A Large Scale Fish Dataset 图像分割与识别
简介
以下是一门实验课的大作业。
数据集介绍:
此数据集包含从土耳其伊兹密尔的一家超市收集的9种不同的海鲜类型,数据集包括镀金头鲷、红鲷、鲈鱼、红鲻鱼、竹荚鱼、黑海鲱鱼,条纹红鲻鱼,鳟鱼,虾图像样本。(label分别为gilt head bream, red sea bream, sea bass, red mullet, horse mackerel,?black sea sprat, striped red mullet, trout, shrimp image samples)
论文材料:
O. Ulucan, D. Karakaya and M. Turkan, "A Large-Scale Dataset for Fish Segmentation and Classification," 2020 Innovations in Intelligent Systems and Applications Conference (ASYU), 2020, pp. 1-5, doi: 10.1109/ASYU50717.2020.9259867.
数据集下载:
https://www.kaggle.com/crowww/a-large-scale-fish-dataset
图像格式:
????图像是通过2台不同的相机收集的,柯达Easyshare Z650 和三星 ST60。因此,图像的分辨率分别为2832x2128,1024x =768。在分割和分类过程之前,数据集的大小已调整为?590x445。通过保留纵横比。调整图像大小后,数据集中的所有标签都得到了增强(通过翻转和旋转)。在增强过程结束时,每个类的总图像数量变为2000;其中1000是RGB图像和另外1000作为他们对应的ground-truth图像标签。
数据集的描述
????该数据集包含9种不同的海鲜类型。对于每个类,有1000个增强图像及ground-truth图像标签。每个类都可以在带有其真实标签的“Fish_Dataset”文件中找到。每个类的所有图像按“00000.png”到“01000.png”排序。例如,如果要访问数据集中虾真实标签图像,则应遵循"Fish->Shrimp->Shrimp GT"的顺序。
任务要求:
1.图像分割:
训练一个深度神经网络分割出图片中海鲜物体,
1)在测试集上形成如下所示的双色图,每一海鲜种类生成一个,共9个;
2)统计分割结果,打印出训练集loss和accuracy和测试集loss和accuracy。
2. 图像分类
训练深度神经网络对海鲜图片数据集进行分类,
??????1)在测试集上生成分类结果图9张(每一类各一张)(如下图,可在每个子图的标题上标记真实label和预测label);
? ? ? 2)?统计分类结果,打印出训练集loss和accuracy和测试集loss和accuracy。
图像分割
图像分割采用的是Unet+ResNet34,其中ResNet34采用的是torchvision中的预训练模型。
训练结果如下
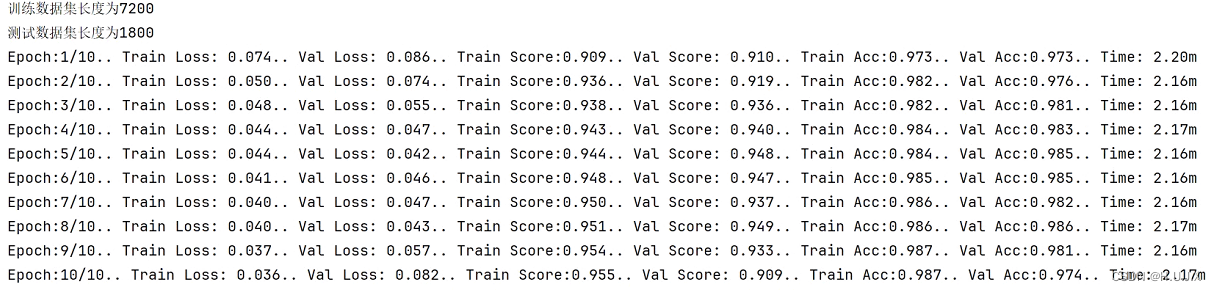
首先是制作数据集。
import torch
from torch.utils.data import Dataset, ConcatDataset, DataLoader
from PIL import Image
import os
import matplotlib.pyplot as plt
from torchvision import transforms
class MyData(Dataset):
def __init__(self, root_dir, label_dir, transfrom):
self.root_dir = os.path.join(root_dir, label_dir)
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.mpath = os.path.join(self.root_dir, self.label_dir + " GT")
self.img_path = os.listdir(self.path)
self.mask_path = os.listdir(self.mpath)
self.myTransforms = transfrom
def __getitem__(self, idx):
img_name = self.img_path[idx]
mask_name = self.mask_path[idx]
img_item_path = os.path.join(self.path, img_name)
mask_item_path = os.path.join(self.mpath, mask_name)
img = Image.open(img_item_path)
label = Image.open(mask_item_path)
img = self.myTransforms(img)
label = self.myTransforms(label)
label = label.to (torch.long)
return img, label
def __len__(self):
return len(self.img_path)
制作Unet+ResNet34的模型,其中resnet34使用的预训练权重。
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import ResNet34_Weights
class DecoderBlock(nn.Module):
"""Upscaling then double conv"""
def __init__(self, conv_in_channels, conv_out_channels, up_in_channels=None, up_out_channels=None):
super().__init__()
"""
eg:
decoder1:
up_in_channels : 1024, up_out_channels : 512
conv_in_channels : 1024, conv_out_channels : 512
decoder5:
up_in_channels : 64, up_out_channels : 64
conv_in_channels : 128, conv_out_channels : 64
"""
if up_in_channels == None:
up_in_channels = conv_in_channels
if up_out_channels == None:
up_out_channels = conv_out_channels
self.up = nn.ConvTranspose2d(up_in_channels, up_out_channels, kernel_size=2, stride=2)
self.conv = nn.Sequential(
nn.Conv2d(conv_in_channels, conv_out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(conv_out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(conv_out_channels, conv_out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(conv_out_channels),
