????本人是一个从小白自学计算机技术,对运维、后端、各种中间件技术、大数据等有一定的学习心得,想获取自学总结资料(pdf版本)或者希望共同学习,关注微信公众号:it自学社团。后台回复相应技术名称/技术点即可获得。(本人学习宗旨:学会了就要免费分享)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 12.1 知识回顾(过滤器、 模型层)
- C++面试:单例模式、工厂模式等简单的设计模式 & 创建型、结构型、行为型设计模式的应用技巧
- Node.js基础---fs文件系统 读取和写入
- Android 无限循环RecyclerView的完美实现方案
- 深入了解Linux OOM Killer:一次可怕的内核事件
- 外汇天眼:在交易中有多少属于你的行情?
- Axure中如何使用交互样式&交互事件&交互动作&情形
- SQL注入总结
- 压力测试+接口测试(工具jmeter)
- Nginx虚拟主机配置