nn.ReLU(inplace=True)
)
# x1-upconv , x2-downconv
def forward(self, x1, x2):
x1 = self.up(x1)
x = torch.cat([x1, x2], dim=1)
return self.conv(x)
class UnetResnet34(nn.Module):
def __init__(self, num_classes=2):
super().__init__()
resnet34 = torchvision.models.resnet34(weights=ResNet34_Weights.IMAGENET1K_V1)
filters = [64, 128, 256, 512]
self.firstlayer = nn.Sequential(*list(resnet34.children())[:3])
self.maxpool = list(resnet34.children())[3]
self.encoder1 = resnet34.layer1
self.encoder2 = resnet34.layer2
self.encoder3 = resnet34.layer3
self.encoder4 = resnet34.layer4
self.bridge = nn.Sequential(
nn.Conv2d(filters[3], filters[3] * 2, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(filters[3] * 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.decoder1 = DecoderBlock(conv_in_channels=filters[3] * 2, conv_out_channels=filters[3])
self.decoder2 = DecoderBlock(conv_in_channels=filters[3], conv_out_channels=filters[2])
self.decoder3 = DecoderBlock(conv_in_channels=filters[2], conv_out_channels=filters[1])
self.decoder4 = DecoderBlock(conv_in_channels=filters[1], conv_out_channels=filters[0])
self.decoder5 = DecoderBlock(
conv_in_channels=filters[1], conv_out_channels=filters[0], up_in_channels=filters[0],
up_out_channels=filters[0]
)
self.lastlayer = nn.Sequential(
nn.ConvTranspose2d(in_channels=filters[0], out_channels=filters[0], kernel_size=2, stride=2),
nn.Conv2d(filters[0], num_classes, kernel_size=3, padding=1, bias=False)
)
def forward(self, x):
e1 = self.firstlayer(x)
maxe1 = self.maxpool(e1)
e2 = self.encoder1(maxe1)
e3 = self.encoder2(e2)
e4 = self.encoder3(e3)
e5 = self.encoder4(e4)
c = self.bridge(e5)
d1 = self.decoder1(c, e5)
d2 = self.decoder2(d1, e4)
d3 = self.decoder3(d2, e3)
d4 = self.decoder4(d3, e2)
d5 = self.decoder5(d4, e1)
out = self.lastlayer(d5)
return out训练部分代码。
import torch.optim
import torchvision
from matplotlib import pyplot as plt
from torch import nn
from torch.utils.data import DataLoader, random_split, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
import time
from unet_utils import *
from Res34_Unet import UnetResnet34
from Dataloader import MyData
train_root_dir = "Fish_Dataset"
class_kind = ["Black Sea Sprat", "Gilt Head Bream", "Hourse Mackerel", "Red Mullet", "Red Sea Bream", "Sea Bass",
"Shrimp", "Striped Red Mullet", "Trout"]
myTransforms = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()]
)
dataset = []
for i in class_kind:
data = MyData(train_root_dir, i, myTransforms)
dataset = ConcatDataset([dataset, data])
fig, axes = plt.subplots(10, 2)
for i in range(10):
image, mask = dataset[i]
axes[i, 0].imshow(image.permute(1, 2, 0).numpy().reshape(256, 256, 3))
axes[i, 1].imshow(mask.numpy().reshape(256, 256)) # input size : 445x590
plt.show()
def train_test_split(dataset, test_size=0.2):
length = len(dataset)
train_length = round(length * (1 - test_size))
test_length = length - train_length
train_dataset, test_dataset = random_split(dataset, [train_length, test_length])
return train_dataset, test_dataset
train_dataset, test_dataset = train_test_split(dataset)
train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
print("训练数据集长度为{}".format(train_data_size))
print("测试数据集长度为{}".format(test_data_size))
# 利用dataloader 加载数据集
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False)
# 搭载神经网络
model = UnetResnet34(num_classes=2)
model = model.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("final_homework/final_homework/logs_train")
fit_time = time.time()
for i in range(epoch):
# 训练步骤开始
t_loss_perb, t_iou_perb, t_acc_perb = 0, 0, 0
v_loss_perb, v_iou_perb, v_acc_perb = 0, 0, 0
t_loss_pere, v_loss_pere = 0, 0
since = time.time()
model.train()
for data in train_dataloader:
imgs, masks = data
imgs = imgs.cuda()
masks = masks.cuda()
outputs = model(imgs)
masks = torch.squeeze(masks)
loss = loss_fn(outputs, masks)
t_iou_perb += mIoU(outputs, masks)
train_accuracy= pixel_accuracy(outputs, masks)
t_acc_perb += train_accuracy
# 优化器模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
t_loss_perb += loss.item()
total_train_step = total_train_step + 1
if total_train_step % 10 == 0:
writer.add_scalar("train_loss", loss.item(), total_train_step)
writer.add_scalar("pixel_accuracy", train_accuracy, total_train_step)
with torch.no_grad():
model.eval()
for data in test_dataloader:
imgs, masks = data
imgs = imgs.cuda()
masks = masks.cuda()
masks = torch.squeeze(masks)
outputs = model(imgs)
loss = loss_fn(outputs, masks)
v_iou_perb += mIoU(outputs, masks)
v_acc_perb += pixel_accuracy(outputs, masks)
# loss
v_loss_perb += loss.item()
#calculation mean for each batch
t_loss_pere = t_loss_perb/len(train_dataloader)
v_loss_pere = v_loss_perb/len(test_dataloader)
print("Epoch:{}/{}..".format(i + 1, epoch),
"Train Loss: {:.3f}..".format(t_loss_pere),
"Val Loss: {:.3f}..".format(v_loss_pere),
"Train Score:{:.3f}..".format(t_iou_perb / len(train_dataloader)),
"Val Score: {:.3f}..".format(v_iou_perb / len(test_dataloader)),
"Train Acc:{:.3f}..".format(t_acc_perb / len(train_dataloader)),
"Val Acc:{:.3f}..".format(v_acc_perb / len(test_dataloader)),
"Time: {:.2f}m".format((time.time() - since) / 60))
torch.save(model, 'Res34_Unet.pth')
writer.close()
预测结果可视化部分。
import os
import matplotlib.pyplot as plt
import numpy as np
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import DataLoader, random_split, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
from Read_Data_predit import MyData
from PIL import Image
myTransforms = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
])
#准备数据集
root_dir = "Fish_Dataset"
kind_name = ["Black Sea Sprat", "Gilt Head Bream", "Hourse Mackerel", "Red Mullet",
"Red Sea Bream", "Sea Bass", "Shrimp", "Striped Red Mullet", "Trout"]
dataset = []
fig, axes = plt.subplots(9, 3)
myModel = torch.load("Res34_Unet.pth")
# fig, axes = plt.subplots(10, 2, figsize=(10, 50))
# for i in range(10):
# image, mask = dataset[i]
# axes[i, 0].imshow(image.permute(1, 2, 0).numpy().reshape(445, 590, 3))
# axes[i, 1].imshow(mask.numpy().reshape(256, 256)) # input size : 445x590
# plt.show()
myModel.eval()
with torch.no_grad():
for i, name in enumerate(kind_name):
img_root_dir = os.path.join(root_dir,name)
mask_root_dir = os.path.join(root_dir, name)
img_item_path = os.path.join(img_root_dir, name, "00010.png")#取每类第一张进行验证
mask_item_path = os.path.join(mask_root_dir, name+" GT", "00010.png") # 取每类第一张进行验证
img = Image.open(img_item_path)
mask = Image.open(mask_item_path)
data_transform = myTransforms(img)
data_transform = data_transform.unsqueeze(dim=0) # 添加一维batch
data_transform = data_transform.cuda()
output = myModel(data_transform)
output = torch.squeeze(output) # 去掉batch_size 维度
output = torch.squeeze(output[1]) # 第0个是背景 第1个是目标
output = output.cpu()
output = output.numpy().reshape(256, 256)
binary_predicted_mask = np.where(output > 0.5, 1, 0)
axes[i, 0].imshow(img.resize((256, 256)))
axes[i, 1].imshow(mask.resize((256, 256)))
axes[i, 2].imshow(binary_predicted_mask)
plt.show()图像分类
? ? ? ? 图像分类采用的是ResNet50,使用torchvision自带的模型与训练权重,因此无需制作模型。
图像分类训练结果,可以看到训练三轮就可以90%。

首先是数据集制作
import torch
from torch.utils.data import Dataset, ConcatDataset, random_split
from PIL import Image
import os
import numpy as np
class MyData(Dataset):
def __init__(self, root_dir, label_dir, class_num, transforms):
self.root_dir = os.path.join(root_dir, label_dir)
self.label_dir = label_dir
self.class_num = class_num
self.transforms = transforms
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
img = self.transforms(img)
label = self.class_num
return img, label
def __len__(self):
return len(self.img_path)
# root_dir = "Fish_Dataset"
#
# kind_name = ["Black Sea Sprat", "Gilt Head Bream", "Hourse Mackerel", "Red Mullet",
# "Red Sea Bream", "Sea Bass", "Shrimp", "Striped Red Mullet", "Trout"]
# dataset = []
#
#
# def train_test_split(dataset, test_size=0.2):
# length = len(dataset)
# train_length = round(length * (1 - test_size))
# test_length = length - train_length
#
# train_dataset, test_dataset = random_split(dataset, [train_length, test_length])
# return train_dataset, test_dataset
#
#
# for i, name in enumerate(kind_name):
# dataset_temp = MyData(root_dir, name, i)
# dataset = ConcatDataset([dataset, dataset_temp])
#
# train_data, test_data = train_test_split(dataset)
# train_data_size = len(train_data)
# test_data_size = len(test_data)
# print("训练数据集长度为{}".format(train_data_size))
# print("测试数据集长度为{}".format(test_data_size))
训练部分代码。
import time
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import DataLoader, random_split, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
from Read_Data import MyData
myTransforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
#准备数据集
root_dir = "Fish_Dataset"
kind_name = ["Black Sea Sprat", "Gilt Head Bream", "Hourse Mackerel", "Red Mullet",
"Red Sea Bream", "Sea Bass", "Shrimp", "Striped Red Mullet", "Trout"]
dataset = []
def train_test_split(dataset, test_size=0.2):
length = len(dataset)
train_length = round(length * (1 - test_size))
test_length = length - train_length
train_dataset, test_dataset = random_split(dataset, [train_length, test_length])
return train_dataset, test_dataset
for i, name in enumerate(kind_name):
dataset_temp = MyData(root_dir, name, i, myTransforms)
dataset = ConcatDataset([dataset, dataset_temp])
train_data, test_data = train_test_split(dataset)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集长度为{}".format(train_data_size))
print("测试数据集长度为{}".format(test_data_size))
#利用dataloader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
#搭载神经网络
# 定义模型
myModel = torchvision.models.resnet50(weights=torchvision.models.ResNet50_Weights.DEFAULT)
# 将原来的ResNet18的最后两层全连接层拿掉,替换成一个输出单元为9的全连接层
inchannel = myModel.fc.in_features
myModel.fc = nn.Linear(inchannel, 9)
myModel.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
#优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(myModel.parameters(), lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./ResNet_train")
for i in range(epoch):
since = time.time()
print("----------------第{}轮训练开始----------------".format(i+1))
total_train_loss = 0
total_train_accuracy = 0
#训练步骤开始
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
ouputs = myModel(imgs)
loss = loss_fn(ouputs, targets)
#优化器模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss = total_train_loss +loss.item()
total_train_step = total_train_step + 1
train_accuracy = (ouputs.argmax(1) == targets).sum()
total_train_accuracy = total_train_accuracy + train_accuracy
# if total_train_step % 10 == 0:
# print("训练次数:{}, train_loss:{}".format(total_train_step, loss.item()))
# print("训练次数:{}, train_accuracy:{}".format(train_accuracy, loss.item()))
#测试步骤开始
total_test_loss = 0
total_test_accuracy = 0
myModel.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
ouputs = myModel(imgs)
loss = loss_fn(ouputs, targets)
total_test_loss = total_test_loss + loss.item()
test_accuracy = (ouputs.argmax(1) == targets).sum()
total_test_step = total_test_step + 1
total_test_accuracy = total_test_accuracy + test_accuracy
print("整体训练集上的Loss: {}".format(total_train_loss))
print("整体训练集上的正确率: {}".format(total_train_accuracy/train_data_size))
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_test_accuracy/test_data_size))
print("第{}轮耗时{:.2f}min".format(i+1,(time.time()-since)/60))
total_test_step = total_test_step + 1
torch.save(model, 'Resnet50_fish.pth')
writer.close()
?预测结果与可视化,需要注意放入模型前将图片进行transorms。
import os
import matplotlib.pyplot as plt
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import DataLoader, random_split, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
from Read_Data_predit import MyData
from PIL import Image
myTransforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
#准备数据集
root_dir = "NA_Fish_Dataset"
kind_name = ["Black Sea Sprat", "Gilt Head Bream", "Hourse Mackerel", "Red Mullet",
"Red Sea Bream", "Sea Bass", "Shrimp", "Striped Red Mullet", "Trout"]
dataset = []
fig, axes = plt.subplots(3, 3)
myModel = torch.load("Resnet50_fish.pth")
myModel.eval()
with torch.no_grad():
for i, name in enumerate(kind_name):
img_item_path = os.path.join(root_dir, name, "00001.png")#取每类第一张进行验证
img = Image.open(img_item_path)
axes[i // 3, i % 3].imshow(img)
data_transform = myTransforms(img)
data_transform = data_transform.unsqueeze(dim=0) # 添加一维batch
data_transform = data_transform.cuda()
output = myModel(data_transform)
output = output.argmax(1)
axes[i // 3, i % 3].set_title("True:"+kind_name[i]+"\nPredited:"+kind_name[output] , loc = "center")
plt.show()Unet工具包
import yaml
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import shutil
import os
import pandas as pd
from torch import nn
def create_df(path):
name = []
for dirname, _, filenames in os.walk(path):
for filename in filenames:
name.append(filename.split('.')[0])
return pd.DataFrame({'id': name}, index=np.arange(0, len(name)))
def plot(history, graphType, isTest=False):
if not isTest:
plt.plot(history[f'train_{graphType}'], label='train', marker='*')
plt.plot(history[f'val_{graphType}'], label='val', marker='o')
else:
plt.plot(history[f'test_{graphType}'], label='test', marker='*')
plt.title(f'{graphType} per epoch')
plt.ylabel(f'{graphType}')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
def CE_Loss(inputs, target, cls_weights, num_classes=2):
n, c, h, w = inputs.size()
nt, ht, wt = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = inputs.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
temp_target = target.view(-1)
CE_loss = nn.CrossEntropyLoss(ignore_index=num_classes)(temp_inputs, temp_target)
return CE_loss
def pixel_accuracy(output, mask):
with torch.no_grad():
output = torch.argmax(F.softmax(output, dim=1), dim=1)
correct = torch.eq(output, mask).int()
accuracy = float(correct.sum()) / float(correct.numel())
return accuracy
def mIoU(pred_mask, mask, n_classes=2, smooth=1e-10):
with torch.no_grad():
pred_mask = F.softmax(pred_mask, dim=1)
pred_mask = torch.argmax(pred_mask, dim=1)
pred_mask = pred_mask.contiguous().view(-1)
mask = mask.contiguous().view(-1)
iou_per_class = []
for clas in range(0, n_classes): # loop per pixel class
true_class = pred_mask == clas
true_label = mask == clas
if true_label.long().sum().item() == 0: # no exist label in this loop
iou_per_class.append(np.nan)
else:
intersect = torch.logical_and(true_class, true_label).sum().float().item()
union = torch.logical_or(true_class, true_label).sum().float().item()
iou = (intersect + smooth) / (union + smooth)
iou_per_class.append(iou)
return np.nanmean(iou_per_class)
def load_train_config(path):
with open(path) as f:
data = yaml.load(f, Loader=yaml.Loader)
return data
def visualize(image, mask, pred_mask, score):
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(20, 10))
ax1.imshow(image)
ax1.set_title('Picture')
ax2.imshow(mask)
ax2.set_title('Ground truth')
ax2.set_axis_off()
ax3.imshow(pred_mask)
ax3.set_title('UnetResnet34 | mIoU {:.3f}'.format(score))
ax3.set_axis_off()
def save_checkpoint(state, current_checkpoint_path, is_best=False, best_model_path=None):
torch.save(state, current_checkpoint_path)
if is_best:
assert best_model_path != None, 'best_model_path should not be None.'
shutil.copyfile(current_checkpoint_path, best_model_path)
def load_checkpoint(best_model_path, current_checkpoint_path, model, optimizer, scheduler, best_checkpoint=False):
train_loss_key = 'train_loss'
val_loss_key = 'val_loss'
path = current_checkpoint_path
if best_checkpoint:
path = best_model_path
model, optimizer, scheduler, epoch, train_loss, val_loss = load_model(path, model, optimizer, scheduler,
train_loss_key, val_loss_key)
print(f'optimizer = {optimizer}, start epoch = {epoch}, train loss = {train_loss}, val loss = {val_loss}')
return model, optimizer, scheduler, val_loss
def load_model(model_path, model, optimizer, scheduler, train_loss_key, val_loss_key):
checkpoint = torch.load(model_path)
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
scheduler.load_state_dict(checkpoint['scheduler'])
epoch = checkpoint['epoch']
train_loss = checkpoint[train_loss_key]
val_loss = checkpoint[val_loss_key]
return model, optimizer, scheduler, epoch, train_loss, val_loss
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 删除字符串中的所有相邻重复项
- SpringMVC(全局异常处理.动态接收Ajax请求)
- 【GitHub项目推荐--基于 Flutter 的游戏引擎】【转载】
- 李宏毅机器学习第二十三周周报 Flow-based model
- Android hilt使用
- postgresql查询每组的前N条记录
- IDEA中也能用Postman了,这款插件平替
- C语言void类型
- STC进阶开发(四)SPI协议、矩阵键盘、EEPROM
- ROS学习笔记(二):话题通信、服务通信的了解和对应节点的搭建(C++)